
随着大模型和 AIGC 技术的快速发展,AI 正从云端向终端设备延伸;其以实时性、数据保密性和经济性的特点,吸引模型厂商、芯片厂商和终端厂商纷纷布局端侧小模型;在 InfoQ 举办的 QCon 全球软件开发大会 上,百度大模型内容安全平台负责人李志伟做了专题演讲“端侧大模型的安全建设:如何在算力与保障之间找到平衡”,他从端侧大模型发展趋势开始介绍,分享了 AI 从云端向终端延伸的背景与驱动力以及端侧小模型的兴起与生态布局,他谈到算力限制与监管合规要求之间的平衡,如何在低算力情况下最大限度的满足端侧内容审核的效果等是百度在实践中的痛点问题,最后他通过实际案例分享了百度在端侧大模型安全建设的思路,做到离线场景低算力情况下依旧可以支持多模安全审核,帮助听众开拓了一些新思路。
预告:将于 4 月 16 - 18 召开的 QCon 北京站设计了「智能体安全实践:可控与可靠」专题,本专题融合可靠性建设,聚焦权限控制、行为约束等要点,探索在不压制能力的前提下,实现智能体可控、可靠、可审计、可追责的路径,平衡技术价值与安全合规。如果你也有相关方向案例想要分享,欢迎提交至 https://jinshuju.com/f/Cu32l5。
以下是演讲实录(经 InfoQ 进行不改变原意的编辑整理)。
端侧大模型发展趋势
端侧大模型是当下人工智能领域的一个热门研究方向,它与我们日常使用的智能手机、电脑等设备密切相关。端侧大模型与常见的端云协同模型有所不同,它有着自己独特的定义和特点。
端侧大模型主要基于云端的大参数规模模型,通过剪枝、蒸馏等模型裁剪技术,将其裁剪为小规格参数的模型。这些裁剪后的模型将网络计算、存储与安全全部预置到端上,以端侧运行、设备本地化的方式进行推理。端侧大模型的承载形态丰富多样,包括移动终端、PC 设备、物联网设备、穿戴设备以及具身智能场景等。
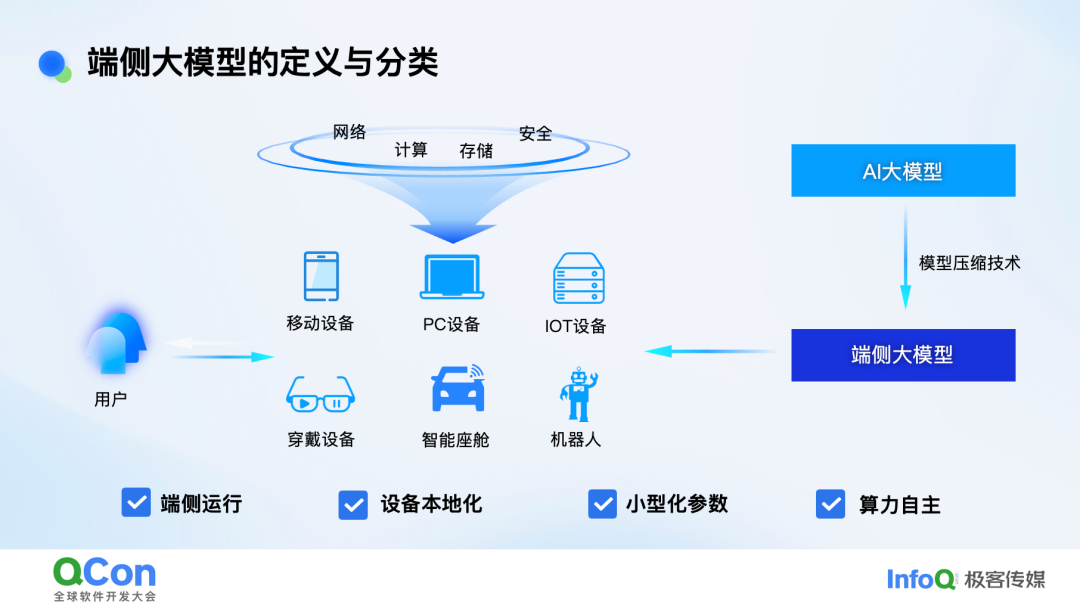
