本文要点
- SVM 是一种非常高效的文档分类工具。
- 通过减小数据集或矢量的大小,可以简化模型训练。
- 通过关联关系重用标签数据,可以降低训练成本,同时提升预测准确性。
- 选择合适的数据结构可以达到最好的效果。
- 扁平化数据层级有助于减少 SVM 的数量。
在进行监督学习时,标签数据的质量在很多时候会成为影响预测系统准确性的重要因素。
在 Love the Sales ,我们会收集来自 700 家多国零售商的产品信息,每天需要对 200 多万个产品进行分类。如果让人工来完成这项工作,一个传统的销售团队需要四年时间。
我们的任务是对这 200 多万个产品(大部分是时尚和家具产品)的文本元数据进行分类,把它们分成 1000 多个类别,并以层级的方式展现出来,类似这样:
服装
男式服装
男式牛仔
男式连衣裤
女式服装
女式牛仔
女式连衣裤
…
支持向量机(SVM)
我们使用 SVM 来完成分类任务。SVM 是一种监督机器学习算法,用于对线性分隔的数据进行分类。
给定一个有标签的训练数据集,SVM 尝试找出样本间最具代表性的平面(plane),并画出多维度的分隔线条。
比如,下图就是一个分隔数据集的例子。

SVM 尝试找出最优的超平面(hyperplane)。

尽管机器学习中的分类算法有很多(神经网络、随机森林、朴素贝叶斯),而SVM 最擅长处理具有多种特征的数据。在我们的例子当中,我们要对文档进行分类,文档中的每一个“单词”都被视为一个离散的特征。
SVM 可以进行多类识别,而我们打算进行简单的二类识别,并把它们链成层级结构。

我们经过测试,这样会得到更好的结果。更重要的是,它使用更少的内存,因为每个 SVM 只需要知道两类数据。大数据集(30 万多样本)的内存开销和大量输入向量(一百万个单词)对我们来说是绝对是个负担。
有些简单的文本预处理技术可用于降低文档特征空间复杂性,比如将字母转换成小写、词干提取、移除奇怪的字符、移除“噪音”单词和数字。
词干提取是一种常见的文本处理技术,非常适用于处理大语料库,目的是将具有意思相近的单词和词根提取成相似的节点。例如,单词“Clothing”和“Clothes”意思相近,使用“Porter”算法提取出词干“cloth”。通过这种方式,我们减少了将近一半的单词量。结合使用词干提取技术和“噪音”单词移除技术(将没有实际意义的单词移除,如 The、Is、And、With 等),我们将需要处理的单词量降低了很多。
创建 SVM
处理好文本数据后,下一步要开始进行模型训练。要训练模型,需要将文本数据转换成 SVM 可理解的格式,也就是所谓的“矢量化(Vectorization)”。以下面的句子为例:
Men, you’ll look fantastic in this great pair of mens skinny jeans
经过预处理后,可以得到如下结果:
men fantastic great pair men skinny jean
上面的句子里有一个重复单词,我们可以对它们进行编码:
Occurrences Term 1 fantastic 1 great 1 jean 2 men 1 pair 1 skinny 这个可以使用向量来表示,如 [1,1,1,2,1,1]。
在单词不多的情况下,可以使用这种方式。但随着样本的增多,词汇表也随着增长,例如,我们增加了另一个训练样本:
women bootcut acid wash jean
这个时候词汇表就会变成:
[acid,bootcut,fantastic,great,jean,men,pair,skinny,wash,women]
原先的向量就会变成:
[0,0,1,1,1,2,1,1,0,0]
如果有数千个样本,词汇表就会变得很大,向量会很臃肿,其中有大部分元素都是空的:
[0,0,0,0,0,0,0,0,..... 2,0,0,0,0,0,.....1,0,0,0,0 …]
好在很多机器学习库支持稀疏向量,也就是说,我们可以只提供非零的向量元素,机器学习库(我们使用的是 LibSVM )可以自动填充其他部分。
我们提供词汇向量和它们在整个训练样本中的索引位置,如:
Term Index Term 0 acid 1 bootcut 2 fantastic 3 great 4 jean 5 men 6 pair 7 skinny 8 wash 9 women 那么“men fantastic great pair men skinny jean”就可以被描述成:
Term Index #2 : 1 Occurance<br></br>
Term Index #3 : 1 Occurance<br></br>
Term Index #4 : 1 Occurance<br></br>
Term Index #5 : 2 Occurrences<br></br>
Term Index #6 : 1 Occurrences<br></br>
Term Index #7 : 1 Occurrences
然后编码成:
[2:1,3:1,4:1,5:2,6:1,7:1]
Alexandre Kowalczyk 在这里对词汇表预处理进行了充分的介绍,还附带了其他SVM 教程。
层级和数据结构
我们知道,SVM 的结构对需要使用多少训练数据有重大影响。下面是一个简单的结构:
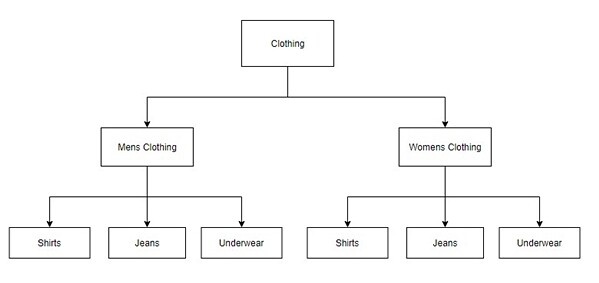
这种结构要求每增加一个子类别都需要两个新SVM。比如,增加新分类“Swimwear”,就需要在男士服装和女士服装下面分别增加一个SVM,就更不用提再增加一种“中性”风格的类别了。总之,层级结构越深,就越复杂。
我们可以通过将数据结构拆分成多棵子树来避免大量的标签和训练工作。
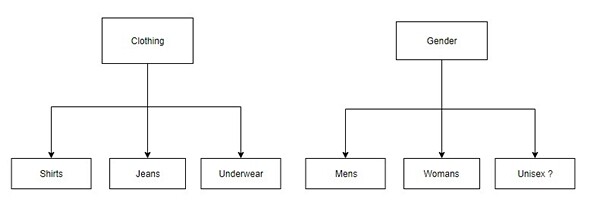
通过拆解层级结构,遍历每个SVM 就可以生成最终的分类结果,并使用基于集合的逻辑推理出来,比如:
Mens Slim-fit jeans = (Mens and Jeans and Slim Fit) and not Womens
这种方式可以减少 SVM 的数量,参考集合的交集可用于表示最终的分类结果。

