
Uber 工程团队对其数据复制平台做了全面升级,现在每天可以在混合云和本地数据湖之间移动数以 PB 计的数据,解决了由于工作负载迅速增长而引起的扩展挑战。该平台基于 Hadoop 开源框架Distcp构建,现在每天处理超过 1PB 的数据复制和数十万个作业,而且速度更快、可靠性和可观测性更高,使得数据分析、机器学习和灾难恢复都达到了前所未有的规模。
Distcp是一个开源框架,它使用 Hadoop 的MapReduce跨多个节点并行复制大型数据集。文件被分割成块,并分配给在YARN容器中运行的 Copy Mapper 任务。Resource Manager 分配资源,Application Master 监控作业执行并协调合并,Copy Committer 在目的地组装最终文件。Uber 的 HiveSync 团队针对 PB 级工作负载优化了这一架构。他们将准备任务移到了 Application Master,实现了列表功能和提交过程的并行化,并提高了小规模传输的效率。
最初,HiveSync是基于 Airbnb 的ReAir项目,使用批量和增量复制实现 Uber HDFS 和云数据湖的同步。对于大于 256MB 的数据集,它通过异步工作进程并行提交 Distcp 作业,并用一个监控线程跟踪进度。随着每日复制的数据量从 250TB 增长到超过 1PB,数据集从 30000 扩展到 144000,HiveSync 面临的积压任务已威胁到服务水平协议(SLA)的达成,这说明他们亟需通过运维与架构升级来支持云迁移及他们的主备数据湖模型。
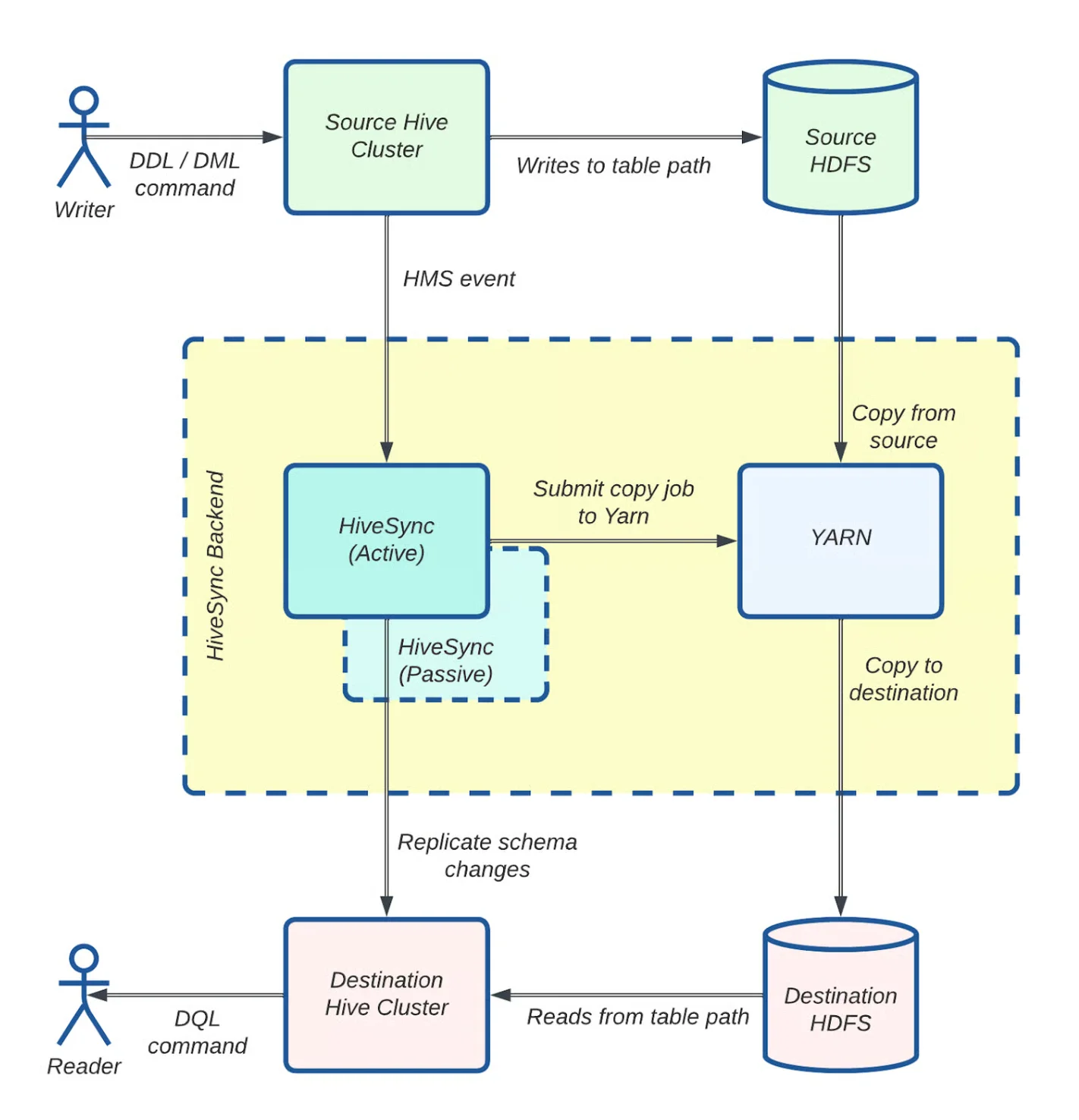
HiveSync 架构:使用 Distcp 的数据复制工作流(图片来源:Uber 博客)