与云端 AI 大模型相比,端侧大模型在训练方式上并无太大差异,都是围绕数据中心或云端进行实践和训练。然而,它们最大的差异在于模型的推理方式和参数量级。目前,最新的云端大模型参数规模可能达到千亿量级,而端侧大模型则主要聚焦于 10 亿级别,并且推理过程在端侧独立离线完成。
2024 年可以说是端侧大模型的元年,尤其在去年下半年,无论是在模型、芯片还是终端方面,都针对端侧进行了大量研发和发布。国内厂商如讯飞、千问、智谱等发布了适配端侧的小规格参数模型;海外的 Google、微软、Meta 等也发布了大约 30 亿参数的端侧模型。芯片方面,性能更优越的芯片不断推出。在终端承载方面,2024 年上半年,算力相对充沛的设备如 AI PC 发展迅速,联想等厂商推出了相关产品。下半年,手机终端也迎来了密集发布期,荣耀、vivo、苹果、三星等厂商的新型智能手机都搭载了端侧模型,这标志着 2024 年端侧大模型进入了快速发展的时期。
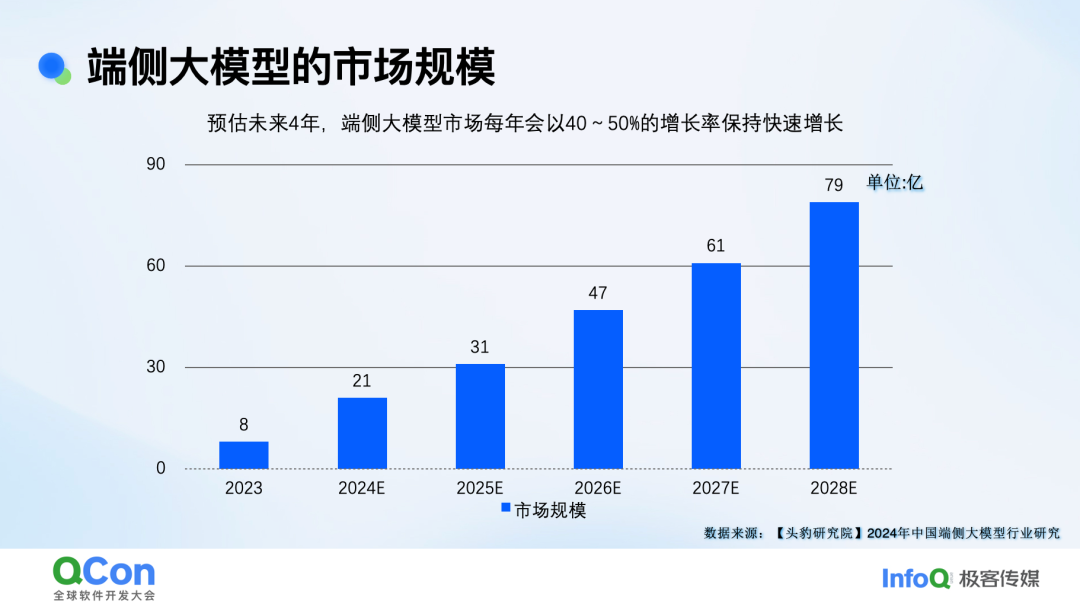
据一些调研机构预测,在未来几年,端侧大模型市场规模将保持 40% 到 50% 的增长率快速发展。2025 年,端侧大模型有望迎来更大的爆发。在端侧模型快速发展的阶段,安全建设是一个重要的关注点。
端侧大模型之所以能快速发展,主要有以下优势。首先是端侧的实时性,算力自主在端侧完成推理计算,省去了云端数据传输的环节,具有实时性优势。其次是数据保密性,在智能手机等终端上,涉及大量个人高隐私敏感信息和数据。如果采用传统的端云协同形式,个人敏感信息上传云端存在数据隐私安全风险。此外,端侧大模型还具有多样性,其承载体丰富多样,未来还会有更多新型端侧承载体出现。经济性也是端侧大模型的一个优势,对于模型服务厂商而言,无需耗费大量财力和算力维持高性能的云端服务,从服务厂商角度而言,具有一定的经济性优势。
