
作者 | 吴英骏
多年来,数据工程社区一直在争论开放表格式(Open table formats )的未来。是 Delta Lake 凭借与 Databricks 的紧密集成取得胜利?还是 Apache Hudi 利用在流处理领域的早期优势脱颖而出?亦或是 Apache Iceberg 悄然崛起,成为行业主导者?
2024 年底,答案已经明了。Databricks 收购了由 Iceberg 原始创建者成立的公司 Tabular,这表明了其对 Iceberg 潜力的高度认可。同时,Snowflake 推出了基于 Iceberg 的目录服务 Polaris。再加上 Starburst 和 Dremio 等知名查询引擎厂商对 Polaris 的支持,整个行业逐渐达成了共识——Apache Iceberg 成为事实上的开放表格式标准。
但这仅仅是故事的开始,展望 2025 年,多个关键发展将进一步巩固 Iceberg 在现代数据工程中的地位。
2025 年 Iceberg 的关键演进
1. RBAC 目录:解决大规模权限管理问题
我们的不得不承认,由于缺乏统一的标准和方法,数据湖中的权限管理一直以来都非常混乱。用户可能会在 S3 存储桶级别设置权限,也可能依赖查询引擎特定的访问控制机制,亦或是其他方法。这种不统一的权限管理方式不仅效率低下,还带来了安全风险。
Iceberg 社区正在通过一个新的 OpenAPI 规范(PR #10722)着手解决这一问题。该规范标准化了凭证结构,使开发者能够直接在 Iceberg 目录中构建基于角色的访问控制(RBAC)系统。
例如,管理员可以在目录级别定义精细的访问策略,而无需依赖底层存储或查询引擎。这些功能与 Databricks 的 Unity Catalog 等企业级特性类似,但同时具备 Iceberg 的开放性和灵活性。
2. 变更数据捕获(CDC):Iceberg 的流处理演进
“Iceberg 不适合流处理”这一观点在过去颇为流行。确实,Iceberg 缺乏强大的 CDC 功能。尽管其架构支持版本化的表快照(Spark CDC 操作),但并未针对高频数据变化或实时分析进行优化。
这种情况将在 Iceberg Spec V3 中得到改变,该版本引入了一项关键功能:行级谱系(Row Lineage)。
行级谱系使 Iceberg 能够跟踪每一行数据的更新、删除或插入变更。这使得在 Iceberg 表上直接实现高效的 CDC 管道成为可能,对于流处理场景来说,这是一个巨大的进步。例如,物化视图维护和系统间的数据同步将更加顺畅。
更多详情可查看 《行级谱系》规范提案。一旦 Spec V3 完全实现,Iceberg 将在实时数据处理领域与 Kafka 和 Hudi 等传统以流处理为核心的系统展开竞争。
3. 物化视图:简化衍生数据
数据湖是存储原始历史数据(通常称为 Bronze Data)的地方。这些表的数量庞大且更新并不频繁,但真正有价值的是从这些原始数据中计算出的衍生数据集,如聚合、转换和预计算的指标。
迄今为止,Iceberg 缺乏对物化视图的内置支持,用户不得不依赖外部系统或定制方案来管理衍生数据。这带来了两个主要挑战:
跟踪基础表与衍生表之间的依赖关系十分繁琐。
对基础表的任何更新都需要重新计算衍生数据。
计划中的物化视图功能(PR #11041)将改变这一现状。通过物化视图,预计算结果将以表格形式存储,Iceberg 将管理跟踪依赖关系所需的元数据。这不仅意味着更高的查询性能,还能在基础表变化时自动更新衍生数据。
Iceberg 的扩张
随着 Iceberg 的不断发展,其生态系统也在扩展。以下是 2025 年值得关注的几个领域:
新数据类型:支持带有时区的纳秒级精度时间戳,将使 Iceberg 适用于金融、电信等对高精度数据要求较高的行业。
二进制删除向量:Spec V3 引入了一种可扩展且高效的删除方案,特别适用于法规要求或 GDPR 合规
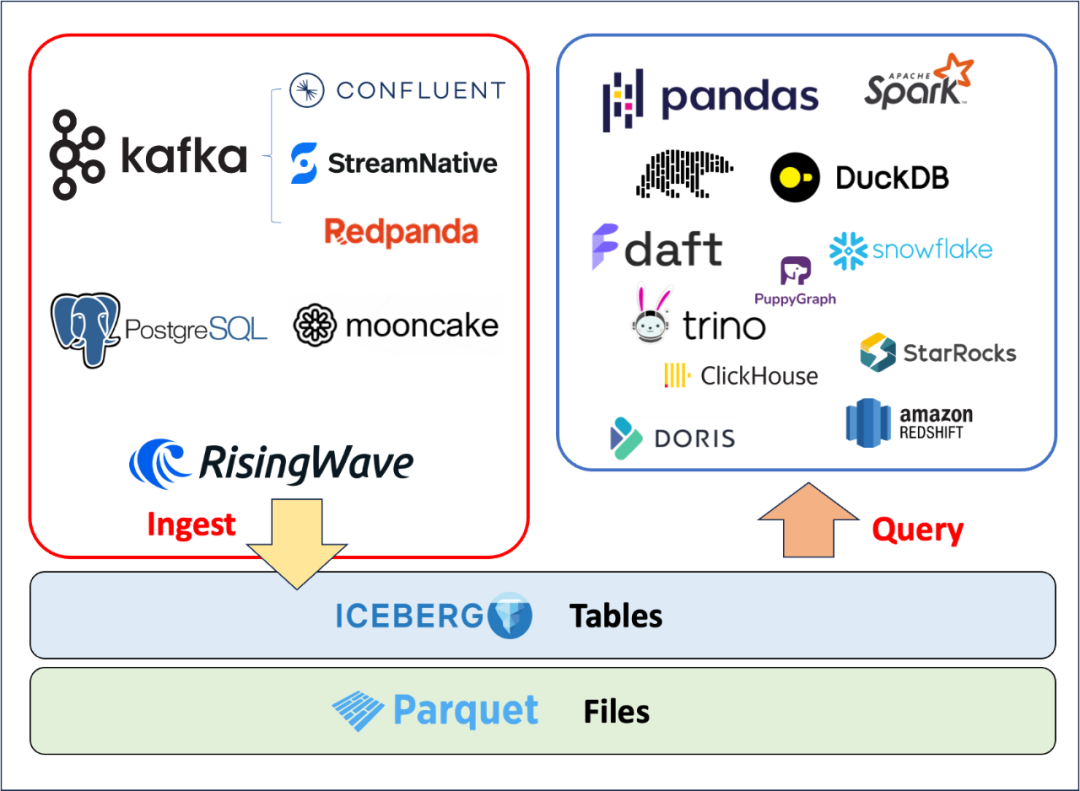
更广泛的查询引擎支持:RisingWave、Trino、Dremio 和 Flink 是一些正在积极增强其 Iceberg 集成的引擎。
Iceberg 的短板
Iceberg 的生态系统已经相当完善。用户可以通过 Kafka 或 Postgres 协议(借助 RisingWave)导入数据,并使用各种引擎查询。但一个明显的短板是缺乏:轻量级压缩。
目前,压缩通常依赖于繁重的 Spark 作业,而这对于小型团队或小型工作负载来说可能过于复杂。对于希望采用更简单、资源效率更高的方式压缩 Iceberg 表的 SQL 和 Python 用户来说,这形成了一个障碍。
好消息是,社区已经意识到这一问题,并且对于构建一个轻量级、与引擎无关的压缩框架产生了越来越大的兴趣。希望 2025 年,能够推出让 Iceberg 对所有用户更加易用的解决方案。
前路展望
凭借 RBAC 目录、具备流处理能力、物化视图以及对新数据类型的支持等创新,Apache Iceberg 会逐渐巩固作为数据工程领域开放表格式标准的地位。
2024 年证明 Iceberg 能够赢得表格式之争。到了 2025 年,重点将转向让它变得更好、更快、更易用,不论是对于小型初创公司还是全球企业。无论您是在构建实时分析管道,管理 PB 级的历史数据,还是探索最前沿的数据湖仓架构,Iceberg 都能为您提供价值。
数据工程的未来已经到来,而它正是 Iceberg。
今日好文推荐
伪装“计算机工程师”窃取 TB 级数据勒索 25 万美元!前 FBI 特工解析 AI 时代安全危机
机器比人靠谱!Meta 耗时4年半,将 Java 代码转成 Kotlin:进度刚过半,真正难搞的还没开始
Airbnb死磕React Native惨败,微软却玩出花!Office、Outlook全线接入,Copilot成最大赢家