为了克服扩展挑战,HiveSync 团队通过将资源密集型任务(如 Copy Listing 和 Input Splitting)从 HiveSync 服务器迁移到 Application Master 增强了 Distcp,减少了 HDFS 客户端争用,并将作业提交延迟减少了高达 90%。Copy Listing 和 Copy Committer 任务被平行化,允许同时处理多个文件,同时保持块顺序不变,p99 列表延迟降低了 60%,最大提交延迟降低了超过 97%。对于规模比较小的作业(传输数据少于 200 个文件或小于 512MB),Hadoop 的 Uber 作业功能直接在 Application Master 的 JVM 中运行 Copy Mapper 任务,每天消除了大约 268000 次容器启动,并提高了 YARN 效率。
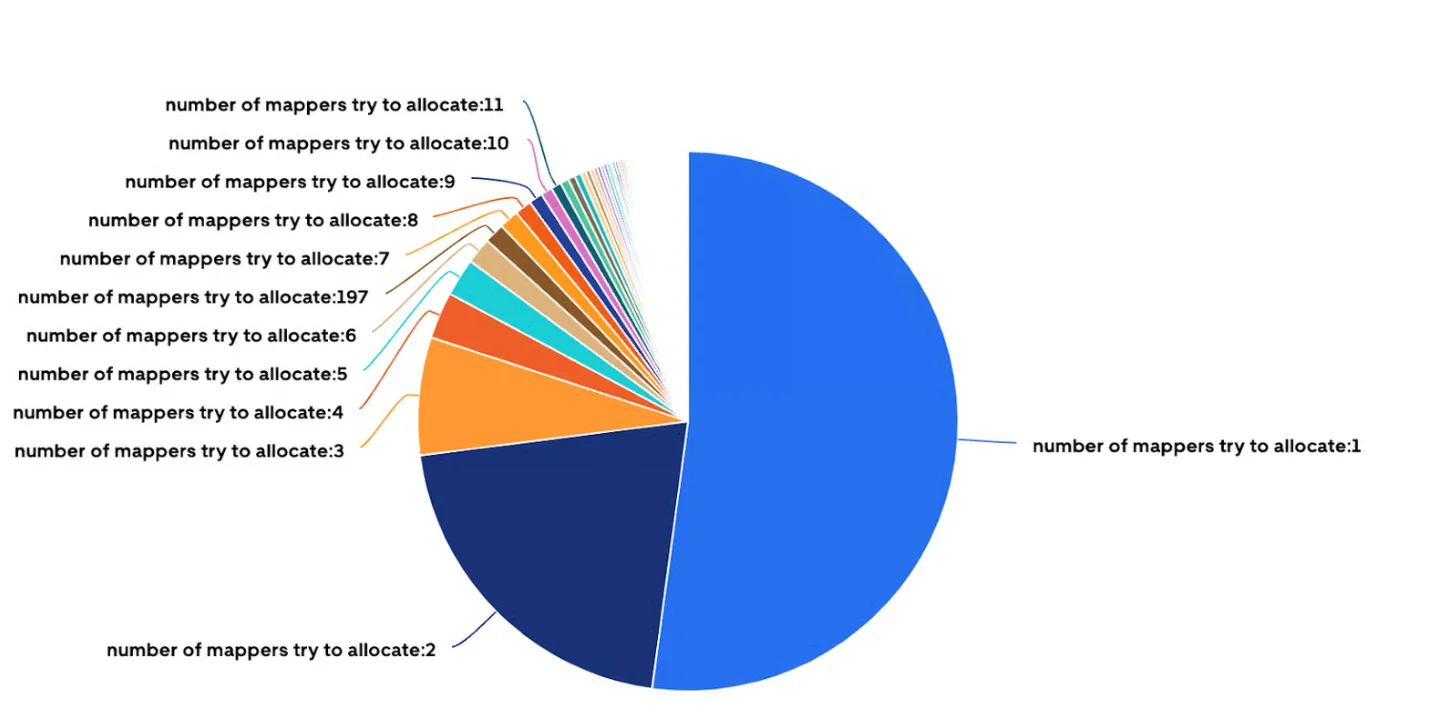
超过 50%的 Distcp 作业被分配给单个映射器(图片来源:Uber 博客)
这些优化将增量复制能力提高了五倍,使 HiveSync 在 Uber 进行 on-premise-to-cloud 迁移期间复制了超过 300PB 数据,而且没有发生一次事件。增强的可观测性(包括作业提交、复制列表、提交者指标、堆内存使用率和 p99 复制速率)可以帮助工程师监控工作负载并预防故障。通过压力测试、断路器机制、YARN 配置优化以及任务执行顺序重排,有效缓解了内存不足、作业提交量高和复制列表任务持续时间过长等问题。
展望未来,HiveSync 团队正专注于进一步提升并行化以及优化资源管理和网络效率。计划中的增强包括:并行化文件权限设置和输入拆分操作,将计算密集型提交任务移到 Reduce 阶段,并实现动态带宽节流器。Uber 计划将这些改进作为开源补丁贡献给社区,提高社区管理混合云环境中超大规模数据复制的能力。工程团队指出,对于他们那样的规模,即使是小的改进也能带来显著的收益。这些工作突显了在复杂的多区域数据管道中维持高吞吐量和可靠性能所需的运营和工程创造力。
声明:本文为 InfoQ 翻译,未经许可禁止转载。
原文链接:https://www.infoq.com/news/2026/03/uber-scaled-data-replication/




