
Snowflake 数据库系统集成了多种强大功能,用于优化查询性能和成本效益。通过测试、研究与实验验证,我们发现特定场景下 Snowflake 未能对可能受益的物理查询执行计划应用名为 JoinFilter 的高效优化技术。本文阐述了 JoinFilter 的技术原理,指导如何识别查询计划中是否启用该功能,并揭示如何引导查询优化器应用 JoinFilter 运算符。
引言
为实现更优的成本效益,企业正加速向云数据平台迁移。与传统需要巨额前期投资和持续维护成本的本地数据仓库不同,Snowflake 等云解决方案采用灵活的按需付费模式,使企业在保障扩展性与性能的同时实现成本优化。在迁移过程中,许多组织优先考虑代码移植与工期要求,往往忽视查询优化。这种疏漏会导致查询执行效率低下,进而引发计算资源的扩容需求,最终推高运营成本,背离成本优化目标。
Snowflake 查询优化器通过缓存机制、分区修剪及 JoinFilter 运算符等技术手段,最大限度减少不必要的数据移动,提升查询效率。然而在实际运行中,优化器可能存在未应用 JoinFilter 的情况,导致性能欠佳与成本增加。本文深入探讨 JoinFilter 在查询优化中的关键作用,定位其未被启用的典型场景,并提供提升性能与降低成本的实践方案。
JoinFilter 简介
Snowflake 采用一种专有且闭源的文件格式——微分区(micro-partition)来存储表数据。同时,Snowflake 会记录每个微分区中所有存储行的元数据,包括:
微分区内各列数值的取值范围;
不同取值的数量;
用于查询优化和高效查询处理的附加属性。
这些元数据在 Snowflake 优化器采用的两种分区修剪技术中发挥着关键作用:静态剪枝与通过 JoinFilter 实现的动态剪枝。这两种技术均通过减少数据扫描量来提升查询性能,但其剪枝的发生时机有所不同。
静态剪枝
静态剪枝发生在查询编译形成逻辑查询计划阶段。Snowflake 利用数据元数据和统计信息(如列的最小值/最大值)来识别并消除不包含查询所需数据的微分区。
通过 JoinFilter 算子实现的动态剪枝
动态剪枝发生在查询执行阶段,基于连接条件进行优化。查询优化器利用连接操作中的信息来排除另一侧不相关的微分区。当优化器采用动态剪枝时,会在查询计划中引入一种特殊类型的算子——JoinFilter。
JoinFilter 运用谓词下推优化技术,通过在执行计划中尽早完成数据过滤来提升查询性能。
如何识别查询计划中的 JoinFilter
顾名思义,JoinFilter 运算符可能出现在涉及两个或多个表连接查询的查询计划中。然而,存在连接操作并不保证查询计划中一定会包含 JoinFilter。在某些情况下,优化器并不会添加 JoinFilter。