增加新的分类会增加最终类别的数量。比如,在最上层增加“儿童”分类,就可以生成整个儿童类别维度(儿童牛仔、衬衫、内衣等),而只需要增加最少量的训练数据(只需要增加一个SVM):

数据重用
根据我们所选的结构,可以通过链接数据关系来重用训练数据。通过链接数据,我们可以实现9 倍以上的训练数据重用,在很大程度上降低了成本,并提高预测的准确性。
对于每一个分类,我们需要尽可能多的训练数据样本,从而得出更全面的结果。尽管我们已经开发了一些内部工具,提供了用户接口用于搜索、排序和按照批次给训练数据打标签,但要给如此多的训练数据打标签仍然是一件费劲、成本高昂和易出错的事情。我们希望通过尽可能重用数据的方式来避开这些问题。
例如,我们知道,“洗衣机”肯定不会是“地毯清洁机”。

通过链接“排除数据”,我们可以将“地毯清洁机”SVM 的“正向”数据加入到“洗衣机”SVM 的“负向”数据中,反之亦然。
这种方式有一个优势,就是在增加额外的训练数据来改进“地毯清洁机”SVM 时,因为链接数据的存在,同样也会起到改进“洗衣机”分类的作用。
另一个可以重用数据的地方在于,子节点的正向训练数据也是其父节点的正向训练数据。
例如,“牛仔服”肯定是“服装”。

也就是说,在往“牛仔服”SVM 加入正向的训练数据的同时,也通过数据链接的方式往“服装”SVM 加入了这些正向训练数据。
增加链接数据比手动给数据打标签要高效得多。

结论
我们认为,SVM 已经帮助我们提升了分类的质量和速度,而这些是通过其他非机器学习方式所无法达到的。所以,我们认为SVM 是开发者的一个得力工具。
另外,在面对结构化分类系统时,将分类组件从整体结构中分离出来,扁平化数据结构,并重用训练数据,将会极大提升我们的效率。上述的例子不仅减少了需要手动进行分类的数据,也给我们带来了极大的灵活性。
作者简介
 David Bishop 最初在新西兰学习计算机科学,后来到了伦敦。十年来,他在英国排名前 100 的招聘网站 reed.co.uk 领导技术团队,现在创办了属于自己的零售技术业务网站 LoveTheSales.com,专注于将上千个零售网站的销售聚合起来。
David Bishop 最初在新西兰学习计算机科学,后来到了伦敦。十年来,他在英国排名前 100 的招聘网站 reed.co.uk 领导技术团队,现在创办了属于自己的零售技术业务网站 LoveTheSales.com,专注于将上千个零售网站的销售聚合起来。
参考
查看英文原文: Get More Bytes for Your Buck




