
整理 | 华卫
用一个 PostgreSQL 主库和 50 个只读副本,就顶住了 ChatGPT 上的 8 亿用户!
近日,OpenAI 的工程师们不仅爆出了这一惊人消息,还直接把 Codex 的“大脑”给扒了个精光。在 OpenAI 官方工程博客主页,OpenAI 工程师、Technical Staff 成员 Michael Bolin 发布了一篇文章,以“揭秘 Codex 智能体循环”为题,深入揭秘了 Codex CLI 的核心框架:智能体循环(Agent Loop),并详细讲解了 Codex 在查询模型时如何构建和管理其上下文,以及适用于所有基于 Responses API 构建智能体循环的实用注意事项和最佳实践。
这些消息传出后,在 Hacker News 等技术论坛及社交平台上获得了高度关注。“看似平淡的技术最终会胜出。OpenAI 正在证明,优秀的架构远胜于花哨的工具。”
值得一提的是,有网友透露,前不久 Anthropic 的一位工程师称“他们用于 Claude Code UI 的架构糟糕且效率低下”。而就在刚刚,X 上出现一条爆料:Codex 已接管 OpenAI 100%的代码编写工作。
对于“你们有多少百分比的编码工作是基于 OpenAI 模型进行”的问题,roon 表示,“100%,我不再写代码了。”而此前,Sam Altman 曾公开发帖称,“roon 是我的小号。”
Codex 的“大脑”揭秘
“每个人工智能智能体的核心都是 Agent Loop,负责协调用户、模型以及模型调用以执行有意义的软件工作的工具之间的交互。”
据介绍,在 OpenAI 内部,“Codex”涵盖了一系列软件智能体产品,包括 Codex CLI、Codex Cloud 和 Codex VS Code 插件,而支撑它们的框架和执行逻辑是同一个。
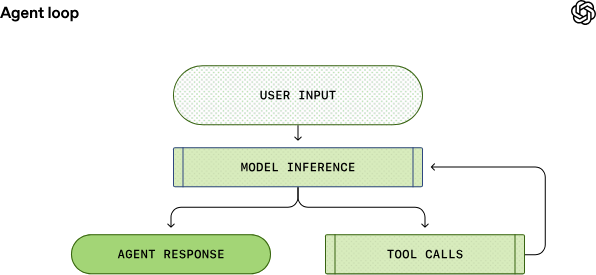
Agent Loop 的简化示意图
首先,智能体会从用户那里接收输入,并将其纳入为模型准备的文本指令集,该指令集被称为提示词。下一步是通过向模型发送指令并要求其生成响应来查询模型,这个过程称为推理。推理过程中,文本提示词首先被转换为一系列输入 token,随后被用于对模型进行采样,生成新的输出 token 序列。输出 token 会被还原为文本,成为模型的回复。由于 token 是逐步生成的,该还原过程可与模型的运行同步进行,这也是众多基于大语言模型的应用支持流式输出的原因。实际应用中,推理功能通常封装在文本 API 后方,从而抽象化词元化的细节。
推理步骤完成后,模型会产生两种结果:(1)针对用户的原始输入生成最终回复;(2)要求智能体执行某项工具调用操作。若为第二种情况,智能体将执行该工具调用并将工具输出结果附加至原始提示词中。该输出结果会被用于生成新的输入内容,再次对模型进行查询;智能体随后会结合这些新信息,重新尝试完成任务。这一过程会不断重复,直至模型停止发出工具调用指令,转而生成面向用户的消息(在 OpenAI 的模型中,该消息被称为助手消息)。多数情况下,这条消息会直接解答用户的原始请求,也可能是向用户提出的跟进问题。
由于智能体可执行能对本地环境进行修改的工具调用,其 “输出” 并不仅限于助手消息。在很多场景下,软件智能体的核心输出是在用户设备上编写或编辑的代码。但无论何种情况,每一轮交互最终都会以一条助手消息收尾,该消息是智能体循环进入终止状态的信号。从智能体的角度来看,其任务已完成,操作控制权将交还给用户。
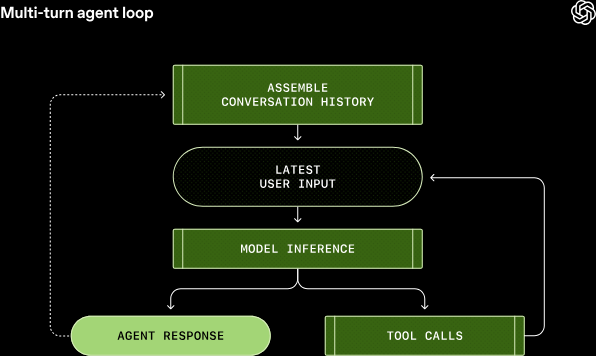
多轮智能体循环
这意味着,对话内容越丰富,用于模型采样的提示词长度也会随之增加。而所有模型都存在上下文窗口限制,即其单次推理调用可处理的 token 最大数量,智能体可能在单次对话轮次中发起数百次工具调用,这有可能耗尽上下文窗口的容量。因此,上下文窗口管理是智能体的多项职责之一。
这套智能体循环如何运行?
