
12 月 30 日 Meta 正式宣布与 Manus 达成全资收购协议,收购金额高达数十亿美元,成为 Meta 成立以来,仅次于 WhatsApp( 190 亿美元)和 Scale AI(未披露具体金额)的第三大收购案。
Manus 创始人肖弘将出任 Meta 副总裁,其核心技术团队将整体并入 Meta AI 部门,公司将继续在新加坡独立运营,现有订阅服务保持不变。肖弘在社交媒体上发文感慨:
“今天是我一生都难以忘却的时刻。”
无论从产品还是营销层面来看,Manus 都堪称生成式 AI 时代的典型创业案例,但也有业内专家表示,看来做一家独立公司很难,通用级 Agent 终究还是巨头的游戏。
这样的评价,也源于 Agent 想要落地企业,本身就存在许多工程交付与产品优化问题,而这一般来说是“大厂专利”。就 ToB 场景而言,企业级 Agent 的使用频率,与资本、品牌市场层面的“表象繁荣”是有些许错位的,创业公司很难组建庞大的工程师团队围绕细分场景做长线研发,遑论贴身服务客户,在价值上形成闭环。
这些所谓的工程交付与产品优化问题,大概可分为以下几类:
幻觉:模型带来的幻觉问题,或许无法被根除,但必须被管理,否则会造成事故;
集成:因为数据孤岛、权限墙的存在,Agent 在很多时候等于“绑着双手”工作;
运维:如何系统地解决版本回归、评测、灰度、告警、审计等问题;
成本可控:Agent 模式下,Token 成本的管理是核心。这里不仅指的是 Token 单价,也包括失败重试、长链路、多轮工具调用带来的不可预测。
没有一项适合创业公司写进“性感”的融资 PPT 中,但每一项都是 B 端客户最关心的问题。在真实的企业场景里,用户不太关心 Token 增量数字,甚至也不太关心产品的想象空间,他们更聚焦当下,更关心:能不能让他现在就少干活,少做回归、少挨骂。
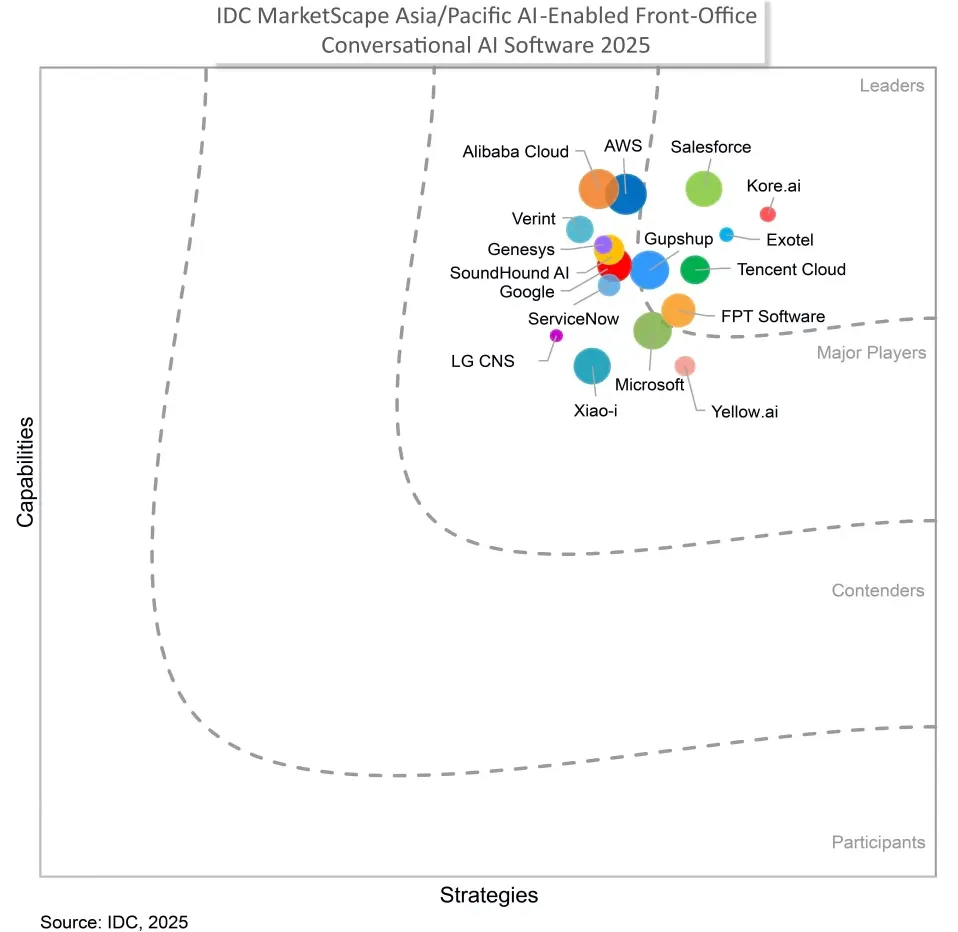
因此当在 IDC《2025 年亚太区 AI 赋能前台对话式 AI 软件厂商评估》报告里的领导者象限看到腾讯云的时候,我非常惊讶——这是唯一的一家中国厂商,而且相比于为了 Token 调用量去猛卷品牌和市场的一众厂商而言,或许相比于卷品牌市场,腾讯云更喜欢、也更擅长卷产品经理,这次站到领导者象限,我不会将其视作“冠军奖杯”,反而更像在即将到来的 2026“困难副本”里,阶段性通关的一个样本。
Agent 越来越像软件产品,而非魔法
当大家都在用品牌市场把 Token 用量推上去时,另一条更务实的路线是:把 Agent 当产品做,当软件做。
这条路或许短期不性感,但更容易在全球化的竞争中活下来。实际上,企业也正把 Agent 驯化成“可控、可审计、可观测”的系统组件,且都要放在精确的业务背景下来谈。
这是一项庞杂的工作,只有产品型团队能够胜任,且完成长期进化。
举个例子,RAG 不是个新技术,对于许多项目型团队,平台提供 RAG 能力,主要的交付任务就已经完成了,剩下的“用量增加”指标,应该交给品牌市场和销售去完成。
但如果作为产品来看,RAG 的迭代空间依然很大。
传统 RAG 的核心是两段式流水线:检索,生成。但其中的每一段都可能出现问题。
对于检索层来说,传统 RAG 的问题是:拿来的资料就可能不对。实际上,检索不是事实保证,只是相似性排序。比如:
召回偏差:Top‑k 里缺了关键证据( 查询 A,检索提供的是“看起来像 A”的 B );
断章取义:检索时丢失了关键限定条件,如时间、范围、例外条款等;
语料过期 / 错误:只能取内容,不能鉴别真伪;
多文档冲突:检索到互相矛盾的片段,模型可能会“自作主张”进行融合。
以上状况都会导致引入 RAG 技术后,幻觉继续出现。
生成层的问题同样不少,核心是就算证据在眼前,模型也可能不用或用错。 比如:
证据利用失败:模型“看见了”,但没按证据约束输出;
证据到答案之间需要推理:片段只给了局部信息,模型需要补全逻辑,补全时出现幻觉;
过度概括:LLM 的训练目标偏向流畅与连贯,而不是严格可证;
指令冲突:系统提示说“只基于资料”,用户又要求“给个确定结论”,模型可能选择“满足用户”。
二者问题叠加,以至于传统 RAG 技术有非常大的局限性。大部分厂商对此的回答是:这是大模型天然的问题,在答案准确度要求较高的场景,不要使用大模型技术。
这话一半是对的,一半是错的。对的部分是,大语言模型存在幻觉确实是底层技术原理导致的,属于生成式 AI 的“本性”。错的部分是,存在不等于失控,如果从产品视角来看,RAG 仍有非常大的优化空间。
腾讯云智能体开发平台的主张是把 RAG 做成“Agentic”的形态: 不是一次检索一次回答,而是能规划、多次工具调用、跨文档推理与证据聚合。
所谓 Agentic RAG ,核心在于赋予了系统“思考,行动”的循环能力,而不是简单的“检索,生成”。其关键能力包括:
任务分解与规划:能够理解复杂问题,并将其拆解为多个子问题,逐步解决;
条件化检索:可以判断何时需要检索,以及应该从哪个数据源进行查询;
自我反思与纠错:当发现检索结果不准确时,能够主动调整检索方向,迭代优化答案;
工具使用:不仅能进行文本检索,还能调用外部工具(如数据库、API 、知识图谱)来获取和处理信息;
多智能体协作:多个智能体可以协同工作,分工合作解决更复杂的任务。
通俗来说,Agentic RAG 的核心目标不是“检索得更多”,而是让模型在流程上更像一个人,而不是一个 SaaS 插件。
当然,Agentic RAG 也不能根除幻觉问题,但可以将幻觉出现的空间压缩。对于对正确性要求极高的环境而言,Agentic RAG 能够反复验证事实、查询多个来源,尽可能确保答案的准确性。
另外当进行复杂的数据库交互时,Agentic RAG 也能自主使用工具改进查询策略,避免查询失败。
最后,Agentic RAG 也使得系统能够持续整合新数据,并随着对问题理解的加深而动态调整策略。
当然,Agentic RAG 自身也存在问题,尚未成为 RAG 应用的标配。比如,Agentic RAG 构建与维护成本比较高——有企业在尝试构建商用级智能体时,遇到了知识库上传限制、问答准确率低等工程化难题,需要专业的陪跑支持才能解决。这与更简单的 GraphRAG 面临的构建维护成本高的问题类似。
同时,Agentic RAG 的技术整合复杂度也比较高,需要将规划、反思、工具调用等多个模块有效整合,并确保它们协同稳定工作,存在一定的技术难度。
但这对腾讯云智能体开发平台而言,似乎并不是个大问题——毕竟其入选 IDC 报告领导者象限的一大核心能力就在于此。
从 RAG 到 Agentic RAG,腾讯云智能体开发平台的案例在透露一个信号:Agent 终于开始像工程一样被讨论,它越来越像软件产品,而非某种神奇的魔法。
归根结底,我们终究需要一些没那么浪漫,但是很值钱的解决方案。
生产环境不相信“愿景”
与 RAG 境遇类似的是 Multi-Agent。
区别在于,Multi-Agent 画的“饼”更大——产品经理 Agent 写 PRD,架构师 Agent 拆模块,开发 Agent 写代码,测试 Agent 生成用例与 fuzz,安全 Agent 做依赖扫描与漏洞推演,最后 Reviewer Agent 做代码审查与风险签署。
这样一种群体智能在企业场景的落地实现,让无数企业主心动。
但事实是,Multi-Agent 非常依赖 Agent 平台的“工作流编排”功能,也就是一个极度确定性的执行流程。而在企业内,许多业务场景可能不存在一个明确的 SOP,且越贴近实际业务,越是如此。理论上 AI 应用应该和传统 SaaS 应用存在明确的产品界限,支持更有好的交付,更低的使用门槛。
当行业需要某一项产品能力,但主流厂商都不支持时,就来到了腾讯云的“舒适位面”。腾讯云 Multi-Agent 同时支持“零代码自由转交协同”与“工作流编排”,并新增 Plan-and-Execute(试用阶段):
“自由协同”更像提高灵活性,适合探索型任务;
“工作流编排”更像提高可控性,适合流程明确、稳定性要求高的任务;
Plan-and-Execute 适合复杂报告 / 网页等任务拆解。
这本质上是在同时覆盖探索型智能与生产型智能:自由协同适合需求不清、路径不定的探索任务;工作流编排更适合流程明确且稳定性要求高的业务;而 Plan-and-Execute 则补上复杂任务的“先规划再执行”能力,便于把报告撰写、网页生成等长链路工作拆成可并行、可回滚的子任务。
如果后续还能配套预算 / 停止条件、验收关卡与权限治理,这套组合就能把“好用的演示”更可靠地推向“可用的生产”。
中国 ToB 软件行业的难点之一是,企业永远会在客户的定制化需求和高利润标品之间摇摆不定。现在腾讯云智能体开发平台,似乎利用 AI 技术找到了很好的折中点:
既可以面向混沌由 AI 新建流程,又可以面对确定流程交付确定结果。
这种一边识别市场真需求,一边利用 AI 能力“既要又要”的模式,几乎可以在腾讯云智能体开发平台 2025 年的所有主要更新中见到。
比如,近日,腾讯云智能体开发平台推出全流程 AI 原生的 Widget 功能,支持自然语言生成和模型原生输出 Widget 组件。这是国内首家从创建到使用全流程都实现了更 AI native 的 Widget 应用方式。
Widget 是一种支持嵌入在对话中的自定义展示组件,可呈现图文、表单、操作按钮等多类型内容。
国内智能体平台的“卡片”功能整体支持组件范围非常有限(尤其是输入类组件),实现方案主要是采用可视化拖拉拽构建前端,再通过手动一一匹配编辑前端组件和数据字段的映射关系实现。一般流程比较复杂、输出效果也不太稳定。
腾讯云智能体开发平台推出的 AI 原生 Widget,兼容 OpenAI Widget 协议,用户可通过模板创建、代码创建、甚至自然语言生成等不同方式配置,自定义创建符合业务需求的专属展示单元。
简单来说,开发人员现在可以用自然语言生成表单,并且将其用在和智能体的交互中,降低交互式组件的开发门槛。
目前,腾讯云智能体开发平台的 Multi-Agent 和工作流模式均已支持 Widget 创建和使用。
客户要的 Multi-Agent “零代码自由转交协同”,有了;用户要的 AI 原生 Widget,也有了。腾讯云向客户 / 用户靠拢的速度,实在是有些快了。
在过去三年 GenAI ToB 的主流叙事里,这个需求几乎有些奢侈:过往,企业是被 AI 舆论裹挟的。AI 有什么就拥抱什么,拥抱不了要反思一下姿势对不对,是不是不够 AI-Native?
腾讯云的想法是,AI 同样需要具备产品思维,主动靠近业务的实际需求和情况,提高端到端复杂任务的完成率。
更进一步看, 产品化的本质是拥抱变化、持续进化,这会让企业在全球化战略盛行的今天,走得更稳健。
通关东南亚的“压力测试场“
国际市场最终看中的不只是客情和渠道,还包括最核心的产品能力。
这是文章开头提到的 IDC 这份瞄准亚太区的报告,有着极高的准入门槛—— 亚太区,尤其是东南亚,是典型的企服“压力测试场”,核心挑战包括:语言与语境极端多样性、监管与部署要求。
在“语言和语境的极端多样性”方面,企业需求远远超出当前模型能力。报告提出,真正可用的系统不仅要覆盖更多本地语言和方言,还要深入理解行业术语、业务表达与文化语境——这不仅是自然语言处理的问题,更是对业务理解能力的要求。
而在“区域监管和部署要求”方面,一些企业甚至无法将关键工作负载部署在单一的公有云上,迫使供应商必须提供本地部署、私有云、混合云等多种形式。
所以在报告的入选门槛上,IDC 要求供应商必须提供可商业化的产品或服务,且客户需至少连续使用一年;必须具备面向前台业务的对话式 AI 开发能力;在亚太及日本地区拥有本地机构,并至少在三地设有办公室且区域营收占比超过 10%;在 2024 年至少拥有三家将 FOC AI 解决方案投入生产使用的区域客户,同时该地区 FOC AI 收入需超过 300 万美元。同时,解决方案必须支持典型客户场景(如客服、营销与销售),具备大型语言模型能力,并保持生态系统开放性,可与多种企业系统集成。
而除了以上两方面技术产品优化,腾讯云的一大入选原因也在于成熟的本地化和灵活的部署方式。
腾讯云在整个亚太地区(不包括印度)都有客户基础,并在新加坡、马来西亚、印度尼西亚、泰国和香港等地设有本地化的销售和支持团队。
另外,针对受监管行业(如金融服务业),腾讯云的 FOC AI 产品提供从私有化部署(on-premises)到 SaaS 部署的多种部署选项。
对于众多在 AI 时代完成全球化布局的企业而言,这绝对是个好消息。
比如全球最大的跨境物流服务商之一 DHL ,覆盖全球两百多个国家和地区,提供国际快递、货运和供应链解决方案服务,拥有全球最大的航空快递网络之一,恰恰最需要成熟的技术产品交付能力、本地化的支持,以及灵活的部署方式,因此在客服系统的智能化升级上,和腾讯云智能体开发平台走到了一起。
如其他国际物流巨头一样, DHL 的客服系统面临着严峻挑战,如:繁多的货运环节,较长的物流管理流程,既要满足本地化适配,又要满足全球化管理的协同需求。
通过接入腾讯智能体开发平台,DHL 将传统 AI 客服升级为「大模型客服」,集成到企业小程序、官网、公众号,C 侧用户通过对话形式进行问答,帮助自动化处理快递寄件、收件、信息查询等超过 40 类过程复杂且分支较多的任务,减轻人工客服压力,提升业务服务效率和质量。
最终,DHL 人工维护的知识条数从超 900 条下降至 119 条问答,转人工客服绝对数减少 200 人次 / 天,机器人解决率从 69% 提升至 74%。
这是 Agent 平台型产品,在高度复杂的业务环境下的真实落地案例。
有行业专家判断,Agent 会是 2026 年最主要的 AI 商业化机遇。那么不如说,Agent 背后的产品思维、工程能力、交付能力、进化能力、全球化能力,就是 2026 年企服领域竞争的重点。
从这个角度看,腾讯云为大家做出了极好的示范。




