
开题:说实话,一开始决定写这篇文章并把名字直接和“云原生”这一在当下如此火热和宏大的技术体系挂钩,心里着实有些忐忑不安。一是云原生理念和技术体系如此浩瀚,作为一个可能正在踏入云原生大门的“新人”(虽然本人踏入软件研发行业已经 11 年了),通过一篇文章,结合自己一两年的经验和思考,来讲清楚云原生是面临巨大挑战的;二是怕被别人冠以“蹭技术热度”之帽,技术性领域尤其是软件研发领域,开发者都有一种强烈的危机感和焦虑感,生怕在日新月异、快速迭代的技术洪流中,一不小心就被时代抛弃了。所以,这种文章标题容易让同行觉得在务虚,反映的是内心焦虑,生怕自己不了解前沿技术,结果更多是饭后谈资。
然而随着京东业务在快速发展,催生出了越来越多的新业务、新赛道和新站点,这些新业态很多都是集团战略级的,而且京东技术商业化落地和价值输出作为集团增长的新曲线的诉求愈来愈强烈。iPaaS 作为京东零售前台研发标准,在支撑公司新业态、新赛道运营体系的搭建和落地,支撑公司国际化站点、商业化项目等方面发挥了愈来愈重要的作用。但如何进一步抽象和屏蔽技术实施和技术复杂度,如何进一步让开发者聚焦业务价值的快速交付,如何更进一步提升开发者开发效率和需求交付效率,如何赋予业务更敏捷的试错能力和更强的创新能力,iPaaS 需要来规划和发挥的空间还是非常大的。当我们结合 iPaaS 的初衷、愿景、价值和云原生的理念和价值进行思考时,发现 iPaaS 和云原生其理念和价值是不谋而合的。所以云原生的理念和技术是 iPaaS 未来一个重要的方向,本文是对云原生和云原生落地 iPaaS 的一个初步思考。
先简单了解一下 iPaaS。(iPaaS 的详细介绍可以参考另一篇文章:https://mp.weixin.qq.com/s/uMprW-dglk9SD_X_MV5CSQ。)
iPaaS 是什么?
iPaaS 为京东零售前台研发标准,其定义为:“iPaaS 是一套开放、共生、智能、协同的技术标准体系,旨在把被海量业务和流量所成功验证过的平台化能力全面标准化和开放化,并提供覆盖大前端到大后端的立体式和完整的技术开放体系,让开发者从大量同质性劳动中解脱出来,最大程度聚焦在业务开发商,实现高效、灵活开发和定制业务的个性化需求。业务在 iPaaS 持续繁荣的生态圈中尽情享受了能力共享和技术创新的红利,通过 iPaaS,业务能够极速构建运营体系,加速业务数字化升级和业务创新。”。
iPaaS 的价值
iPaaS 面向开发者,其终极价值在于高效支撑业务,其价值总结来看包括:
a. 让开发者聚焦业务,提升开发者生产力。
b. 降本提效。
c. 赋予业务极速创新能力。
d. 助力技术商业化落地。
iPaaS 的愿景
iPaaS 的愿景是以技术和业务能力的标准化、规范化为基础,拉通智能协同链路,打造高度可集成、可连接外部系统和业务的能力,达到与开发者和业务开放共生,实现互利多赢,助力开发者聚焦业务价值和个性化需求定制,支撑业务快速搭建运营体系,实现快速试错和业务创新。总结来看,iPaaS 的最顶层愿景是通过标准化能力和技术开放能力连接开发者、业务和 iPaaS 平台,形成一个不断繁荣、良性发展的生态圈,以实现开发者-业务-iPaaS 的三赢局面。

云原生
从云原生业界比较认可的定义(“云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用。云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式 API。这些技术能够构建容错性好、易于管理和可观测的松耦合系统。结合可靠的自动化手段,云原生技术使工程师能够轻松地对系统作出频繁和可预测的重大变更。”)可以看出,云原生是一种理念,生在云上,长在云上,最大化地发挥云的能力和价值。也是一系列架构原则和设计模式的集合,旨在将云应用中的非业务代码的部分进行最大化的剥离,从而让云设施(IaaS、PaaS)接管应用中原有的大量非功能特性,让开发者聚焦在业务价值交付上。
我们剖析并总结 iPaaS 和云原生的理念和价值,发现很多方面都是非常契合的,这坚定了我们未来融合云原生理念和技术,本文算是对云原生理论和落地 iPaaS 的一些浅层次的思考。
最后需要给本文的读者“打一剂预防针”,本文对云原生的解读只限在整体性和入门级的介绍,通过本文能知道云原生是什么?能了解其理念、思想、价值和技术栈,如果想通过本文来深度了解云原生的技术原理和方案,那臣妾办不到啊,还需要结合技术的官网进行进一步的学习和研究。最后本文会解读一下 iPaaS 在云原生落地的方向和规划,可能存在误区,也欢迎各位读者能够给到有意义的建议和提示。
本文将重点讲解以下 5 方面:
1. 回顾软件交付的发展历程。
2. 什么是云原生?云原生能给我们带来什么?
3. 云原生的架构原则和设计模式。
4. 云原生主要技术。
5. iPaaS(京东前台研发标准)在云原生的思考和探索。
1、软件交付的发展历程
作为一个在软件研发行业扎根超过 11 年的“老兵”,经历过在中小公司通过 shell 脚本+配置文件+war 包方式交付客户软件,到把程序和运行时打包到庞大虚拟机然后通过移动硬盘交付给客户部署,在到现在在京东通过一站式的集成交付平台只需要点几个按钮就可以管理和部署数千个应用实例,高峰期每天数十次的频繁发布交付的历程。过去十年是互联网行业快速和颠覆式发展的十年,也是云计算和软件交付技术快速发展的十年。让我们把视线拉向过去,回顾一下软件交付技术的发展历程。
Chroot Jail
虚拟化容器技术可以追溯到上个世纪,1979 年,贝尔实验室为 Unix V7 操作系统的发布进行最后的开发和测试,为了提高系统级别软件构建和测试的效率,他们开始设计和构思在现有操作系统环境下“隔离”出一个可供软件进行构建和测试的环境,通过一个简单的命令就可以改变程序的“视图”,每次只要在当前目录里放置一个完整操作系统文件系统部分,该软件运行所需的所有依赖就完备了。这样开发者间接拥有了应用基础设施“快速销毁和重现”的能力,而不需要在环境搭好之后进入到环境里去进行应用所需的依赖安装和配置。于是 chroot(Change Root)的技术就诞生了,用来重定向进程及其子进程的根目录到一个文件系统上的新位置,被隔离出来的环境被赋予了一个很形象的名字:Chroot Jail,Chroot 也算是人类第一次进入“进程隔离”的大门。chroot 也逐渐成为了开发测试环境配置和应用依赖管理的一个重要工具。2000 年,同属 Unix 家族的 FreeBSD 操作系统发布了“jail”命令,把” 隔离“这个概念扩展到了进程的完整视图,拥有独立进程环境和用户体系,分配独立的 IP 地址。chroot 打开进程环境隔离的大门,但 FreeBSD Jails 才实现真正进程的沙箱化,这种沙箱是通过操作系统级别的隔离与限制能力来实现而非硬件虚拟化技术。不过在 Jails 时代,“云”的概念尚未普及, 进程沙箱技术一直局限在了小众的场景世界里。
LXC
Google 在 2006 年之间发布了一个名为 Process Container 技术,提供操作系统级别的资源限制、优先级控制、资源审计能力和进程控制能力,与沙箱理念不谋而合,这个技术也是 Google 内部基础设施得以实现的基本诉求和基础依赖,也成为了 Google 眼中“容器”技术的雏形,Process Container 推出后的第二年就进入了 Linux 内核主干。但因 Container 在 Linux 内核中另有它用,Process Container 在 Linux 中被正式改名为 Cgroups。2008 年 LXC 把 Cgroups 的资源管理和限制能力和 Linux Namespace 的视图隔离能力组合在一起,提交并正式进入 Linux 内核。并伴随着 Linux OS 开始迅速占领商用服务器市场的契机,LXC 受到了 chroot 等未曾有的关注。
PaaS
2008 年后世界上互联网巨头们 AWS,Microsoft 开始持续加大在公有云的投入,思考和落地在 IaaS 之上构建新的技术与商业价值,催生出了我们现在都耳熟能详的新兴产业:PaaS。2009 年开源项目 Cloud Foundry 发布,第一次对 PaaS 的概念完成了清晰而完整的定义。PaaS 定位是应用的托管服务,其理念“PaaS 对应用的直接管理、编排和调度让开发者专注于业务逻辑而非基础设施”在云计算行业得到了一致的认同,借助 PaaS 离开发者足够近的优势,从而锁定云服务,这就要求 PaaS 必须不依赖 IaaS 底层技术基础实施,能够高效打包封装用户的应用,快速的部署到低层基础设施上。开源、中立、轻量、敏捷的 Linux 容器技术成了 PaaS 实现应用托管和部署的绝佳选择,Linux 容器已经跳出了进程沙箱的局限性,开始扮演着“应用容器”的角色,容器和应用画上了等号,这才最终使得平台层系统能够实现应用的全生命周期托管。
Docker
2013 年一家叫 dotCloud 的公司发布了一个颠覆性的开源项目 Docker,Docker 通过容器镜像,将应用运行所需的完整环境(包括操作系统的文件系统)进行整体打包,实现“一次发布、随处运行”,比通过 Buildpack 把一个应用可运行文件如 WAR 包和脚本配置进行封装,连制作一个开发和测试环境都无法统一的技术要先进高明的多。同时 Docker 借鉴 Git 的思想,通过 DockerHub 这样的镜像托管仓库,能够让高效分发和交付你的软件服务到世界任何地方。
终极来看 Docker 其实一直在思考和解决的一个问题是:软件究竟应该通过什么样的方式进行交付?容器镜像给出一份完美的答案。就连 Docker 自己都说自己只是“站在巨人肩膀上”,确实没有过去十几年 Linux 容器等技术的完善和发展,一个创业公司的开源项目就能颠覆整个行业恐怕是痴人说梦。
Kubernetes
容器镜像已经成为了云时代软件交付与分发的事实标准。Docker、Mesosphere、Kubernetes 在“应用”有着不同理解和顶层设计,Docker 体系以“单一容器”为核心的应用定义方式,而 Kubernetes 则提出了一整套容器化设计模式和对应的控制模型,从而明确了如何真正以容器为核心构建能够真正跟开发者对接起来的应用交付和开发范式,最终 Kubernetes 取得到了云时代应用编排的关键领导地位。
云原生
Kubernetes 已发展为云时代应用编排的事实标准,作为连通“云”与“应用”的高速公路,以标准、高效的方式将“应用”快速交付到世界上任何一个位置,既可以是最终用户,也可以是 PaaS/Serverless 从而催生出更加多样化的应用托管生态。其背后的思想和目标就是最大程度的发挥容器和云的价值,这正是整个“云原生”的理念。
2、什么是云原生?
云原生定义
CNCF(Cloud Native Computing Foundation,成立于 2015 年,致力于云原生技术普及和可持续发展的基金会)给出的定义:
“Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.
These techniques enable loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil.”
翻译过来:
“云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用。云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式 API。
这些技术能够构建容错性好、易于管理和可观测的松耦合系统。结合可靠的自动化手段,云原生技术使工程师能够轻松地对系统作出频繁和可预测的重大变更。“
你如果是第一次读这个定义,会不会感觉有点晦涩难懂。构建弹性可扩展应用,容错性好、易管理、可观测系统,表达的太宽泛了,并不代表一种特定的概念和方法,这些目标我们用一系列方法论、设计思想和设计模式也可以达成,这个定义还是很难让我们抓住云原生的本质是什么。我们先略过 CNCF 的官方定义,从云原生的形态和终极价值的角度来解剖和理解云原生。
应用以原生形态被设计生在、长在云上,以充分发挥云的优势
云原生,从字面上拆成 2 个词,“云”和“原生”,云就是强大的云计算能力,也是前提。原生是对企业应用来讲的,云原生时代的应用被设计成“生在云上,长在云上”。应用是原生的,只包含业务代码,意味着需要最大化剥离应用中非业务的代码和功能,让云基础设施来接管(包括 IaaS、PaaS 等),应用可最大化利用云的优势,充分享受云计算的技术红利。
讨论云原生,是在讨论一系列架构原则和模式的集合。
开发者遵循一种新的软件开发、发布和运维模式,使得云原生下的应用可以从大量非业务/非功能性(高可用挑战、自动扩缩容挑战、安全挑战、运维升级挑战等)需求和挑战中解脱出来,从而能够最大化聚焦在业务价值交付上。用户采用一条低心智负担的、敏捷的,能够以可扩展、可复制和自动化的方式最大化地利用云的能力、发挥云的价值的最佳路径来构建和交付应用,开发复杂度和运维工作量都得到极大降低。云原生背后的一个价值观是:将复杂留给云,将简单留给应用。
所以云原生背后蕴含了一组架构原则,包括:服务化、弹性、可观测性、韧性、自动化、零信任、架构持续演进。也包括了一组架构模式:微服务架构模式、Service Mesh 架构模式、Serverless 模式、存储计算分离模式、分布式事务模式、可观测架构、事件驱动架构。
讨论云原生,是在讨论云原生能给企业和用户带来什么价值。
云把软硬件的能力升级成服务,形成强大的技术服务能力和资源优化能力,让用户以低成本、敏捷的方式构建数字化应用,开发者聚焦在业务开发,系统天然具备高可用、高移植性、高弹性等特点,从而赋予企业和业务更敏捷的迭代和更高效的软件交付能力,企业更快推出新的产品功能和点子到市场和用户,帮助业务更快试错和创新,在如今日新月异、竞争越来越剧烈的市场大环境下打造企业的核心竞争力。
云原生本质上也是一套“以利用云计算技术为用户降本增效”的最佳实践与方法论。
讨论云原生,是在讨论云原生的技术。
云原生开源技术生态基本统一了软件交付和运维的模式。容器技术和 Kubernetes 服务编排技术的结合,解决了应用部署自动化、标准化、配置化问题。微服务通过把巨石应用拆解为若干单功能的服务,减少了服务间的耦合性,让开发和部署更加便捷和灵活,可以有效降低开发周期。Service Mesh 让中间件的升级和应用系统的升级完全解耦,在运维和管控方面的灵活性获得提升。Serverless 让运维对开发透明,对于应用所需资源进行自动伸缩。FaaS 是 Serverless 的一种实现,则更加简化了开发运维的过程,从开发到最后测试上线都可以在一个集成开发环境中完成。所以,云原生代表一系列的技术(容器技术、云原生微服务、Serverless、Service Mesh 技术、DevOps),来最大化利用云的能力,提升开发效率,提升应用交付质量和速度。
所以,到底什么是云原生?