如图 1 所示,查询计划中包含 JoinFilter 的分支(以绿色标出)与不包含该操作的分支(以红色标出)形成对比。
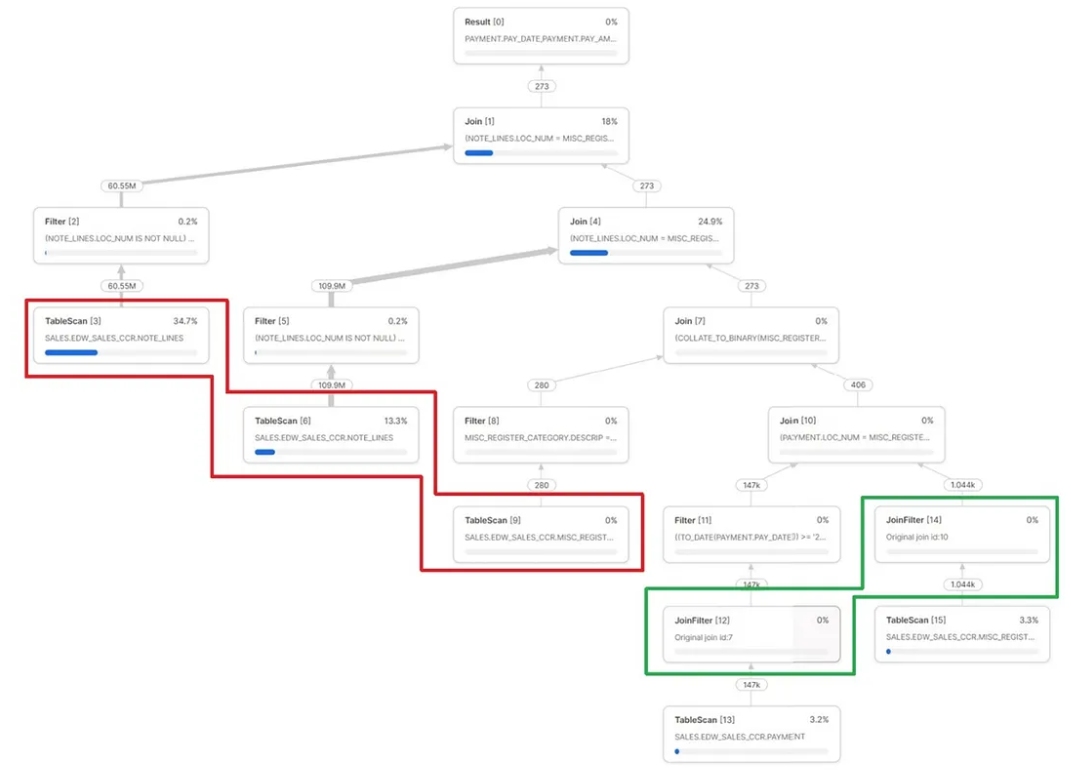
图 1:包含部分连接过滤器的查询计划
缺失 JoinFilter 的一个可能原因
查询所涉及表的元数据统计信息对于优化器生成的查询计划至关重要。根据我们的经验,直接使用表而非视图的查询通常能产生更优化的查询计划。
例如,图 2a 和图 2b 展示了一个在子查询中引用视图的查询的分区剪枝统计信息。相比之下,图 2c 和图 2d 则展示了相同查询但在子查询中引用表(而非视图)时的分区剪枝统计信息。显而易见,在子查询中使用表时,分区剪枝的效果要优于使用视图。根据 Snowflake 技术支持提供的信息,这是因为优化器需要解析视图的定义,这限制了其全面访问元数据并高效执行数据分区剪枝的能力。

图 2a:在子查询中引用视图的查询
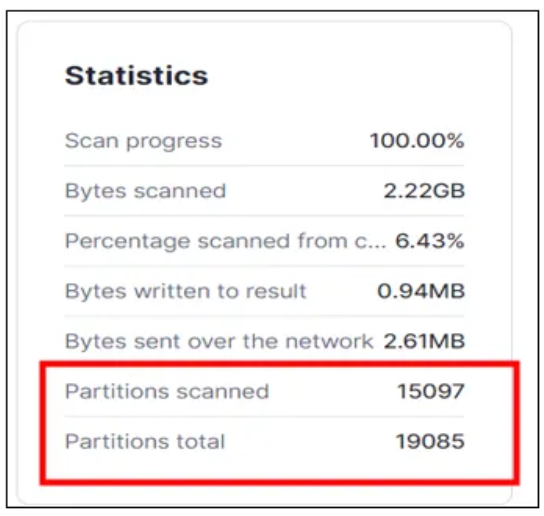
图 2b:图 2a 查询的分区扫描统计信息

图 2c:在子查询中引用表的查询
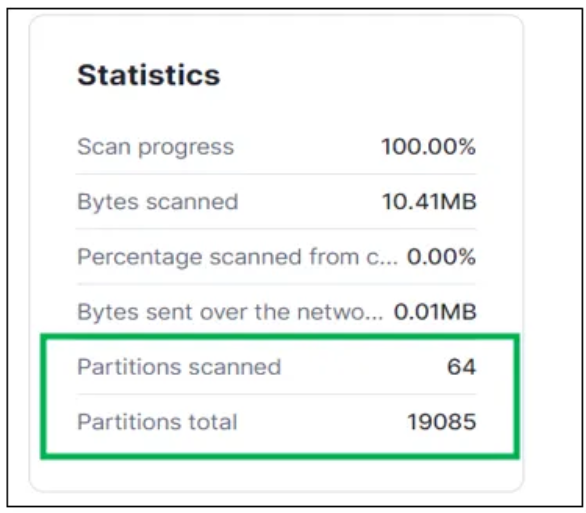
图 2d:图 2c 查询的分区扫描统计信息
尽管目前尚未完全理解决策是否应用 JoinFilter 的精确因素,但我们的实践经验表明,使用视图也可能导致 JoinFilter 的缺失。
让我们通过一个示例进行说明:
图 4 展示了优化器为引用视图的查询(图 3)生成的查询执行计划。根据该执行计划,以下是关于 JoinFilter 的统计信息:
基于 PAYMENT 与 MISC_REGISTER_DETAIL 表间的连接,优化器添加了 2 个 JoinFilter 运算符(如绿色所示);
涉及 NOTE_LINES 表的连接操作缺失了 JoinFilter,导致需要从 NOTE_LINES 表扫描约 1.1 亿行和 6500 万行数据;
在小型仓库上的整体执行时间为 65 秒。
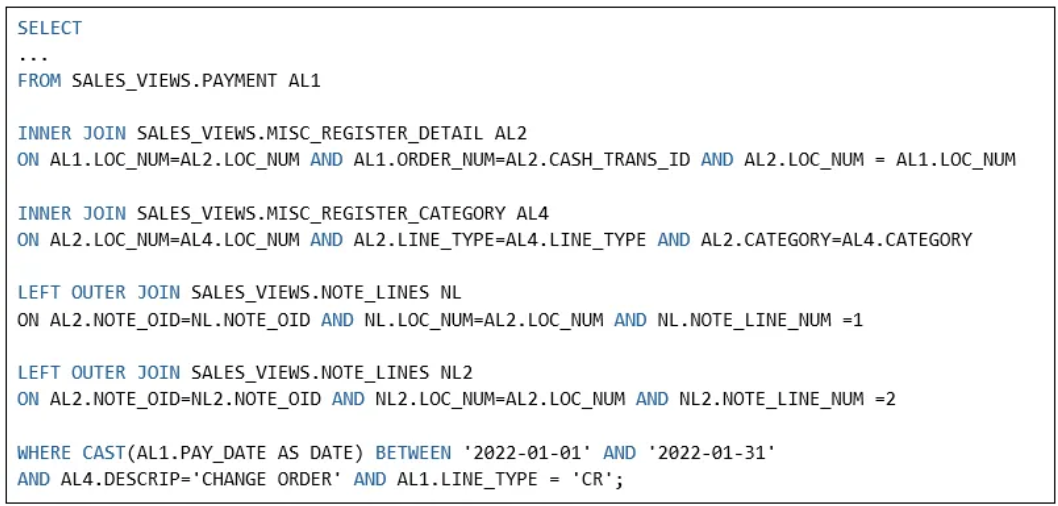
图 3:使用视图的查询
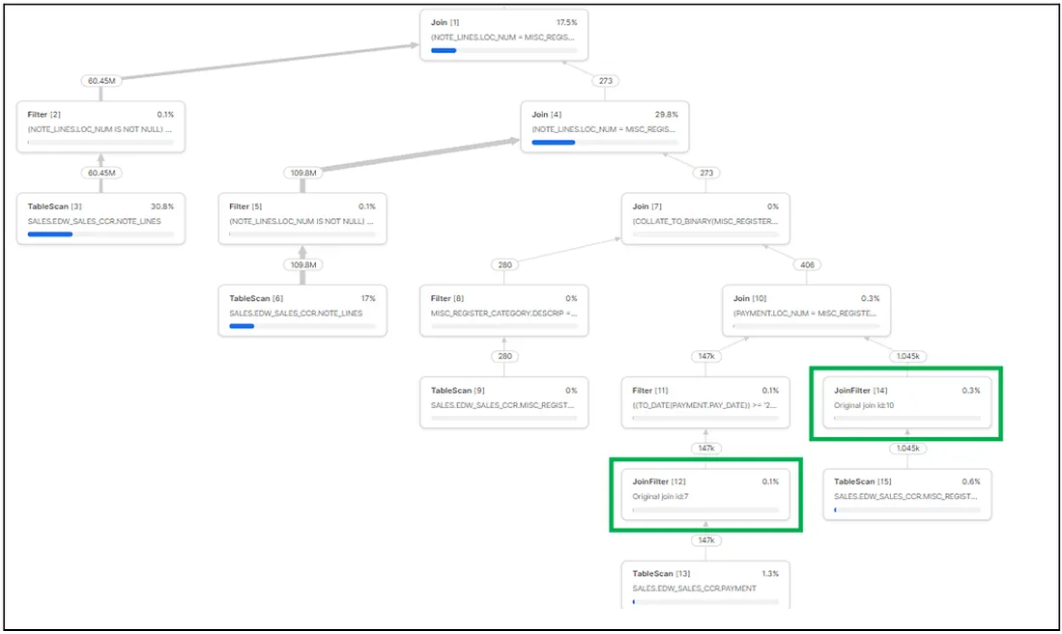
图 4:使用视图时的查询执行计划
现在,让我们分析图 6 中针对同一查询(已重写为使用基表,如图 5 所示)的查询执行计划。我们将此计划与涉及视图的查询执行计划(图 3 所示)进行比较,重点关注 JoinFilter 的存在及其影响:
优化器基于 PAYMENT 与 MISC_REGISTER_DETAIL 表之间的连接添加了 2 个 JoinFilter 运算符;
此次优化器在扫描 NOTE_LINES 表数据时额外增加了过滤条件;
由于额外 JoinFilter 的存在,从 NOTE_LINES 表扫描的行数约为 33.6 万行,而此前为 1.1 亿行;
在小型仓库上的总体执行时间为 30 秒。
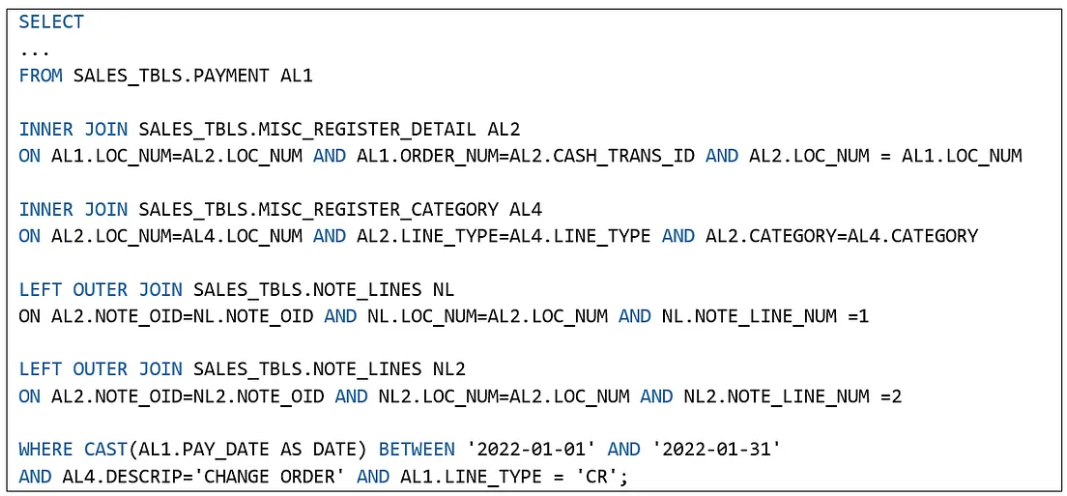
图 5:使用基表的查询
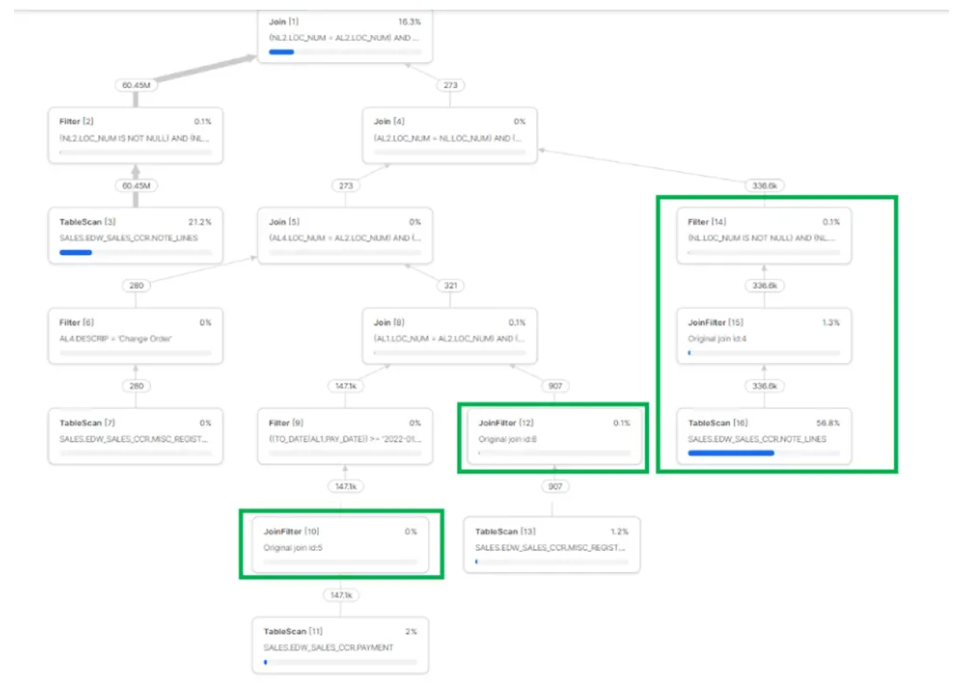
图 6:使用基表时的查询执行计划
通过对比可知,使用基表替代视图会影响查询计划中 JoinFilter 运算符的引入,从而显著提升查询性能。
JoinFilter 优化技术
在接下来的章节中,我们将讨论一种可促使查询优化器添加缺失 JoinFilter 的优化技术,并通过实际案例展示该技术的有效性。
JoinFilter 优化技术通过重构查询语句,引导优化器在执行计划中加入原本缺失的 JoinFilter 运算符。该方法有助于识别可通过添加 JoinFilter 缓解的性能瓶颈。但需注意,在重构过程中要确保所有修改操作不会抵消已获得的性能提升。
识别与引入 JoinFilter 优化的步骤
1、分析高开销节点——检查执行计划中开销最高的节点,识别潜在问题。
2、检查连接操作——重点关注高开销节点中的连接操作,定位性能瓶颈。
3、分析连接结构——特别关注以下特征的连接:
a. 其中一个输入分支为另一连接的结果集;
b. 另一输入分支直接读取自数据表。
4、检测 JoinFilter 缺失——若表输入分支未应用 JoinFilter,应考虑重构查询结构。
5、评估行数对比——比较输入与输出行数:若输出/输入比率较低,则表明引入 JoinFilter 可提升性能。
6、重构查询语句——通过临时表等方式重组查询逻辑,促使优化器应用 JoinFilter。
7、循环优化验证——若需进一步优化,可对查询其他部分重复此流程。
8、评估优化效果——确保性能提升程度与重构工作量相匹配。
JoinFilter 优化技术的实际案例与影响分析
为了展示 JoinFilter 优化的实际效果,我们通过公司真实案例进行说明。本案例中,该优化技术使得查询执行时间减少 50%。在 Snowflake 小型数据仓库上,原始查询耗时 45 分钟,而经过优化重构后的查询仅需 23 分钟。
图 7 展示了优化前的原始查询,图 8 则呈现了对应的查询执行计划,其中清晰显示出缺少 JoinFilter 优化。
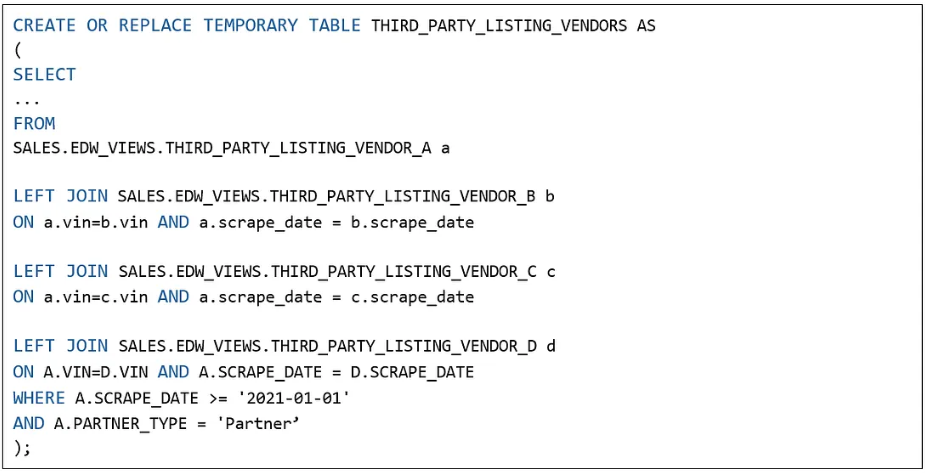
图 7:原始查询
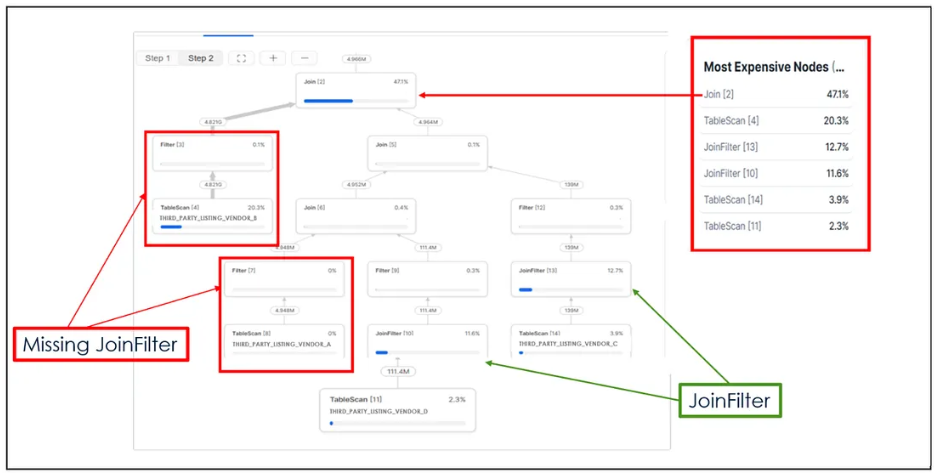
图 8:原始查询性能分析图
原查询涉及四个视图:THIRD_PARTY_LISTING_VENDOR_A、THIRD_PARTY_LISTING_VENDOR_B、THIRD_PARTY_LISTING_VENDOR_C 与 THIRD_PARTY_LISTING_VENDOR_D。

图 8 所示查询的连接顺序
问题
最耗时的节点部分(图 8)显示,与缺少 JoinFilter 运算符的 THIRD_PARTY_LISTING_VENDOR_B 表进行连接操作,约占该查询总执行时间的 50%。为了促使 Snowflake 优化器在从 THIRD_PARTY_LISTING_VENDOR_B 表选择行时应用 JoinFilter,我们将原始查询拆分为两个新查询,分别称为第一部分和第二部分。
解决方案
通过采用此优化技术,原始查询被重新构建并拆分为两部分:第一部分和第二部分。
图 9 和图 10 分别展示了修改后查询的第一部分及其优化器执行计划。如图 9 所示,通过连接 THIRD_PARTY_LISTING_VENDOR_A 和 THIRD_PARTY_LISTING_VENDOR_B 表创建了临时表 THIRD_PARTY_LISTING_VENDORS_TEMP。图 10 显示,对 THIRD_PARTY_LISTING_VENDOR_B 表成功应用了 JoinFilter,使其行选择数量从 40 亿行减少至 1.78 亿行。该第一部分查询在小型仓库上耗时 8 分钟完成执行。

图 9:修改后的查询第一部分
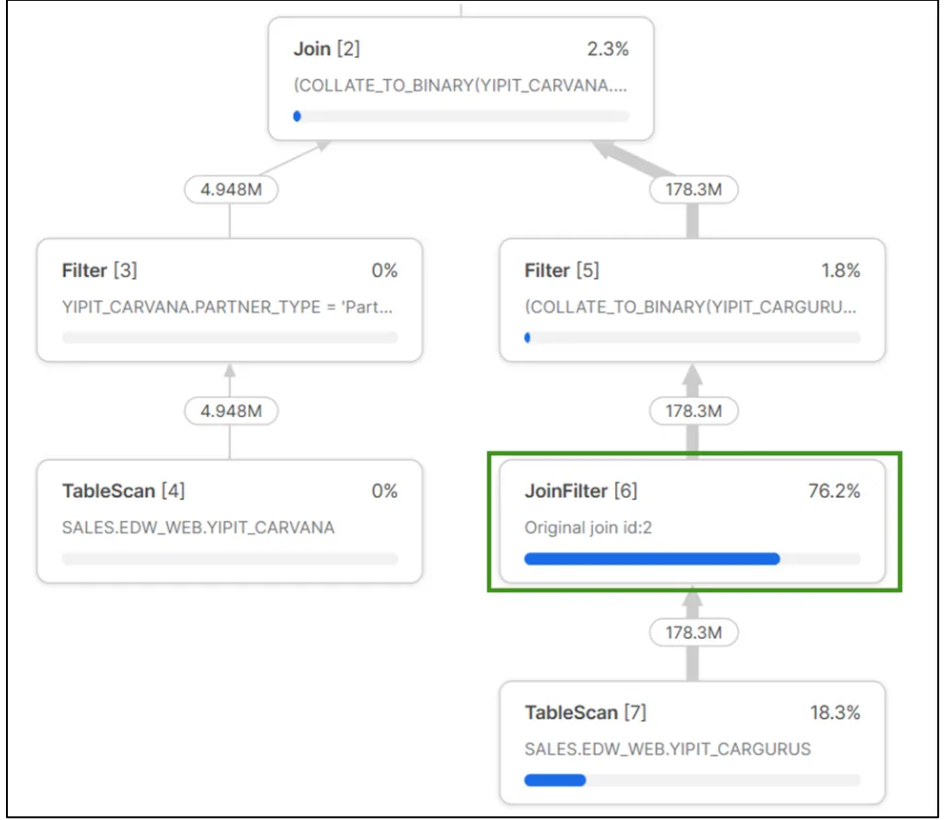
图 10:修改后的查询第一部分执行计划
在修改后查询的第二部分中,临时表 THIRD_PARTY_LISTING_VENDORS_TEMP 与 THIRD_PARTY_LISTING_VENDOR_C 及 THIRD_PARTY_LISTING_VENDOR_D 进行了关联操作。

图 11:修改后的查询第二部分

修改后查询第二部分采用的新关联顺序
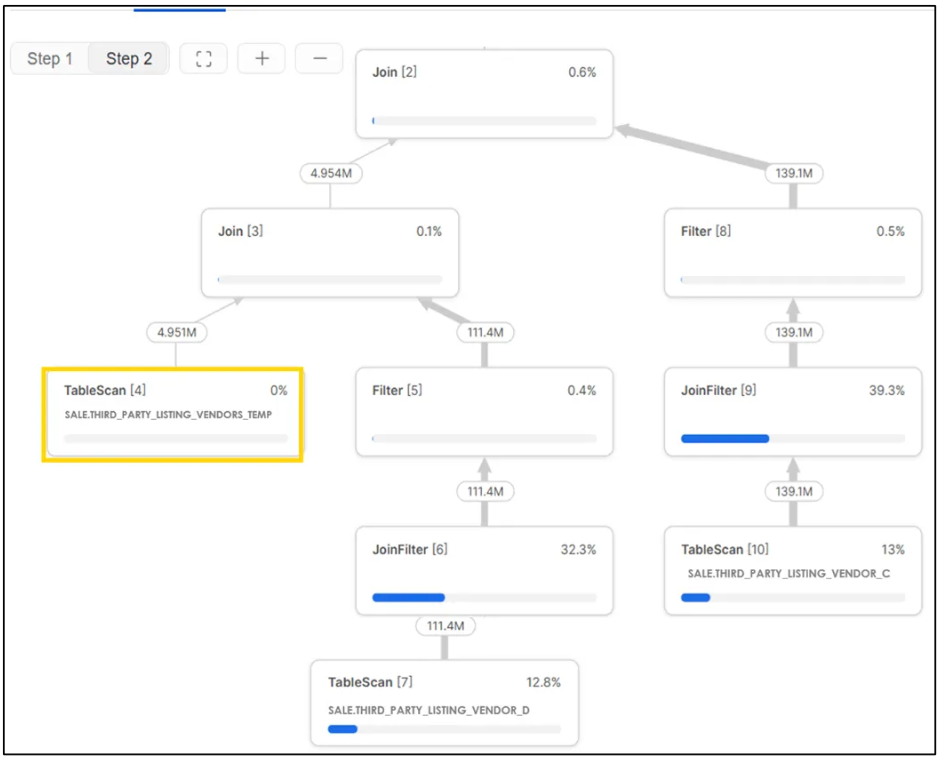
图 12:修改后的第二部分查询执行计划
第二部分在小型虚拟仓库上耗时 15 分钟完成。整体而言,修改后的第一部分与第二部分端到端总执行时间为 23 分钟,相较原始查询实现了 50% 的时间缩减。
结论
本文强调了 JoinFilter 在涉及连接操作的查询中的重要性。我们的研究表明,查询重构能够有效影响 JoinFilter 的应用,特别是在处理视图时。尽管单独使用重构方法已展现出显著改进,但将其与基表结合使用还能进一步提升查询性能。
我们的研究结果为识别和处理 JoinFilter 可能缺失的场景提供了实用指导,并提出了高效引入 JoinFilter 的策略。通过应用这些方法,组织能够优化其数据处理流程,提升查询效率,并在 Snowflake 等云环境中实现成本可控的运营。
点击链接立即报名注册:Ascent - Snowflake Platform Training - China