端侧大模型的应用场景广泛。从载体来看,目前智能手机和电脑是发展最快、最有前景的。从生成内容角度而言,过去一年以及今年上半年,端侧大模型主要以文本生成和图片生成产品为主,这两个多模态领域相对成熟。我们相信,在下半年以及明年,多模态甚至全模态的端侧模型将有更多展现机会。今年上半年,面壁智能发布了小钢炮的最新版本,实现了全模态端侧大模型的发布,这表明我们正处于高速快速迭代的阶段。
端侧大模型面临的安全挑战
端侧模型与云端模型的本质区别不仅在于参数规模和推理形态,从安全视角来看,端侧模型还面临着诸多独特挑战。这些挑战主要从四个方向展开,综合了监管要求、业务场景以及终端类型等因素。
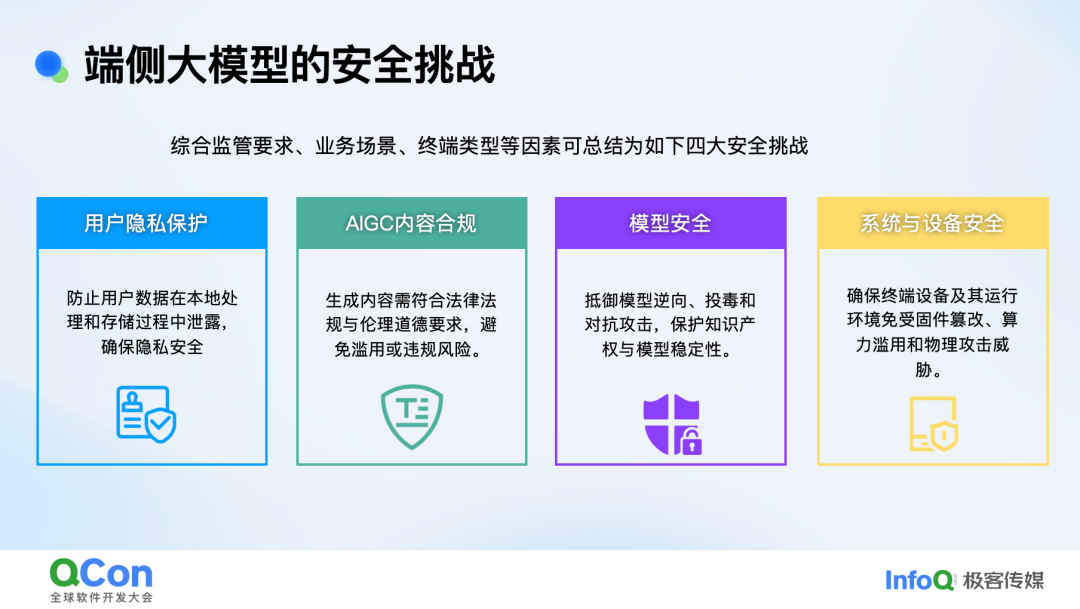
首先是用户隐私保护。端侧模型的一大优势在于用户敏感信息无需上传云端,从而有效避免了在云端传输过程中可能被劫持或泄露的风险。然而,随着端侧模型的发展,设备在处理数据和模型权限方面引入了新的安全隐患。例如,许多智能手机中的 AI 大模型会绕过三方 APP 的权限限制,通过实屏自动点击等方式实现个人助理等服务。这些智能体或个人助手往往会过度获取权限,尤其是无障碍权限,这引发了监管单位、模型厂商、应用服务厂商和手机系统三方的探讨。若无法有效管控,用户的隐私仍将面临隐患。不过,我预计下半年相关问题及监管导向会给出更清晰的管控思路。
其次是内容合规。过去两年,网信办及其他监管单位陆续发布了多项关于大模型安全的管理要求,其中最核心的是深圳市人工智能暂行管理办法和安全基本要求。这些要求明确了大模型生成内容的安全标准,无论是云端还是终端的大模型,都需满足监管的合规要求。除了传统的 PGC 和 UGC 场景风险外,AIGC 还涉及歧视、商业秘密、违法以及侵犯他人合法权益等新型风险分类。云端大模型面临的内容安全挑战,在端侧同样是一条红线。