据介绍,Codex 正是借助响应 API 来驱动这套智能体循环的,博文曝出许多背后的实际运行细节,包括:
Codex 不会把用户的话直接给大模型用,而是会主动“拼接”出一整套精心设计的提示词结构,且涵盖多个角色的指令、用户输入的一句话在结尾才出现。
模型推理与工具调用之间可能会进行多轮迭代,提示词的内容会持续增加。
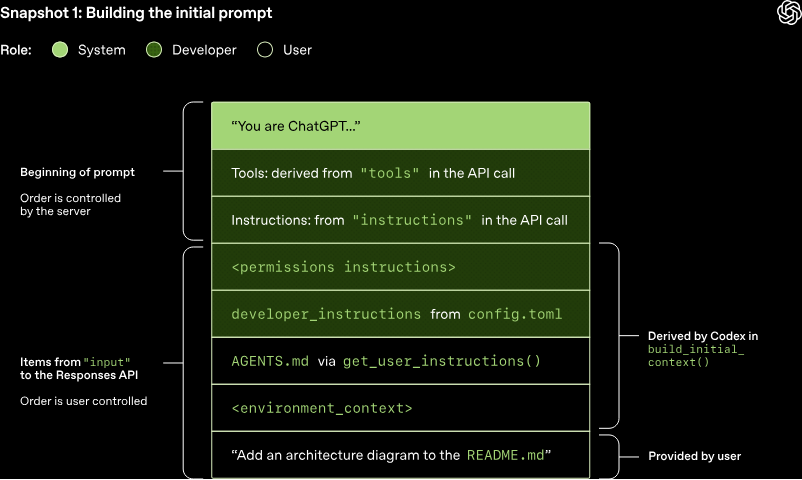
构建初始提示词
作为终端用户,在调用响应 API 时无需逐字指定用于模型采样的提示词,只需在查询中指定各类输入类型,由响应 API 服务器决定如何将这些信息组织为模型可处理的提示词格式。在初始提示词中,列表中的每个条目均关联一个角色。该角色决定了对应内容的权重占比,优先级从高到低分为以下几类:系统、开发者、用户、助手。
响应 API 接收包含多个参数的 JSON 负载,其中三个核心参数有:
指令:插入模型上下文的系统(或开发者)消息
工具:模型生成回复过程中可调用的工具列表
输入:向模型传入的文本、图片或文件输入列表
在 Codex 中,若已配置,指令字段的内容会从~/.codex/config.toml 配置文件中的模型指令文件读取;若未配置,则使用与该模型关联的基础指令。模型专属指令存储在 Codex 代码仓库中,并被打包至命令行工具中。工具字段为符合响应 API 定义的模式的工具定义列表。对于 Codex 而言,该列表包含三部分工具:Codex 命令行工具自带的工具、响应 API 提供且开放给 Codex 使用的工具,以及通常由用户通过 MCP 服务器提供的自定义工具。JSON 负载的输入字段为一个条目列表。在添加用户消息前,Codex 会先向该输入中插入以下条目:
1. 一条角色为开发者(role=developer)的消息,用于描述仅适用于工具部分中定义的 Codex 内置 Shell 工具的沙箱环境。也就是说,其他工具(如由 MCP 服务器提供的工具)并不受 Codex 的沙箱限制,需自行负责实施自身的防护规则。该消息基于模板构建,核心内容均来自打包在 Codex 命令行工具中的 Markdown 代码片段。
2.一条角色为开发者的消息,其内容为从用户的 config.toml 配置文件中读取的 developer_instructions 配置值。
3.一条角色为用户的消息,其内容为用户指令;该内容并非来源于单个文件,而是从多个数据源聚合而来。一般而言,表述越具体的指令,排序越靠后:
加载 $CODEX_HOME 目录下 AGENTS.override.md 和 AGENTS.md 文件的内容
在默认 32 千字节的大小限制内,从当前工作目录对应的 Git / 项目根目录(若存在)向上遍历至当前工作目录本身,加载任意 AGENTS.override.md、AGENTS.md 文件的内容,或加载 config.toml 配置文件中 project_doc_fallback_filenames 参数指定的任意文件内容