我个人更愿意这样来解释云原生:
云原生代表着一种新的软件设计理念,应用从一开始就被设计为长在云上、生在云上,让云基础设施来接管应用中的非业务性代码和功能,用户专注于真正有价值的业务代码,充分发挥云的优势,以灵活、低成本的方式构建弹性、可扩展的应用;同时,云原生也代表着一系列的方法论、实践和技术,包括容器、微服务、Serverless、DevOps、服务网格等。这些方法论和技术,帮助我们构建韧性、弹性、可移植、可扩展的应用,提升企业的软件交付能力,赋予企业敏捷迭代、快速试错和创新的竞争力。
什么是云原生或许会一直在变,也或许永远没有确切和标准的答案,但正是这种“永远没有确切定义”的特点让云原生保持了持续生命力,其理念和技术不断革新和演进,推动云计算向前发展。
3、云原生的架构原则和设计模式
云原生也给出了若干应用架构原则和设计模式,作为应用的架构控制面,引导和规范架构师设计出高容错性、弹性和可扩展的应用。
一、云原生架构原则
1、服务化原则
通过服务化把不同生命周期的模块分离出来,独立业务迭代,避免迭代频繁的模块被变化低的模块拖慢,从而提升整体迭代速度和稳定性。服务化架构面向接口契约编程,服务内职责和功能高度内聚,通过提取应用中公共功能模块大大提升了软件的复用性。云原生架构把服务化放在首位,还在于服务化从架构层面抽象化业务模块之间的关系,标准化服务流量的传输,从而帮助业务模块进行基于服务流量的策略控制和治理,服务是用什么语言编写的并不关心。
2、弹性原则
弹性是指系统的部署规模可以随着业务流量和容量变化而自动伸缩,无须根据事先的容量规划准备固定的硬件和软件资源。好的弹性能力不仅缩短了从采购到上线的时间,让企业不用操心额外软硬件资源的成本支出,无须为闲置成本买单,降低了企业的 IT 成本,最重要的是当业务面临突发性的容量扩张和流量增长时,不会因为软硬件资源储备不足而支撑不了,避免让企业错过业务和用户增长的好机会,保障了企业收益。
3、可观测原则
建立可观测性的主要目标是对服务 SLO(Service Level Objective)进行度量,从而优化 SLA,因此架构设计上需要为各个组件定义清晰的 SLO,包括并发度、耗时、可用时长、容量等。大规模集群应用之间的调用关系、宕机和故障原因是极其复杂的,可观测性可使运维、开发和业务人员实时掌握软件运行情况,并结合多个维度的数据指标,获得关联分析和问题归因分析的能力,不断对业务健康度和用户体验进行数字化衡量和持续优化。
4、韧性原则
韧性代表了当软件所依赖的软硬件组件出现各种异常时,软件表现出来的抵御能力,这些异常通常包括硬件故障、硬件资源瓶颈(如 CPU/ 网卡带宽耗尽)、业务流量超出软件设计能力、影响机房工作的故障和灾难、软件 bug、黑客攻击等对业务不可用带来致命影响的因素。韧性从多个维度诠释了软件持续提供业务服务的能力。从架构设计上,韧性包括服务异步化能力、重试 / 限流 / 降级 /熔断 / 反压、主从模式、集群模式、AZ 内的高可用、单元化、跨 region 容灾、异地多活容灾等。
5、自动化原则
技术往往是把“双刃剑”,容器、微服务、DevOps、大量第三方组件的使用,在降低分布式复杂性和提升迭代速度的同时,因为整体增大了软件技术栈的复杂度和组件规模,所以不可避免地带来了软件交付的复杂性。GitOps、Kubernetes operator 和大量自动化交付工具在 CI/CD 流水线中的实践,一方面标准化企业内部的软件交付过程,另一方面在标准化的基础上进行自动化,通过配置数据自描述和面向终态的交付过程,让自动化工具理解交付目标和环境差异,实现整个软件交付和运维的自动化。
6、零信任原则
零信任是对系统安全架构和设计思想的重新审视,在默认情况下不应该信任网络内外部的任何人/设备/系统,要通过认证和授权构建访问控制的基础。并且零信任也体现应用的高可用和容错性建设思想中,假设一切上下游、中间件、网络等都有可能出现故障,反推应用自身建立熔断、限流、降级、兜底等能力,从而构建韧性、自愈和高容错行的应用。
7、架构持续演进原则
技术和业务的演进速度非常快,很少有一开始就清晰定义和设计并在整个软件生命周期里面都适用的架构,相反往往还需要对架构进行一定范围内的重构,因此云原生架构本身也应该和必须是一个具备持续演进能力的架构,而不是一个封闭式架构。增量迭代、目标选取,架构治理和风险控制。是在业务高速迭代情况下的架构、业务、实现平衡关系。
二、云原生架构模式
1、服务化架构模式
求以模块为颗粒度划分一个软件服务,分离模块和部署关系,不同服务按需独立缩扩容,按照业务属性独立升级迭代,提升整体迭代效率。微服务以接口契约定义彼此业务关系,以标准协议确保彼此的互联互通,结合 DDD(领域模型驱动)、TDD(测试驱动开发)、容器化部署提升每个接口的代码质量和迭代速度。
2、Mesh 架构模式
Mesh 化架构是把中间件框架(比如 RPC、缓存、异步消息等)从业务进程中分离,让中间件 SDK 与业务代码进一步解耦,从而使得中间件升级对业务进程没有影响,分离后在业务进程中只保留很“薄”的 Client 部分,Client 通常很少变化,只负责与 Mesh 进程通讯,原来需要在 SDK 中处理的流量控制、安全等逻辑由 Mesh 进程完成。实施 Mesh 化架构后,大量分布式架构模式(熔断、限流、降级、重试、反压、隔仓⋯⋯)都由 Mesh 进程完成,即使在业务代码的制品中并没有使用这些三方软件包;同时获得更好的安全性(比如零信任架构能力)、按流量进行动态环境隔离、基于流量做冒烟 / 回归测试等。
3、Serverless 模式
Serverless 将“部署”这个动作从运维中“收走”,使开发者不用关心应用在哪里运行,更不用关心装什么 OS、怎么配置网络、需要多少 CPU ⋯。是否适合于 Serverless 运算。如果应用是有状态的,云在进行调度时可能导致上下文丢失,毕竟 Serverless 的调度不会帮助应用做状态同步;如果应用是长时间后台运行的密集型计算任务,会得不到太多 Serverless 的优势;如果应用涉及到频繁的外部 I/O(网络或者存储,以及服务间调用),也因为繁重的 I/O 负担、时延大而不适合。Serverless 非常适合于事件驱动的数据计算任务、计算时间短的请求 / 响应应用、没有复杂相互调用的长周期任务。
3、存储计算分离模式
在云环境中,推荐把各类暂态数据(如 session)、结构化和非结构化持久数据都采用云服务来保存,从而实现存储计算分离。一些状态如果保存到远端缓存,会造成交易性能的明显下降,比如交易会话数据太大、需要不断根据上下文重新获取等,则可以考虑通过采用 Event Log + 快照(或 Check Point)的方式,实现重启后快速增量恢复服务,减少不可用对业务的影响时长。
4、事件驱动架构
本质上是一种应用/ 组件间的集成架构模式。事件具有 schema,所以可以校验 event 的有效性,同时 EDA 具备 QoS 保障机制,也能够对事件处理失败进行响应。事件驱动模式一般用在下面场景下:
增强服务韧性:由于服务间是异步集成的,也就是下游的任何处理失败甚至宕机都不会被上游感知。
CQRS(Command Query Responsibility Segregation):把对服务状态有影响的命令用事件来发起,而对服务状态没有影响的查询才使用同步调用的 API 接口;结合 EDA 中的 Event Sourcing 可以用于维护数据变更的一致性,当需要重新构建服务状态时,把 EDA 中的事件重新“播放”一遍即可。
构建开放式接口:在 EDA 下,事件的提供者并不用关心有哪些订阅者,不像服务调用的场景 —— 数据的产生者需要知道数据的消费者在哪里并调用它,因此保持了接口的开放性;
事件流处理:应用于大量事件流(而非离散事件)的数据分析场景,典型应用是基于 Kafka 的日志处理。
基于事件触发的响应:在 IoT 时代大量传感器产生的数据,不会像人机交互一样需要等待处理结果的返回,天然适合用 EDA 来构建数据处理应用。
数据变化通知:在服务架构下,往往一个服务中的数据发生变化,另外的服务会感兴趣,比如用户订单完成后,积分服务、信用服务等都需要得到事件通知并更新用户积分和信用等级。
5、可观测架构
可观测架构包括 Logging、Tracing、Metrics 三个方面,其中 Logging 提供多个级别(verbose/ debug/warning/error/fatal)的详细信息跟踪,由应用开发者主动提供;Tracing 提供一个请求从前端 到后端的完整调用链路跟踪,对于分布式场景尤其有用;Metrics 则提供对系统量化的多维度度量。
4、云原生主要技术
云原生背后包含了一系列的技术,通过在应用中采纳和实践这些技术,来让我们享受云计算的优势和红利,让我们聚焦业务价值交付,提升企业敏捷性和创新能力。
一、容器
为了更好理解容器是什么,有什么价值,我们有必要回顾一下软件部署架构和交付的历史,下面这张图(相信大家已经看过无数次了)可以很好的描述软件部署的发展三阶段:
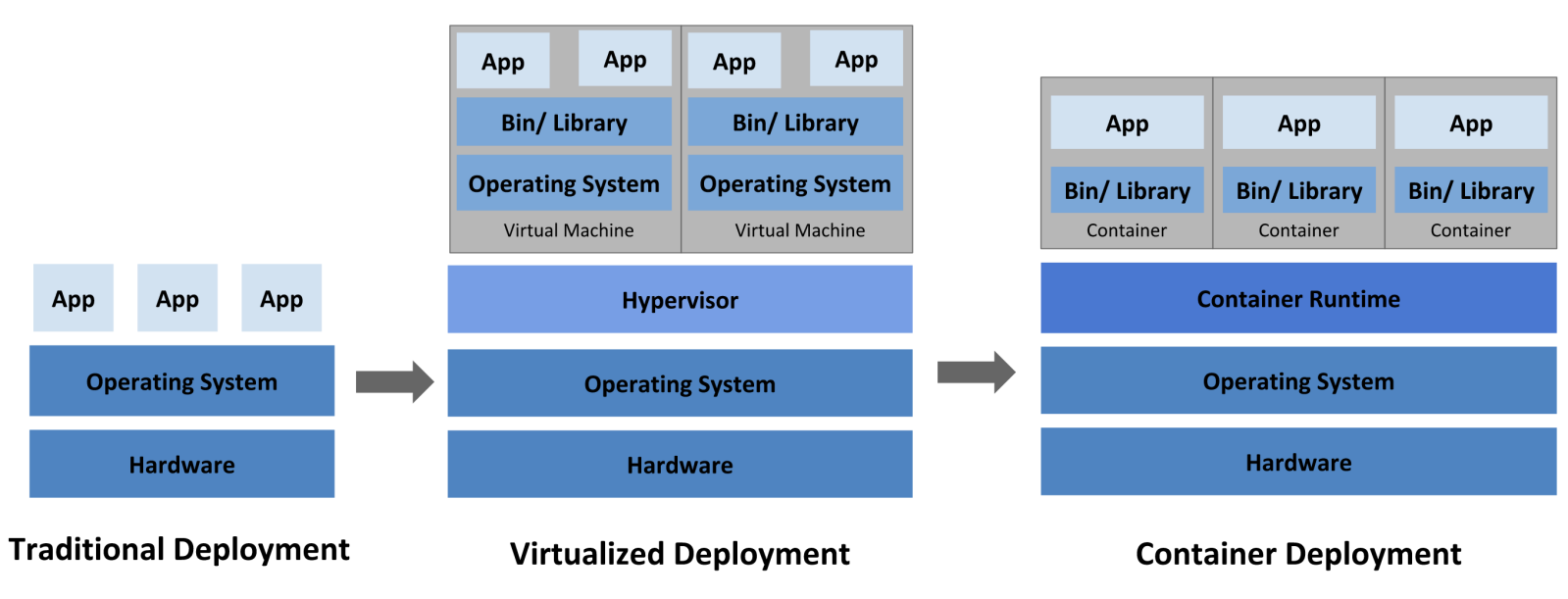
1、传统部署时代:
早期,各个组织机构在物理服务器上运行应用程序。无法为物理服务器中的应用程序定义资源边界,这会导致资源分配问题。例如,如果在物理服务器上运行多个应用程序,则可能会出现一个应用程序占用大部分资源的情况,结果可能导致其他应用程序的性能下降。一种解决方案是在不同的物理服务器上运行每个应用程序,但是由于资源利用不足而无法扩展,并且维护许多物理服务器的成本很高。
2、虚拟化部署时代:
作为解决方案,引入了虚拟化。虚拟化技术允许你在单个物理服务器的 CPU 上运行多个虚拟机(VM)。 虚拟化允许应用程序在 VM 之间隔离,并提供一定程度的安全,因为一个应用程序的信息 不能被另一应用程序随意访问。
虚拟化技术能够更好地利用物理服务器上的资源,并且因为可轻松地添加或更新应用程序而可以实现更好的可伸缩性,降低硬件成本等等。每个 VM 是一台完整的计算机,在虚拟化硬件之上运行所有组件,包括其自己的操作系统。
3、容器部署时代:
容器也是一种沙箱思想的体现,屏蔽不同环境之间的差异,进而基于容器做标准化的软件交付。开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Linux 或 Windows 机器上,所以也可以称容器是一个视图隔离、资源可限制、独立文件系统(镜像是容器所需的二进制文件、配置文件以及依赖的文件集合)的进程集合。
VM 是对硬件资源的虚拟,Docker 是对操作系统的虚拟。相比 VM,Docker 比虚拟化少了两层: hypervisor 层和 GuestOS 层,使用 Docker Engine 进行调度和隔离,所有应用共用主机操作系统,因此在体量上,Docker 较虚拟机更轻量级,在性能上优于虚拟化,接近裸机性能。
正如集装箱的出现加速了贸易全球化进程,以容器为代表的技术作推动和加速云计算和云原生普及和发展。航运业使用物理容器(集装箱)来打包和隔离不同的货物,以便在轮船、火车、卡车和飞机上运输,云原生时代,把应用程序的代码与相关配置文件、库以及运行应用所需的依赖项捆绑在一起,让应用可以跨云平台和技术设施,以一致和可靠的方式运行。这使得开发者和 IT 专业人员能够更快、更安全地创建和部署应用程序。容器技术在应用程序的整个生命周期工作流中提供了高隔离、可移植性、灵活性、可伸缩性和控制优势。
容器具有如下优势:
敏捷应用程序的创建和部署:与使用 VM 镜像相比,提高了容器镜像创建的简便性和效率。
持续开发、集成和部署:通过快速简单的回滚(由于镜像不可变性),支持可靠且频繁的容器镜像构建和部署。
关注开发与运维的分离:在构建/发布时而不是在部署时创建应用程序容器镜像, 从而将应用程序与基础架构分离。
可观察性不仅可以显示操作系统级别的信息和指标,还可以显示应用程序的运行状况和其他指标信号。
跨开发、测试和生产的环境一致性:在便携式计算机上与在云中相同地运行。
跨云和操作系统发行版本的可移植性:可在 Ubuntu、RHEL、CoreOS、本地、 Google Kubernetes Engine 和其他任何地方运行。
以应用程序为中心的管理:提高抽象级别,从在虚拟硬件上运行 OS 到使用逻辑资源在 OS 上运行应用程序。
松散耦合、分布式、弹性、解放的微服务:应用程序被分解成较小的独立部分,并且可以动态部署和管理- 而不是在一台大型单机上整体运行。
资源隔离:可预测的应用程序性能。
资源利用:高效率和高密度。
Docker 是一个典型的开源、流行应用容器引擎,已成为云时代应用分发和交付的事实标准。Docker 使应用通过“自包含”的方式打包应用,使应用以敏捷、可扩展、可复制的方式发布在云上,极大提升应用的可移植性、部署密度和弹性,最大化发挥出云的能力。这也就是容器技术对云发挥出的革命性影响所在,容器技术让管理应用等于管理容器本身,因此容器技术是云原生技术的核心底盘。
二、Kubernetes
1、什么是 Kubernetes?
Docker 体系是以“单一容器”为核心的应用定义方式,而应用程序扩展到跨多个服务器部署的多个容器,因此对其进行操作变得更加复杂。如何协调和安排多个容器?应用程序中所有不同的容器之间如何实现相互通信?如何缩放多个容器实例?这就需要一个可以对应用进行编排和调度的计算。Kubernetes。
Docker、Mesosphere、Kubernetes 在“应用”有着不同理解和顶层设计,而 Kubernetes 则提出了一整套容器化设计模式和对应的控制模型,从而明确了如何真正以容器为核心构建能够真正跟开发者对接起来的应用交付和开发范式,最终 Kubernetes 取得到了云时代应用编排的关键领导地位。
Kubernetes 作为大规模分布式资源调度和编排的引擎,已成为云时代容器调度和编排的事实标准,现在很多人也称 Kubernetes 为云原生的操作系统。Kubernetes 以一种可移植、可伸缩且可扩展的方式实现基于容器的应用程序,可实现自动化的资源调度、应用自动部署和回滚、弹性伸缩、服务发现和负载均衡、自我修复/自愈,通过屏蔽了底层架构的复杂性和差异性,帮助应用平滑运行在不同基础设施上。
总结来说,Kunbernetes 可以帮助我们:
资源调度
根据应用请求的资源量 CPU、Memory,或者 GPU 等设备资源,在集群中选择合适的节点来运行应用。Kubernetes 可以更加充分地利用硬件,最大程度获取运行企业应用所需的资源。
应用部署和管理
支持应用的自动发布与应用的回滚,以及与应用相关的配置的管理。也可以自动化存储卷的编排,让存储卷与容器应用的生命周期相关联。
自动修复
Kubernetes 让应用机器具备自愈能力,通过监测这个集群中所有的宿主机,重新启动失败的容器、替换容器、杀死不响应用户定义的运行状况检查的容器,实行机器自动修复。这一切对于客户端来说都是透明和自动化的,极大简化了运维管理的复杂性。
服务发现和负责均衡
通过 Service 资源出现各种应用服务,结合 DNS 和多种负载均衡机制,支持容器化 应用之间的相互通信。
弹性伸缩
K8s 可以监测业务上所承担的负载,如果这个业务本身的 CPU 利用率过高,或者响应时间过长, 它可以对这个业务进行自动扩容。当发现 CPU 利用率过低,或 QPS 下降,K8s 也可以触发自动缩容,避免资源闲置。
2、Kubernetes 本质
Kubernetes 的核心能力是容器调度和编排。定位是应用基础设施,介于 IaaS 与 PaaS 之间,面向平台开发者,让每个人能够开发自己的 PaaS。对比 Linux 与 Kubernetes 的概念模型,他们都是定义了开放的、标准化的访问接口:向下封装资源,向上支撑应用,从某种意义上来讲,Kubernetes 已经成为云时代的操作系统。
Kubernetes 架构的本质就是 2 个东西:声明式 API 与控制器模式。声明式 API 是对底层基础实施各种能力的声明式 API 定义,也就是建模成一份数据,理论上声明式 API 可以对一切应用基础实施“能力”进行建模,数据中的内容是对该应用基础实施期望状态的描述。数据的增删查改会触发控制器执行对应的运维逻辑,以此来驱动底层基础实施向数据所定义的期望状态逼近。
3、Kubernetes 架构和概念
3.1、架构
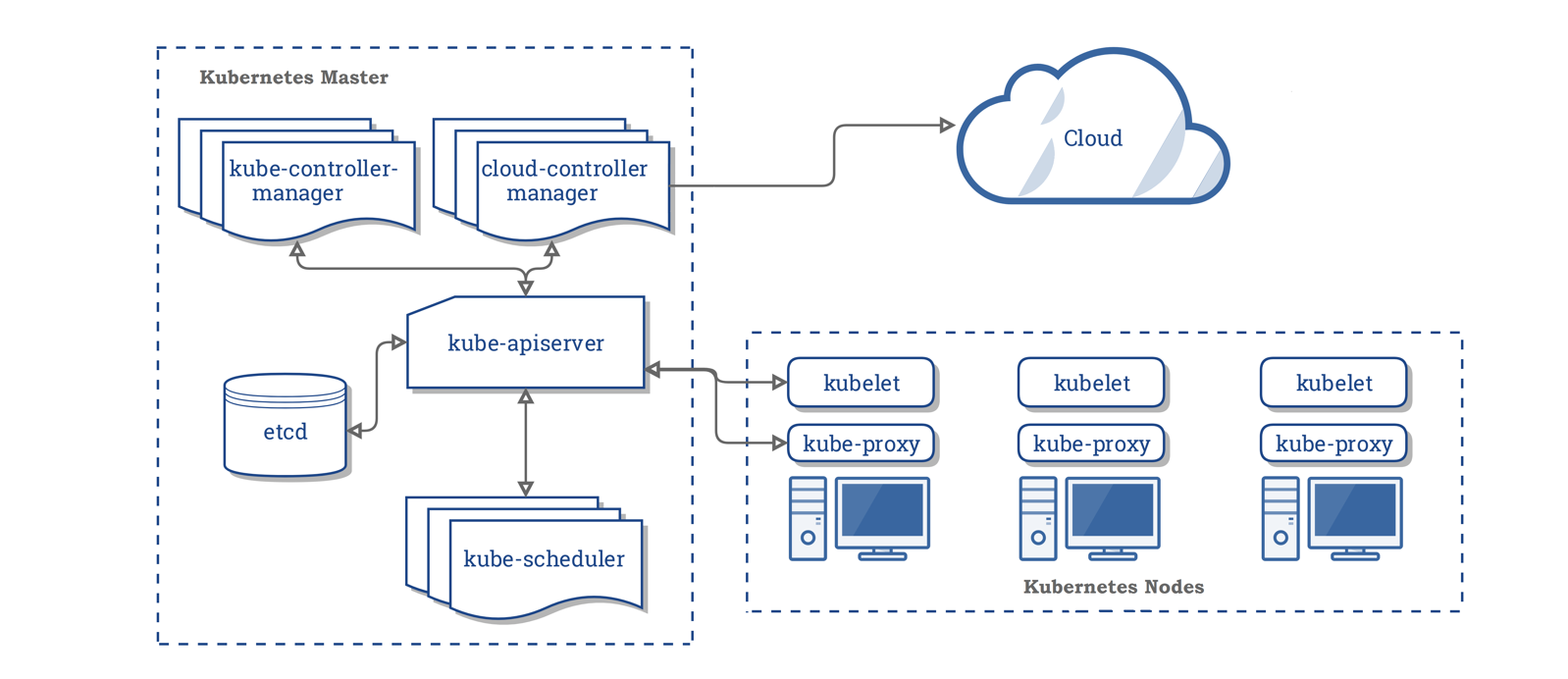
一个 K8s 集群由一组节点组成,这些节点可以是虚拟机也可以是物理机,从职责来看这些节点可以分为 2 类。一类是负责管理整个 K8s 集群的控制平面,通常运行在 Master 节点上,用来暴露 API 和接口来定义、 部署容器和管理容器的生命周期。控制平面的组件对集群做出全局决策(比如调度),以及检测和响应集群事件(例如,当不满足部署的 replicas 字段时,启动新的 pod),包含了 kube-apiserver、kube-controller-manager、kube-scheduler 和 ected;另一类是工作节点(Node),Node 是 Kubernetes 集群架构中运行 Pod 的服务节点,是 Kubernetes 集群操作的单元,用来承载被分配 Pod 的运行,是 Pod 运行的宿主机。运行 Docker Eninge 服务,守护进程 kunelet 及负载均衡器 kube-proxy。
3.2、正常运行的 Kubernetes 集群所需的各种组件。
控制平面组件
- kube-apiserver
作为 Kubernetes 系统的入口,其封装了核心对象的增删改查操作,以 RESTful API 接口方式提供给外部客户和内部组件调用,集群内各个功能模块之间数据交互和通信的中心枢纽。
只有 API Server 与存储通信,其他模块通过 API Server 访问集群状态。这样第一,是为了保证集群状态访问的安全。第二,是为了隔离集群状态访问的方式和后端存储实现的方式:API Server 是状态访问的方式,不会因为后端存储技术 etcd 的改变而改变。加入以后将 etcd 更换成其他的存储方式,并不会影响依赖依赖 API Server 的其他 K8s 系统模块。
- etcd
etcd 是兼具一致性和高可用性的轻量级键值数据库,etcd 是 Kubernetes 的关键组件,是 K8s 集群运行的大脑,因为它存储了集群的整个状态:其配置,规格以及运行中的工作负载的状态。主要使用场景包括:
服务发现:分布式系统中,需要成百上千个进程来提供一组对等的服务可以利用 etc 来解决资源注册的问题,当这一组后端进程被调度,在进程内部启动之后,可以将自身所在的地址注册到 etcd。API 网关能够通过 etcd 及时感知到后端进程的地址,这样当后端进程发生故障迁移的时候,会重新注册到 etcd 中,使得 API 网关能够及时地感知到新的集群地址。同时,因为 etcd 提供的 Lease 操作,可以及时感知到进程状态的变化,如果进程运行过程中死掉了,那么网关可以及时感知到进程状态的变化,从而将流量自动地切到其他的进程。(资源注册,存活性检测,API 网关无状态可水平扩展,支持上万个进程的规模)
分布式系统并发控制:执行一些计算任务的时候,通常情况下需要控制任务的并发度。因为任务到了后端服务,通常是有容量瓶颈的(分布式信号量,自动踢出故障节点,存储进程的执行状态)
Kubernetes 元数据存储:用于保存集群所有的网络配置和对象的状态信息。通过 watch 机制,实时通知配置变化,通过 raft 算法保持系统数据的 cp 和强一致性。
Leader 选举
- kube-scheduler
Kubernetes Scheduler 确定如何在工作器节点之间部署 Pod 和 ReplicaSet,以及如何向这些节点分发流量。在整个系统中承担了“承上启下”的重要功能,“承上”是指它负责接收 Controller Manager 创建的新 Pod,为其调度至目标 Node;“启下”是指调度完成后,目标 Node 上的 kubelet 服务进程接管后继工作,负责 Pod 接下来生命周期。在整个调度过程中涉及三个对象,分别是待调度 Pod 列表、可用 Node 列表,以及调度算法和策略。Kubernetes Scheduler 通过调度算法调度为待调度 Pod 列表中的每个 Pod 从 Node 列表中选择一个最适合的 Node 来实现 Pod 的调度。随后,目标节点上的 kubelet 通过 API Server 监听到 Kubernetes Scheduler 产生的 Pod 绑定事件,然后获取对应的 Pod 清单,下载 Image 镜像并启动容器。
- kube-controller-manager
kube-controller-manager 作为集群内部的管理控制中心,负责集群内的 Node、Pod 副本、服务端点(Endpoint)、命名空间(Namespace)、服务账号(ServiceAccount)、资源定额(ResourceQuota)的管理,当某个 Node 意外宕机时,Controller Manager 会及时发现并执行自动化修复流程,确保集群始终处于预期的工作状态。每个控制器都是一个单独的进程, 但是为了降低复杂性,它们都被编译到同一个可执行文件,并在一个进程中运行。
每个 Controller 通过 API Server 提供的接口实时监控整个集群的每个资源对象的当前状态,当发生各种故障导致系统状态发生变化时,会尝试将系统状态修复到“期望状态”。一些典型的 Controller 有:
节点控制器(Node Controller): 定期检查 Node 的健康状态,标识出(失效|未失效)的 Node 节点,负责在节点出现故障时进行通知和响应。
任务控制器(Job controller): 监测代表一次性任务的 Job 对象,然后创建 Pods 来运行这些任务直至完成。
端点控制器(Endpoints Controller): 关联 Service 和 Pod,创建 Endpoints 为 Service 的后端,当 Pod 发生变化时,实时更新 Endpoints。
服务帐户和令牌控制器(Service Account & Token Controllers): 为新的命名空间创建默认帐户和 API 访问令牌。
控制平面组件
- kubelet
在 Kubernetes 集群中,在每个 Node(又称 Worker)上都会启动一个 kubelet 服务进程。该进程用于处理 Master 下发到本节点的任务,管理 Pod 及 Pod 中的容器。每个 kubelet 进程都会在 API Server 上注册节点自身的信息,定期向 Master 汇报节点资源的使用情况,并通过 cAdvisor 监控容器和节点资源。
