
当下,智能体正在从“能聊天”走向“能执行”。
OpenClaw 之所以迅速出圈,正是因为它不再只是一个单纯的大模型对话界面,而是能够进一步连接浏览器、工具调用、任务流转与自动执行,让 AI 真正具备“做事”的能力。对于很多开发者、团队和企业来说,这种从问答走向行动的体验,确实足够惊艳。
但真正开始使用之后,很多人先感受到的,并不是效果有多强,而是账单增长得有多快。
OpenClaw 爆火,但很多人先遇到的不是“效果”,而是“账单”
原因并不复杂。智能体和传统单轮问答不一样,它的运行往往意味着更长的上下文、更频繁的模型调用、更多轮次的任务拆解,以及工具执行过程中的持续反馈。
而 OpenClaw 真正容易“烧钱”的地方,往往不只是一次问答本身,而是多轮工具调用带来的连续消耗。当智能体需要反复检索信息、调用浏览器、执行脚本、读取结果再回传模型继续判断时,每一步都在累积 token 成本。任务越复杂、链路越长,成本就越容易失控。
我们相对更直观地理解这件事:单次复杂任务可能消耗 50K-100K tokens,按云端 API 计费口径,约等于单次花费 1 元左右;如果进入自动化脚本高频运行阶段,一天触发 100 次以上非常常见,一年下来就是 36500 元以上的持续性支出。
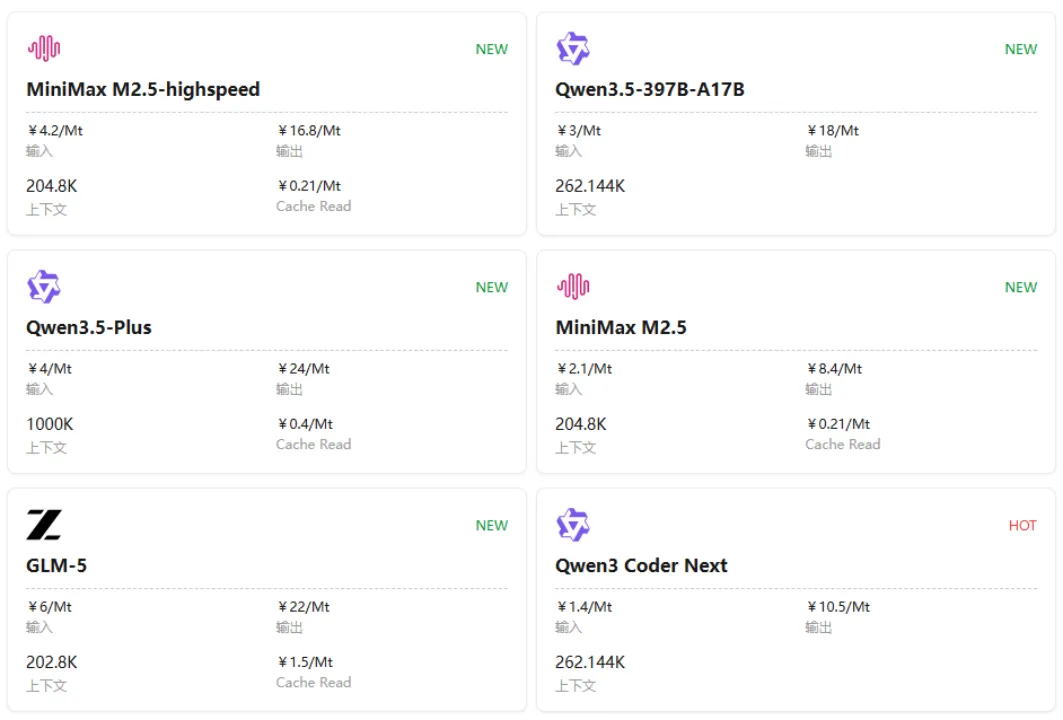
数据来源于网络-仅作参考
这还只是单个任务的成本压力,如果进一步进入多任务工作流,多个环节串联调用、上下文持续累积、执行链路不断拉长,token 消耗和调用次数还会被进一步放大。很多团队真正遇到的问题,已经不只是“能不能跑起来”,而是“这种成本结构能不能长期承受”。
而如果再往前一步,进入多人并行使用的阶段,问题就会更加现实:不同岗位、不同团队、不同场景同时调用,多个“龙虾”叠加成“龙虾军团”,成本就不再只是单点增加,而是成倍放大。
