
最近,优步在其官方工程博客上发布了一篇 文章,阐述了将批数据分析和机器学习(ML)训练的技术栈迁移到 谷歌云平台(GCP) 的战略。优步运行着世界上最大的 Hadoop 装置之一,在两个区域的数万台服务器上管理着超过上艾字节(exabyte)的数据。开源数据生态系统,尤其是 Hadoop,一直是数据平台的基石。
迁移计划的战略包括两个步骤,即初始迁移和利用云原生服务。优步的初始战略包括利用 GCP 的对象存储作为数据湖存储,同时将数据技术栈的其他部分迁移到 GCP 的基础设施即服务(IaaS)上。这种方式可以实现快速迁移,并将对现有作业和流水线的影响降至最低,因为他们可以在 IaaS 上复制其内部软件栈、引擎和安全模型的对应版本。在此阶段之后,优步工程团队,计划逐步采用 GCP 的平台即服务(PaaS)产品,如 Dataproc 和 BigQuery,以充分利用云原生服务的弹性和性能优势。
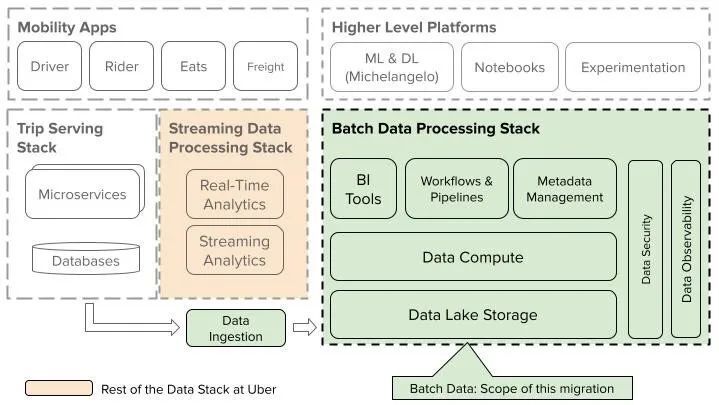
迁移的范围(图片来源:优步博客)
初始迁移完成后,团队将重点集成云原生服务,以最大程度地提升数据基础设施的性能和可扩展性。这种分阶段的方式能够确保优步的用户(从仪表盘的所有者到 ML 的参与者)在不改变现有工作流或服务的情况下体验无缝迁移。
为了确保平滑和高效的迁移,优步团队制定了几项指导原则:
通过将大部分批处理数据栈原封不动地转移到云 IaaS 上,最大限度地减少使用中断;他们的目标是避免用户的人工制品或服务发生任何变化。利用众所周知的抽象和开放标准,他们努力使迁移尽可能做到透明。
他们将依赖于一个云存储连接器,该连接器实现了到谷歌云存储(Google Cloud Storage)的 Hadoop FileSystem 接口,确保了 HDFS 兼容性。通过标准化 Apache Hadoop HDFS 客户端,他们将会抽象出内部 HDFS 实现的具体细节,从而实现与 GCP 存储层的无缝集成。
优步团队为 Presto、Spark 和 Hive 开发了数据访问代理,对底层计算集群进行了抽象。这些代理将支持在测试阶段有选择性地将测试流量路由到基于云的集群,并在全面迁移阶段将查询和作业全部路由到云技术栈中。
利用优步的云中立基础设施。优步现有的容器环境、计算平台和部署工具可以在云和内部环境之间自由切换。这些平台使其能够轻松地将批数据生态系统微服务扩展到云 IaaS 上。
团队将构建和增强现有的数据管理服务,以支持已选定和已批准的云服务,确保健壮的数据治理。公司的目标是保持与内部环境相同的授权访问和安全级别,同时支持对对象存储数据湖和其他云服务的无缝用户身份验证。
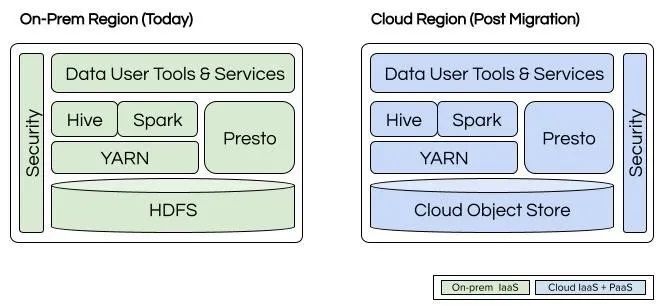
迁移前和迁移后的优步批数据技术栈(图片来源:优步博客)
优步团队重点关注迁移过程中的数据桶映射和云资源布局。将 HDFS 文件和目录映射到一个或多个桶中的云对象至关重要。他们需要在不同的粒度水平上应用 IAM 策略,同时要考虑对桶和对象的限制,比如读 / 写吞吐量和 IOPS 限流。团队的目标是开发一种映射算法,以满足这些约束条件,并按照以组织为中心的层级方式组织数据资源,从而改进数据的管理。
另外一个工作方向是安全集成,调整现有的基于 Kerberos 的令牌和 Hadoop Delegation 令牌,使其适用于云 PaaS,尤其是谷歌云存储(Google Cloud Storage,GCS),这是非常重要的。这个工作方向旨在支持无缝的用户、群组和服务账户的认证与授权,并保持与内部环境一致的访问级别。
团队还关注数据复制。权限感知的双向数据复制服务 HiveSync 能够让优步以双活模式运行。他们扩展了 HiveSync 的功能,以便于将内部环境中数据湖的数据复制到基于云的数据湖和对应的 Hive Metastore 中。这包括初始的批量转移和持续的增量更新,直到基于云的技术栈成为主方案。
最后一个工作方向是在 GCP IaaS 上提供新的 YARN 和 Presto 集群。在迁移过程中,优步的数据访问代理会将查询和作业流量路由至这些基于云的集群,确保平稳迁移。
优步向谷歌云的大数据迁移将面临一些挑战,比如存储方面的性能差异和遗留系统所导致的难以预知的问题。团队计划通过使用开源工具、利用云弹性进行成本管理、将非核心用途迁移到专用存储,以及积极主动的测试集成和淘汰过时的实践来解决这些问题。
原文链接:
https://www.infoq.com/news/2024/06/uber-bigdata-migration-gcp/




