
微信支付日志系统利用 Hermes 来实现日志的全文检索功能,自从接入以来,日志量持续增长。目前单日入库日志量已经突破万亿级,单集群日入库规模也已经突破了万亿,存储规模达 PB 级。本文将介绍微信支付日志系统在 Hermes 上的实践,希望与大家一同交流。
一、业务规模
目前微信支付日志单日最大入库总量已达到万亿级,单日入库存储量达 PB 级,而在春节等重大节假日预计整个日入库规模会有进一步的增长。
微信支付日志业务采用的 Hermes 集群,单集群日入库规模也已经突破了万亿级每天,节点部署有二百多台,单集群存储总量达到 PB 级。另外,每天的检索查询并发在 6000 左右:
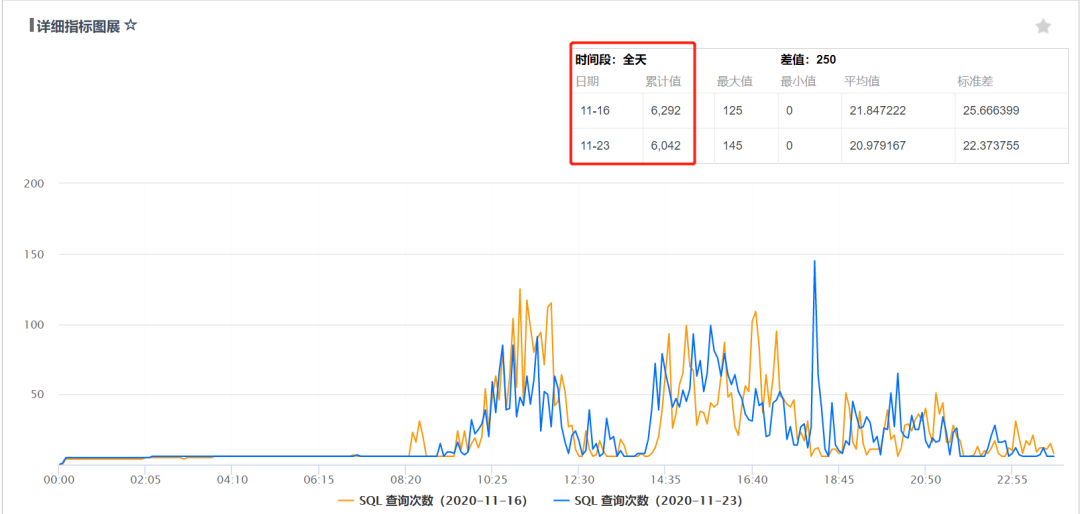
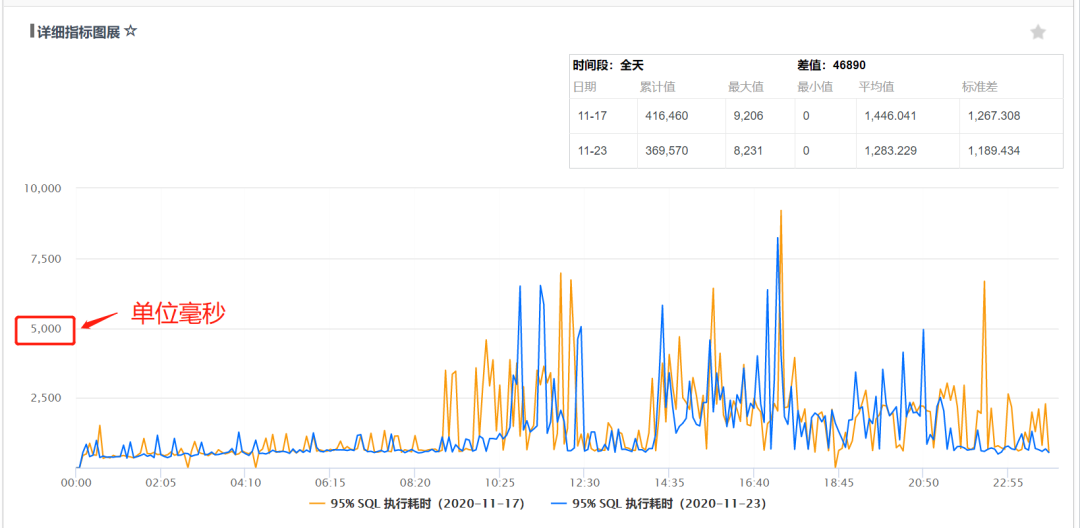
在如此海量日志存储规模下,整个微信支付日志查询 SLA 达到了 4 个 9,95% 的耗时小于 5s。
二、存算分离
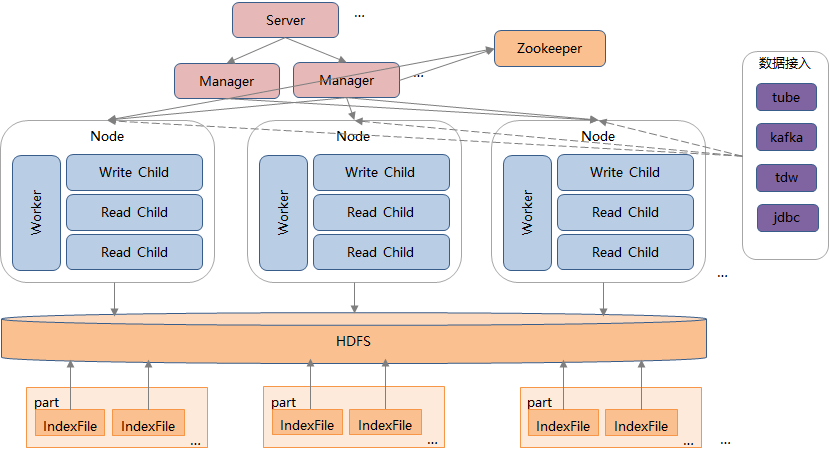
Hermes 底层存储采用 HDFS 来实现,所有的存储相关的策略都由专业的 HDFS 的能力来提供,包括:
1. 数据多副本容灾
日志默认存储 2 副本容灾,针对历史数据可以灵活的降低副本来减少存储成本,而针对非常重要的日志数据也可以灵活的增加副本来提高数据容灾能力。
2. 磁盘故障容错
单磁盘或单机故障 HDFS 可自动迁移副本,整个容错过程对上层计算层透明。
3. 冷热分级
利用 HDFS 提供的异构存储能力,结合 Hermes 本身的按天分区存储,可以非常方便的实现数据的冷热分级。冷热分级后的数据对上层业务透明,业务无需关注数据本身的存储情况
4. EC 编码
HDFS 3.0 版本之后支持 EC 编码,进一步降低存储成本,目前暂时未在线上实践。通过采用这种存算分离的架构,一方面可以简化上层的计算层的设计;另一方面计算层计算索引的时候只需计算单份即可实现多副本容灾,从而极大的减少计算层的 CPU、内存资源消耗,使得写入 QPS 成倍提升。
三、异步索引合并
Hermes 本身采用类 LSM 的数据写入模式,数据先写入内存+WAL,积累到一定数量后再批量刷写到 HDFS 进行持久化存储。节点故障时,系统通过回滚 WAL 进行数据恢复,从而确保整个写入为高效的顺序写入。
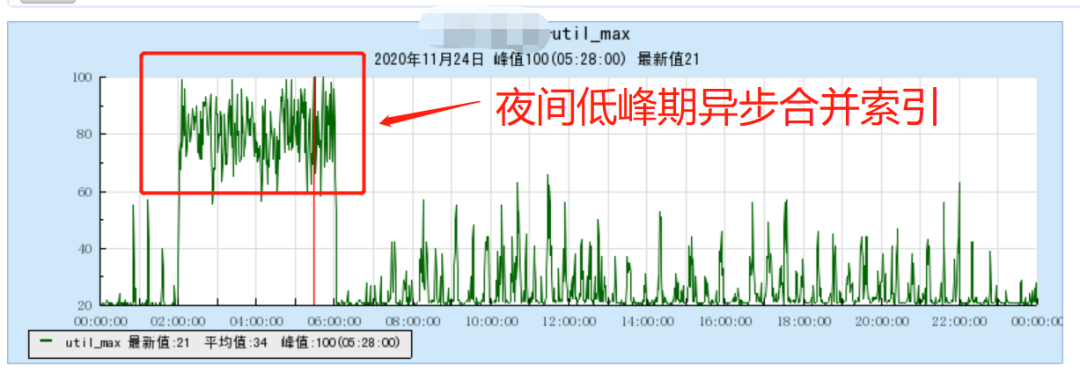
这种高效的写入方式带来的一个问题就是:随着数据的不断刷写,会产生大量的小的索引,从而对查询和 HDFS 存储造成较大的压力。
Hermes 本身会不断的对小的索引进行合并,降低索引文件的个数;而在夜间低峰期,我们也会对历史的分区数据进行一次较大的合并粒度,从而尽可能的提高整个系统的查询效率。微信支付业务的合并时间点选取的是凌晨 2~6 点,避开了凌晨 0~1 点的除夕红包高峰。
四、索引与数据分离
日志等业务场景的一个重要的特点就是:先按照分词+字段信息进行检索,然后拉取完整的一整行日志进行分析。针对这种场景,传统的列存往往存在行存信息获取效率较低,而索引和数据混存又会存在合并索引时读写 IO 放大严重的问题。