最终远远不只是 3 万多元这么简单,这也是 OpenClaw 爆火背后,一个越来越现实的问题:当智能体开始从尝鲜走向常态化使用,成本必须要“管得住”。
把大模型放本地,OpenClaw 的成本结构就变了
要解决这个问题,关键并不在于放弃智能体,而在于改变它背后的成本结构。
过去,很多 Open Claw 方案的默认逻辑是:前端负责交互,模型能力主要来自云端 API。这样的方式上手快、部署轻,也适合前期体验和快速验证,但成本模型本质上是变量型的——调用越多、上下文越长、任务越复杂,token 消耗就越高,费用也会随之增加。
如果把“大模型脑子”放到本地,这个逻辑就会发生变化。从模型适配角度看,本地部署不是“只能跑小模型”的妥协。

按不同显存档位,常见可选模型大致可以参考这样的搭配,根据你的 GPU 显存以及应用场景推荐以下本地模型:
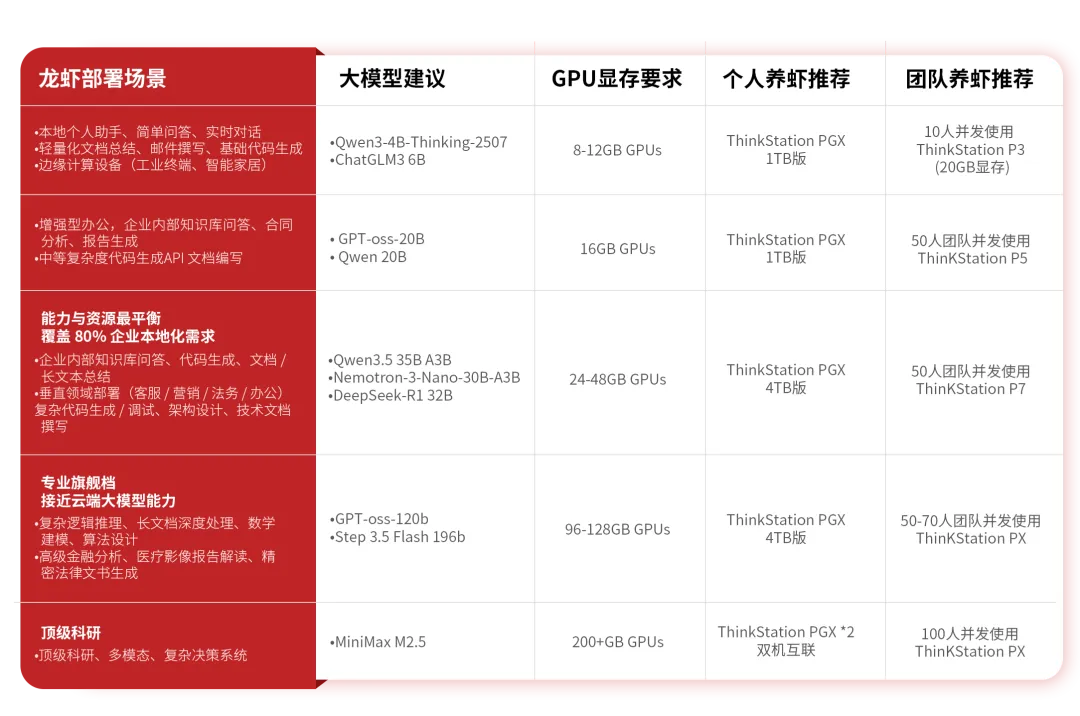
联想 ThinkStation AI 工作站,本地“龙虾”部署第一站
以 ThinkStation PGX 为代表的 AI 工作站本地化方案,带来的不只是“少买一点 token”,而是让 OpenClaw 的底层能力,从持续依赖外部计费,转向基于本地算力的稳定运行。
ThinkStation PGX 配备 128GB 统一内存,可在本地进行最高 200B 参数级模型的推理测试,其 GB10 超级芯片还可提供最高 1 PFLOP 的 FP4 AI 性能。内置 NVIDIA ConnectX™ 网络技术,支持双台互联,由此支撑参数规模高达 405B,它不是一个“勉强跑个本地模型”的轻量尝试,而是真正具备把大模型能力长期放在桌面端的 AI 超级电脑!

同时,ThinkStation PGX 机身小巧便携,整机功耗仅 240W,这意味着即便在本地运行大模型和智能体工作流时,也能更好兼顾性能输出与能耗控制,更适合长期、持续、稳定地放在桌面端使用。基于原生 Linux 系统,并结合 NVIDIA 全栈开发生态,ThinkStation PGX 也为 OpenClaw 提供了更友好的运行环境,让本地模型部署、调用和工作流衔接都更加顺手。
除了 ThinkStation PGX AI 迷你超算电脑,联想 AI 工作站还有更全面的产品线,提供 10 人的团队并发到 200 人以内的团队并发使用,提供开箱即用的 AI 能力,内置不同级别参数大模型,支持行业场景定制,比云更安全,比服务器更简单!
省下来的是成本,守住的更是企业数据安全
比起成本,更值得被强调的是安全,近日官方媒体多次发布“养虾”安全提示。
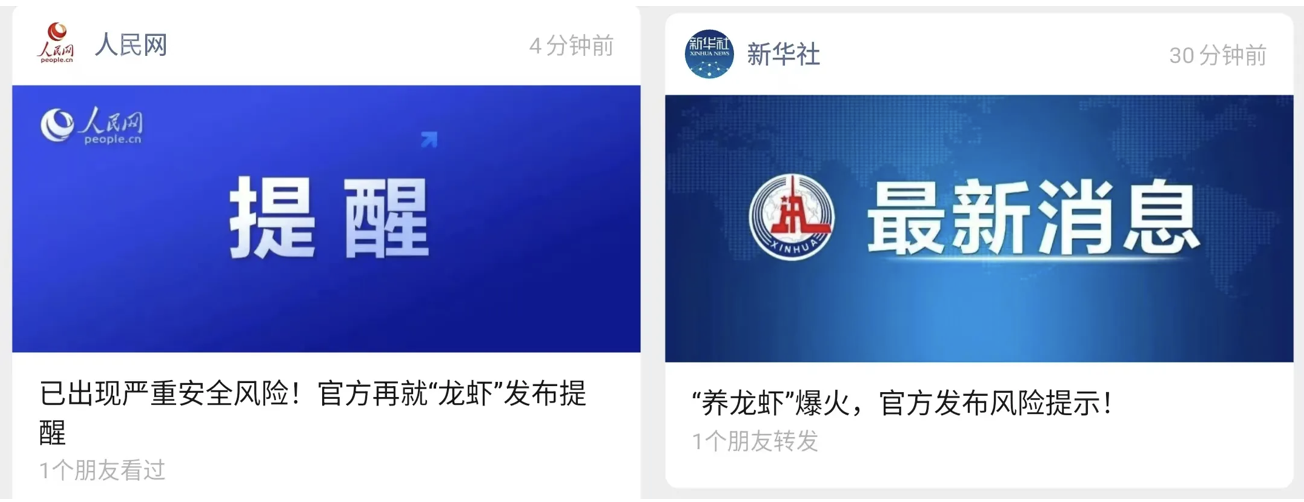
OpenClaw 的能力越强,进入真实业务环境时面临的安全要求也越高。因为一旦它开始接入企业内部资料、业务流程和本地工具链,“操控边界是否清晰、权限是否可控、数据是否可管”成为最重要的安全问题。
把模型放在本地后,很多原本需要传到外部模型服务的上下文、提示内容、知识文档,都可以尽可能留在本地环境中处理。对于涉及内部知识库、流程文档、研发资料、客户信息或本地系统调用的场景来说,这种变化非常关键,因为它直接减少了数据外发和外部依赖带来的风险暴露。

全栈服务能力,安心落地的关键一环
最后,对于企业客户来说,完整、可落地、可持续的服务体系是放心部署,安心落地的关键。联想 AI 工作站在全国拥有超过 1 万名认证工程师,2300 多个专业服务站,100% 覆盖 1-6 线城市,保证 7x24 小时在线支持。
ThinkStation PGX 在中国区还额外享有 3 年一次的硬盘恢复服务,同享 NVIDIA 的专家咨询。高覆盖率和快速响应,为用户提供端到端的全生命周期尊享体验。

联想 ThinkStation AI 工作站家族




