
Kubernetes 发布 1.36 版本,代号 Haru,这是 2026 年的首个重要版本。该版本包含 70 项增强功能:18 项进入 Stable 阶段,25 项进入 Beta 阶段,以及 25 项新的 Alpha 功能,重点聚焦安全加固、人工智能和机器学习工作负载,以及大规模 API 的可扩展性。由编辑 Chad M. Crowell、Kirti Goyal、Sophia Ugochukwu、Swathi Rao 和 Utkarsh Umre 撰写的发布博客将此次发布描述为“时节更迭、山巅光影流转”之时如约而至,共有 106 家公司和 491 位个人参与了贡献。

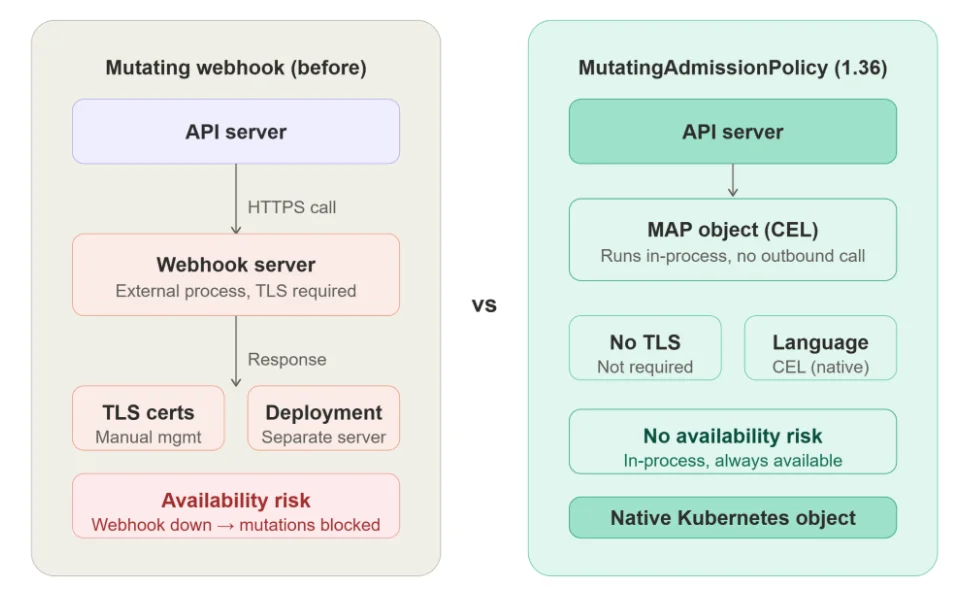
本次发布最亮眼的安全功能是用户命名空间(User Namespaces)正式达到 GA,该功能已经历多个版本周期的打磨。该功能可将容器内的 root 用户映射为主机上的非特权用户,即便进程突破容器隔离,也无法获取底层节点的管理权限。同样达到 GA 的还有可变准入策略(Mutating Admission Policies),允许团队借助通用表达式语言(CEL)把变更逻辑定义为原生 Kubernetes 对象,无需再单独维护独立的 Webhook 服务器。发布博客表示,这“为传统 Webhook 提供了原生、高性能的替代方案”,同时降低了“管理自定义准入 Webhook 带来的延迟与运维复杂度”。Kloia 官方博客也对此做了详细解读并配有原理图示。
细粒度 Kubelet API 授权也在本版本中正式达到 GA。该功能于 v1.32 版本首次以 Alpha 状态引入,支持对 Kubelet HTTPS API 进行更精细的最小权限访问控制,替代了监控与可观测性工具以往所需的过度宽泛的 nodes/proxy 权限。SELinux 卷标签功能进入 Stable 阶段,通过 mount -o context=XYZ 选项替代递归文件重标记,在挂载时为整个卷统一配置正确的 SELinux 标签,以此降低开启 SELinux 强制模式环境下的 Pod 启动延迟。基于 validation-gen 的声明式验证、以及卷组快照(Volume Group Snapshots)——支持同时为多个持久卷声明(PersistentVolumeClaim)创建崩溃一致性快照——也均在本版本中达到 GA。
DRA 管理员访问以及动态资源分配的优先列表功能同样达到 GA,为集群管理员提供了一个固定框架用于全局访问和管理硬件资源,并保障资源选择逻辑在各类集群环境中保持统一。
v1.36 版本在人工智能与机器学习方面的优化主要体现在默认配置适配了日益增长的工作负载需求。ScaleOps 团队在文章中表示,该版本“与其说是全新的机制,不如说是默认配置补齐了两年间沉淀的 AI 工作负载实践经验”。多项 DRA 增强功能进入测试阶段并默认开启:DRA 可分区设备、DRA 可消耗容量以及 DRA 设备污点与容忍,均无需手动配置特性门控即可启用。这些功能替代了传统的整数 GPU 设备插件模型——该模型不考虑实际资源利用率,直接将整张显卡整体分配——转而提供原生能力,适配现代加速器的分区、共享以及故障恢复机制。VMware Cloud Foundation 博客还提到,以往“申请复杂资源往往需要晦涩且厂商专属的配置模块,调度器也难以做优化调度”,而 v1.36 版本采用的标准化架构大幅降低了多节点 AI 部署的复杂度。
AI 工作负载方面重磅新增的 Alpha 功能是工作负载感知抢占(Workload-Aware Preemption)。在这项功能之前,调度器在为高优先级工作负载腾出空间时会抢占单个 Pod,容易出现分布式训练任务八个进程中七个都在运行,却始终无法正常推进的情况。新的机制将 PodGroup 视为一个整体抢占单元,只有在确认高优先级任务组确实能够容纳资源后才会执行驱逐操作。正如 Palark 团队在版本解读文章中所说,该功能解决了分布式训练的“部分抢占故障模式”,这也是运行大型 GPU 任务的团队长期面临的痛点。Gang 调度 API 于 v1.35 版本以 Alpha 状态引入,在 v1.36 中正式进入 Beta 阶段。
