
DeepMind 的研究人员推出了 SIMA 2 (Scalable Instructable Multiworld Agent),这是一个建立在 Gemini 基础模型上的通用智能体,可以理解并在多个 3D 虚拟游戏环境中行动。该智能体与其前身SIMA 1的区别在于,它超越了简单的命令执行,转而“对高级目标进行推理,与用户对话,并处理通过语言和图像处理复杂指令”。第一版需要逐步指导,而 SIMA 2 可以制定多步骤计划并与用户讨论策略。
研究人员报告称,该智能体在他们的游戏测试组合中“大幅缩小了与人类表现的差距”,同时展示了他们所描述的“对以前未见过环境的强大泛化能力”。该系统保留了底层Gemini模型的推理能力,并可以与更先进的 Gemini 变体对接以获得额外功能。
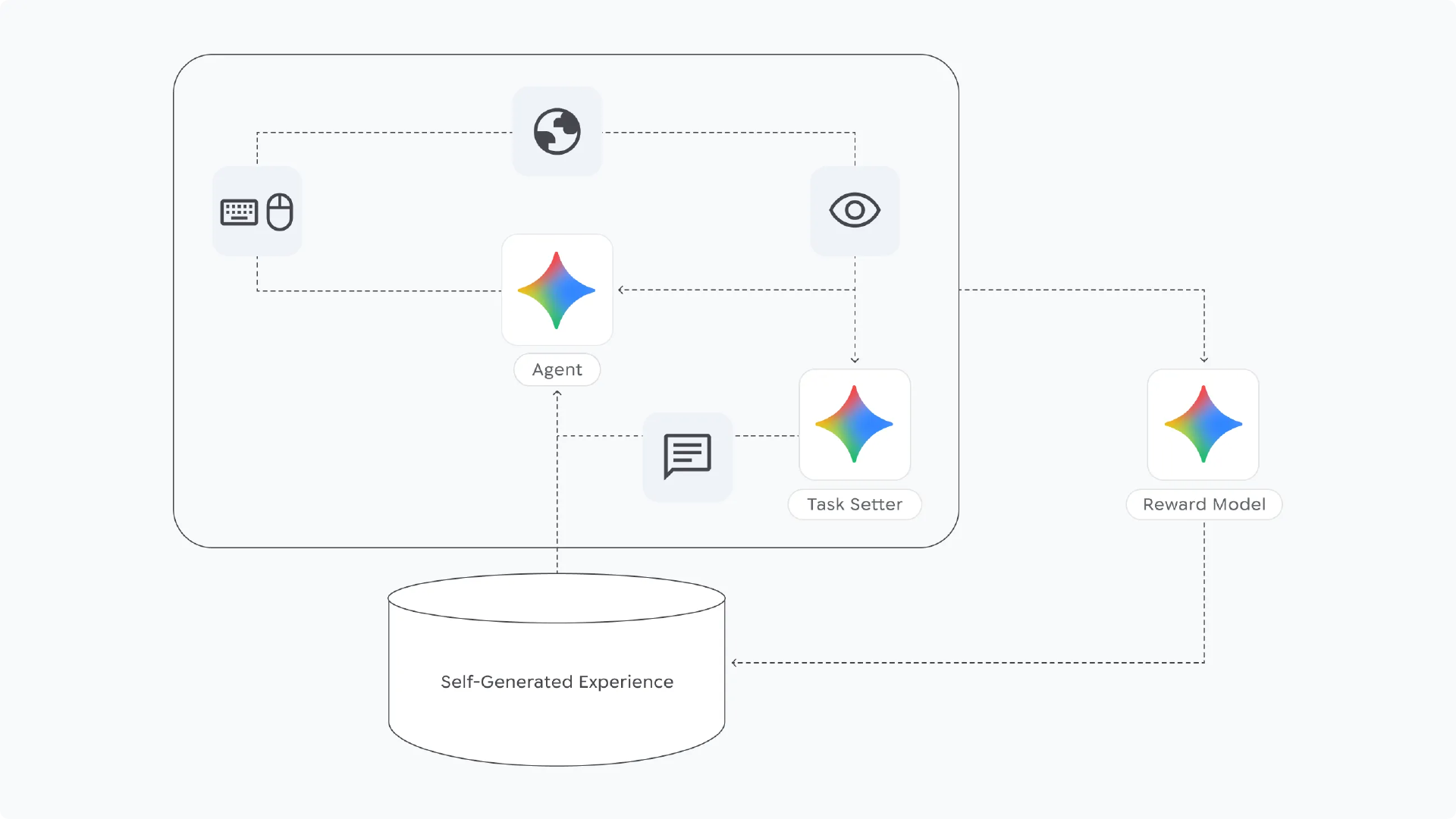
来源:谷歌 DeepMind SIMA 2 自我改进
该智能体采用了一个自我改进循环,其中 Gemini 提供了一个初始任务以及对 SIMA 2 行动的估计奖励。系统将这些信息添加到自生成经验库中,然后用于后续迭代的训练。根据研究人员的说法,这个过程允许智能体“在完全独立于人类生成的演示和干预的情况下,改进以前失败的任务。”
通过评估智能体在完全独立的环境中遇到新的视觉效果、菜单和游戏机制的表现,研究人员测试了 SIMA 2 的泛化能力。
研究人员还在 The Gunk 和Genie 3环境中进行了定性评估。The Gunk 是一款故事驱动的动作冒险平台游戏,主要内容是使用手持吸力工具清理行星,而 Genie 3 是一个生成式世界模型,根据文本描述或初始帧创建图片般逼真的场景。这些新生成的环境不会出现在训练数据集中,这使得团队可以测试 SIMA 2 是否可以将 Gemini 的世界知识应用到视频游戏世界之外的逼真设置中。
