
整理 | 华卫、核子可乐
众所周知,大语言模型(LLM)往往对硬件要求很高。近日,软件工程师 Andrew Rossignol 成功在一台“古董”老笔记本 PowerBook G4 上运行了生成式 AI。
据了解,这台笔记本已有 20 年历史,仅配备 1.5 GHz PowerPC G4 处理器和 1 GB 内存,但仍然顺利跑起了 Meta 的 Llama 2 大模型推理任务。此番实验移植了开源 llama2.c 项目,而后使用名为 AltiVec 的 PowerPC 矢量扩展提升性能表现。
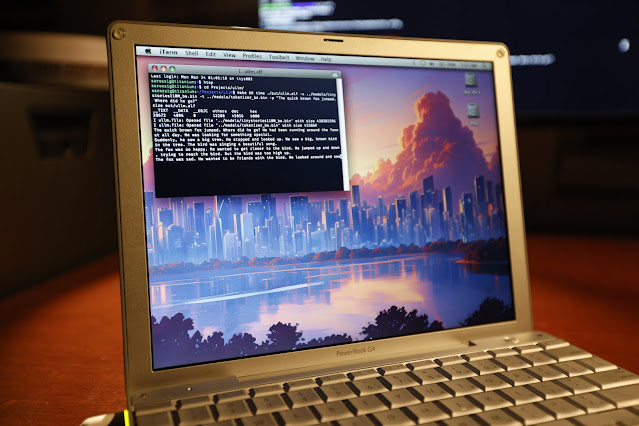
在 PowerBook G4 上运行 TinyStories 110M Llama 2 大模型推理任务。
Rossignol 在一篇博客里,完整介绍了关于此项目的所有过程和更多技术细节。以下是经不改变原意的翻译和整理后的博客原文:
另辟蹊径,慢慢思考:在 PowerPC Mac 上运行大模型
为旧硬件注入新生命永远是件令人心旷神怡的好事,也是我本人的爱好之一。让现代软件在几十年前设计的系统上运行起来,对我总有种难以抗拒的吸引力。而在近年深入研究大语言模型(LLM)的过程中,这种冲动也一直萦绕在我的脑海:能不能把 AI 的前沿技术引入自己那台代表旧日荣光的 2005 款 PowerBook G4 中?借助一块 1.5 GHz 处理器、整整 1 GB 的内存和 32 位寻址空间,我开始了实验并最终取得了成功。而通过在苹果经典笔记本电脑上跑起大模型推理,我们证明即使是陈旧的硬件也完全可以牵手代表未来的 AI 新成果。
我首先选择了 Andrej Karpathy 的 llama2.c 项目——这个出色的项目仅使用一个 C 文件就实现了 Llama 2 大模型推理。其中没有使用到任何加速器,性能完全靠项目的简单性实现,也让我找到了实现推理的基本思路。
我将其核心实现分叉成了名叫 ullm 的新项目。核心算法保持不变,但我花了一些时间对代码做出改进,增强了其稳健性。
代码改进
我从最基础的改进着手,陆续添加了系统函数的打包器,例如文件 I/O 和内存分配机制,借此降低程序检测难度。
引入状态返回,删除所有 exit 调用。
抽象文件访问以简化状态处理。
抽象 malloc/free 以进行简单的调试/分析。
将 512 字节静态 LUT 替换为单字符串。
修复了使用-Wall 编译时的一些警告提示。
从库入手
我把代码组织成库以便于大规模修复,这套库具有由标头公开的公共 API,因此可以进行单元测试、确保进一步重构不致破坏其推理功能。
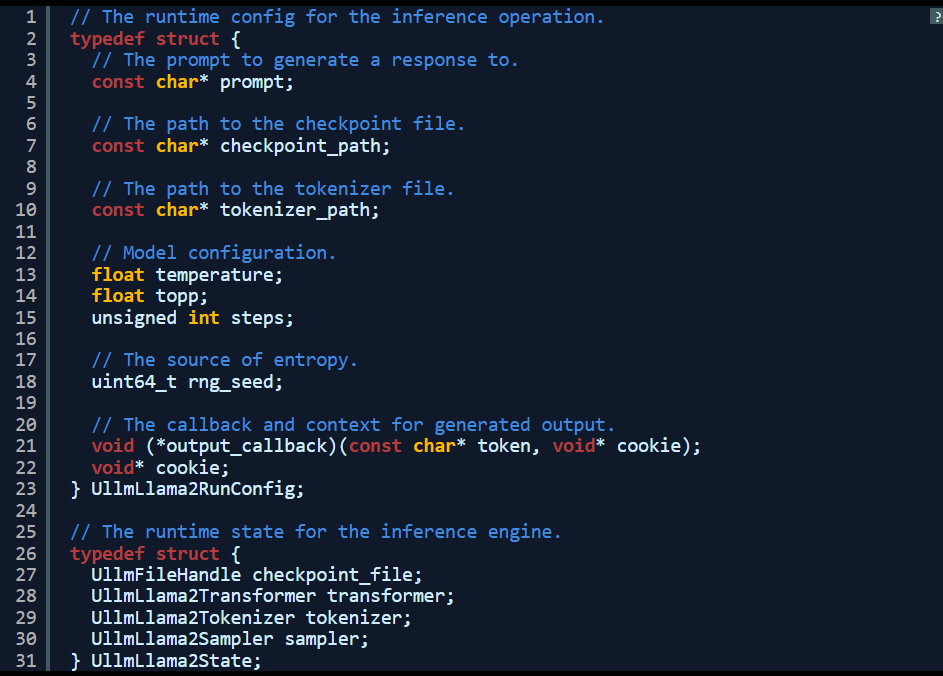
该库需要两条输入:其一为 const config,负责提供模型路径、rng seed 与 token 输出回调等细节信息;其二则是 state,负责跟踪加载权重、临时缓冲区和 tokenizer 状态等。
生成的 API 测试起来非常简单,并可轻松为其构建命令行界面工具。
基于回调的输出与测试
由于迁移至公共 API,因此我们可以轻松使用回调替换掉基于 printf 的输出,这样就能让推理引擎持续生成 token。这也是后续实现端到端推理管道集成测试所必需的最后一条变更。
内部结构
除了公共 API 之外,我还重新组织了其内部结构。在改进之后,代码变得相对优雅,同时删除了所有 exit 调用,以便在初始化或推理过程中失败时进行状态传播。

移植到 PPC
为了适应运行 gcc 4.x(大家没看错)工具链的 PowerPC Mac,我还做了额外的调整。最核心的问题就是 PowerPC 7447B CPU 为大端处理器,而如今发布的模型检查点和标记器则默认使用小端处理器。在首次测试时 malloc 达到 2 GB,明显是出了问题。从种种迹象来看,模型明显是在从文件中读取小端值。
大小端:将模型检查点/标记器从小端转换为大端。
对齐,16 字节:将权重复制到内存中,而非进行内存映射。
性能:AltiVec。
在解决了错误并完成上述结构变更后,我使用 x86 Dell PowerEdge T440 主力机实现了输出奇偶校验。
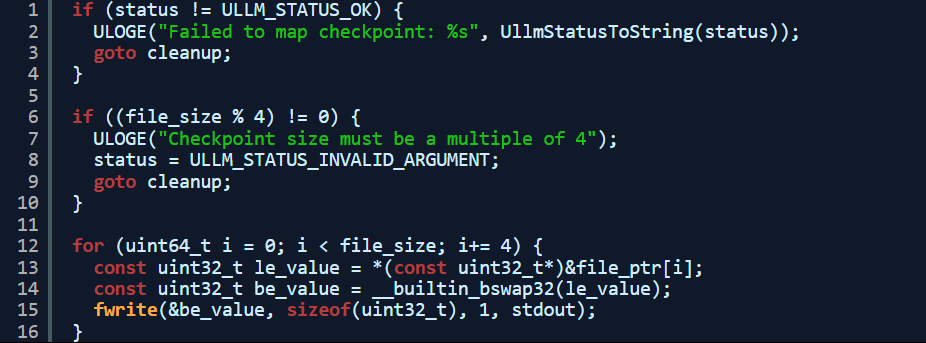
以下是我编写的,用于切换模型检查点的粗略代码:
模型
Llama2.c 项目推荐使用 TinyStories 模型,而且理由非常充分。这些小模型无需任何专门的硬件加速,即可生成特定形式的输出。
在实验中,我使用 15M 模型变体进行了大部分测试,之后又切换到保真度最高的 110M 模型。这已经是上限了,更大的模型要么 32 位寻址空间装不下,要么在现有硬件的 CPU 和可用内存带宽上运行速度太慢。
好消息是,这些模型确实能创作出不少异想天开的儿童故事,读起来那是相当有趣。而由于体量相对较小,它们也让我在调试架构难题时感受相对轻松。
性能
为了在苹果与戴尔硬件间直观比较性能,我选择启用编译器优化(-O2)的单线程推理选项。
在单一英特尔至强 Silver 4216 3.2 GHz 核心上运行推理时,其基准性能结果如下:
I ullm.llama2: Complete: 6.91 token/s
real 0m26.511s
user 0m26.019s
sys 0m0.472s
可以看到,戴尔的成绩是总用时 26.5 秒,每秒平均生成 6.91 个 token(剧透:苹果远远达不到这个水平)。其中 Inference seed 并非随机,所以生成的输出结果在每轮运行中均恒定不变,这就保证了多次运行下的性能间可以直接比较。
好了,使用相同的代码在 1.5 GHz PowerPC 7447B 处理器上运行,PowerBook G4 到底取得了怎样的成绩?
I ullm.llama2: Complete: 0.77 token/s
real 4m0.099s
user 3m51.387s
sys 0m5.533s
虽然速度慢得多,但它仍然成功了!在与拥有更高内存带宽的现代 CPU 相比,PowerPC 的速度大约是其九分之一。老实讲,居然能跟 15 年后的年轻计算机保持在同一性能数量级内,这真的令人印象深刻。
下面我们来看看耗费时间最长的函数:matmul。控制结构的核心在于嵌套循环与乘法/求和。
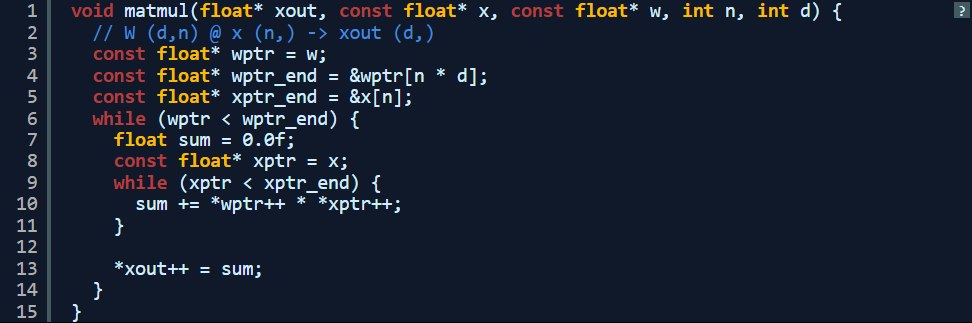
那还能不能做得更好?我记得 PowerPC 处理器支持所谓 AltiVec 矢量扩展,虽然早期版本的处理器扩展比较有限,但确实包含一项可以加快速度的关键运算:融合乘加。使用融合乘加运算,处理器能够执行 4 倍的并行浮点乘法与加法,依靠 SIMD(单指令多数据)语义实现加速。
以下是使用 AltiVec SIMD 扩展重写的同一函数。请注意,这是我第一次编写 AltiVec 代码。在修复了 16 字节对齐问题之后,此代码能够与原始 C 语言版本生成同样的输出。
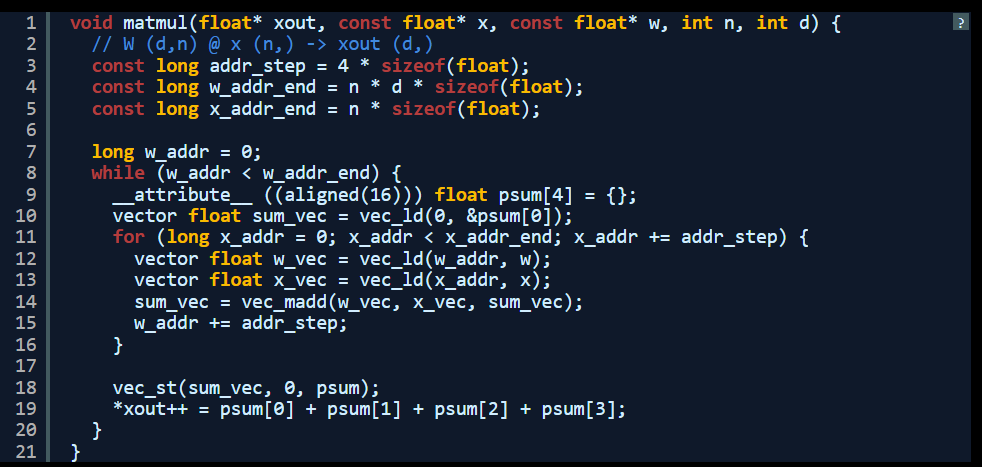
可以看到,这里实际上有 4 个并行求和,之后我在核心乘法求和循环结束时进行了手动求和。
如今网络上几乎找不到多少关于这个古老扩展集的资料,好在 Gemini 给了我不少帮助。另外,官方提供的 PowerPC 文档也还不错,只是与旧版本的 ISA 并不完全匹配。
I ullm.llama2: Complete: 0.88 token/s
real 3m32.098s
user 3m23.535s
sys 0m5.368s
好极了!AltiVec 将推理过程缩短了约 30 秒,让实现速度从戴尔的九分之一变成了八分之一,每秒生成的 token 数量则增加了 10%。爽!
后续探索
Llama2.c 项目还讨论了如何使用相同代码运行具备数十亿参数的模型。虽然颇具吸引力,但遗憾的是 G4 PowerPC 系统是 32 位的,因此最大可寻址内存只有区区 4 GB,运行模型体量的上限也就是这个 110M TinyStories 了。量化技术虽然有肥皂剧帮助,但模型检查点仍然高达 7 GB(不量化则约为 26 GB),还是塞不进可用地址空间。
所以我认为这个项目可以到此结束了。在此过程中,我熟悉了大模型的性质及其操作方式,也深切意识到矩阵乘法正是制约每秒输出 token 数量的最大瓶颈。
所以还是让我的老爷机做它该做的吧:一边听歌一边码字,今天确实辛苦它了。
参考链接:
https://www.macrumors.com/2025/03/24/powerbook-g4-generative-ai/
http://www.theresistornetwork.com/2025/03/thinking-different-thinking-slowly-llms.html