暂停作业的 Pod 可变资源(Mutable Pod Resources for Suspended Jobs)功能也进入 Beta 状态,并默认启用。该功能允许队列控制器暂停正在运行的作业,调整其 CPU、内存、GPU 及扩展资源请求,适配集群当前可用容量,随后恢复作业运行,无需销毁并重新创建 Pod。Kloia 团队表示,这省去了依赖自定义控制器或彻底终止、重启作业的操作,让工作负载队列系统能够根据集群实时状态进行灵活调度。
在 API 可扩展性方面,v1.36 版本引入了分片列表与分片监听流作为全新的 Alpha 功能。拥有大量控制器的大型集群常会遇到监听流瓶颈,原因是所有观察者都通过每种资源类型的单一连接接收更新。分片机制可将这类负载分摊到多个流中,Palark 团队表示,这解决了“超大规模部署里监听流容易成为性能瓶颈的关键痛点”。
通过 cgroup v2 实现的内存服务质量(Memory QoS)在本版本中进入 Beta 阶段,提供了分层内存保护机制,能够更好地将内核控制与 Pod 的资源请求和限制相匹配,减少同一节点上各工作负载之间的资源争用。Pod 级资源原地垂直扩缩容(In-Place Vertical Scaling for Pod-Level Resources)同样进入 Beta 版本并默认启用,支持在不重启容器的前提下调整 Pod 级别的 CPU 和内存配额上限。新版本新增 ResizeDeferred 事件类型,当因节点容量不足无法立即执行扩缩容操作时,Pod 会继续按现有资源规格运行,待节点资源空闲后,Kubelet 将自动重试完成扩缩容。
计划进行版本升级的团队需要留意本版本中若干已移除的功能。gitRepo 卷插件自 v1.11 版本开始被废弃后,现已被彻底移除。该插件存在允许攻击者以 root 权限在节点上执行代码的漏洞,PerfectScale 团队建议在升级前迁移至初始化容器或外部 git-sync 工具。Kube-proxy 中自 v1.35 版本开始废弃的 IPVS 模式也已正式移除。此外,kubeadm 中的 FlexVolume 支持以及 Portworx 内置驱动也在本版本中被移除,正如 Kloia 团队在其升级指南中所说明的那样。
有一项早于本版本发布、但仍在 v1.36 官方博客中重点强调的重大运维变更是 Ingress NGINX 的正式退役。Kubernetes SIG Network 与安全响应委员会已于 2026 年 3 月 24 日正式退役该项目。自当日起,项目不再进行任何版本发布、问题修复以及安全漏洞补丁推送。InfoQ 在 Kubernetes 1.35 版本报道中梳理了 Kubernetes 网络生态的发展脉络,并指出 Ingress NGINX 只会“尽力维护至 2026 年 3 月”。
VMware Cloud Foundation 博客将本次版本置于更大的行业转变背景下:“Kubernetes 正从一个灵活的框架逐步转向拥有更标准化、更具强制性的默认安全与资源规范。”文章还提到,“跟进 Kubernetes 版本迭代已不再只是简单升级集群”,还涉及“管理生命周期复杂度、判断何时采用新版本、厘清变更对现有工作负载的影响,以及避免平台演进带来的业务中断”。
“通过采用更规范化的实现方式,Kubernetes 让调度器能够更清晰地识别 GPU 及 AI 加速器的专属资源需求,大幅降低了多节点 AI 部署的复杂度。”
——VMware Cloud Foundation 博客,Kubernetes 1.36:企业平台的实际变化
完整的 Kubernetes 1.36 发布说明 也已发布。
查看英文原文:https://www.infoq.com/news/2026/05/kubernetes-1-36-released/