- kube-proxy
kube-proxy 运行在所有节点上,它监听 apiserver 中 service 和 endpoint 的变化情况,创建路由规则以提供服务 IP 和负载均衡功能。简单理解此进程是 Service 的透明代理兼负载均衡器,其核心功能是将到某个 Service 的访问请求转发到后端的多个 Pod 实例上。iptables 与 IPVS 都是基于 Netfilter 实现的,但因为定位不同,二者有着本质的差别:iptables 是为防火墙而设计的;IPVS 则专门用于高性能负载均衡,并使用更高效的数据结构(Hash 表),允许几乎无限的规模扩张。
- 容器运行时(Container Runtime)
容器运行环境是负责运行容器的软件。Kubernetes 支持多个容器运行环境: Docker、 containerd、CRI-O 以及任何实现 Kubernetes CRI (容器运行环境接口)。
此外,K8s 还有一系列的插件组件,可以参考:Kubernetes Addons
3.3、Kubernetes 对象
API 对象是 K8s 集群中的管理操作单元。K8s 集群系统每支持一项新功能,引入一项新技术,一定会新引入对应的 API 对象,支持对该功能的管理操作。例如副本集 Replica Set 对应的 API 对象是 RS。
每个 API 对象都有 3 大类属性:元数据 metadata、规范 spec 和状态 status。元数据是用来标识 API 对象的,每个对象都至少有 3 个元数据:namespace,name 和 uid;除此以外还有各种各样的标签 labels 用来标识和匹配不同的对象。规范 spec 描述了用户期望 K8s 集群中的分布式系统达到的理想状态(Desired State),例如用户可以通过复制控制器 Replication Controller 设置期望的 Pod 副本数为 3;status 描述了系统实际当前达到的状态(Status),例如系统当前实际的 Pod 副本数为 2;那么复制控制器当前的程序逻辑就是自动启动新的 Pod,争取达到副本数为 3。
K8s 中所有的配置都是通过 API 对象的 spec 去设置的,也就是用户通过配置系统的理想状态来改变系统,这是 k8s 重要设计理念之一,即所有的操作都是声明式(Declarative)的而不是命令式(Imperative)的。声明式的操作,相对于命令式操作,对于重复操作能实现幂等效果,这对于容易出现数据丢失或重复的分布式环境来说是很重要的。另外,声明式操作更容易被用户使用,可以使系统向用户隐藏实现的细节,隐藏实现的细节的同时,也就保留了系统未来持续优化的可能性。此外,声明式的 API,同时隐含了所有的 API 对象都是名词性质的,例如 Service、Volumn 这些 API 都是名词,这些名词描述了用户所期望得到的一个目标分布式对象。
3.3.1、Pod
Pod 是 Kubernetes 进行创建、调度和管理的最小的原子单位,是 Kubernetes 集群中的一个应用实例。Pod 是一个或多个相关容器的组合,Pod 如果有是多个容器,这些容器一般是“超亲密关系”,并共享存储、网络资源。一般 Pod 有 2 种使用方式。1 是单容器 Pod,最常见的应用方式;2 是多容器 Pod,对于多容器 Pod,Kubernetes 会保证所有的容器都在同一台物理主机或虚拟主机中运行。多容器 Pod 是相对高阶的使用方式,除非应用耦合特别严重,一般不推荐使用这种方式。一个 Pod 内的容器共享 IP 地址和端口范围,容器之间可以通过 localhost 互相访问。
Pod 并不提供保证正常运行的能力,因为可能遭受 Node 节点的物理故障、网络分区等等的影响,整体的高可用是 Kubernetes 集群通过在集群内调度 Node 来实现的。通常情况下我们不要直接创建 Pod,一般都是通过 Controller 来进行管理。Pod 提供了比容器更高层次的抽象,是一个虚拟概念,能带来明显的好处:
- Pod 做为一个可以独立运行的服务单元,简化了应用部署的难度,以更高的抽象层次为应用部署管提供了极大的方便。
- Pod 做为最小的应用实例可以独立运行,因此可以方便的进行部署、水平扩展和收缩、方便进行调度管理与资源的分配。
- Pod 中的容器共享相同的数据和网络地址空间,Pod 之间也进行了统一的资源管理与分配。
Sidecar
我们可以在一个 Pod 中按照顺序启动一个或多个辅助容器,来完成一些独立于主进程(主容器)之外的工作,完成工作后这些辅助容器会依次退出,之后主容器才会启动,这种容器设计模式叫做 sidecar。比如对于前端 Web 应用,如果把构建后的 Js 项目放到 Nginx 镜像的/usr/share/nginx/html 目录下,Nginx 和 Js 应用做成一个镜像运行容器,每次应用有更新或者 Nginx 要做升级、更新配置操作都需要重新做一个镜像,非常麻烦。有了 Pod 之后,这样的问题就很容易解决了。我们可以把前端 Web 应用和 Nginx 分别做成镜像,然后把它们作为一个 Pod 里的两个容器"组合"在一起。
所有 spec.initContainers 定义的容器,都会比 spec.containers 定义的用户容器先启动。并且,Init 容器会按顺序逐一启动,直到它们都启动并且退出了,用户容器才会启动。这就是容器设计模式里最常用的一种模式:sidecar。顾名思义,sidecar 指的就是我们可以在一个 Pod 中,启动一个辅助容器,来完成一些独立于主进程(主容器)之外的工作。
Pod 和控制器
你可以使用工作负载资源来创建和管理多个 Pod。 资源的控制器能够处理副本的管理、上线,并在 Pod 失效时提供自愈能力。 例如,如果一个节点失败,控制器注意到该节点上的 Pod 已经停止工作, 就可以创建替换性的 Pod。调度器会将替身 Pod 调度到一个健康的节点执行。
下面是一些管理一个或者多个 Pod 的工作负载资源的示例:
- ReplicaSet
ReplicaSet 是新一代的 ReplicationController,拥有更强表达能力的 pod 标签选择器。目的是维护一组在任何时候都处于运行状态的 Pod 副本的稳定集合。 因此,它通常用来保证给定数量的、完全相同的 Pod 的可用性。
- Deployment
一个 Deployment 为 Pods 和 ReplicaSets 提供声明式的更新能力。你负责描述 Deployment 中的 目标状态,而 Deployment 控制器(Controller) 以受控速率更改实际状态, 使其变为期望状态。你可以定义 Deployment 以创建新的 ReplicaSet,或删除现有 Deployment, 并通过新的 Deployment 收养其资源。
- StatefulSet
StatefulSet 是用来管理有状态应用的工作负载 API 对象。StatefulSet 用来管理某 Pod 集合的部署和扩缩, 并为这些 Pod 提供持久存储和持久标识符。和 Deployment 类似, StatefulSet 管理基于相同容器规约的一组 Pod。但和 Deployment 不同的是, StatefulSet 为它们的每个 Pod 维护了一个有粘性的 ID。这些 Pod 是基于相同的规约来创建的, 但是不能相互替换:无论怎么调度,每个 Pod 都有一个永久不变的 ID。
- DaemonSet
DaemonSet 确保全部(或者某些)节点上运行一个 Pod 的副本。 当有节点加入集群时, 也会为他们新增一个 Pod 。 当有节点从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。DaemonSet 的一些典型用法:在每个节点上运行集群守护进程,在每个节点上运行日志收集守护进程,在每个节点上运行监控守护进程。
3.4、kubernetes 部署原理和流程案例
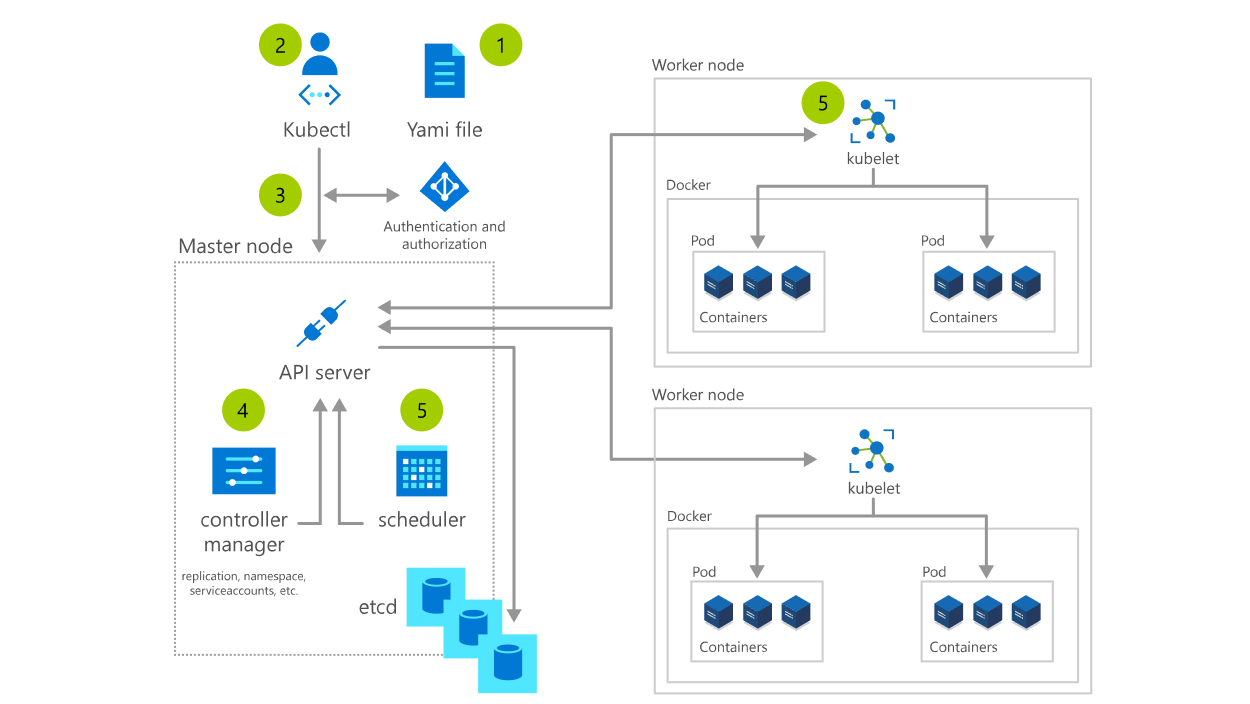
(1)创建一个描述集群的所需状态配置的 YAML 文件。
(2)通过 kubectl(Kubernetes 命令行接口)将 YAML 文件应用到集群。
(3)Kubectl 将请求提交给 kube-apiserver,后者在将更改记录到数据库 etcd, 之前会对请求进行身份验证和授权。
(4)Kube-controller-manager 持续监视系统是否有新的请求,并努力将系统状态调节至所需状态 - 在此过程中创建 ReplicaSet、部署和 Pod。
(5)在所有控制器都运行之后,kube-scheduler 会看到有 Pod 处于“挂起”状态,因为它们尚未被安排在节点上运行。scheduler 程序会为 Pod 查找合适的节点,然后与每个节点中的 kubelet 通信以控制并启动部署。
3.5、Kubernetes 架构关键设计理念
(1)声明式 API:开发者可以关注于应用自身,而非系统执行细节。比如 Deployment(无状态应用)、 StatefulSet(有状态应用)、Job(任务类应用)等不同资源类型,提供了对不同类型工作负载的抽象;对 Kubernetes 实现而言,基于声明式 API 可以提供更加健壮的分布式系统实现。