SIMA 2 架构使用Gemini Flash-Lite模型,该模型混合了游戏玩法和 Gemini 预训练数据。研究人员表示,这种混合“对于保持基础模型的原始能力至关重要,例如视觉理解、对话、推理和提示性。”训练过程从一个预训练的 Gemini Flash-Lite 检查点开始,并使用混合数据集进行监督微调,训练模型在提示图像帧和指令时产生键盘和鼠标动作响应。
谷歌 DeepMind 的研究人员将 SIMA 2 定位为超越简单指令遵循的一步,创造了他们所描述的更有能力和协作性更强的具身智能体,能够在 3D 虚拟世界中推理、对话和执行目标导向的行动。该系统展示了泛化能力,“从游戏世界扩展到 Genie 3 生成的全新逼真环境”,并可以根据自我生成的经验在新环境中进行改进。
在 Reddit 上讨论这项研究的技术社区成员指出了游戏之外的潜在应用。一位评论者评论道:
这将有助于以非常便宜和安全的方式在现实世界中训练机器人。应该有助于推动 AI 研究训练。
另一位强调了技术架构,指出:
该团队正在使用 Genie 3 创建世界,并使用 SIMA 2 在该世界中进行递归自我改进。
该团队承认当前的局限性,指出 SIMA 2“仍然面临着非常长远的挑战,复杂的任务需要广泛的、多步骤的推理和目标验证。”智能体在有限的上下文窗口下运行,以保持低延迟的交互,研究人员确定了精确的键盘和鼠标控制执行以及对复杂 3D 场景的强大视觉理解是当前的挑战。
DeepMind 将 SIMA 2 作为一个有限的研究预览版发布,并向一小群学者和游戏开发者提供了早期访问权。在整个开发过程中,该公司与负责任的开发和创新团队合作,特别是在智能体的自我改进能力方面。研究人员认为,SIMA 2 获得的技能,包括导航、工具使用和协同任务执行,可以作为物理具身 AI 系统在机器人应用中的构建块。
原文链接:




