
我们的一个客户遇到了一个 MySQL 问题,他们有一张大表,这张表有 20 多亿条记录,而且还在不断增加。如果不更换基础设施,就有磁盘空间被耗尽的风险,最终可能会破坏整个应用程序。而且,这么大的表还存在其他问题:糟糕的查询性能、糟糕的模式设计,因为记录太多而找不到简单的方法来进行数据分析。我们希望有这么一个解决方案,既能解决这些问题,又不需要引入高成本的维护时间窗口,导致应用程序无法运行以及客户无法使用系统。在这篇文章中,我将介绍我们的解决方案,但我还想提醒一下,这并不是一个建议:不同的情况需要不同的解决方案,不过也许有人可以从我们的解决方案中得到一些有价值的见解。
云解决方案会是解药吗?
在评估了几个备选解决方案之后,我们决定将数据迁移到云端,我们选择了 Google Big Query。我们之所以选择它,是因为我们的客户更喜欢谷歌的云解决方案,他们的数据具有结构化和可分析的特点,而且不要求低延迟,所以 BigQuery 似乎是一个完美的选择。经过测试,我们确信 Big Query 是一个足够好的解决方案,能够满足客户的需求,让他们能够使用分析工具,可以在几秒钟内进行数据分析。但是,正如你可能已经知道的那样,对 BigQuery 进行大量查询可能会产生很大的开销,因此我们希望避免直接通过应用程序进行查询,我们只将 BigQuery 作为分析和备份工具。
将数据流到云端
说到流式传输数据,有很多方法可以实现,我们选择了非常简单的方法。我们使用了 Kafka,因为我们已经在项目中广泛使用它了,所以不需要再引入其他的解决方案。Kafka 给了我们另一个优势——我们可以将所有的数据推到 Kafka 上,并保留一段时间,然后再将它们传输到目的地,不会给 MySQL 集群增加很大的负载。如果 BigQuery 引入失败(比如执行请求查询的成本太高或太困难),这个办法为我们提供了某种退路。这是一个重要的决定,它给我们带来了很多好处,而开销很小。
将数据从 MySQL 流到 Kafka
关于如何将数据从 MySQL 流到 Kafka,你可能会想到 Debezium(https://debezium.io)或 Kafka Connect。这两种解决方案都是很好的选择,但在我们的案例中,我们没有办法使用它们。MySQL 服务器版本太老了,Debezium 不支持,升级 MySQL 升级也不是办法。我们也不能使用 Kafka Connect,因为表中缺少自增列,Kafka Connect 就没办法保证在传输数据时不丢失数据。我们知道有可能可以使用时间戳,但这种方法有可能会丢失部分数据,因为 Kafka 查询数据时使用的时间戳精度低于表列中定义的精度。当然,这两种解决方案都很好,如果在你的项目中使用它们不会导致冲突,我推荐使用它们将数据库里的数据流到 Kafka。在我们的案例中,我们需要开发一个简单的 Kafka 生产者,它负责查询数据,并保证不丢失数据,然后将数据流到 Kafka,以及另一个消费者,它负责将数据发送到 BigQuery,如下图所示。
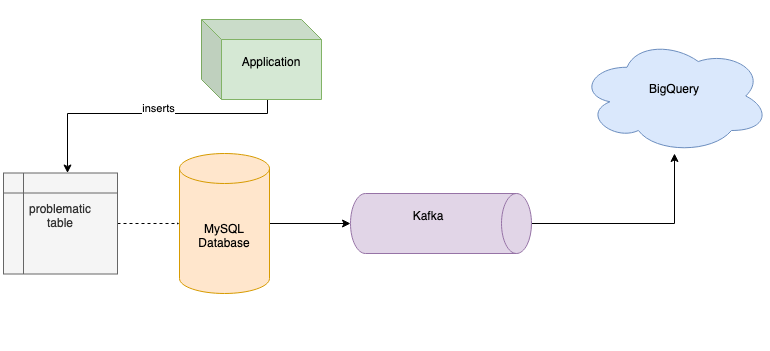
将数据流到 BigQuery
通过分区来回收存储空间
我们将所有数据流到 Kafka(为了减少负载,我们使用了数据过滤),然后再将数据流到 BigQuery,这帮我们解决了查询性能问题,让我们可以在几秒钟内分析大量数据,但空间问题仍然存在。我们想设计一个解决方案,既能解决现在的问题,又能在将来方便使用。我们为数据表准备了新的 schema,使用序列 ID 作为主键,并将数据按月份进行分区。对大表进行分区,我们就能够备份旧分区,并在不再需要这些分区时将其删除,回收一些空间。因此,我们用新 schema 创建了新表,并使用来自 Kafka 的数据来填充新的分区表。在迁移了所有记录之后,我们部署了新版本的应用程序,它向新表进行插入,并删除了旧表,以便回收空间。当然,为了将旧数据迁移到新表中,你需要有足够的空闲可用空间。不过,在我们的案例中,我们在迁移过程中不断地备份和删除旧分区,确保有足够的空间来存储新数据。
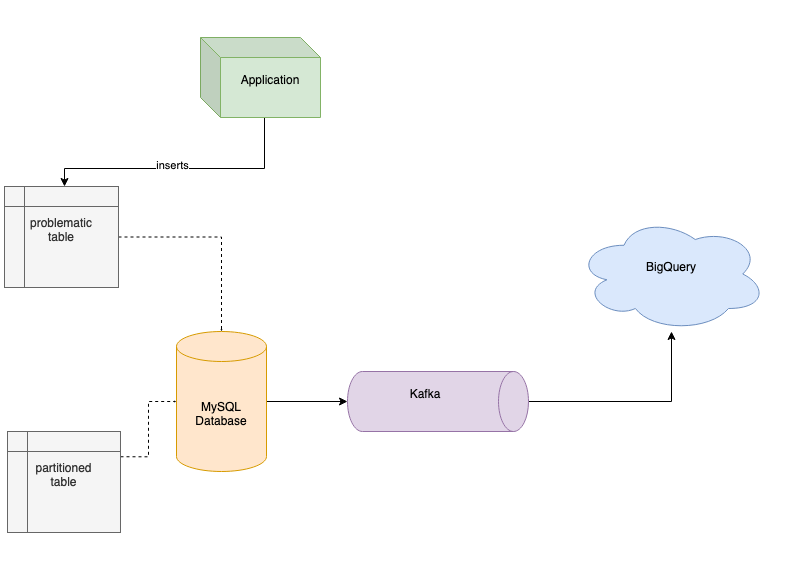
将数据流到分区表中
通过整理数据来回收存储空间
在将数据流到 BigQuery 之后,我们就可以轻松地对整个数据集进行分析,并验证一些新的想法,比如减少数据库中表所占用的空间。其中一个想法是验证不同类型的数据是如何在表中分布的。后来发现,几乎 90%的数据是没有必要存在的,所以我们决定对数据进行整理。我开发了一个新的 Kafka 消费者,它将过滤掉不需要的记录,并将需要留下的记录插入到另一张表。我们把它叫作整理表,如下所示。
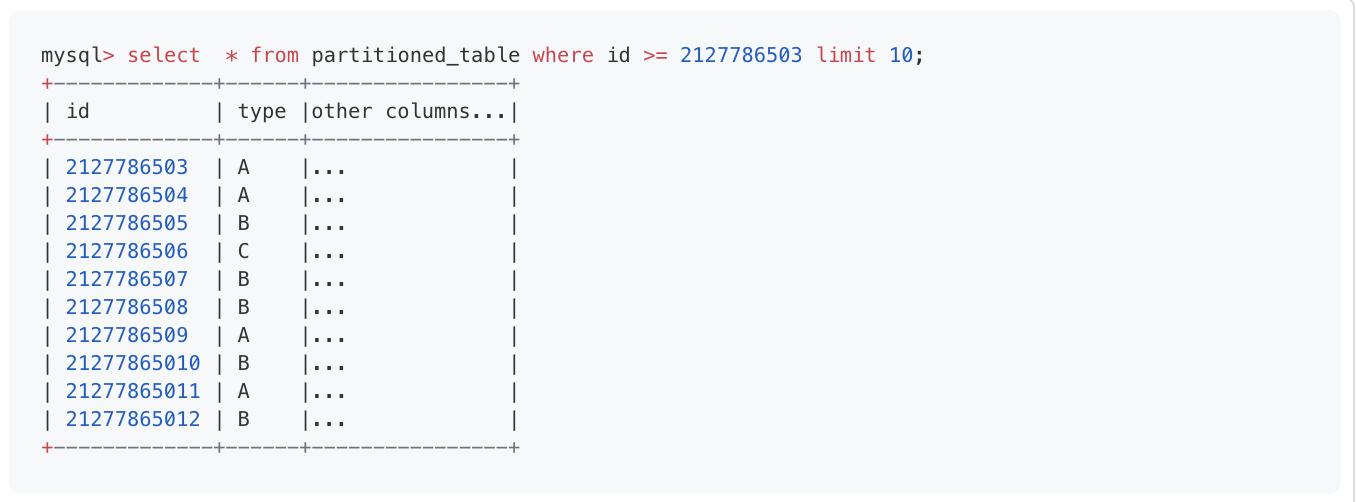
经过整理,类型 A 和 B 被过滤掉了:

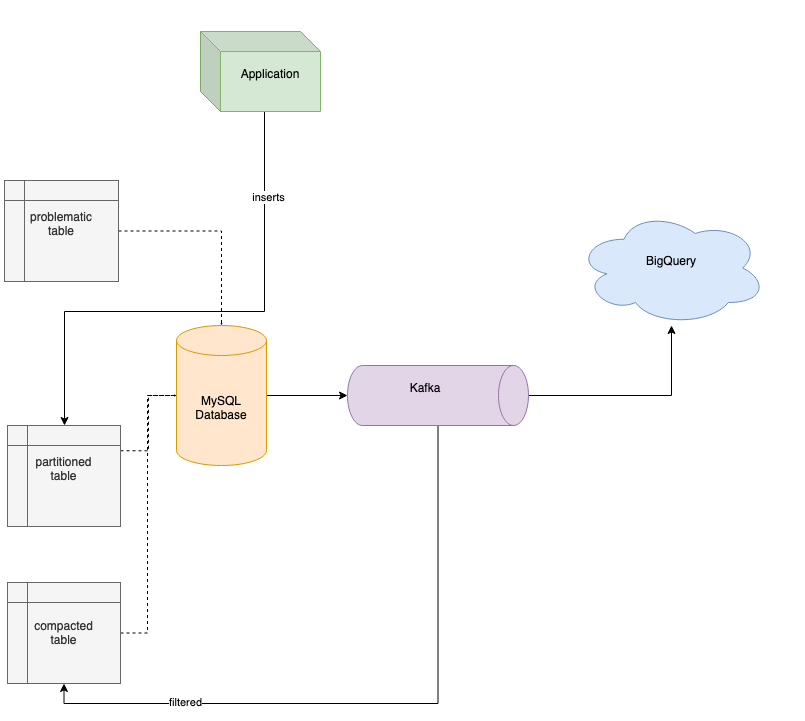
将数据流入新表
整理好数据之后,我们更新了应用程序,让它从新的整理表读取数据。我们继续将数据写入之前所说的分区表,Kafka 不断地从这个表将数据推到整理表中。正如你所看到的,我们通过上述的解决方案解决了客户所面临的问题。因为使用了分区,存储空间不再是个问题,数据整理和索引解决了应用程序的一些查询性能问题。最后,我们将所有数据流到云端,让我们的客户能够轻松对所有数据进行分析。由于我们只对特定的分析查询使用 BigQuery,而来自用户其他应用程序的相关查询仍然由 MySQL 服务器处理,所以开销并不会很高。另一点很重要的是,所有这些都是在没有停机的情况下完成的,因此客户不会受到影响。
总结
总的来说,我们使用 Kafka 将数据流到 BigQuery。因为将所有的数据都推到了 Kafka,我们有了足够的空间来开发其他的解决方案,这样我们就可以为我们的客户解决重要的问题,而不需要担心会出错。
原文链接:




