
各位好,我是果诚,一个在互联网大厂摸爬滚打多年的数据从业者。最近 DeepSeek 这股风刮得太猛了,本周末的大事莫过于腾讯于 2025 年 2 月 15 日晚开始灰度测试在微信中接入 DeepSeek-R1 模型。作为一个月活将近 14 亿的国民级 app,表达一个开放的意愿就已经能够让股价火箭上天。而另一面,笔者的朋友圈也都很躁动,众多企业朋友们都在热情入局 DeepSeek。
今天想跟大家聊聊最近比较火的 DeepSeek 私有部署 + Lakehouse 方案。作为一名数据从业者,我想结合自己的经验,跟大家聊聊我的看法。
为什么是 DeepSeek:开放共享与技术演进的双重印证
说到大语言模型,不得不提 OpenAI。作为行业的开创者,OpenAI 用 ChatGPT 展示了大语言模型的惊人潜力。但有趣的是,在技术发展道路上,OpenAI 选择了一条相对封闭的路线。
DeepSeek 选择了一个与众不同的姿态——开放共享。当笔者深入研读 DeepSeek 的技术文档时,不禁为其披露技术细节的诚意所打动。相比之下,回想前几年研究 OpenAI 发布的论文时,核心技术细节往往语焉不详。
对技术感兴趣的朋友,笔者推荐这个材料:逐篇解读 DeepSeek 关键 9 篇论文的播客,相信能帮助我们更好地理解大模型的技术发展路径。(链接放在文章底部)
技术的真正意义,不在于被少数人掌握,而在于能为更多场景创造可能。
回想 2016 年,图灵奖得主 Yann LeCun 在 NeurIPS 会议上提出了著名的"蛋糕比喻",将大型语言模型的发展比作一个三层蛋糕:自监督学习是基础,指令监督微调是提升,而强化学习则是优化。这个洞见在今天看来依然深刻。DeepSeek 在强化学习方面取得了显著进展,并因此获得了性能提升,这可以被视为对 LeCun 路径的一种 印证。(当然,DeepSeek 的成功是多种因素共同作用的结果,LeCun 的路径也并非 LLM 发展的唯一道路,但它提供了一个有价值的参考框架。)
而说到知识记忆能力这个关键维度,Yann 的另一个洞见是,在通往 AGI 的道路上,语言表达能力、知识记忆能力和逻辑推理能力是三个关键维度。
语言表达能力 - 例如 ChatGPT 3.5
逻辑推理能力 - 例如 DeepSeek R1
知识记忆能力 - RAG 这正是我们接下来要探讨的 RAG(检索增强生成)技术…
为什么企业应建立 RAG 知识库:让 LLM 拥有“外挂大脑”
在企业级 AI 应用中,如何让 LLM 更好地理解和利用企业内部知识,是一个关键问题。这时,RAG(Retrieval-Augmented Generation,检索增强生成)知识库就派上了用场。简单来说,RAG 就像是给 LLM 配备了一个“外挂大脑”,让它在生成答案之前,先从知识库中检索相关信息,然后再结合自身知识进行生成。这种方式可以有效提高 LLM 的准确性和可靠性,减少“胡说八道”的情况。
RAG 知识库的简单架构示意:
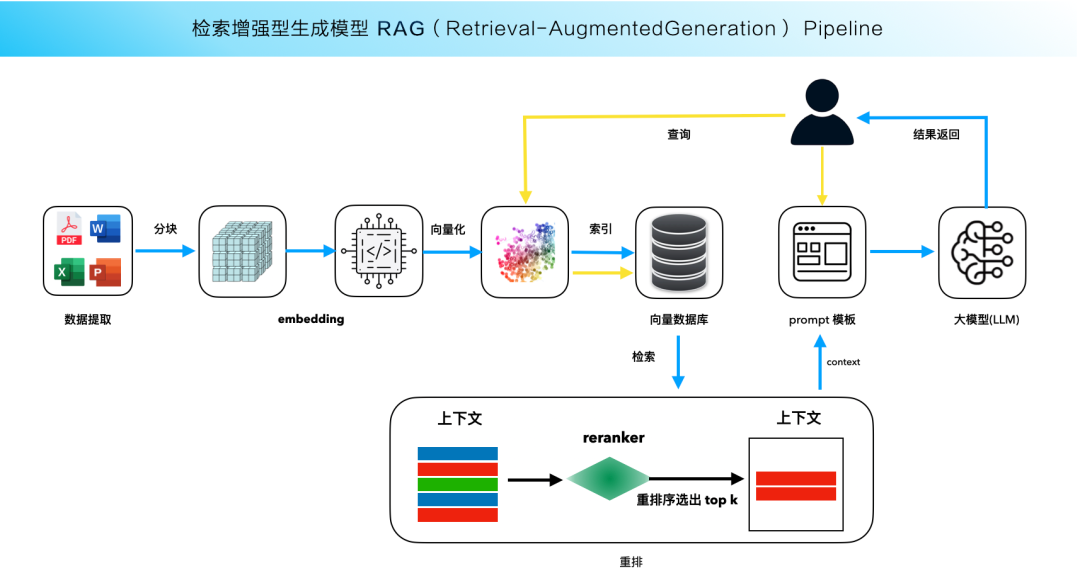
RAG 知识库特别适用于需要访问最新信息、重视透明度和可解释性的应用场景。但同时,RAG 也存在一些局限性,
RAG 知识库的优势与局限性
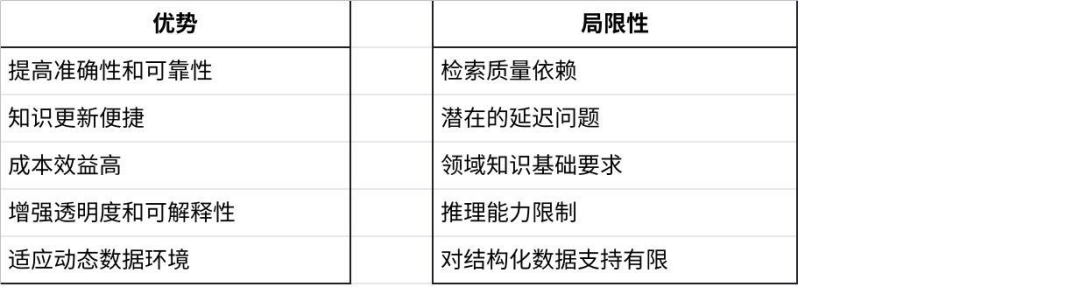
目前,RAG 知识库的构成主要还是以文档和一些半结构化数据为主。那么问题来了,企业的结构化数据又该如何成为 RAG 的一部分,让大模型也能“消费”这些数据呢?特别是那些经过企业数仓 ETL 加工处理过的“可信赖”的数据,如何才能更好地融入 RAG 流程,为 LLM 提供更全面、更准确的知识来源呢?这正是我们接下来要探讨的重点。
新范式:选用湖仓架构作为企业的数据基础底座,让广泛的数据和 AI 结合起来
企业价值密度最高的数据通常是结构化数据!
DeepSeek+RAG+Lakehouse,或是释放数据价值的新思路,前边谈过 DeepSeek 和 RAG,这里我们重点看一下 Lakehouse(一体化湖仓)。很多企业的数据都散落在各个系统里,格式五花八门,想用的时候找不到或很难做统一管理。这就像是盖房子,建材零散混乱彼此隔绝,自然无法有效利用。
一体化湖仓架构的出现,就是为了解决这个数据基建的“资源对接管理”问题。数据湖仓可以把你的结构化数据(比如数据库里的表格)、半结构化数据(比如 JSON 文件)和非结构化数据(比如文档、图片、视频)统统整合起来,形成一个统一的数据平台;它可以把离线任务、实时分析、流式数据处理有机结合在一起;新一代数据湖仓甚至可以把传统的数据分析计算引擎和 AI 也作为数据处理引擎统一起来,对数据进行分析处理。
湖仓架构的演进过程,受篇幅所限笔者这里不展开,只提一个关键点:在选择湖仓架构的时候,建议考察架构的存储是否是必须多套还是统一、元数据管理是多套还是统一。
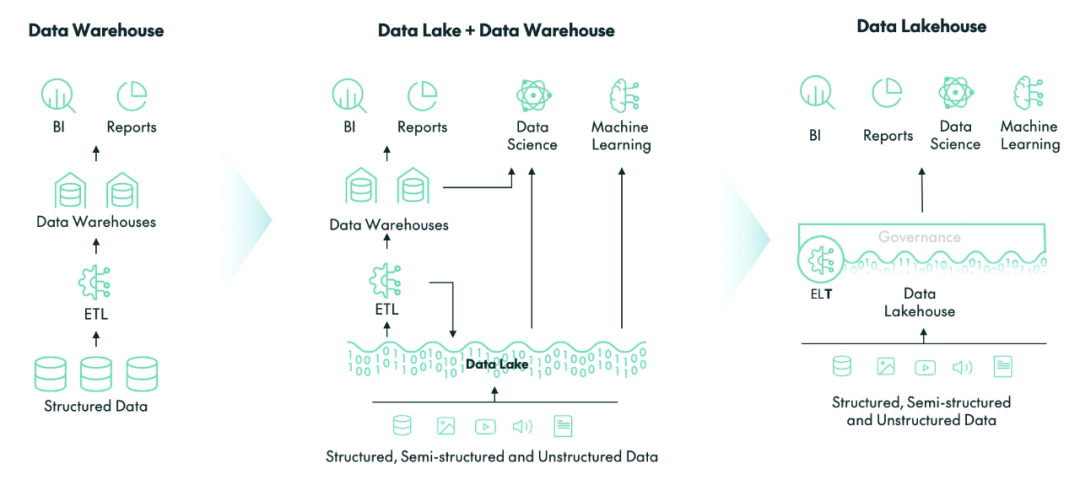
最新一代的湖仓架构的主张是统一存储和统一元数据管理,面向多种负载应用,包括传统数据分析和机器学习,都用同一套数据。这样才能保证数据质量和数据可被信赖,也能大幅减少数据孤岛、数据不一致、数据烟囱等问题。
让湖仓一体 Ready for RAG,建立具备“可信数据”的企业 RAG 知识库
前面说了那么多,可能有些同学还是觉得有点抽象。接下来,笔者就结合具体的方案,跟大家聊聊如何基于 Lakehouse 架构来构建一个具备“可信数据”的企业 RAG 知识库。
这张图展示了 Lakehouse+RAG 构建的知识库架构,以及基于该知识库的 AI 产品功能,例如对话式数据分析工具 DataGPT。
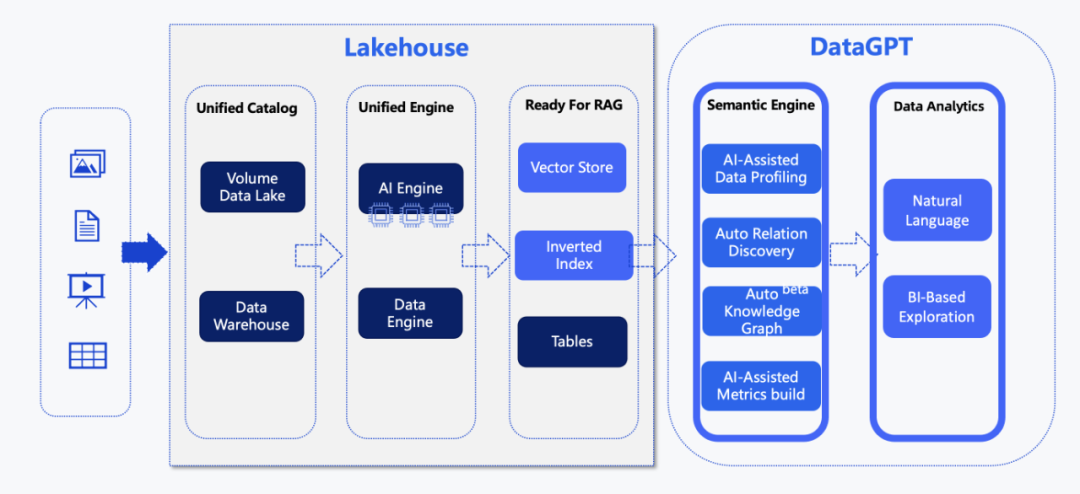
整个流程可以概括为以下几个步骤:
数据入湖仓:来自多源、多类型的数据通过各种方式进入 Lakehouse 。在这个过程中,元数据会被统一管理,并且会按照数仓的权限体系进行访问控制,确保数据的安全性。同时,数据会通过 Lakehouse 的一体化引擎(Single Engine)以及 AI 引擎进行转换和信息提取。
数据处理与存储:通过数据与 AI 处理引擎,从结构化、非结构化数据中提取关键信息,并以以下三种形式存储在 Lakehouse 系统中:
表(Table):存储结构化数据,方便进行查询和分析。
向量(Vector):将文本、图像等非结构化数据转化为向量形式,用于语义搜索和相似度计算。
倒排索引(Inverted Index):用于快速查找包含特定关键词的文档。
RAG 就绪层:这也是整个架构的关键所在。在这一层,通过语义引擎进行自动化的数据特征分析、知识图谱构建、指标自动化提取等操作。简单来说,就是为 RAG 做好数据准备,让 LLM 能够更好地理解和利用这些数据。关于向量和倒排索引的使用方法,可以参考相关文档(向量:https://www.yunqi.tech/documents/vector-search 、倒排索引:[https://www.yunqi.tech/documents/inverted-index])。
在这个流程中,DeepSeek 等 AI 模型的能力被充分利用,助力数据平台处理各种类型的数据,为 RAG 知识库的构建奠定坚实的基础。
笔者认为,这个架构的亮点在于它将数据处理和 AI 能力紧密结合,可以实现了“数据 Ready for AI”。通过 Lakehouse 的统一数据管理和 AI 引擎的智能处理,企业可以构建一个高质量、可信赖的 RAG 知识库,为 LLM 提供更全面、更准确的知识来源,从而提升 AI 应用的效果。
DeepSeek+RAG+Lakehouse 结合实现企业自有的 AI 函数、对话式分析、文档问答
通过与 DeepSeek 等 AI 模型深度集成,Lakehouse 还可以实现企业自有的 AI 函数
AI 函数:让“大模型”批量处理数据
将 DeepSeek 作为函数集成到数据处理流程中,实现 AI 辅助的数据清洗、转换、分析等功能。这就像是给数据处理流程装上了一个可以批处理的“大模型”计算引擎。
举个例子,企业可以批量使用 DeepSeek 对客户评论进行情感分析,自动识别正面、负面和中性评论。然后,将情感分析结果添加到客户数据中,为后续的客户关系管理提供更精准的支持。
为了让大家更直观地了解 AI 函数的用法,下面笔者将展示如何使用 SQL AI 函数,调用 DeepSeek R1 来处理一道数学题。众所周知,大模型有相对更强的语言能力,但数学能力偏弱,DeepSeek R1 作为推理模型,能够有更好的数学能力提升,比如解决经典的 9.11 和 9.9 哪个数更大的问题:
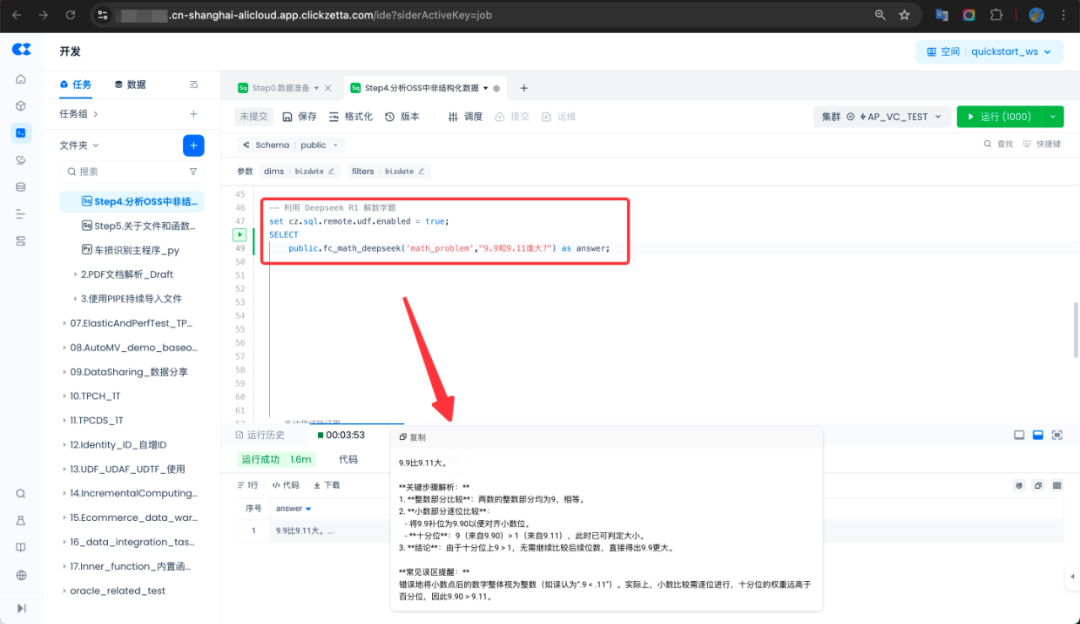
将下面的程序,以及依赖包(Python 3.10)打包成 zip,并按照文档描述上传至对象存储如 OSS,再创建函数即可。具体步骤请参考(https://www.yunqi.tech/documents/RemoteFunctionDevGuidePython3)
实现功能的程序代码为(调用阿里云百炼平台的 DeepSeek r1 满血版)
Pythonimport sysfrom openai import OpenAIfrom cz.udf import annotate# 百炼通过 OpenAI SDK 或 OpenAI 兼容的HTTP方式快速体验DeepSeek模型。client = OpenAI( api_key='xxxxx', # 请替换为有效的 API Key base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")@annotate("string,string->string")class fc_deepseek: def evaluate(self, service_type, input_text): if service_type != "math_problem": return "Invalid Service Type" try: completion = client.chat.completions.create( model="deepseek-r1", messages=[{'role': 'user', 'content': input_text}] ) return completion.choices[0].message.content if completion.choices else "无法获取答案" except Exception as e: return f"计算错误: {e}"如企业想使用私有化部署模型,可以采用模型托管和推理服务如 Ollama, 它可以让你在私有化环境运行 DeepSeek,并允许通过 API 方式 调用它们,它提供了一个兼容 OpenAI API 格式的 HTTP 服务器,比如 http://IP:11434/v1/chat/completions。我们只需要修改 evaluate 方法。
当然,在 SQL 环境用大模型处理数学问题,属实是在以计算擅长的传统数据引擎面前班门弄斧了。在实践中,我们更希望通过大模型的能力,补充解决传统数据引擎不擅长的问题。
另外,AI 函数的强大之处在于其灵活性和可扩展性。它不仅可以调用 DeepSeek 等大模型,还可以根据不同的场景需求,调用其他各种类型的模型。例如,下面的函数就是调用视觉模型进行车型识别:
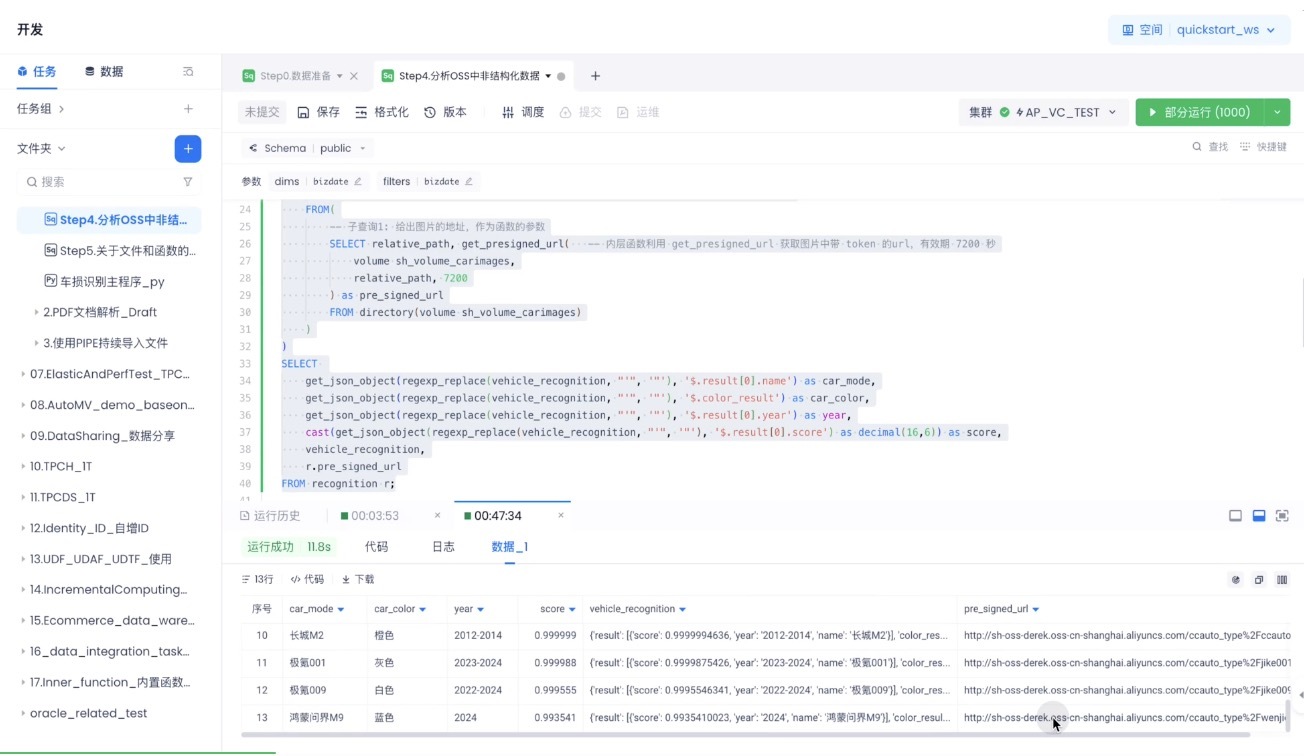

这意味着,企业可以根据自身的业务需求,灵活地选择合适的 AI 模型,构建各种各样的 AI 函数,从而实现更加智能化、个性化的数据处理流程。
数据对话式分析:让数据分析像聊天一样简单
笔者长期关注数据分析领域,我看到对话式分析已经成为了企业数字化转型的一个重要方向。随着知识库 + 推理模型的发展,这个方向又迎来了新的可能性。
采用推理模型 + Multi-Agent 架构的 ChatBI 系统,有比较好的语义理解和执行能力
比如想了解"2020 年,北京哪个区的房价同比增长最大?"这样的问题,系统能直接理解意图并给出分析结果。
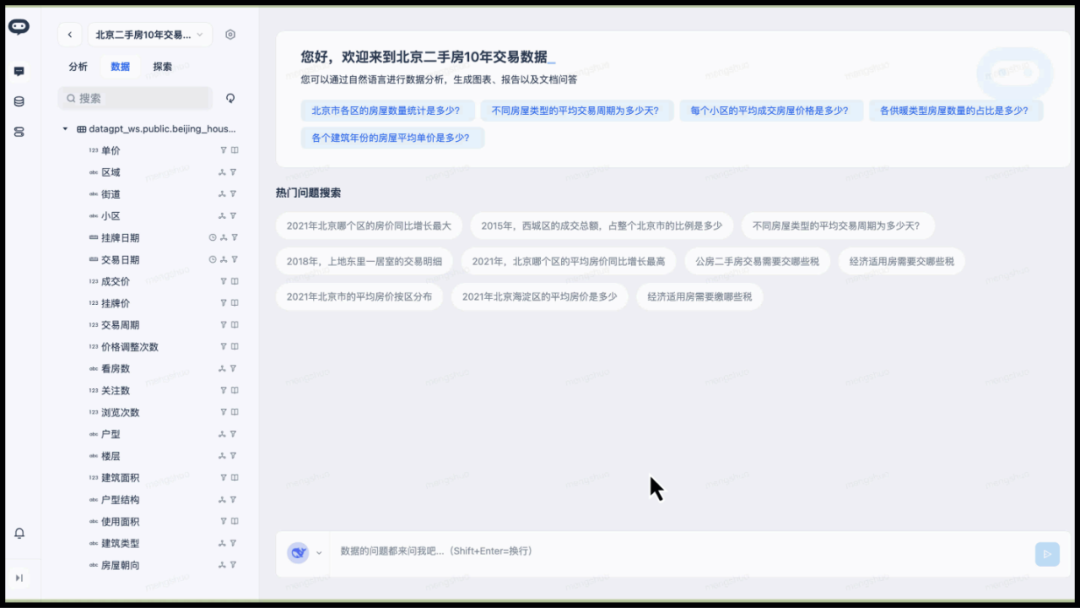
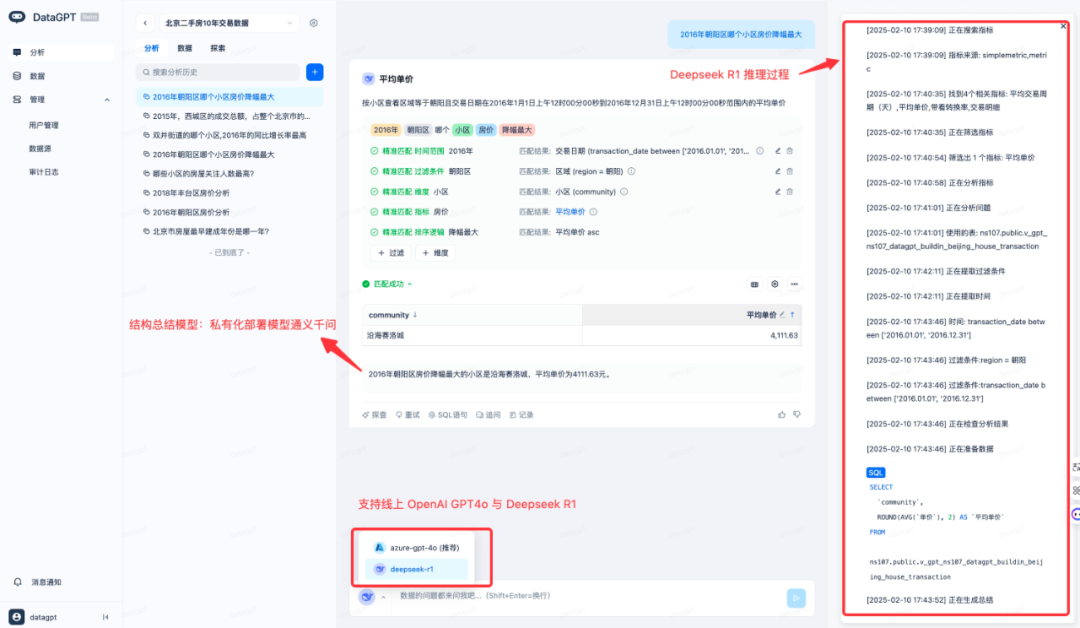
DeepSeek R1 作为推理模型,对 ChatBI 的推理能力也有进一步加强。
本图呈现了 DeepSeek R1 基于 Multi-Agent 架构的创新性推理流程。在接收到用户查询后,系统首先通过意图识别 Agent 精准解析问题本质,随后由指标提取、时间范围解析、维度拆解三大 Agent 并行协作,完成结构化数据的深度挖掘。为保障决策精准度,过滤条件识别 Agent 会动态构建数据约束,能保障自然语言的灵活度。最后通过总结归纳 Agent 生成层次分明的结构化回答。
这种推理模型 + Multi-Agent 架构不仅实现了复杂问题的全链路智能解析,更通过各 Agent 的灵活组合显著提升了系统在商业分析、数据决策等场景下的自适应能力,较传统单线程处理模式效率有大幅提升。
文档问答:DeepSeek 大模型的基础操作
文档问答是大模型非常成熟的应用场景,通过 RAG 可以将企业自有数据喂给大模型,并结合湖仓内的数据做文档和企业自有信息的问答,下面是简单的展示:
总结 DeepSeek+RAG+Lakehouse 这套方案的价值
从最初企业受限于数据合规、定制化和成本等问题,对大模型只能远远观望,到如今企业可以基于 DeepSeek 大模型入局,打造属于自己的“AI 大脑”和 AI 应用。RAG 为“AI ”提供了个性化信息支撑,让企业能够充分利用自身的数字资产。
而 DeepSeek 等私有部署 LLM + Lakehouse 架构的结合,未来或是一种全新的企业级 AI 范式。它不仅解决了合规的问题,还统一了数据要素管理,降低了 AI 应用的门槛;更重要的是,它真正实现了“数据 Ready for AI”,让数据不再是沉睡的资源,而是能够驱动业务增长的强大引擎。
在可以预见的未来,AI 大模型等能力必将愈加普惠,成本将持续降低,使用什么大模型未来将不再是门槛,而拥有关键入口的数据场景,和数据资源将是企业的核心价值。
(附录)
详解 DeepSeek 大模型关键的 9 篇论文的播客,这是目前笔者看到的最好材料之一,由商业访谈录节目制作,强烈推荐欢迎收听收藏

作者简介
苏郡城,云器科技运营总监,云计算大数据领域专家。曾主导阿里云国际业务数据体系建设,十余年一线数据化运营实战,助力企业实现数字化增长,热衷于技术社区分享。
今日好文推荐
中文比 R1 丝滑、玩宝可梦还贼溜?全球首个混合推理模型 Claude 3.7 Sonnet 太惊艳,网友直呼“孤独求败”!