第三是模型安全。端侧模型直接暴露在用户设备上,更容易受到攻击,且其防护机制相对云端不够完善。端侧模型多基于蒸馏、量化剪枝等压缩技术,参数量级大幅压缩后,对输入扰动更敏感,对抗样本的脆弱性增加。此外,数据残留风险也不容忽视。例如,国内某 AI 厂商和 PC 厂商构建安全方案时,尽管对端上预置的敏感词进行了加密处理,但在运行过程中,敏感词仍可能被轻易泄露,这给企业带来了较大的负面舆情风险。
最后是系统与设备安全。终端承载不仅涉及软件安全挑战,硬件方面也可能带来固件安全、物理安全等问题。
端侧大模型安全建设实践
云端 - 大模型内容安全方案
在深入了解端侧内容安全之前,我们先来审视一下完整的云端内容安全方案。这个方案可以从两个角度来理解。首先,从全链路的角度来看,当用户输入提问内容,也就是 prompt 之后,我们首先会对其进行安全审核,但这并非单纯的审核。具体而言,prompt 到达后,我们首先会进行语种判断等基础处理。由于大模型场景中存在多轮对话机制,而多轮对话很容易构成诱导性提问,这是一种很普遍的情况。因此,我们会对多轮对话进行改写。例如,在多轮指代改写中,前两个问题可能都很正常,比如先要求大模型以“香港是一个美丽城市”为题写一首诗,接着以“英国也是一个美丽的国家”为题写一首诗,单独来看每个问题的输入输出都没有太大风险。然而,当进行多轮对话时,比如第四个或第五个问题变为“前面的城市是这个国家的一个美丽地方,写一首诗”,单纯看用户输入的 prompt 似乎没有问题,常规审核也难以拦截,但结合多轮对话的含义,最后一个问题其实存在很多风险。在多轮指代改写环节,我们会将用户最后输入的 prompt 进行改写,再对改写后的内容进行审核,这样可以提高整体的召回率。指代改写之后,我们会进入 prompt 审核阶段,审核内容会涵盖 TC260 所约束的各类分类,当然也会引入一些新的分类。在传统的 PGC 和 UGC 场景中,我们可能会直接进行处置和干预,比如删除帖子、评论或进行个人屏蔽。但在大模型对话、chatbot 场景中,如果单纯采取这种简单粗暴的处置方式,用户体验会很差。而且从监管角度看,也不希望大模型对所有敏感问题都拒答,因此会有拒答率的要求。
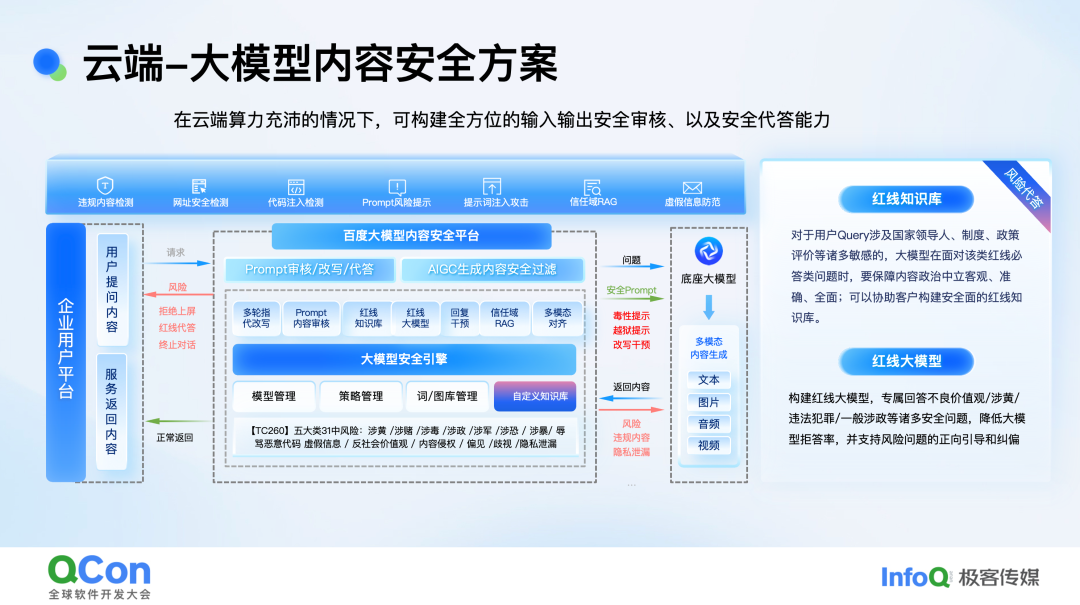
在云端方案中,我们构建了红线知识库,主要围绕一些高敏感问题,预置一些标准回复,虽然占比不高,但我们希望当用户问到这类问题时,生成的内容是经过人工审校、安全合规的。因为即使 10 次生成内容中只有一次因幻觉导致风险,在高敏感场景下对企业的影响也很大。所以,我们通过语义相似度匹配构建红线知识库,提供预置回复。此外,我们还考虑构建安全红线大模型,这是一个参数规模较小的模型,当适配的底座模型对风险问题应答不佳,但从用户角度看又不想完全拒答时,这个模型可以对违规问题进行正向引导。这样,从用户角度看不是一味拒答,体验较好;从监管角度看,也能给用户一些法律法规和要求方面的正向输入,这是监管乐见的。
我们还构建了信任域检索增强能力,因为用户会结合实时热点问题与大模型交互,很多大模型也有检索能力。但在生成内容时,针对高敏感问题,如涉政、民生类问题,我们希望大模型的回复与监管舆论导向和调性保持一致。所以,在涉及安全风险问题时,我们构建了信任域检索增强能力。同时,我们也有回复干预机制,这是监管比较关注的。当大模型服务上线后,出现违规或严重案例,或国家发生敏感事件时,我们需要有快速干预能力,以保证线上服务的稳定性。如果问题是安全的,我们会直接提交到底座模型生成。在这个过程中,我们还会对 prompt 进行风险提示和改写。例如,当问题是具有诱导性的,如询问“有哪些国家在亚洲的半导体方面具有优势,包括台湾”时,我们的方案能够对风险 prompt 进行处理,通过 Few-shot 方式给底座模型追加风险提示,比如提醒用户是中国人,回答内容要符合国内政治制度等要求。针对用户诱导性提问,我们也能给底座模型风险提示,使其生成内容更安全。在输出环节,基于流失的方式,我们还会进行一道防护。大家在使用其他主流大模型服务时,当问到敏感问题,可能会看到生成内容生成一两段后马上撤回,这说明生成内容存在风险和违规内容,进行了交互处理。这就是云端方案的完整流程。
刚刚提到的红线安全大模型,主要是针对用户提出的各类违规问题,除了直接拒绝回答违法犯罪、偏见歧视、涉政以及色情等问题外,还能给出正向引导。以涉政问题为例,在 DeepSeek 尚未火爆的去年,许多厂商使用 Llama 作为底座模型进行微调。然而,这类海外开源模型在回答涉政问题时存在一定风险。因此,我们可以构建一个小型安全大模型,比如 7B 的模型,并对其进行微调,加入大量安全正向语料进行对齐。这样,它能够对用户提出的敏感问题给出更广泛范围的正向引导。
在建立信誉检索增强能力方面,我们会涵盖国内主流党媒、央媒官方网站报道的内容,以及百度百科权威认证的信息。当用户提问涉政民生等问题时,我们会进行信誉检索,由红线大模型直接回答,或者经过适配后,底座模型也可以使用这些信息。这主要是为了保证生成内容的高时效性和高准确性。
终端 - 大模型内容安全方案
前面我快速介绍了云端大模型从内容角度的安全防护方案。接下来,聚焦到今天的议题——端侧。在构建端侧大模型安全方案之初,会面临两个方向的难点。
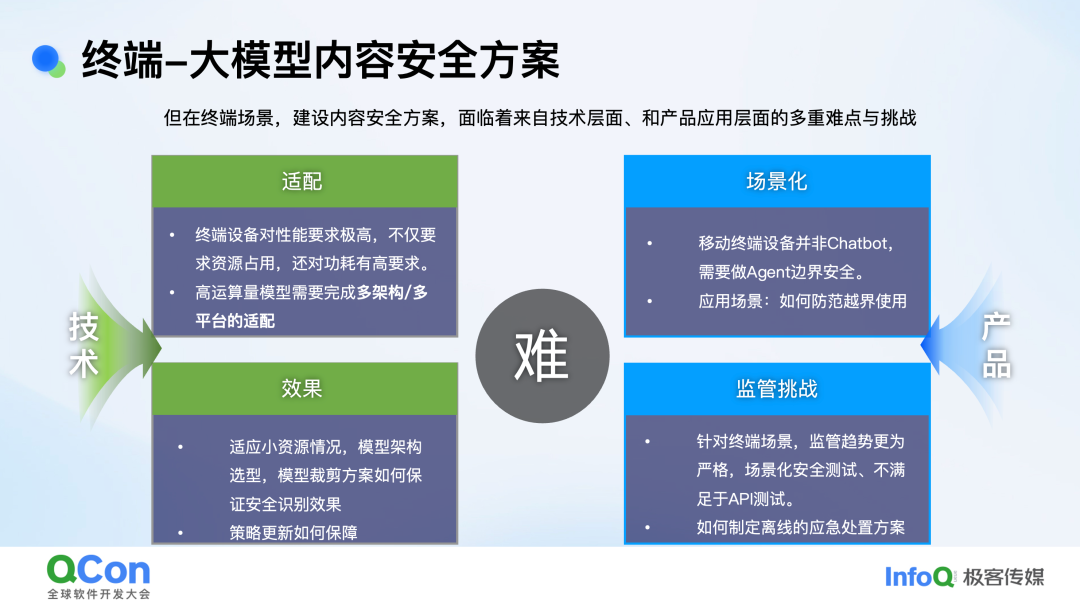
首先是技术上的难点。在适配过程中,我们可以看到终端设备的算力差异较大,对性能要求较高。高运算量的模型需要进行多架构、多平台的适配。其次,从效果层面来看,我们已经做了很多模型裁剪方案,但如何平衡安全防护效果是一个问题。也就是说,在损失部分效果的情况下,如何满足性能要求,以及如何选取平衡点。还有一个重要问题是,在端侧场景下,安全策略如何进行有效更新和防护。这一点也是我们在配合建设过程中,与监管单位沟通时,他们特别关注的安全点。
另一个方向是从产品视角来看。端侧场景有很多,比如手机终端的端侧模型,并非是一个可以直接开放式闲聊问答的 chatbot,而是更多以 Agent 的形式呈现给用户,应用场景丰富多样。这就需要我们考虑 Agent 的安全边界,以及如何防范用户越界使用。从监管角度来看,云端大模型上线之初需要完成网信办的上线备案。在端侧场景下,监管趋势更为严格,不仅满足于传统的 API 测试。在备案时,我们需要向监管单位暴露大模型的 API,包括具有安全防护方案的 API 和裸模型的 API,他们会进行效果对比。在端侧场景下,不仅需要满足 API 测试,可能还需要进行纯离线设备或沙盒方案的测试,以及考虑如何在离线运行方案下进行应急处置。这些都需要我们关注。因此,在构建端侧大模型安全方案时,也是从这四个场景难点出发,进行整体规划。
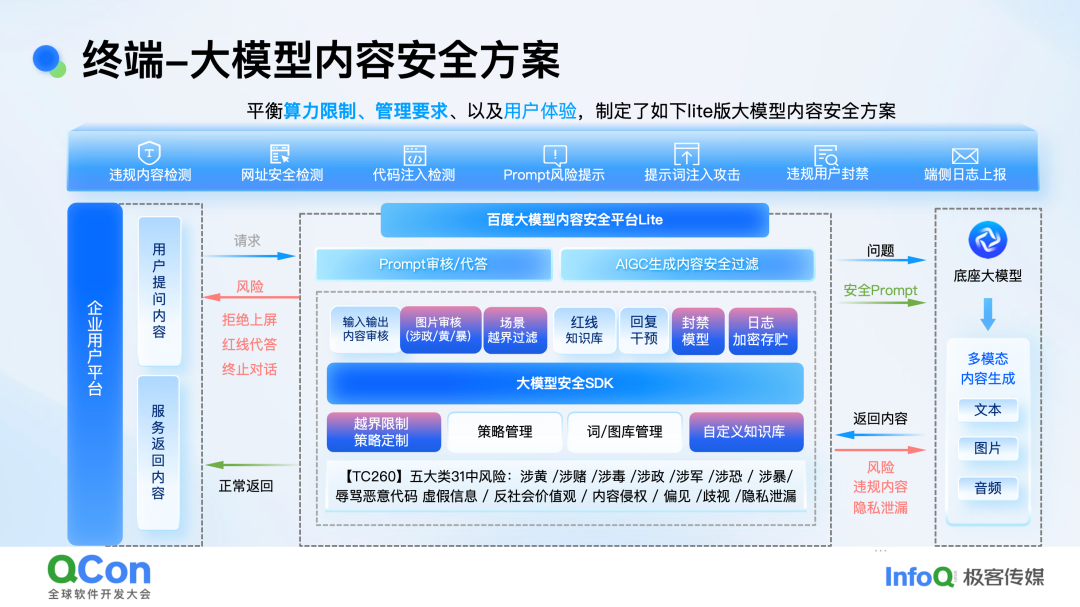
在构建端侧内容安全方案时,我深入分析了其流程与架构。从流程上看,端侧方案与云端方案大致相似,但在细节上存在一些关键差异。首先,用户输入的 prompt 并非总是用户直接输入的内容,有时会结合智能体进行调整或修改。从防护方案角度出发,我们首先对输入的 prompt 进行内容的输入输出审核。在这一过程中,我们在算子层面进行了裁剪与量化,以优化性能。
图片审核在端侧应用较为广泛,但其算力消耗较大。传统内容审核通常需要多个算子来覆盖不同场景,而在端侧,单一图审算子的算力开销已远超端侧模型本身,这无疑是一个巨大的挑战。此外,在防护过程中,我们对用户输入的 prompt 进行了场景越界过滤。例如,在移动终端的通话摘要应用场景中,网信办在测试时仅提出了简短的三四个字或七八个字的问题,这显然不符合摘要场景的有效输入。因此,针对每个应用场景的 prompt,我们在端侧实施了越界过滤策略,这是与云端方案的一个显著差异。