为此,Hermes 除了会对日志进行分词构建索引之外,还可以额外配置存储一份完整的日志行存信息:
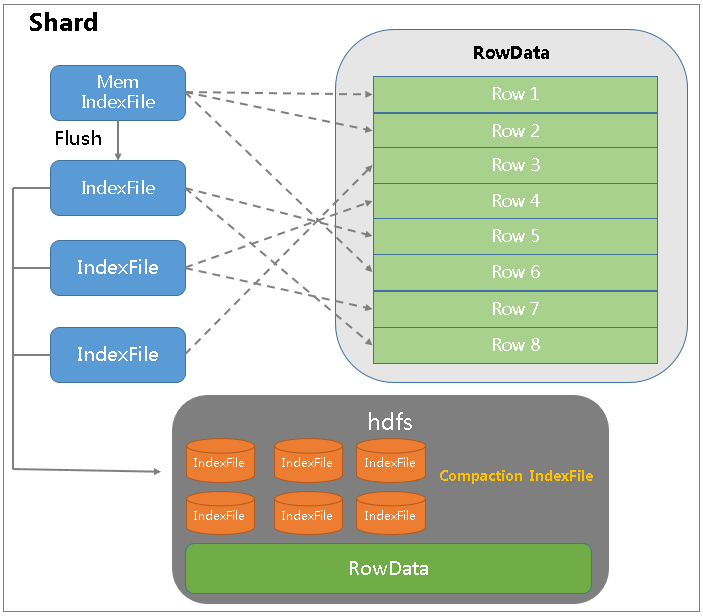
如上图所示,通过将索引和数据分离存储,索引目录里只存储倒排索引,行数据里同一个分片里每个索引目录相应的行数据。通过每个索引目录的 Offset 和 RowId,在 RowData 中读取结果数据。通过索引和数据的分离,索引目录刷盘次数和个数降低 68%,内存使用量降低 70%,磁盘使用量降低 14%,检索性能提升 80%。

五、存储冷热分级
微信支付 90% 的日志模块都是数据量非常小的长尾模块。因此适当的引入一些高性能的 SSD 设备来加速这些存储较小的业务的查询是非常合适的,而为了可以尽可能的减少 SSD 的成本,需要对业务的数据进行冷热分级。
Hermes 本身的数据冷热分级是利用 HDFS 的异构存储能力来实现的,通过配置不同的副本放置策略,可以灵活的指定副本使用的存储类型,而整个过程对上层业务透明。
HDFS 异构存储策略如下所示:
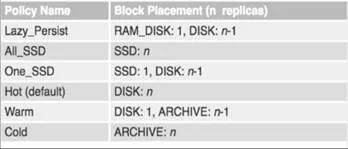
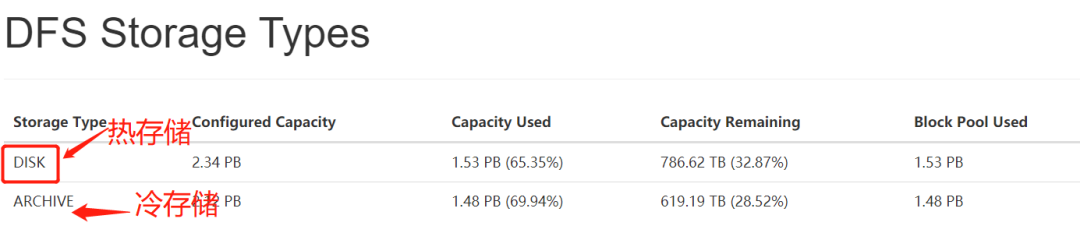
HDFS 异构存储在 Hermes 中的实践:
六、历史分区副本降级
Hermes 底层存储采用 HDFS 多副本来进行数据容灾,一般默认会存储两副本。目前微信支付的日志最长的保存周期为 30 天,存储数据量非常大。
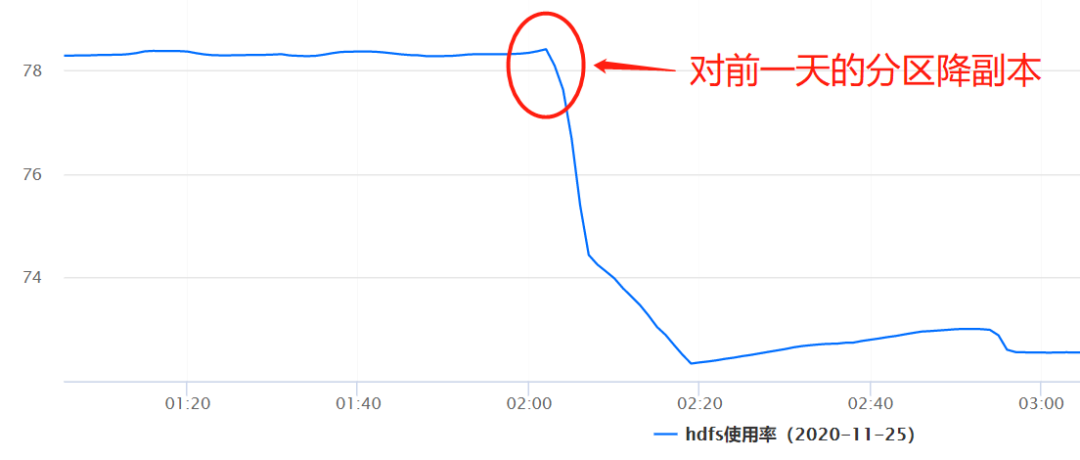
为了尽可能的降低业务的存储成本,在同业务协商沟通之后,了解到一般三天之前的日志的查询需求很低,对于日志的稳定性可以降低一些,因此 Hermes 运维侧直接对三天前的数据进行例行降副本操作,从而使得整个存储的成本直接降低 70% 以上,整个降副本操作对上层计算层和业务层都是透明的,业务对此没有任何感知。
七、日志批量导出
微信支付的同事经常会有批量导出指定时间段的命中某些关键词的日志的需求:
为此 Hermes 提供批量异步导出日志到 HDFS 等存储介质的功能,用户提交导出请求后,系统会把所有命中的日志导出一份到 TDW HDFS 上面,用户再用 TDW HDFS 客户端或者通过 Hermes 的接口机拖走就行。
TDW HDFS 上面用户的日志导出文件:

八、结语
微信支付接入 Hermes 以来,日志量规模从最初的百亿规模增长至现在的万亿级规模,对整个 Hermes 本身的存储能力、扩展能力、容灾能力和资源规划能力都持续提出挑战。
好在 Hermes 本身优秀的存储架构使得可以在海量业务数据规模下灵活的对业务的数据进行翻转腾挪,从而从容的应对业务持续提出的各种挑战。
头图:Unsplash
作者:宋新村
来源:云加社区 - 微信公众号 [ID:QcloudCommunity]
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。