若已配置相关技能,则补充以下内容:关于技能的简短引言、各技能对应的技能元数据、技能使用方法说明章节。
4. 一条角色为用户的消息,用于描述智能体当前的运行本地环境,其中会明确当前工作目录及用户所使用的终端 Shell 信息。
当 Codex 完成上述所有计算并完成输入初始化后,会追加用户消息以启动对话。需注意的是,输入中的每一个元素都是一个 JSON 对象,包含类型、角色和内容三个字段。当 Codex 构建好要发送至响应 API 的完整 JSON 负载后,会根据~/.codex/config.toml 中响应 API 端点的配置方式,携带授权请求头发起 HTTP POST 请求(若有指定,还会添加额外的 HTTP 请求头和查询参数)。当 OpenAI 响应 API 服务器接收到该请求后,会使用 JSON 数据来推导出模型的提示信息,(需要说明的是,Responses API 的自定义实现可能会采用不同的方法)。
可见,提示词中前三项的顺序由服务器决定,而非客户端。也就是说,这三项里仅系统消息的内容同样由服务器控制,工具与指令则均由客户端决定。紧随其后的是 JSON 负载中的输入内容,至此提示词拼接完成。
模型采样
提示词准备就绪后,模型才开始进行进行采样。
第一轮交互:此次向响应 API 发起的 HTTP 请求,将启动 Codex 中对话的第一轮交互。服务器会以服务器发送事件(SSE)流的形式进行响应,每个事件的数据均为一个 JSON 负载,其 type 字段以 response 开头。Codex 接收该事件流并将其重新发布为可供客户端调用的内部事件对象。`response.output_text.delta`这类事件用于为用户界面实现流式输出功能,而`response.output_item.added`等其他事件则会被转换为对象,附加至输入内容中,为后续的响应 API 调用所用。
若首次向响应 API 发起的请求返回两个`response.output_item.done`事件,一个类型为推理(reasoning),一个类型为函数调用(function_call),那么当结合工具调用的返回结果再次向模型发起查询时,这些事件必须在 JSON 的输入字段中进行体现。后续查询中用于模型采样的最终提示词结构如下:
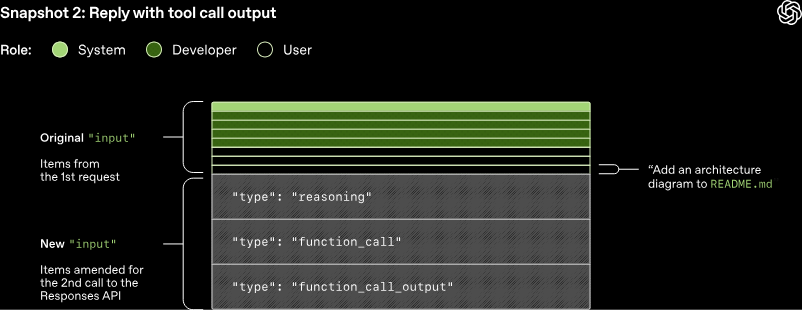
需要特别注意的是,旧提示词是新提示词的完整前缀。这一设计是有意为之的,因为它能让用户借助提示词缓存提升后续请求的效率。
在 Codex 命令行工具中,会将助手消息展示给用户,并聚焦输入编辑区,以此提示用户轮到其继续对话。若用户做出回应,上一轮的助手消息以及用户的新消息均需附加至响应 API 请求的输入字段中,从而开启新一轮对话。同样,由于对话处于持续进行的状态,发送至响应 API 的输入内容长度也会不断增加。
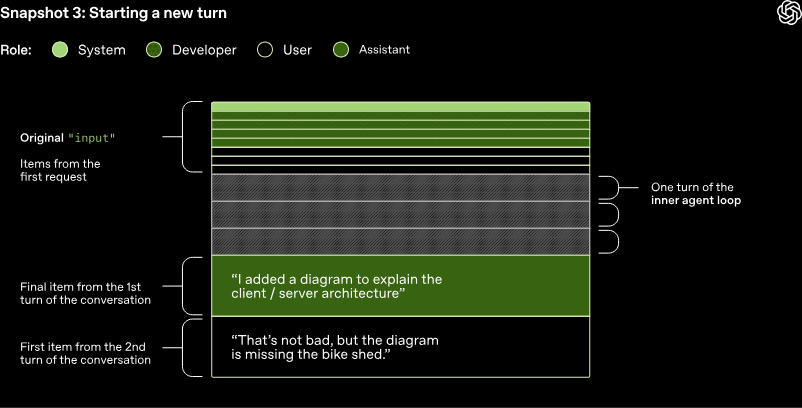