(2)可扩展性架构:所有 K8s 组件都是基于一致的、开放的 API 实现和交互;三方开发者也可通过 CRD(Custom Resource Definition)/Operator 等方法提供领域相关的扩展实现,极大提升了 K8s 的能力。
(3)可移植性:K8s 通过一系列抽象如 Loadbalance Service(负载均衡服务)、CNI(容器网络接口)、CSI(容 器存储接口),帮助业务应用可以屏蔽底层基础设施的实现差异,实现容器灵活迁移的设计目标。
三、云原生微服务
多个“微服务”共同形成了一个物理独立但逻辑完整的分布式微服务体系。这些微服务相对独立,通过解耦研发、测试与部署流程,提高整体迭代效率。微服务模式通过分布式架构将应用水平扩展和冗余部署,从根本上解决了单体应用在拓展性和稳定性上存在的先天架构缺陷。但也要注意到微服务模型也面临着分布式系统的典型挑战: 如何高效调用远程方法、如何实现可靠的系统容量预估、如何建立负载均衡体系、如何面向松耦合系统进行集成测试、如何面向大规模复杂关联应用的部署与运维。
在云原生时代,云原生微服务体系将充分利用云资源的高可用和安全体系,让应用获得更有保障的弹性、可用性与安全性。应用构建在云所提供的基础设施与基础服务之上,充分利用云服务所带来的便捷性、稳定性,降低应用架构的复杂度。云原生的微服务体系也将帮助应用架构全面升级,让应用天然具有更好的可观测性、可控制性、可容错性等特性。
自从微服务架构理念在 2011 年提出以来,典型的架构模式按出现的先后顺序大致分为四代。
第一代:应用自身需要解决上下游寻址、通讯、容错等问题。随着微服务规模扩大,服务寻址逻辑的处理变得越来越复杂,即使同一编程语言的另一个应用,上述微服务流量管理等的基础能力无法复用,都需要重新实现一遍。
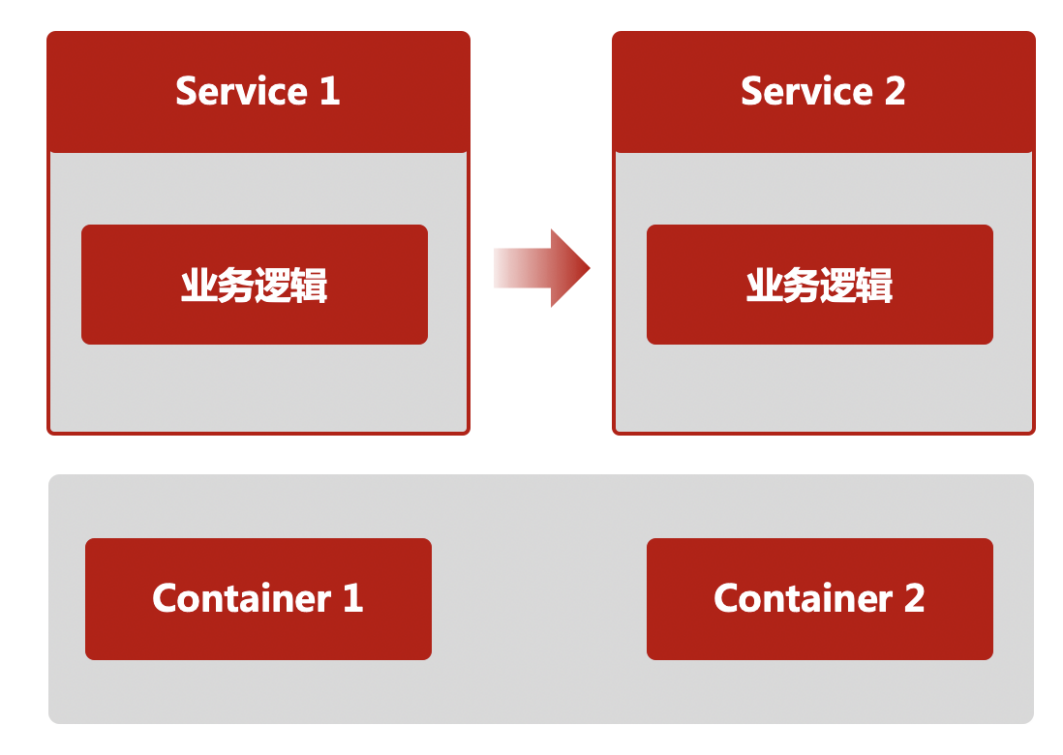
第二代:引入了旁路服务注册中心(如 ZooKeeper)作为协调者来完成服务的自动注册和发现。服务之间的通讯以及容错机制开始模块化,形成独立服务框架。但随着服务框架内功能日益增多,跨语言的基础功能复用显得十分困难,使得微服务的开发者被迫被限定在某种特定语言上,这也违背了微服务的敏捷迭代原则。
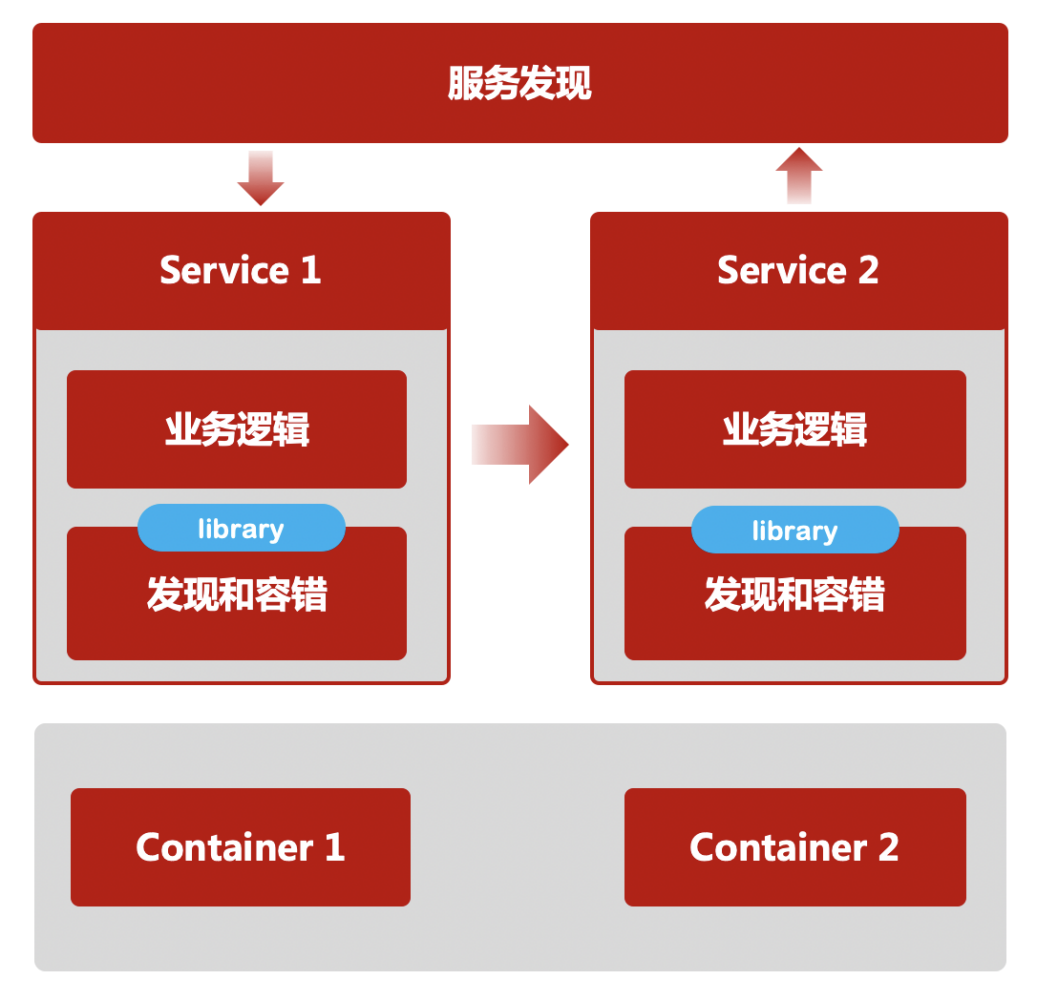
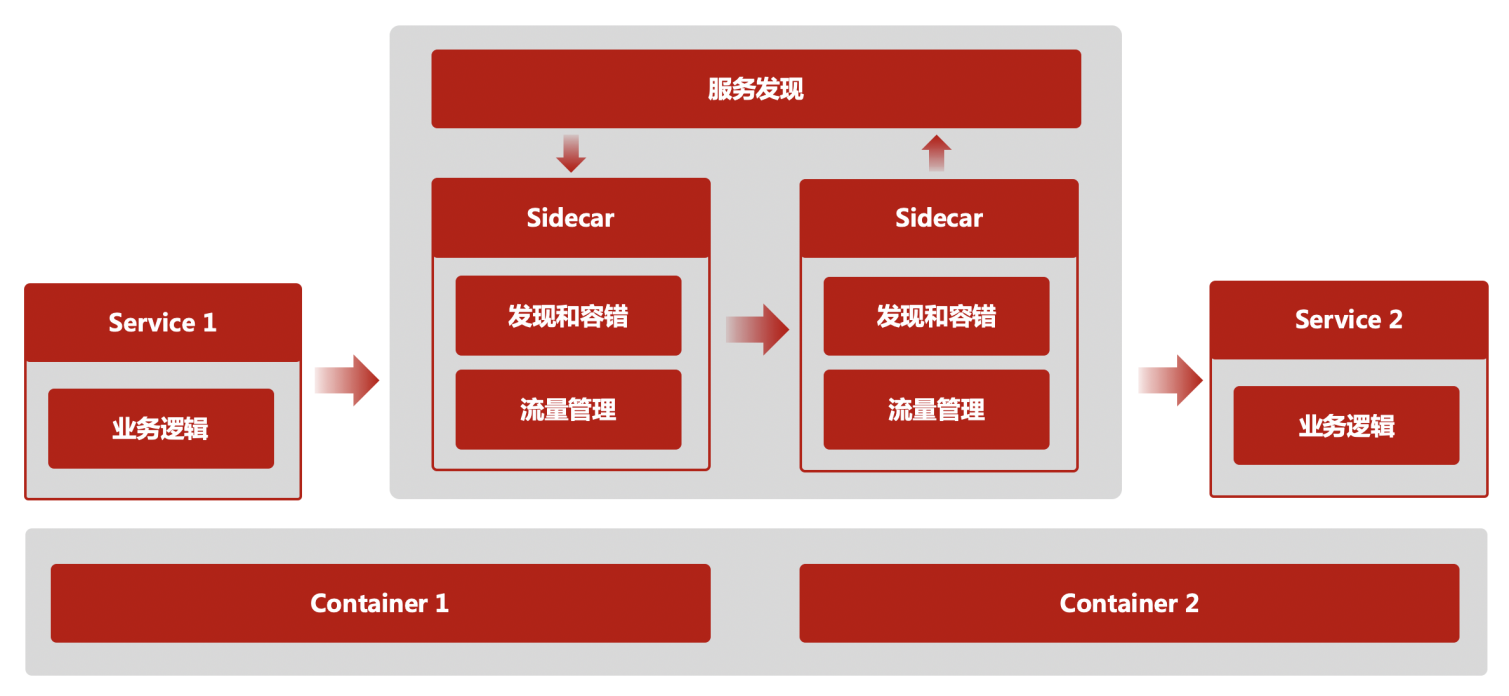
第三代:服务网格,原来被模块化到服务框架里的微服务基础能力,被进一步的从一个 SDK 演进成为一个独立进程 - Sidecar(边车)。这个变化使得第二代架构中多语言支持问题得以彻底解决,微服务基础能力演进和业务逻辑迭代彻底解耦。这个架构就是在云原生时代的微服务架构 - Cloud Native Microservices,边车(Sidecar)进程开始接管微服务应用之间的流量,承载第二代中服务框架的功能,包括服务发现、调用容错、服务治理功能,例如:权重路由、灰度路由、流量重放、服务伪装等。
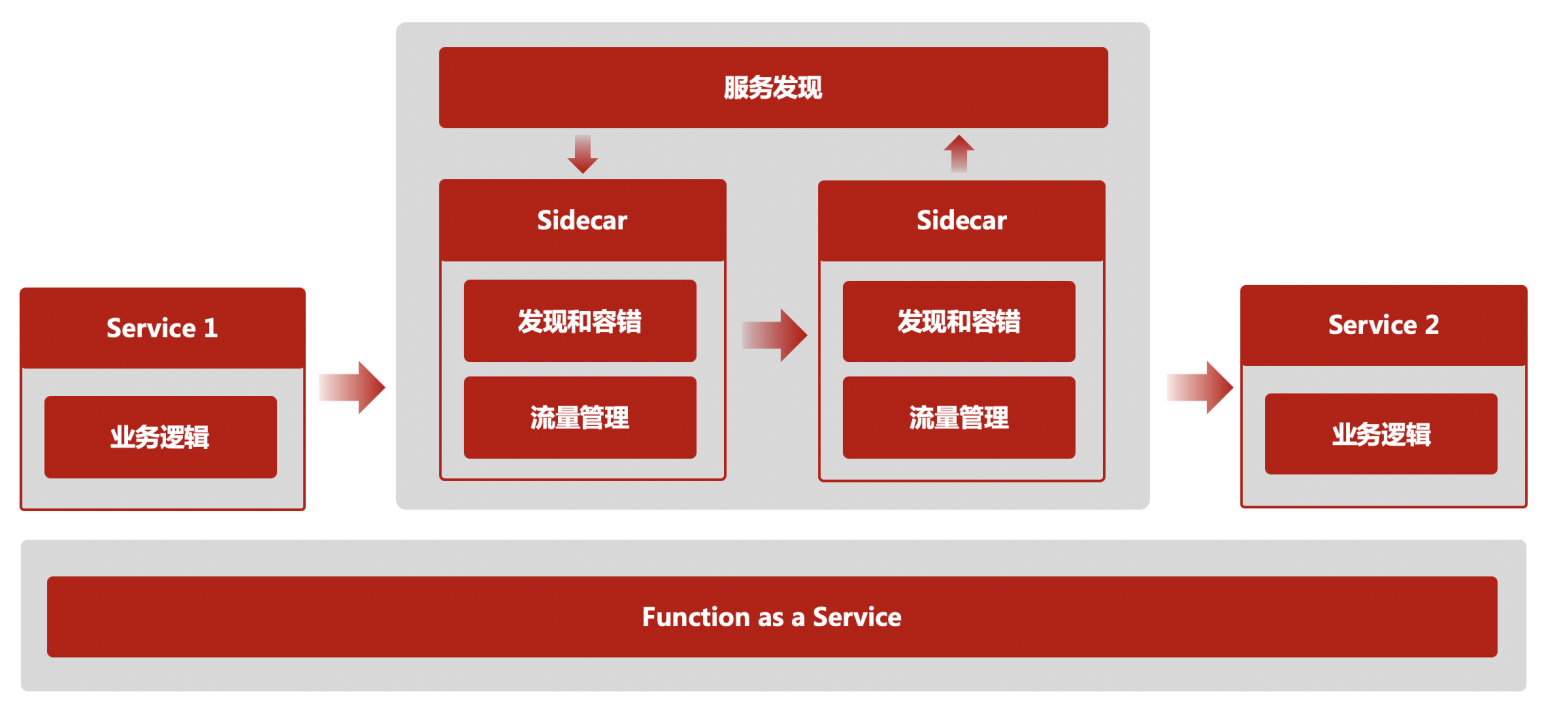
第四代:Serverless 微服务,微服务进一步由一个应用简化为微逻辑(Micrologic),从而对边车模式提出了更高诉求,更多可复用的分布式能力从应用中剥离,被下沉到边车中,例如:状态管理、资源绑定、链路追踪、事 务管理、安全等。同时,在开发侧提倡面向本地编程的理念,提供标准 API 屏蔽掉底层资源、服务、 基础设施的差异,进一步降低微服务开发难度。也就是目前业界提出的多运行时微服务架构(Muti-Runtime Microservices)。
四、Serverless
过去一直通过各种途径学习、研究 Serverless,当我想在这个章节给 Serverless 给一个官方的定义,发现百度百科竟然没有 Serverless 这个词条,也说明了 Serverless 在行业还是一个非常新的概念,仍然处于探索和发展阶段,并且对于 Serverless 也没有一个权威的定义,但我们可以从 Serverless 背后的愿景和思想来理解 Serverless 是什么?
我们看下 AWS 怎么定义 Serverless 的:
Serverless 的全称是 Serverless Computing 无服务器运算,以平台即服务(PaaS)为基础,让用户可以在不考虑服务器的情况下构建并运行应用程序和服务,开发者无需关注基础设施管理任务,例如服务器或集群配置、修补、操作系统维护和容量预置,能够为几乎任何类型的应用程序或后端服务构建无服务器应用程序。无服务器应用程序是由事件驱动的,并通过与技术无关的 API 或消息收发实现松散耦合。响应事件而执行事件驱动型代码,例如状态更改或终端节点请求,事件驱动型架构将代码与状态解耦,松散耦合组件之间的集成通常使用消息收发异步完成。
“Serverless”这个名字本身描绘了该技术的里面:无服务器,这里的 less 其含义不是说应用的运行不需要服务器,而是针对用户的心智负担和关注点来说的,用户构建一个应用无需关心服务器、运行时、扩缩容等技术实施的负担,通过 Serverless 平台的托管服务和函数快速构建一个全新的应用。
“名可名,非常名”。Serverless 可以翻译为无服务器,但却无法完整阐述背后的本质、愿景和价值。
我们看 Serverless 给用户带来了什么?
专注
“Less is more”。企业在搭建数字化应用的终极目的是实现商业价值的最大化回报,投入数字化应用搭建的资源和成本不是无限的,这些投入中能够给企业带来真正价值的是业务逻辑/代码,重复性的技术性工作(扩缩容、部署、容灾、监控、日志、安全补丁等)是来支撑业务代码提供服务的,本身不产生任何业务价值。Serverless 的 Less 就是让用户尽可能少的关注和执行繁琐且重复性的技术性工作,More 就是用户就能尽可能多的把资源聚焦到能产出价值的业务代码上。所以也可以说,Serverless 一种让用户专注于业务价值交付的方法。
快
天下武功、唯快不破。尤其在当日快速变革的商业环境,是否能快速看准机遇、抓住机遇,企业的试错能力是关键,企业能够快速试错,意味着可以快速创新,能够快速创新能让企业在复杂多变的竞争环境中获得优势和成功。快速试错依赖于企业把功能和业务点子推到市场的速度,这个速度由企业交付软件的周期决定,Serverless 理念就是让企业只关注业务,通过编排云托管服务或直接部署代码即可构建支撑应用,缩短了从代码开发到投入生产的时间,这样企业可以获得前所未有的交付软件价值的速度。
用户如何实现无需关注技术设施,甚至无需部署应用就可以构建一个应用的呢?通过 2 种能力:
1、BaaS(Backend as a Service),公共的托管服务。公共的托管服务通常是云厂商提供的通用的、跨场景、跟业务无紧密关系的共享服务。我们知道,对于很多初创企业来讲,65%的应用 QPM 是小于 100 的,是典型的长尾应用,如果应用依赖所有服务都自建的话,会分散在核心业务的投入,模糊他们对于创造业务价值和商业价值的注意力。诸如登录、文件系统、对象存储和数据仓库、语音分析、身份验证等能力通过托管形式共享给企业,企业不仅可以减少大量的成本,也加快应用的构建。
2、FaaS(Function as a Service),函数即服务。FaaS 是一种构建和部署服务器端软件的新方法,粒度细到能够独立的部署一个函数。我们通过传统方式部署服务器端软件时,我们从主机实例开始,通常是虚拟机(VM)实例或容器,在主机中部署我们的应用程序,如果我们的主机是 VM 或容器,那么我们的应用程序是一个操作系统进程。FaaS 改变了这种部署模式, 部署模型中少了主机实例和应用程序进程,我们只关注实现应用程序逻辑的各个操作和函数,我们将这些函数代码单独上传到云供应商提供的 FaaS 平台。函数在云服务托管的服务器进程中缺省处于空闲状态,直到需要它们运行的时候才会被激活, 通过配置 FaaS 平台来监听每个函数的激活事件。 当该事件发生时,FaaS 平台实例化函数,然后使用触发事件调用它。所以 FaaS 本质上是一种事件驱动的模型,除了提供托管和执行代码的平台之外,FaaS 平台还集成了各种同步和异步事件源,HTTP API 网关就是一种同步事件源,消息总线、对象存储或类似于的定时器就是一种异步源。
很多人说 Serverless 就是 BaaS+FaaS,也是不无道理的。
总结来看,Serverless 的价值有:
1、提升迭代速度:通过加快构建和发布周期以及减少运营开销,开发人员可以快速构建新功能。自动化测试和发布流程可以降低错误率,因此产品能够更快地进入市场。
2、加速创新:利用模块化架构,开发人员可以快速更改任何单个应用程序组件,并降低整个应用程序面临的风险,因此团队可以更频繁地试验新想法。
3、降低成本:按需付费,利用按价值付费的定价模式,现代应用程序可以减少过度配置和闲置资源,从而降低成本。开发者无需关注同质化的、负担繁重的基于服务器等基础设施的开发、运维、安全、高可用等工作,开发和维护成本也变得更低。
4、弹性伸缩:您的应用程序可自动扩展,或通过切换占用资源(如吞吐量、内存)的单位数(而不是切换单个服务器的单位数)来调整容量,从而实现扩展。
国内外比较出名的 Serverless 产品有阿里函数计算、腾讯 Serverless、AWS Lambda、Azure Functions 等。近两年来 Serverless 近年来呈加速发展趋势,用户使用 Serverless 架构在可靠性、成本和研发运维效率等方面获得显著收益,那在哪些场景是最适合 Serverless?最能发挥 Serverless 优势呢?
1、小程序/Web/Moible/API 后端服务:在小程序、Web/Moible 应用、API 服务等场景中,业务逻辑复杂多变,迭代上线速度要求高,而且这类在线应用,资源利用率通常小于 30%,尤其是小程序等长尾应用,资源利用率更是低于 10%。Serverless 免运维,按需付费的特点非常适合构建小程序 /Web/Mobile/API 后端系统,通过预留计算资源 + 实时自动伸缩,开发者能够快速构建延时稳定、能承载高频访问的在线应用。
2、物联网:物联网意味着成千上万的设备会连入网络,时刻在不断的产生数据,这对数据的分析、处理的及时性提出了很高的挑战。通过使用 Serverless 架构,物联网设备所采集的数据将可以作为云函数的触发事件,而实现数据的实时处理、分析和应用。随着物联网设备计算能力的进一步提升,云函数作为最小粒度的计算单元,有机会被调度到设备端运行,实现边缘计算,达到「端 - 云」联合的 Serverless 架构。
3、任务批处理:在构建典型任务批处理(如图像处理、大规模音视频文件转码)系统时,需要包含计算资源管理、任务优先级调度、任务编排、任务可靠执行等一系列功能。通过 Serverless 计算平台,用户只需要专注于任务处理逻辑的处理,无需从机器或者容器层开始构建,也无需考虑使用消息队列进行任务信息的持久化和计算资源分配,而且 Serverless 计算的极致弹性可以很好地满足突发任务下对算力的需求,用户无需使用 Kubernetes 等容器编排系统实现资源的伸缩和容错,自行搭建或集成监控报警系统。通过将对象存储服务化并和 Serverless 计算平台集成的方式,能实时响应对象创建、删除等操作,实现以对象存储为中心的大规模数据处理。用户既可以通过增量处理对象存储上的新增数据,也可以创建大量函数实例来并行处理存 量数据。
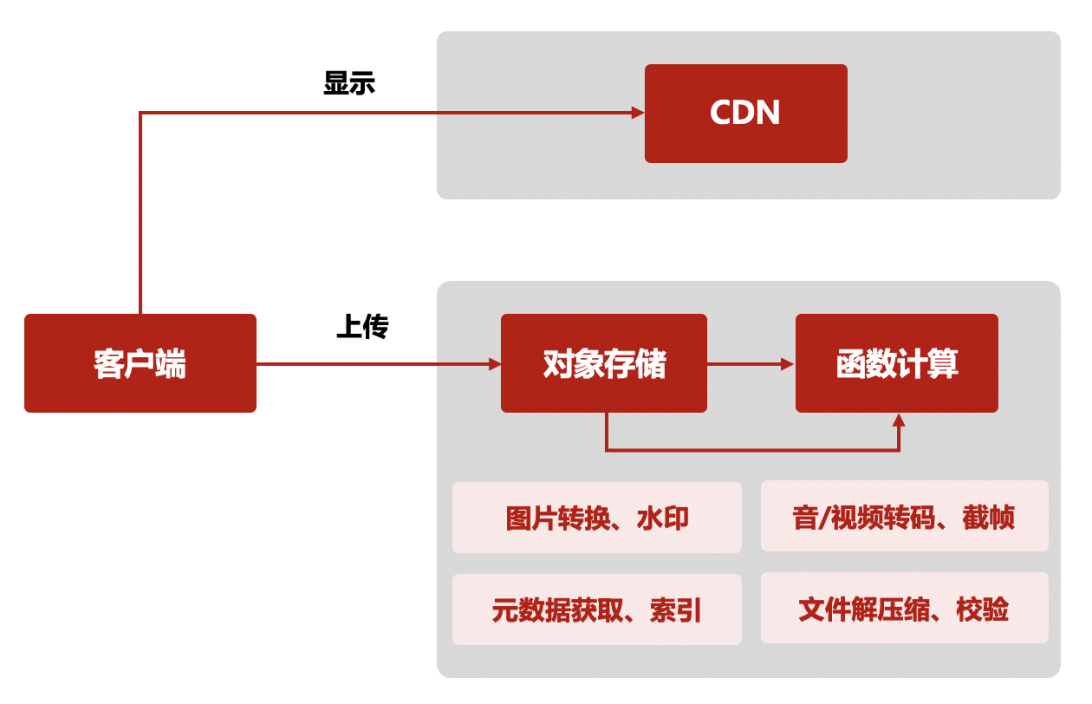
4、运维及集成:通过对接云函数以及云上的各个产品、日志服务、监控告警系统,云时代的运维也都可以用云函数来构建。定时触发的云函数,将可以方便地替代需要在主机上来运行的定时任务;而日志或告警触发的云函数,将可以对云中的事件作出立刻回应及处理。
Serverless 作为一种全新的技术架构,具有很多的优点,如降低运营成本、降低运维需求、降低人力成本和减少资源开销等。但技术没有银弹,Serverless 也处在发展期,存在一些弊端,包括:
1、不适合处理复杂的业务逻辑,它更适合调用云上的其他服务,粘合关键的产品。
2、冷启动导致的高延迟问题。
3、Serverless 调用之间不能共享状态让编写复杂程序变得极度困难。无状态是现代应用追求的目标,“12 要素”也倡导如此。但 Serverless 将无状态进行的更加彻底,在不同的调用之间无法共享内存状态。例如单机限流在本地是一个 AtomicInteger 变量,但在 Serverless 架构中它变成存储在内存数据库(Redis)中的一条记录,更新成本、保证原子性等因素让我们的编码变得数倍复杂。对于大多云原生的互联网应用来说,这种彻底的无状态架构是一个巨大的挑战,而对于动辄有几十万、上百万行代码的、充满了状态的企业应用来说,Serverless 的无状态改造几乎是一个无法完成的任务。
4、 本地开发、测试困难,同时逻辑散落在各处,排查问题困难。
5、厂商锁定。云计算是赢者通吃的行业,大而全的云厂商优势巨大,Serverless 加剧了这种趋势,用户的函数代码部署到 FaaS 后迁移工作量巨大,同时应用中依赖了大量云公共服务,在新的云平台极有可能找不到替代,做不到平滑迁移。
五、Service Mesh 技术
在上面云原生微服务章节介绍了微服务流量控制和治理的技术发展历程,总结来看分为:

Spring Cloud、Dubbo 或京东 JSF 为代表的第二代微服务框架所面临的三个本质问题:
1、侵入性强。想要集成 SDK 的能力,除了需要添加相关依赖,往往还需要在业务代码中增加一部分的代码、或注解、或配置;业务代码与治理层代码界限不清晰。
2、无法跨语言。
3、中间件演变困难。由于版本碎片化严重,导致中间件向前演进的过程中就需要在代码中兼容各种各样的老版本逻辑,带着“枷锁” 前行,无法实现快速迭代。
4、内容多、门槛高。Spring Cloud 被称为微服务治理的全家桶,包含大大小小几十个组件,内容相当之多,往往需要几年时间去熟悉其中的关键组件。而要想使用 Spring Cloud 作为完整的治理框架,则需要深入了解其中原理与实现,否则遇到问题还是很难定位。
5、治理功能不全。不同于 RPC 框架,Spring Cloud 作为治理全家桶的典型,也不是万能的,诸如协议转换支持、多重授权机制、动态请求路由、故障注入、灰度发布等高级功能并没有覆盖到。而这些功能往往是企业大规模落地不可获缺的功能,因此公司往往还需要投入其它人力进行相关功能的自研或者调研其它组件作为补充。
微服务时代,Service Mesh 应运而生,屏蔽了分布式系统的诸多复杂性,让开发者可以回归业务,聚焦真正的价值。
Service Mesh 一词最早由开发 Linkerd 的 Buoyant 公司提出,并于 2016 年 9 月 29 日第一次公开使用了这一术语。William Morgan,Buoyant CEO,对 Service Mesh 这一概念定义如下:
A Service Mesh is a dedicated infrastructure layer for handling service-to-service communication. It’s responsible for the reliable delivery of requests through the complex topology of services that comprise a modern, cloud native application. In practice, the Service Mesh is typically implemented as an array of lightweight network proxies that are deployed alongside application code, without the application needing to be aware.
翻译一下:
服务网格(Service Mesh)是处理服务间通信的基础设施层。它负责构成现代云原生应用程序的复杂服务拓扑来可靠地交付请求。在实践中,Service Mesh 通常以轻量级网络代理阵列的形式实现,这些代理与应用程序代码部署在一起,对应用程序来说无需感知代理的存在。
从这段定义中可以读出,Service Mesh 的本质是基础设施层,核心功能是请求分发,机制是通过网络代理,特点是对应用透明。
简单地说,Service Mesh 是一个专注于处理服务间通信的基础设施层。Service Mesh 是分布式应用在微服务软件架构之上发展起来的新技术,旨在将那些微服务间的连接、安全、流量控制和可观测等通用功能下沉为平台基础设施,实现应用与平台基础设施的解耦。解耦让开发者聚焦于业务逻辑本身而无需关注微服务相关治理问题,提升应用开发效率并加速业务探索和创新。因为大量非功能性从业务进程剥离到另外进程中,Service Mesh 以无侵入的方式实现了应用轻量化。
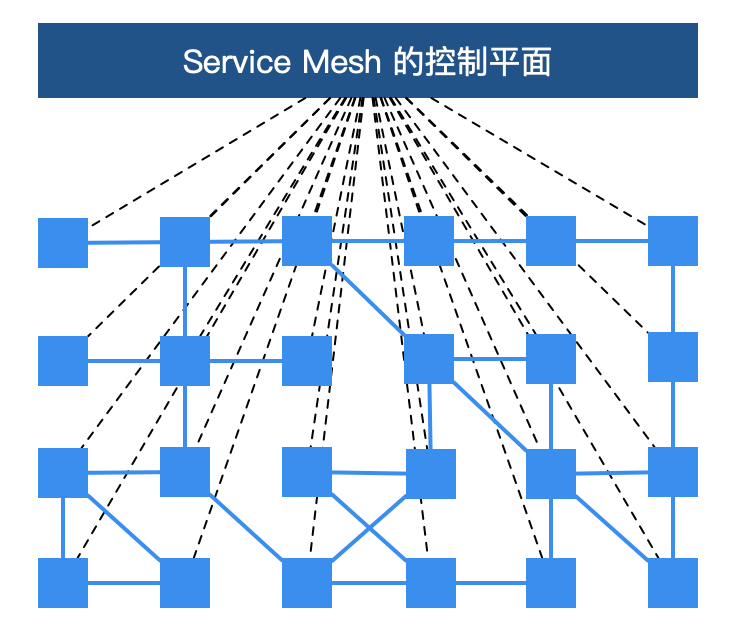
服务网格从总体架构上来讲比较简单,不过是一堆紧挨着各项服务的用户代理,外加一组任务管理流程组成。代理在服务网格中被称为数据层或数据平面(data plane),管理流程被称为控制层或控制平面(control plane)。数据层截获不同服务之间的调用并对其进行“处理”;控制层协调代理的行为,并为运维人员提供 API,用来操控和测量整个网络。
更进一步地说,服务网格是一个专用的基础设施层,旨在“在微服务架构中实现可靠、快速和安全的服务间调用”。它不是一个“服务”的网格,而是一个“代理”的网格,服务可以插入这个代理,从而使网络抽象化。在典型的服务网格中,这些代理作为一个 sidecar(边车)被注入到每个服务部署中。服务不直接通过网络调用服务,而是调用它们本地的 sidecar 代理,而 sidecar 代理又代表服务管理请求,从而封装了服务间通信的复杂性。相互连接的 sidecar 代理集实现了所谓的数据平面,这与用于配置代理和收集指标的服务网格组件(控制平面)形成对比。
总而言之,Service Mesh 的基础设施层主要分为两部分:控制平面与数据平面。当前流行的两款开源服务网格 Istio 和 Linkerd 实际上都是这种构造。
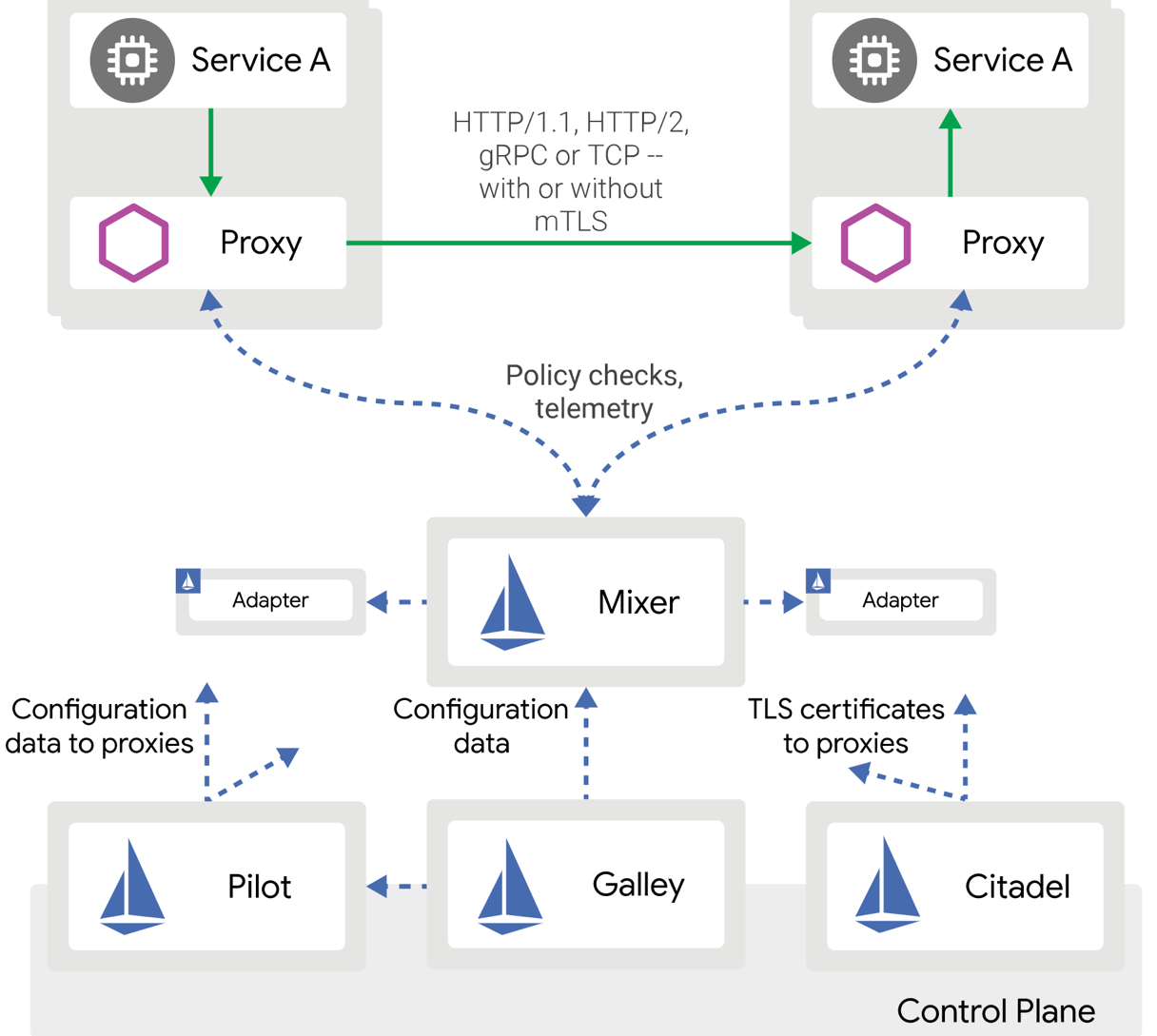
以 Istio 为例
1、控制平面:控制面是用来配置、监控、展示数据面网络流量的一组程序。
a) 不直接解析数据包。
b) 与控制平面中的代理通信,下发策略和配置。
c) 负责网络行为的可视化。
d) 通常提供 API 或者命令行工具可用于配置版本化管理,便于持续集成和部署。
2、数据平面
a) 直接处理入站和出站数据包,转发、路由、健康检查、负载均衡、认证、鉴权、产生监控数据等。
b) Service Mesh 的数据面是一个个 sidecar 应用程序,sidecar 处理的是微服务的网络数据转发。Istio 使用 Enovy 项目作为 sidecar 的实现。
c) 对应用来说透明,即可以做到无感知部署。
d) 当 Istio 与 Kubernetes 一起用来构建 Cloud Native 应用时,sidecar 本身作为 Kubernetes Pod 中的一个容器运行。
那么 Service Mesh 带来的真正价值有哪些呢?
1、微服务治理与业务逻辑的解耦。服务网格把 SDK 中的大部分能力从应用中剥离出来,拆解为独立进程,以 sidecar 的模式进行部署。服务网格通过将服务通信及相关管控功能从业务程序中分离并下沉到基础设施层,使其和业务系统完全解耦,使开发人员更加专注于业务本身。
2、异构系统的统一治理。随着新技术的发展和人员更替,在同一家公司中往往会出现不同语言、不同框架的应用和服务,为了能够统一管控这些服务,以往的做法是为每种语言、每种框架都开发一套完整的 SDK,维护成本非常之高,而且给公司的中间件团队带来了很大的挑战。有了服务网格之后,通过将主体的服务治理能力下沉到基础设施,多语言的支持就轻松很多了。只需要提供一个非常轻量级的 SDK,甚至很多情况下都不需要一个单独的 SDK,就可以方便地实现多语言、多协议的统一流量管控、监控等需求。
3、可观察性。因为服务网格是一个专用的基础设施层,所有的服务间通信都要通过它,所以它在技术堆栈中处于独特的位置,以便在服务调用级别上提供统一的遥测指标。这意味着,所有服务都被监控为“黑盒”。服务网格捕获诸如来源、目的地、协议、URL、状态码、延迟、持续时间等线路数据。这本质上等同于 web 服务器日志可以提供的数据,但是服务网格可以为所有服务捕获这些数据,而不仅仅是单个服务的 web 层。需要指出的是,收集数据仅仅是解决微服务应用程序中可观察性问题的一部分。存储与分析这些数据则需要额外能力的机制的补充,然后作用于警报或实例自动伸缩等。
4、流量控制。通过 Service Mesh,可以为服务提供智能路由(蓝绿部署、金丝雀发布、A/B test)、超时重试、熔断、故障注入、流量镜像等各种控制能力。而以上这些往往是传统微服务框架不具备,但是对系统来说至关重要的功能。例如,服务网格承载了微服务之间的通信流量,因此可以在网格中通过规则进行故障注入,模拟部分微服务出现故障的情况,对整个应用的健壮性进行测试。由于服务网格的设计目的是有效地将来源请求调用连接到其最优目标服务实例,所以这些流量控制特性是“面向目的地的”。这正是服务网格流量控制能力的一大特点。
5、安全。在某种程度上,单体架构应用受其单地址空间的保护。然而,一旦单体架构应用被分解为多个微服务,网络就会成为一个重要的攻击面。更多的服务意味着更多的网络流量,这对黑客来说意味着更多的机会来攻击信息流。而服务网格恰恰提供了保护网络调用的能力和基础设施。服务网格的安全相关的好处主要体现在以下三个核心领域:服务的认证、服务间通讯的加密、安全相关策略的强制执行。
Service Mesh 和云原生
我们知道云原生的三驾马车为 Serverless、Service Mesh、Kubernetes,而 Istio 已成为了 Sevice Mesh 的事实标准,当我们理解 Kubernetes 和 Istio 名字的含义,发现其中的奥妙,Kubernetes 名字意为舵手,是云原生的操作系统,Istio 的意思为船帆,意味着我们要到达终极云原生目标,不仅要有舵手,还需要船帆。这也能揭示 CNCF 的野心和方向。
Kubernetes 的本质是应用的生命周期管理,具体来说就是部署和管理(扩缩容、自动恢复、发布),微服务提供了可扩展、高弹性的部署和管理平台。Service Mesh 的基础是透明代理,通过 sidecar proxy 拦截到微服务间流量后再通过控制平面配置管理微服务的行为。Service Mesh 将流量管理从 Kubernetes 中解耦,Service Mesh 内部的流量无需 kube-proxy 组件的支持,通过为更接近微服务应用层的抽象,管理服务间的流量、安全性和可观察性。
如果说 Kubernetes 管理的对象是 Pod,那么 Service Mesh 中管理的对象就是一个个 Service,所以说使用 Kubernetes 管理微服务后再应用 Service Mesh 就是水到渠成了,如果连 Service 你也不想管了,那你就需要 Serverless 了。
就像之前说的软件开发没有银弹,传统微服务架构有许多痛点,而服务网格也不例外,也有它的局限性。
1、增加了复杂度。服务网格将 sidecar 代理和其它组件引入到已经很复杂的分布式环境中,会极大地增加整体链路和操作运维的复杂性。
2、运维人员需要更专业。在容器编排器(如 Kubernetes)上添加 Istio 之类的服务网格,通常需要运维人员成为这两种技术的专家,以便充分使用二者的功能以及定位环境中遇到的问题。
3、延迟。从链路层面来讲,服务网格是一种侵入性的、复杂的技术,可以为系统调用增加显著的延迟。这个延迟是毫秒级别的,但是在特殊业务场景下,这个延迟可能也是难以容忍的。
4、平台的适配。服务网格的侵入性迫使开发人员和运维人员适应高度自治的平台并遵守平台的规则。
六、DevOps
DevOps 就是为了提高软件研发效率,快速应对变化,持续交付价值的的一系列理念和实践,其基本思想就是持续部署(CD),让软件的构建、测试、发布能够更加快捷可靠,以尽量缩短系统变更从提交到最后安全部署到生产系统的时间。
要实现持续部署(CD),就必须对业务进行端到端分析,把所有相关部门的操作统一考虑进行优化,利用所可用的技术和方法,用一种理念来整合资源。DevOps 提倡打破开发、测试和运维之间的壁垒,利用技术手段实现各个软件开发环节的自动化甚至智能化,被证实对提高软件生产质量、安全,缩短软件发布周期等都有非常明显的促进作用,也推动了 IT 技术的发展。
DevOps 原则
- 文化(Culture)
一般大家关注的都是技术和工具,但实际上要解决的核心问题是和业务、和人相关的问题。提高效率,加强协作,就需要不同的团队之间更好的沟通。如果每个人能够更好的相互理解对方的目标和关切的对象,那么协作的质量就可以明显的提高。
DevOps 实施中面对的首要矛盾在于不同团队的关注点完全不一样。运维人员希望系统运行可靠,所以系统稳定性和安全性是第一位。而开发人员则想着如何尽快让新功能上线,实现创新和突破,为客户提供更大价值。不同的业务视角,必然导致误会和摩擦,导致双方都觉得对方在阻挠自己完成工作。要实施 DevOps,就首先要让开发和运维人员认识到他们的目标是一致的,只是工作岗位不同,需要共担责任。这就是 DevOps 需要首先在文化层面解决的问题。只有解决了认知问题,才能打破不同团队之的鸿沟,实现流程自动化,把大家的工作融合成一体。
- 自动化(Automation)
DevOps 的持续集成的目标就是小步快跑,快速迭代,频繁发布。要把这个理念落实,就需要规范化和流程化,让可以自动化的环节实现自动化。
- 度量(Measurement)
通过数据可以对每个活动和流程进行度量和分析,找到工作中存在的瓶颈和漏洞以及对于危急情况的及时报警等。通过分析,可以对团队工作和系统进行调整,让效率改进形成闭环。度量首先要解决数据准确性、完整性和及时性问题,其次要建立正确的分析指标。DevOps 过程考核的标准应该鼓励团队更加注重工具的建设,自动化的加速和各个环节优化,这样才能最大可能发挥度量的作用。
- 共享(Sharing)
要实现真正的协作,还需要团队在知识层面达成一致。通过共享知识,让团队共同进步。可见度 visibility,透明性 transparency,知识的传递 transfer of knowledge。
IaC
IaC (Infrastructure as Code)提出系统建设的核心理念,兼顾高效和安全,让运维系统的建设更加有序。
运维平台一般都经历过如下几个发展阶段:手工、脚本、工具、平台、智能化运维等,但总体来说分为两类:指令式,声明式。
在复杂的运维场景下,指令式的运维方式具有变更操作副作用:不透明、指令性接口一般不具有幂等性、难以实现复杂的变更控制、知识难以积累和分享、变更缺乏并发性等缺点。
人们提出了声明式的编程理念。用户仅仅通过一种方式描述其要到达的目的,而并不具体说明如何达到目标。声明式接口实际上代表了一种思维模式:把系统的核心功能进行抽象和封装,让用户在一个更高的层次上进行操作。声明式接口是一种和云计算时代相契合的思维范式。前面列出的指令式的缺点都可以由声明式接口来弥补。
GitOps
GitOps 作为 IaC 运维理念的一种具体落地方式,就是使用 Git 来存储关于应用系统的最终状态的声明式描述。GitOps 的核心是一个 GitOps 引擎,它负责监控 Git 中的状态,每当它发现状态有改变,它就负责把目标应用系统中的状态以安全可靠的方式迁移到目标状态,实现部署、升级、配置修改、回滚等操作。
Git 中存储有对于应用系统的完整描述以及所有修改历史。方便重建的同时,也便于对系统的更新历史进行查看,符合 DevOps 所提倡的透明化原则。同时,GitOps 也具有声明式运维的所有优点。和 GitOps 配套的一个基本假设是不可变基础设施,所以 GitOps 和 Kubernetes 运维可以非常好的配合。
云原生开源生态的建设,基本统一了软件部署和运维的基本模式。更重要的是,云原生技术的快速演进,技术复杂性不断下沉到云,赋能开发者个体能力,不断提升了应用开发效率。
首先是容器技术和 Kubernetes 服务编排技术的结合,解决了应用部署自动化、标准化、配置化问题。CNCF 打破了云上平台的壁垒,使建设跨平台的应用成为可能,成为事实上的云上应用开发平台的标准,极大简化了多云部署。
一个完整开发流程涉及到很多步骤,而环节越多,一次循环花费的时间越长,效率就越低。微服务通过把巨石应用拆解为若干单功能的服务,减少了服务间的耦合性,让开发和部署更加便捷,可以有效降低开发周期,提高部署灵活性。Service Mesh 让中间件的升级和应用系统的升级完全解耦,在运维和管控方面的灵活性获得提升。Serverless 让运维对开发透明,对于应用所需资源进行自动伸缩。FaaS 是 Serverless 的一种实现,则更加简化了开发运维的过程,从开发到最后测试上线都可以在一个集成开发环境中完成。无论哪一种场景,后台的运维平台的工作都是不可以缺少的,只是通过技术让扩容、容错等技术对开发人员透明,让效率更高。
5、iPaaS(京东前台研发标准)在云原生的思考和探索
以下是 iPaaS 愿景在能力图谱中的贯彻。
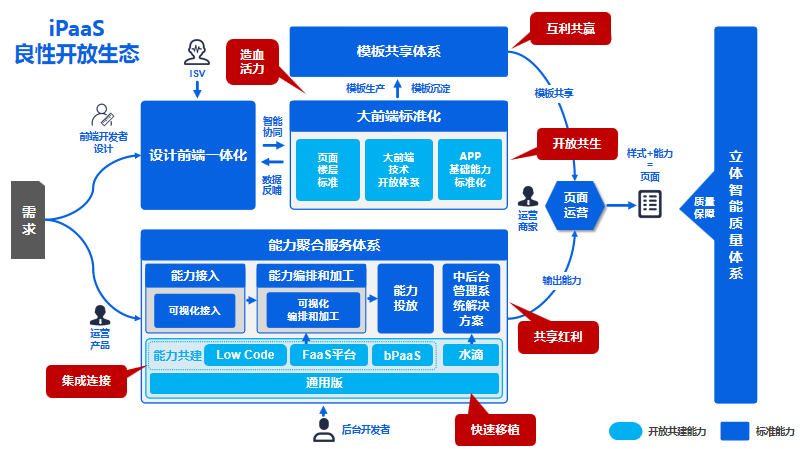
随着 iPaaS 赋能开发者从试水阶段正迈向赋能阶段,我们对 iPaaS 的能力有了不同的理解和思考,从最初聚焦的 5 大能力,到我们从用户角度、从业务场景出发或解剖 iPaaS 的内在价值来看,可以得出不一样的能力和价值,我把这些能力形成不同的主线,以牵引我们能建设出一个有活力、以业务场景为中心的 iPaaS 体系。
a) iPaaS 的核心思想和基础是标准,跟具体实现方式划清界限,意味着是抽象的、稳定的,也是开放和可扩展的。标准是 iPaaS 形成体系的理论基础。
b) iPaaS 光有标准还不行,谁都可以搞一套标准来,如果我们能提供开发者基于标准下的立体式和一站式技术开发和共建平台,让开发者可以低门槛、灵活和高效定制和开发,这个对开发者的吸引力是无穷的。所以 iPaaS 技术开放体系是术,是工具。
c) 但有标准和技术开放体系也不够,能力都是点状的,无法体系化解决业务的场景化需求。iPaaS 的背后一个重大价值是一个强大的业务平台,我们也称为 SaaS,SaaS 是土壤,让标准和技术开放体系可以从树木变成树林,滋生出各种各样的业务解决方案。
d) iPaaS 要形成持续繁荣的生态,一个搞笑能力沉淀和共享的体系必不可少,沉淀和共享让 iPaaS 生态水池中的水越来越多。
e) 京东业务快速发展,催生出了各种各样的新站点和新赛道,通用版可以让 iPaaS 快速完成独立部署和交付。这也是 iPaaS 面临的一个大的业务场景。
f) iPaaS 不但是技术,强调设计、研发、测试运维打破流程壁垒,统一目标,标准流程,提升协作效率和质量。
g) 最后,是全场景的解决方案,解决方案其实是一种服务精神,标准、技术体系很重要,但如果我们能深入业务场景,形成清晰的解决方案矩阵,可以让用户高效满足自己的需求。平台化建设要脱离业务,解决方案孵化要深入业务。
我们把 iPaaS 核心理念、价值、方向跟云原生体系进行整体性分析,发现二者在很多方面是相同的,下面是梳理的 iPaaS 和云原生价值和能力背后实现原理和理念的对比:

对比云原生的理念和技术,iPaaS 在一些方面的建设做的尚可,包括:
1、建立了脱离了具体客户和业务场景的通用体系化标准,该标准让 iPaaS 变成一个高度开放的体系,同时可通过串联设计平台、测试平台、监控平台等形成一个一站式云上开发和协作平台;
2、强大和立体式的技术开放共建体系,让开发者无需关注重复性劳动和底层技术设施和技术复杂度,从而可聚焦和专注在业务代码和个性化需求的定制上,开发者的研发效率和需求交付效率得到了明显的提升。覆盖从大前端(iHub)、Low Code、FaaS、通用版、微前端到中后台管理系统解决方案(Drip 水滴);
3、iPaaS 标准+共享能力的复用,在配套技术开放体系,可支撑快速满足业务的各类需求,助力业务频繁试错和创新。
4、iPaaS 背后的系统和平台支撑了 10+个京东大促,大促期间无事故和问题,切高性能高可用的接口保证了大促业务的平稳运营。
5、iPaaS 已开始赋能京东在各个海外站点(泰国站、印尼站)和商业化项目,助力零售技术和业务能力走出公司。
但同时我们发现 iPaaS 还存在薄弱的环节或亟待加强提升的地方,结合云原生的理念和技术,以下是我们的思考和可能的规划。
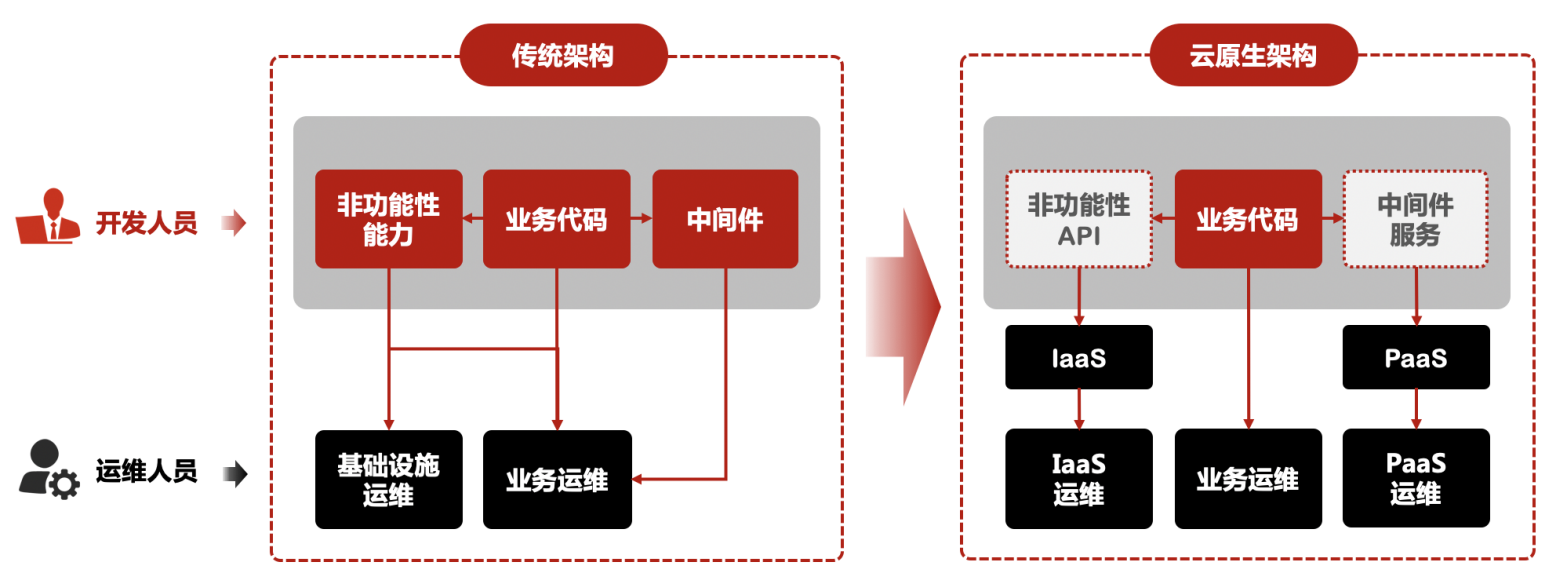
1、应用“云原生化”
云原生应用在构建之初就基于一个重要前提:生在云上,长在云上。这就要求应用如同新生儿一样,除了保留业务代码外,非功能性代码和中间件代码都应剥离出来,交由云设施来接管,以实现云原生的理念:应用诞生起就生/长在云上,能够最大化地发挥云的优势和价值,实现不在关注非功能性需求的同时系统天然具备轻量、弹性、敏捷和自动化特点。纵观 iPaaS 后端应用架构,应用的存储、消息、服务流量治理、高可用、熔断容错、自动恢复能力都是通过相关集成在应用中代码或中间件 SDK 来实现的,面临升级困难、无法跨云部署等问题。在云原生时代,云把三方软硬件的能力升级成了服务,比如“如何获取存储”变成了若干服务,包括对象存储服务、块存储服务等,这些服务把分布式场景中的高可用挑战、自动扩缩容挑战、安全挑战、运维升级挑战等都处理了。所以应用需要经过对中间件直接依赖进行解耦,这个过程不是一蹴而就的,依赖应用运行的云计算环境的水平,但是应用进行对技术基础设施和技术中间件的直接依赖的解耦是必要的,通过一个标准技术中间层来隔离应用和具体的技术,能够在条件成熟的时候,帮助应用快速实现云原生化并部署在云上。以下是 iPaaS 实现云原生应用架构的转变:
2、Serverless
iPaaS 体系在前台,面对着很多逻辑密集型需求,这些需求变更频繁,如数据格式化、数据字段转换和加工、数据标准化处理等,这些需求用传统的研发流程如 Java 交付周期会很长,频繁上线频繁变更导致线上系统运行稳定造成威胁,针对这些场景,iPaaS 提供即写即用、秒级上线的函数编写平台,通过把函数注入到应用程序中,提供本地调用,极大提升了逻辑性需求交付效率,同时也提供事件触发的方式执行函数,即解耦了技术和平台,又提升了资源利用率。不过现在的函数平台只是面对是公司的开发者,用来实现快速交付和个性化逻辑需求的快速定制,要实现真正的 FaaS,必须要能做到基于事件触发机制、自动弹性伸缩、按需付费等特点。iPaaS 在实现 Serverless 化的路上始终抱着开放的心态,利用云或自研实现函数平台的 Serverless 化,都是我们乐见的。以下是未来 iPaaS 函数平台的方向和规划:
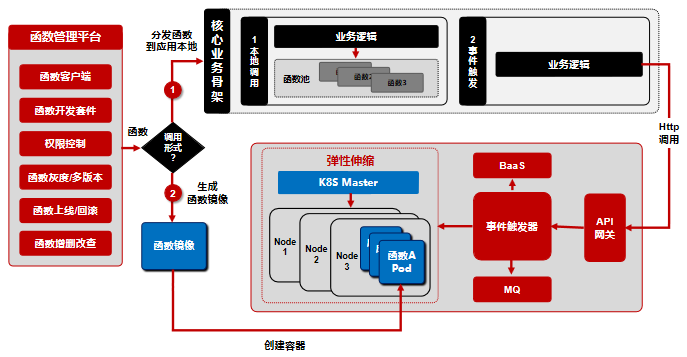
上图标注了 2 种函数执行的方式,第一张是通过函数管理平台把函数分发到应用本地,针对的是对函数执行延迟敏感的场景,应用直接调用分发到同一个进程中的函数,获得相应结果或完成某个能力;第二种方式是 iPaaS 未来需要完善的能力,通过健全基于事件触发的函数调用机制来实现按需付费,通过 Kubernetes+Docker 技术来构建可实现自动弹性伸缩能力的 Serverless 化架构。
3、Service Mesh
面对 RPC 服务框架如 JSF、Dubbo 存在的侵入性强、无法跨语言、中间件演变困难、内容多、门槛高、治理功能不全等问题,微服务的发现、流量管理、流量可观测性等能力完全可以让跟应用策底解耦的 Service Mesh 技术来实现。作为新一代 Service Mesh 产品的领航者,Istio 创新性的在原有网格产品的基础上,添加了控制平面这一结构,使其产品形态更加的完善。这也是为什么 Istio 被称作第二代 Service Mesh 的原因。Istio 能提供:
1) 为 HTTP、gRPC、WebSocket 和 TCP 流量自动负载均衡。
2) 通过丰富的路由规则、重试、故障转移和故障注入对流量行为进行细粒度控制。
3) 提供完善的可观察性方面的能力,包括对所有网格控制下的流量进行自动化度量、日志记录和追踪。
4) 提供身份验证和授权策略,在集群中实现安全的服务间通信。
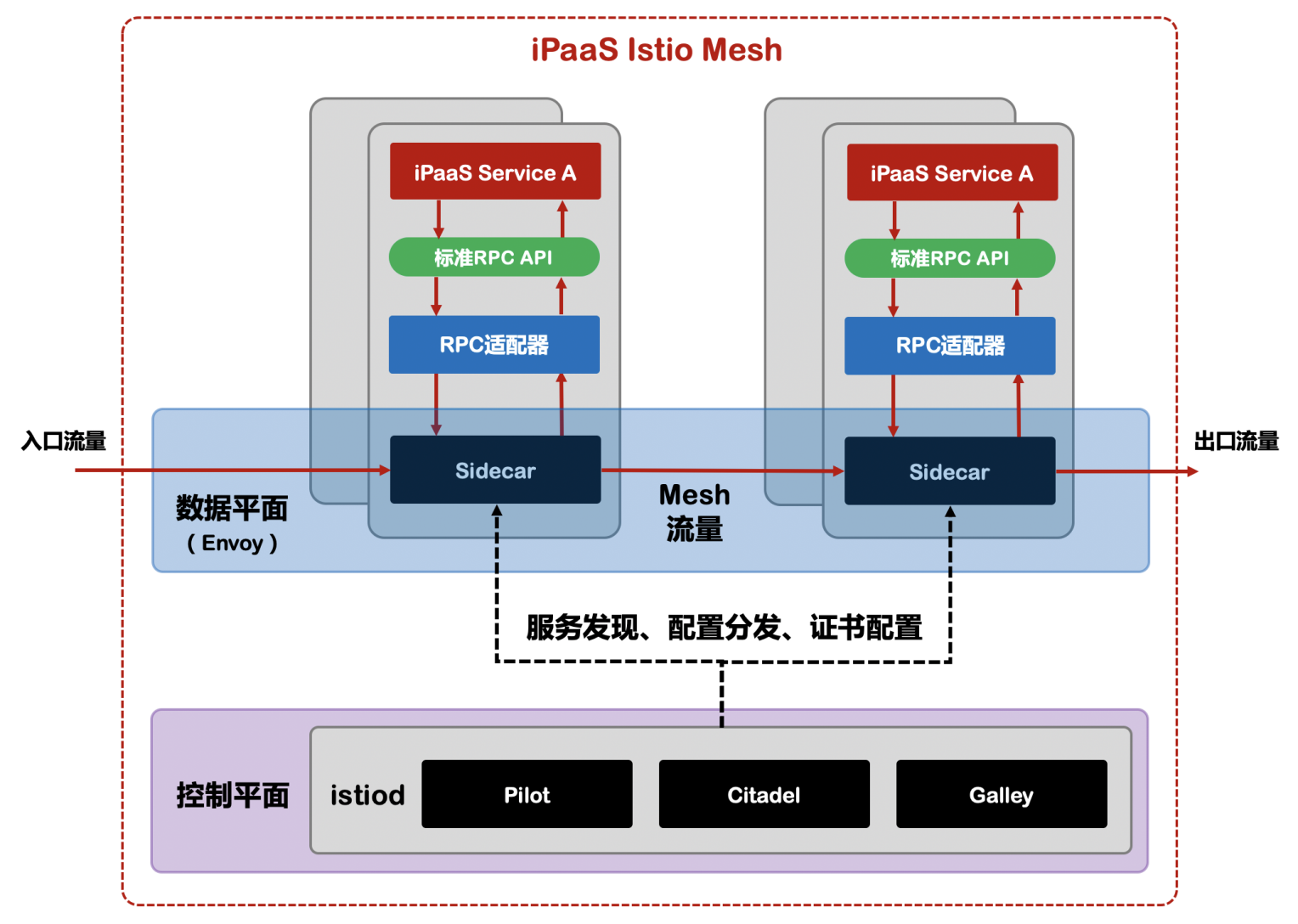
iPaaS 为了适应各类云环境和技术设施,借助标准技术 API 来屏蔽应用和具体技术,通过统一适配器来适配不同的技术设施和中间件,使 iPaaS 可以在不同环境中实现低成本移植。所以以上方案不仅让 iPaaS 不依赖 Istio,同时集成 Istio 能够给平台带来诸多如对应用透明、可扩展性、可移植性、策略一致性优势。
4、一键式商业化项目交付方案
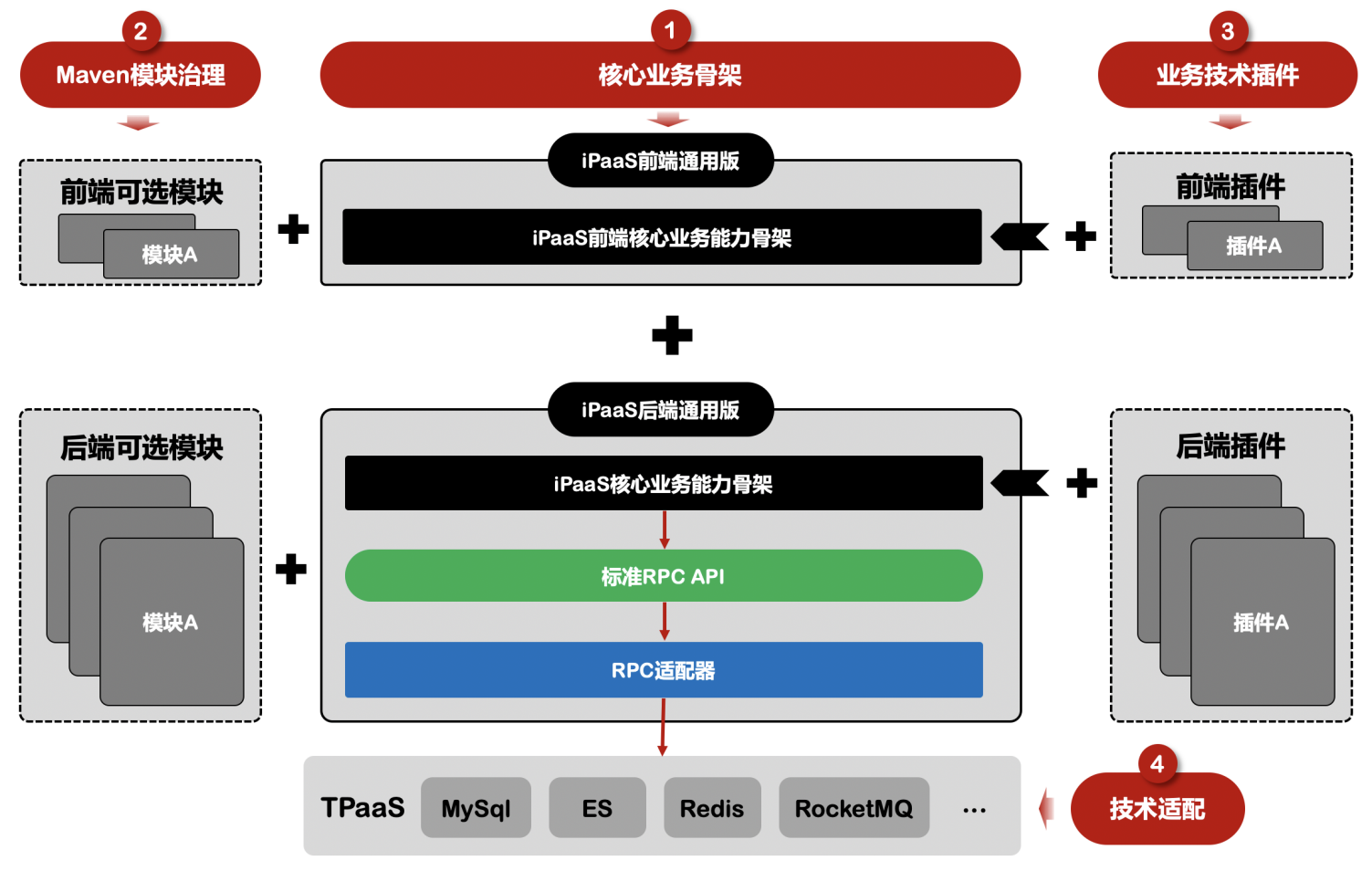
1)通用版
iPaaS 后端通用版能力已经经过了近 1 年半的改造和演进,目前核心能力通用性、按需根据 Maven 打包、SPI & BPaaS 能力扩展和定制等方面已经发展到一定的水平,可以做到不需要花费很多研发资源下较快把体系迁移到新站点,前提是新站点要具备京东云技术基础设施,也就是京东 IaaS 和 PaaS。本文前面也讲到技术商业化作为京东增长的新曲线,可以预见未来会催生越来越多的商业化赛道和项目,iPaaS 整体体系解耦京东 TPaaS 势在必行。所以为了 iPaaS 通用版的方向是进行策底的解耦 JD TPaaS 改造,通过标准技术 API+技术适配层来隔离 &适配底层技术。
2)一键式交付方案
系统有了通用版能力后,我们发现在响应新的站点和商业化项目过程中最大的工作量和难题是如何快速移植、部署整体平台体系到客户环境,可能是公有云、私有云,甚至混合云,这就需要我们依据云原生技术设计出一套可以快速部署完整 iPaaS 体系到不同客户云环境的能力,且体系可以做到稳定和一致性的方式运行。以下是我们初步设计的方案:
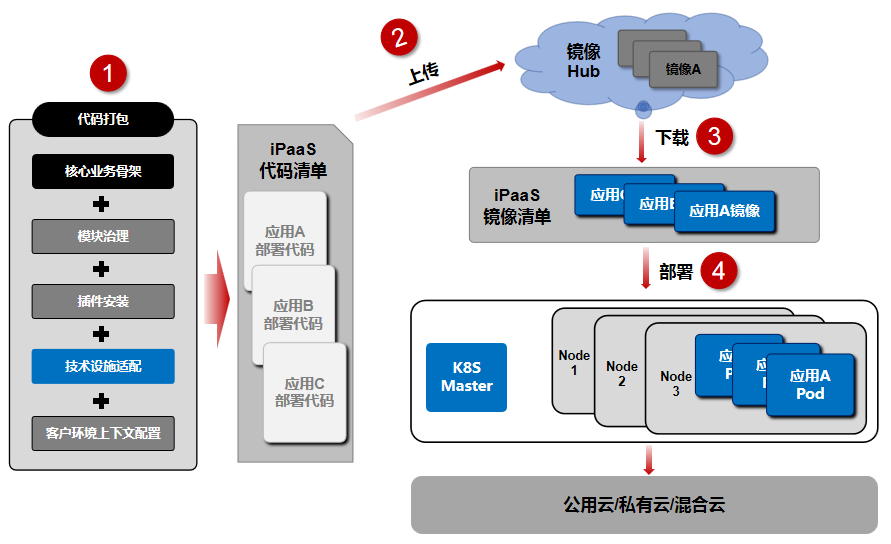
5、持续提升 iPaaS 平台韧性
应用通过接入云原生服务可以天然获得可观测性、高可用、容错性、自愈等能力,从而构建韧性应用。同时云原生的架构原则也同样在我们开发者在开发和设计软件架构时起到非常好的指导作用,包括服务化、弹性、可观察性、韧性、自动化、零信任等原则,帮助我们更好的建设系统的高可用基础能力,包括:从架构设计上,韧性包括服务异步化能力、重试/限流/降级/熔断 / 反压、主从模式、集群模式、AZ 内的高可用、单元化、跨 region 容灾、异地多活容灾等。
iPaaS 在云原生领域还处在思索和探索的阶段,本文只是希望能够抛砖引玉,文中阐述的理解和想法可能存在纰漏、错误,也希望读者们抱着宽容来阅读和回复,有任何问题、建议请回复本文或发送邮件到 i-paas@jd.com。
引用:
1、Kubernetes 官网:Kubernetes官网
2、阿里云原生白皮书
3、Istio Handbook




