
AI 已经成为各行各业软件研发的基础,带来了前所未有的效率和创新。今天,我们将分享苏锐在 AWS 量化投研行业活动的演讲实录,为大家介绍 JuiceFS 在 AI 量化投研领域的应用经验,也希望为其他正在云上构建机器学习平台,面临热点数据吞吐不足的企业提供一些启发。
1. 背景
JuiceFS 最初是为了解决互联网行业在云上存储大量数据时遇到的问题。随着 AI 技术的发展,一些使用 AI 进行研发的企业开始关注到 JuiceFS,其中包括量化私募机构,有新兴的量化机构,他们从一开始就在云上构建自己的投研平台,也有一些头部老牌基金,他们正从机房开始向云延伸。
量化投研是一种利用数学模型对大量市场数据进行分析和挖掘,以获取市场行情的规律和趋势,并进行投资决策的投研方法。随着人工智能技术的快速发展,机器学习和深度学习等算法已广泛应用于量化投研,成为金融行业中率先应用人工智能的领域之一。下面这张图显示了量化机构每天的任务数量。黄线代表任务数量的变化情况。我们可以看到任务数量在上班时间内明显增多,而下班时间则明显减少。
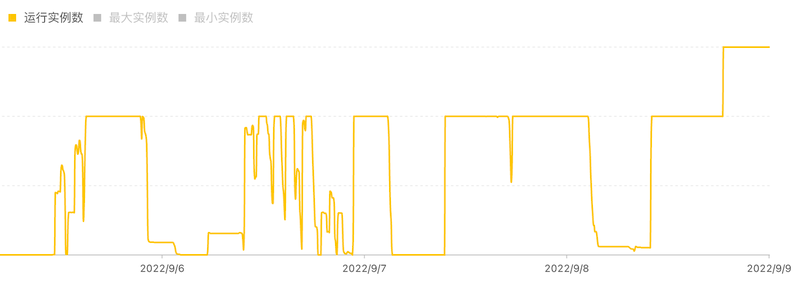
目前,大部分量化私募使用的 IT 资源都是在机房内,CPU 核数、内存和存储等都是固定的。在这种情况下,当面临波动的任务负载时,可能会出现以下问题:
机房提供的是固定算力,在低峰期会有过剩的资源,而在高峰期研究员则需要排队等待,这会导致资源的浪费和效率的降低。研究员希望他们的想法能够尽快得到处理,公司也希望最大限度地利用资源。
突然出现的任务负载增加可能会导致计算资源不足。例如,当研究员有灵感时或者在验证新的论文时,需要进行大规模的验证。此外,当招募新员工或高峰期到来时,计算资源不足也会成为一个问题。
由于机房的扩容周期通常为三个月,而硬件缺货时甚至需要等待六个月,供应链的周期很难满足业务需求。
弹性计算是解决上述这些问题的最简单方法。
2. 弹性计算的优势
在过去的两年中,已经注意到越来越多的量化私募从机房开始转向云端。对于直接在云端构建研究平台的机构,可以直接在 AWS 这样的公有云上进行部署。这样,所有的资源都可以轻松地使用,只需简单地点击鼠标即可启动或关闭,从而大大缩短 time to market 的时间。不再需要等待硬件选型和购买的时间,而且所有的计算资源都可以根据需要进行弹性使用,无论需要多少算力都可以灵活分配。
然而,对于那些已经有一定历史的量化私募机构而言,它们已经建设了大量的 IDC 设施,因此不可能将这些全部放弃,然后转向公有云。因此,它们需要先充分利用这些 IDC 设施,并将其与云计算结合起来。
混合云可能是更多机构要选择的方案。
机房内现有的资产可以作为一个固定算力,满足平均或低峰期的算力需求。增量部分可以在云上进行扩展,使用的资源按秒计费。通过这种方式,机房内已有的资产也能够得到更好地利用。
弹性算力还有一个重要好处,就是可以更快地使用最新的硬件设备。相比之下,如果自己购买硬件,可能需要等待 3 年或 5 年的折旧期限,这使得我们难以跟上硬件的更新换代。弹性算力的好处也在于可以帮助我们更快地跟上技术的发展。
3. 弹性环境中,存储的痛点
计算只是简单的处理过程,而数据则需要进行持久化,因此存储通常比计算更难弹性化。在弹性计算过程中,需要考虑如何保留已经处理的数据,以便后续使用。同时,在扩展算力时,需要确保存储能够支持相应的需求,并具备高可用性和可扩展性。否则,可能会面临数据丢失或性能下降等问题。
痛点一:性能、成本和效率如何取舍?
在进行存储选型时,企业通常会考虑三个因素:性能、成本和效率。这些因素在存储系统的设计中相互影响。在存储选型时需要综合考虑不同方案的优缺点,以找到最适合企业需求的方案。
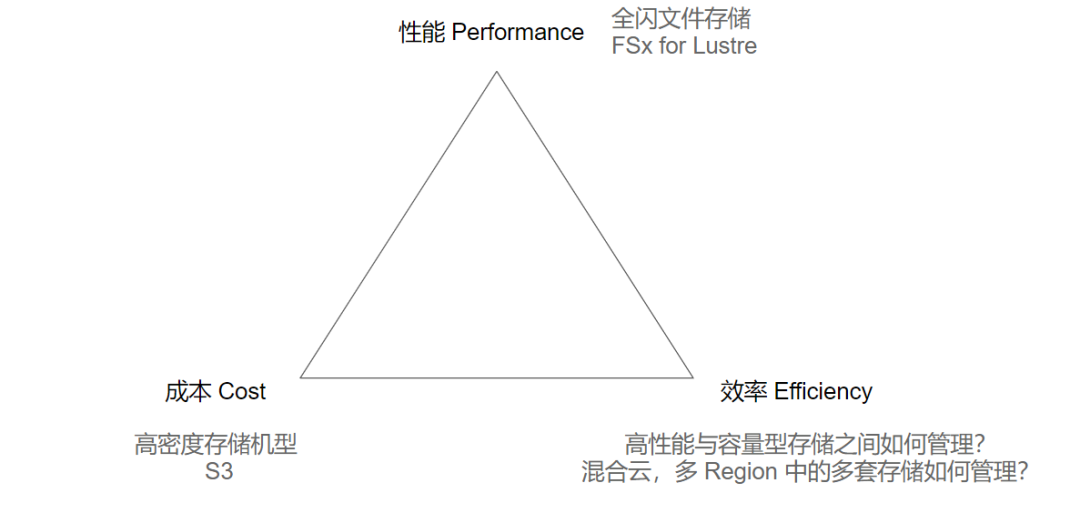
在模型训练阶段,用户通常会追求高性能的存储方案。例如,机房里提供全闪存的文件存储,AWS 上提供 FSx for Lustre 等产品都会选择更高级的硬件,这些方案都能提供出色的吞吐性能。然而,存储成本也较高,因此需要寻找低成本的全量数据归档存储方案。在机房里,一些高密度存储方案也可以降低成本,在云上会选择使用 Amazon S3 等对象存储服务。
为了追求成本和性能,用户在机房和云上都会构建出两套异构的存储。一套低成本的存储系统用于全量归档,另一套高性能的存储则用于模型训练。这种多套存储的环境也带来了管理数据迁移、数据冷热等问题,尤其是在多个区域、多个云环境下,这种情况会变得更加复杂。
因此,我们需要有效的解决方案,既能快速、省钱,同时又能高效地管理存储。
痛点二:存储系统扩容慢
运维过存储系统的人深知存储系统扩容的缓慢。存储系统本质上是一组硬盘,用于存储数据。当需要增加存储容量时,通常的想法增加硬盘。然而,在分布式存储系统中,扩容并不是这么简单的过程,需要对所有数据进行重新平衡,以便更有效地管理存储系统中的所有数据。此外,存储硬件的性能是有限的,如果一部分性能用于数据迁移,就会影响线上业务的服务能力。
举一个简单的例子,我们将一个巨大的存储集群缩小为仅三台机器,每台机器配备两个硬盘,存储一些数据,如下方这个图示。在分布式系统中,为了确保数据的安全,我们通常会将数据复制多份,通常存储三份。下图,圆圈、三角形和菱形各代表一个文件,在分布式架构中,每个图形都有 3 份。
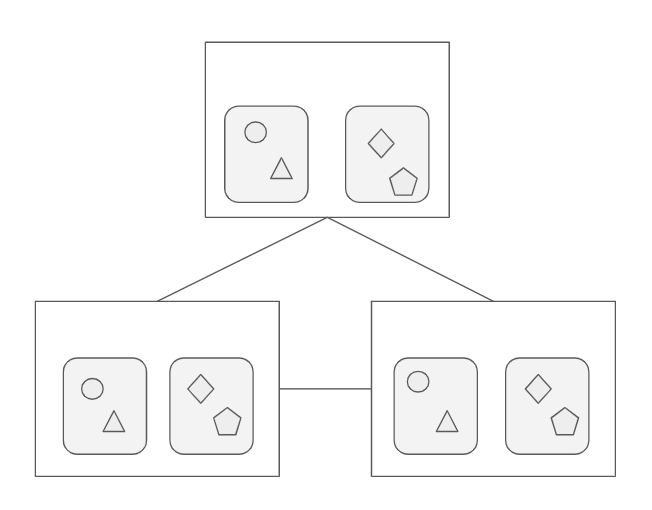
(分布式存储-三备份)
当存储容量不足时,需要加入新的机器,以扩展存储空间。然而,新的数据并不会只存储在新的机器上,而是必须对现有数据进行重平衡以更有效地管理所有数据。在这种情况下,数据会使用一套算法从旧位置移动到新位置。同时,硬盘提供的能力是有限的,如果我们将一部分固定能力用于数据迁移,则无法为线上业务提供服务。
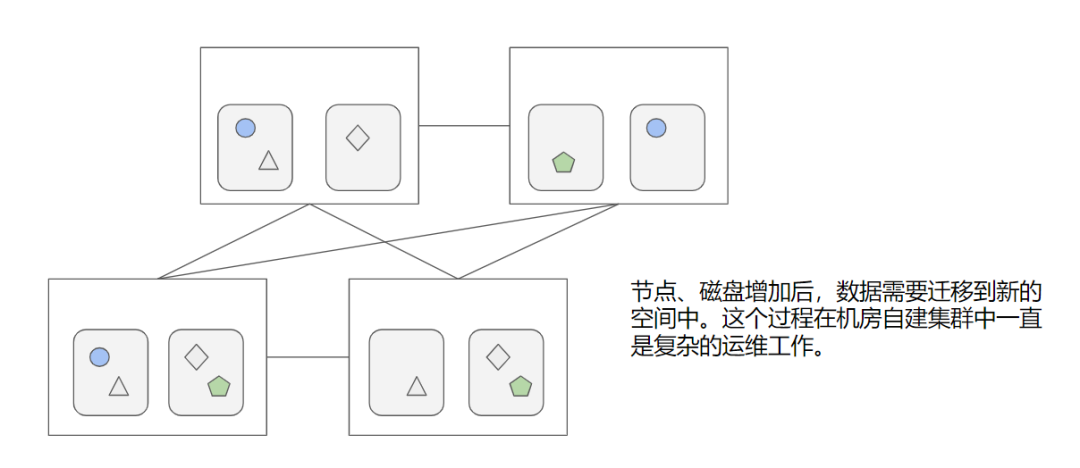
(存储扩容-数据再平衡)
运维工程师们深知存储集群扩容的挑战,选择何时迁移和股票投资中择时一样让人难以预测。如何平稳地搬家,以及如何在不影响线上业务的情况下避免事故,都是一项复杂的任务。仅仅靠自动机制很难完成好,因为业务负载的情况是难以预知的,通常要老司机手动挡干预。除了扩容,当集群中出现了硬盘损坏的情况,就要将其中的数据转移至新的硬盘中,同样要确保每份数据存储了三份。因此,即便不进行扩容,大规模的存储集群仍然需要每天都进行数据搬迁。
在这种困难的存储系统扩容条件下,当新的算法、研究员和灵感出现时,存储通常会成为拖累。
痛点三:可用容量很多,性能不足了,为什么?
之前提到的是容量不足导致需要扩容,但是在量化私募这个领域中,我们发现大部分的客户需要扩容的原因并不是容量不足,而是由于吞吐性能不足。
硬盘提供的性能是有限的,当现有硬盘的性能跑到极限时,就必须购置新的硬盘来满足性能需求。许多量化客户,虽然他们的存储容量还有很大的富余,但为了满足新的性能需求,他们仍需要扩容。
举个例子,假设现在需要读取的数据存储在下图圆圈所示范围,要求性能非常高,那么圆圈所在硬盘的性能已经达到了极限;接着另一个研究员需要读取同样存储在这块硬盘上的三角形,但这块硬盘的性能也已经到了极限,因此读取三角形数据的速度一定会很慢。
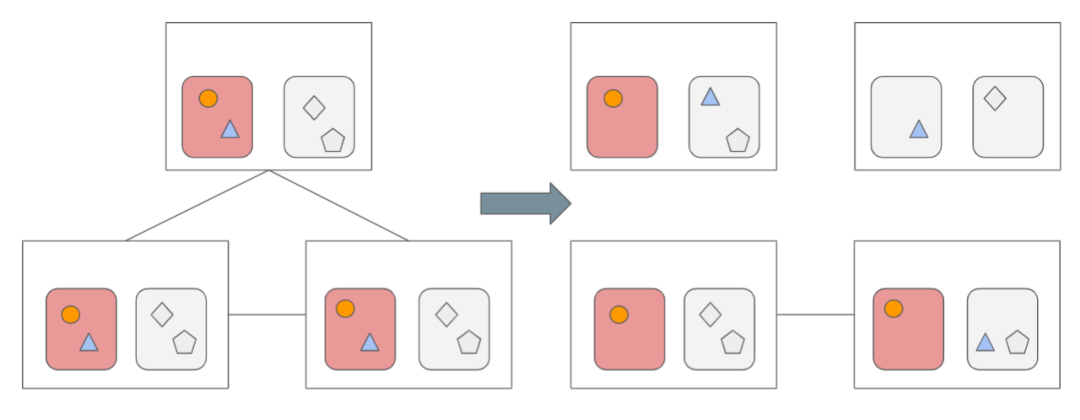
(性能不足引发的存储扩容,造成存储空间闲置)
为了实现增加性能,需要将三角的数据迁移到新的硬盘上,就是图上没有标红的硬盘。
为什么这个问题在量化私募行业特别明显呢?因为我们的行业最原始的数据可能来自于市场数据。以 A 股的数据为例,过去 10 年的数据加在一起才 240G,而今天硬盘容量都好几 TB 一块,这就意味着我们要处理的原始数据实际上是有限的,可能最多也只有几十 TB 的规模。但这几十 TB 的原始数据可能被数十到数百名研究员共享,他们需要同时读取同一份数据,这导致了性能瓶颈的出现。这是量化行业使用数据的一个特点,即由于数据的共享和读取需求,容量充足但性能不足的情况很常见。这也是最开始有量化基金找到 JuiceFS 这个产品去帮他们解决的一个问题。
因此,对于这类会产生热点数据的场景,即对计算的弹性要求更加极致时,匹配性能可伸缩的存储,可以更好地实现整体的性能和成本得到的平衡。
4.JuiceFS 如何实现性能扩展 & 性价比
在 2017 年,当我们开始研发 JuiceFS 时就决定要为云环境设计。我们注意到当时市场上的所有文件存储产品都是在 2005 年前后或更早设计的,甚至还有一些是在 90 年代设计的。这些产品仍然广泛地用于量化私募行业中。由于我们的基础设施的基础资源环境已经发生了变化,因此在开发新产品时,必须跟上我们现在所使用的环境的发展趋势。
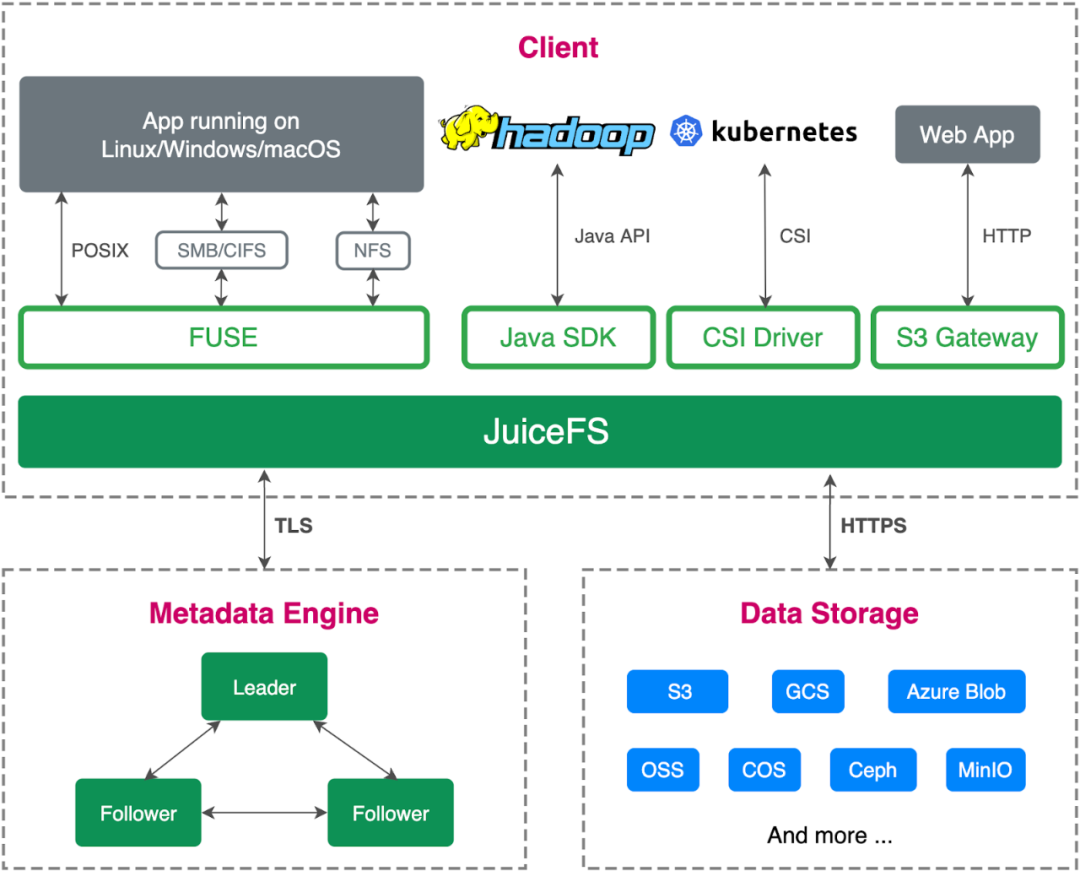
(JuiceFS 企业版架构图)
在这张图中,三个虚线框代表了文件系统的三个核心组件,元数据引擎、数据引擎和客户端,它们一起实现了文件系统的关键功能。
文件系统可以简单地理解为一种用于组织、管理和访问文件和目录的技术。比如我们电脑上使用的硬盘,文件系统提供了一种与它的交互方式,即通过文件和目录(文件夹)的形式来访问和管理存储在硬盘物理介质上的数据。
例如,在 Linux 中一块硬件格式化文件系统后,挂载到一个目录上,看到的是一个目录树,其中包含目录、文件夹和文件。每个文件都可以设定权限,并具有时间戳,记录了创建时间、上次修改时间等,称为元数据。它们存放在上图左下角的虚线框内所示的 Juicedata 自研元数据引擎中,这个引擎很大程度上决定了文件系统的性能。
右下角虚线框代表文件内容的存储。这部分是 20 年前存储系统最重要的功能之一,需要管理大量机器和其中的硬盘。例如,在 HDFS 中的 DataNode,Ceph 中的 RADOS,Lustre 中也有 ChunkServer,这些服务需要完成例如数据分块、存储、副本管理、迁移等,很复杂。在云环境中,S3 已经将这个问题解决得非常出色。因此,当我们决定在云上重新构建一个文件存储系统时,我们不再需要管理大量硬盘。相反,我们可以站在 S3 的基础之上,为其增加更多的功能。在 JuiceFS 的设计中,用户存储在 JuiceFS 文件系统中的所有文件内容直接存储在用户自己的 S3 Bucket 中。
图片上方展示的是一个客户端访问系统,JuiceFS 提供了最标准的 POSIX 接口,并支持像 HDFS 等不同的 API 互通。这让开发者在编写程序时更加便利,可以根据自己的需求选择最适合的接口。此外,我们还提供了性能扩展功能,以满足更高的性能需求。
因为 S3 提供的性能和语义不足以满足高性能的模型训练或投研分析的需求,所以我们需要一种中间解决方案来弥补这些不足。例如,PyTorch 需要的是一个 POSIX 文件系统,但 S3 只提供 HTTP API。
JuiceFS 就是这样一种解决方案,它可以将数据存储在 S3 中,同时提供 POSIX 和其他 API,以满足不同应用的需求,并通过内部优化来提供最佳的性能。
要解决上文提到量化机构面临热点数据吞吐不足的问题,需要介绍 JuiceFS 的缓存功能。当用户的 GPU 计算节点需要读取数据时,所有数据的访问都会首先从 S3 中拉取一次,然后存储在 JuiceFS 缓存中。在以后的访问中,所有数据都可以在缓存中被命中,从而获得与全闪存文件存储相当的性能。JuiceFS 的缓存层可动态伸缩,为用户提供可弹性扩展的吞吐性能。此外 JuiceFS 的缓存层可以与计算节点上的高性能存储形成一个分层的多级缓存,进一步提高性能。
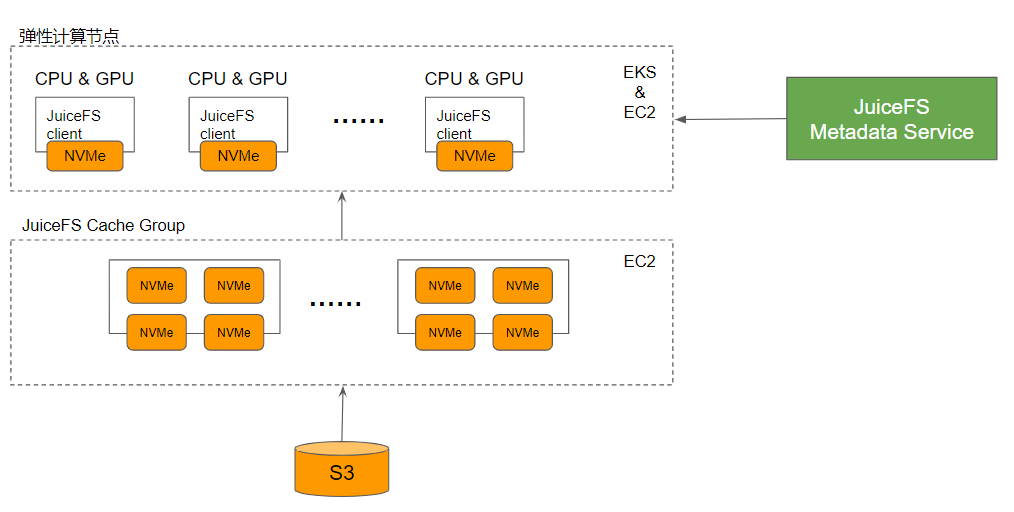
(JuiceFS 企业版缓存)
总结一下,使用 JuiceFS,数据都可以保存在低成本的 S3 中,降低了存储成本;同时, 通过一个动态的缓存层为 S3 提供了加速,还实现了吞吐性能的弹性扩展。
如果热点数据仍然存储在有限数量的 NVMe 盘中,扩大整个缓存层的规模实际上并没有太大的意义。为了解决数据热点问题,可以使用 cache 分组的方式,让热点数据在每个组中都得到存储。用户只需要根据需求建立多个缓存组,通过简单的配置调整即可在短时间内完成,非常有效地解决了数据热点问题。
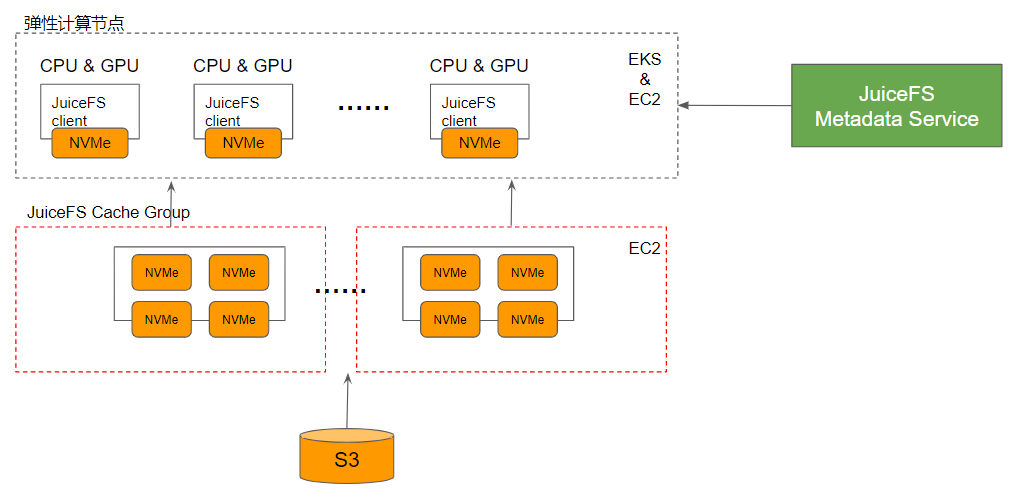
(JuiceFS 企业版 缓存分组)
用户可以设置自己的 cache group,或者为每个团队设置自己的 cache group,这样可以扩展热点数据的性能,并且整个系统的性能也可以基本上线性扩展。此外,如果用户在下班后关闭了这些 cache group,就可以避免额外的成本。
对于那些仍然拥有机房资产的量化私募机构,可以使用混合云部署方案,数据仍然存储在 S3 中,但可以预热到机房中的 cache group 进行计算加速。
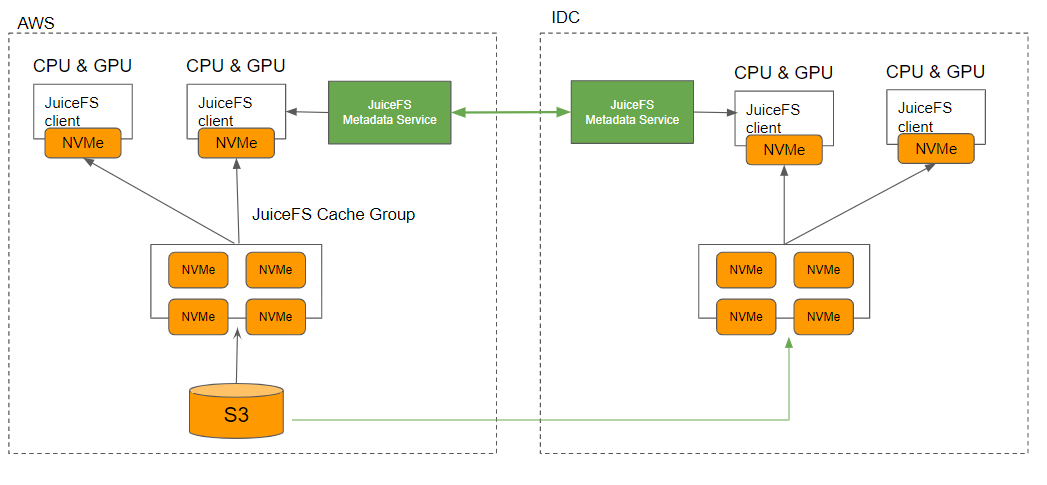
(JuiceFS 混合云部署架构图)
JuiceFS 可以在云环境和机房环境中使用两个 JuiceFS 实例进行数据复制,而这个过程对用户来说是透明的,无需进行额外的操作。JuiceFS 自动将热数据存储在高性能的 cache 层中,这意味着不论用户在机房还是云上执行任务,都可以快速访问热数据,从而解决了现有资产和云上弹性部署的混合使用问题。
现场视频(03: 07 开始):https://www.laohu8.com/m/live/1762844022350878
关于作者
苏锐, Juicedata 合伙人,作为 1 号成员参与创建 JuiceFS,一直深度参与在开源社区中支持开发者使用 JuiceFS。