弃用简单参数费力做优化,就为了用户隐私?
“在对话过程中,发送至响应 API 的 JSON 数据量,是否会让智能体循环的时间复杂度达到二次方级别?”答案是肯定的。
据悉,尽管响应 API 支持通过可选的 previous_response_id 参数缓解这一问题,但目前 Codex 并未启用该参数,主要是为了保证请求完全无状态,并兼容零数据保留(ZDR) 配置,即不存储用户对话数据。
取而代之的,是两套需投入大量研发精力、涉及复杂实施流程的技术策略。文中,OpenAI 详细介绍了这两项硬核优化的具体方案。
通常,模型采样的开销远高于网络传输的开销,采样环节会成为优化效率的核心目标,这也是提示词缓存至关重要的原因,它能复用前一次推理调用的计算结果。当缓存命中时,模型采样的时间复杂度将从二次方降至线性。OpenAI 相关的提示词缓存文档对这一机制有更详细的说明:仅当提示词存在完全匹配的前缀时,才有可能实现缓存命中。为充分发挥缓存的优势,需将指令、示例等静态内容置于提示词开头,而将用户专属信息等可变内容放在末尾。这一原则同样适用于图片和工具,且其内容在各次请求中必须保持完全一致。
基于这一原则,Codex 中可能有以下导致缓存未命中的操作:
在对话过程中修改模型可调用的工具列表;
更换响应 API 请求的目标模型(实际场景中,这会改变原始提示词中的第三项内容,因该部分包含模型专属指令);
修改沙箱配置、审批模式或当前工作目录。
因此,Codex 团队在为命令行工具开发新功能时,必须审慎考量,避免新功能破坏提示词缓存机制。例如,他们最初对 MCP 工具的支持曾出现一个漏洞:工具的枚举顺序无法保持一致,进而导致缓存未命中。需要注意的是,MCP 工具的处理难度尤为突出,因为 MCP 服务器可通过 notifications/tools/list_changed 通知,动态修改其提供的工具列表。若在长对话过程中响应该通知,极易引发高成本的缓存未命中问题。
在可能的情况下,针对对话过程中发生的配置变更,他们会通过在输入中追加新消息的方式体现变更,而非修改已有的早期消息:
若沙箱配置或审批模式发生变更,我们会插入一条新的
role=developer消息,格式与原始的条目保持一致;若当前工作目录发生变更,我们会插入一条新的
role=user消息,格式与原始的条目保持一致。
据介绍,为保障性能,OpenAI 在实现缓存命中方面投入了大量精力。除此之外,他们还重点管理了一项核心资源:上下文窗口。
其规避上下文窗口耗尽的通用策略是:一旦词元数量超过某个阈值,就对对话进行压缩。具体来说,会用一个更精简、且能代表对话核心内容的新条目列表替代原有输入,让智能体在继续执行任务时仍能理解此前的对话过程。早期的压缩功能实现方案,需要用户手动调用/compact 命令,该命令会结合现有对话内容和自定义的摘要生成指令,向响应 API 发起查询;Codex 则会将返回的、包含对话摘要的助手消息,作为后续对话轮次的新输入。
此后,响应 API 不断迭代,新增了专用的/responses/compact 端点,能以更高效率完成压缩操作。该端点会返回一个条目列表,可替代原有输入继续对话,同时释放出更多的上下文窗口空间。该列表中包含一个特殊的 type=compaction 条目,其附带的 encrypted_content 加密字段为透明化设计,可保留模型对原始对话的潜在理解。
现在,当词元数量超过 auto_compact_limit 自动压缩阈值时,Codex 会自动调用该端点对对话内容进行压缩。
极限扩容:用 1 个数据库扛住了 8 亿用户
在另一篇技术博文中,OpenAI 工程师 Bohan Zhang 介绍, OpenAI 通过严苛的技术优化与扎实的工程实践,对单个数据库 PostgreSQL 进行深度扩容,实现以单套体系支撑 8 亿用户、每秒数百万次查询的访问需求。
据称,多年来,PostgreSQL 一直是支撑 ChatGPT、OpenAI API 等核心产品的核心底层数据系统之一。过去一年,公司 PostgreSQL 的负载增长超 10 倍,且这一增长趋势仍在持续加速。OpenAI 称,PostgreSQL 的横向扩展能力远超此前行业普遍认知,能够稳定支撑规模大得多的读密集型工作负载。“这套最初由加州大学伯克利分校的科学家团队研发的系统,助力我们通过单主节点 Azure PostgreSQL 弹性服务器实例,搭配分布在全球多个区域的近 50 个只读副本,承接了海量的全球访问流量。”
而且,OpenAI 表示,其扩容在实现规模提升的同时,始终将延迟控制与可靠性优化放在核心位置:生产环境中,客户端 99 分位延迟稳定保持在十几毫秒的低水平,服务可用性达到五个九标准;过去 12 个月内,PostgreSQL 仅出现过一次零级严重故障,该故障发生在 ChatGPT 图像生成功能爆红上线期间,一周内超 1 亿新用户注册导致写流量突发暴涨超 10 倍。
尽管 PostgreSQL 的扩容成果已达预期,OpenAI 仍在持续探索其性能极限。目前,他们已将可分片的写密集型业务负载迁移至 CosmosDB 等分片式数据库系统;对于分片难度更高的剩余写密集型负载,相关迁移工作也在积极推进,以此进一步减轻 PostgreSQL 主节点的写压力。同时,OpenAI 正与微软 Azure 团队展开合作,推动级联复制功能落地,实现只读副本的安全、大规模扩容。随着基础设施需求的持续增长,其将继续探索更多扩容方案,包括基于 PostgreSQL 的分片架构改造、引入其他分布式数据库系统等。
有网友评价道,“这招的高明之处,就在于极简。他们没用什么花里胡哨的冷门技术,不过是把最佳实践做到了极致。过去十年,行业里全是 ‘一切皆分片、拥抱 NoSQL、全面分布式,为 CAP 定理折腰’ 的论调,而 OpenAI 倒好, 服务十亿级用户的解法,居然只是一句‘试过加只读副本吗?’”
参考链接:




