
Brandon Foley 在 CNCF 博客上发布了一项基准测试研究,证实 AI 编码智能体能够发现并修复孤立的漏洞,但它们通常难以理解系统范围内的影响。这对“改进代码检索是提升自动化漏洞修复能力的主要途径”这一观点提出了挑战。
作者将 AI 编码智能体集成到他的日常工作流中,开展实验来探究这类工具处理真实漏洞时的实际表现。他以 Kubernetes 仓库中的拉取请求作为基准,这些都是真实存在、由实际开发者主动修复的漏洞。每一个智能体仅能获取问题描述,无法借助拉取请求说明与代码差异内容获取解题提示。
三种智能体配置针对九份 Kubernetes 漏洞报告进行了测试,涵盖 kubelet、调度器、网络、存储及应用子系统。第一种使用通过 KAITO RAG 引擎(由 Qdrant 支持)实现的纯 RAG 检索,结合了 BM25 关键词匹配和嵌入向量语义搜索。第二种采用了混合方法,先通过 RAG 完成信息检索,再读取本地文件系统。第三种则完全依靠本地仓库克隆文件,没有检索索引。所有测试流程均使用同款模型 Claude Opus 4.6,统一设置五分钟超时限制与相同的输出格式,唯一变量是每个智能体查阅代码的方式。
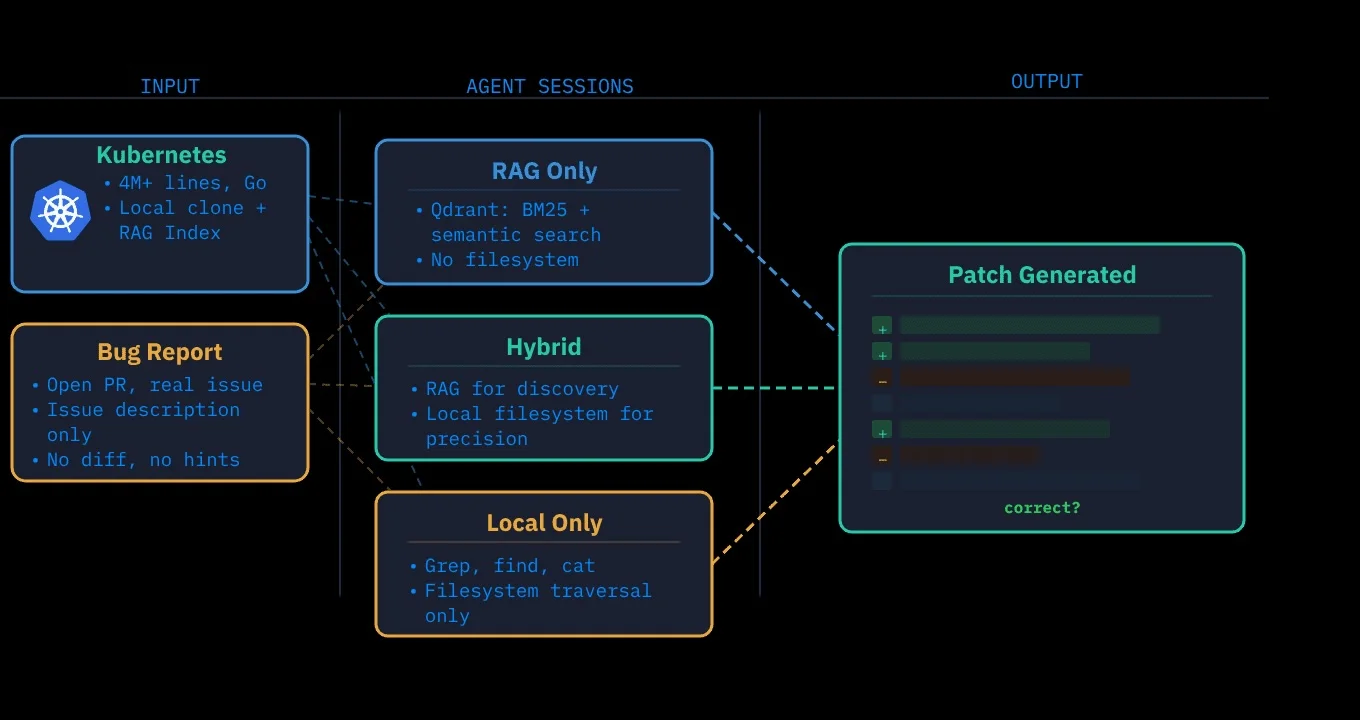
本次基准测试的 AI 智能体配置
在速度和成本方面,结果很明确。纯 RAG 始终是最快的,平均耗时 76 秒,因为它完全跳过了文件系统导航,直接根据检索到的代码片段生成内容。混合方法最慢,平均耗时约两分半钟,因为强制的 RAG 检索在本地查阅代码前额外增加了开销。从词元使用效率来看,混合方法被证明是最昂贵的,不是因为它读取了更多代码,而是因为它进行了最多的模型调用,而且由于 API 是无状态的,每次调用都需要完整的对话历史。在所有测试中,调用次数是影响成本和延迟的最主要因素。
然而,在正确性方面,情况更为微妙。主要的失败情形不是修复不正确,而是修复不完整。智能体解决了“主要”漏洞,但忽略了相关联的变更;修复了一种实现方式,却忽略了第二种;修补了核心问题,但遗漏了依赖集成逻辑中必要的调整,或者在遇到代码库中已存在的部分修复时停止。常见的模式是:智能体不会主动思考还有哪些内容需要同步修改,只要当下问题看似解决,便直接停止。
第二个模式出现在架构选择方面。面临多种选择时,智能体倾向于引入新的抽象,而不是复用现有的抽象。在一个测试案例里,正确的修复使用了已有的 RestartCount 字段,而所有智能体却引入了一个新的 Attempt 字段,功能上虽正确,但让架构变得更为臃肿。
研究表明,检索策略会影响代码信息的查找效率,但不影响推理质量。强制使用 RAG 在某些情况下改善了结果,因为它会迫使智能体在执行修复之前识别出相关的策略评估层,从而产生了更优的架构决策。然而,在识别出相关代码后,智能体会继续进行局部推理;检索有助于导航,但无法帮助其理解系统范围内的影响。
也许最具可操作性的发现是关于问题报告质量的。标注了具体文件、函数和预期行为、描述清晰的漏洞报告让三种方案都达到优异效果,完全抹平了检索策略之间的性能差异。这意味着,人工撰写的问题描述的质量,其影响远大于检索架构的选择。
该研究发现,作用域发现是 AI 智能体面临的一个关键挑战,也就是识别出所有需要更改的部分,而不仅仅是看起来出问题的地方。这个问题仍然是 AI 大规模运营的主要障碍。结构化的智能体技能或精心策划的执行流程可能会改善系统级推理,但在大型代码库中,这些技能需要持续维护,才能保持与仓库的对齐,这就形成了需要额外运维管理的体系,无法实现一次性完成修复。
查看英文原文:https://www.infoq.com/news/2026/05/ai-agents-kubernetes-rag/