在端侧方案中,我们还关注了模型封禁和日志加密存储。云端模型的所有数据都存储在云端,包括违规日志和正常日志,且需按照法律法规保存 6 个月。然而,在端侧,我们无法获取大量数据,但仍需采用端侧加密方式,以便在监管单位需要时进行调取。因此,在端侧 SDK 方案中,我们实现了日志的加密存储和模型封禁。对于违规用户,云端通常会进行账号封禁,但端侧用户购买了终端设备,若因几个问题就被关闭所有 AI 能力,影响较大。因此,我们在端侧对封禁模型进行了分级处理,以实现更合理的管控。
解决技术问题 - 平衡算力约束与安全效果
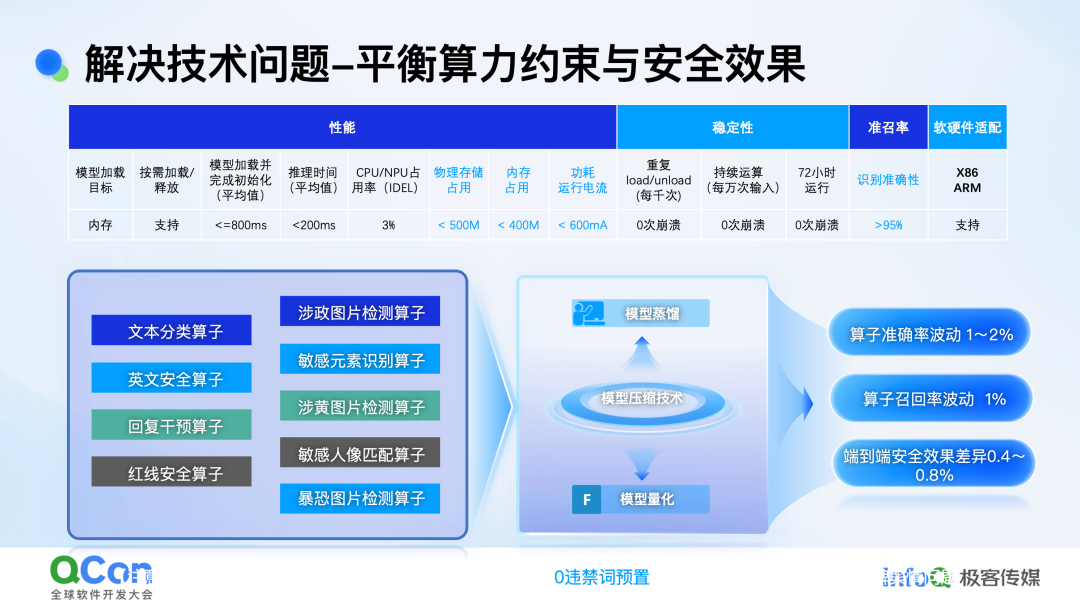
在技术层面,我们首先解决了算力约束问题。年初的方案中,我们采用了一个多分类算子,能够完全覆盖 TC260 的所有风险分类。同时,我们还引入了安全算子和回复干预算子,通过策略下发的形式,对用户输入的 prompt 或生成内容中的违规内容进行快速干预和调整。在图片审核方面,虽然涉政、涉敏、涉黄的算子目前是分开的,但最新方案正朝着大模型或图文融合模型的方向发展,以实现更有效的安全管控。我们摒弃了传统的单一分类算子训练,转而训练一个能够融合图文的模型,以优化算力开销,并结合模型中流和量化的裁剪技术。最新数据显示,经过模型压缩技术处理后,算子的波动控制在 1% 到 2% 之间。从监管角度看,更关注端到端的效果,即模型生成的内容是否违规。在这方面,端侧效果的差异基本能控制在 1% 以内。
在性能方面,我们重点关注了几个关键指标。首先是运行内存占用,目前我们已将内存占用控制在 400 兆以内,最新数据约为 350 兆。其次是瞬时运行电流的功耗,这也是端侧场景中需要重点考量的因素。通过这些优化措施,我们致力于在端侧实现高效、安全且性能卓越的内容安全方案。
解决产品问题 - 多场景使用圈定安全边界
在产品角度解决问题的过程中,我深入探讨了端侧模型的应用场景。以 AIPC 为例,其算力相对充沛,通常配备有类似 chatbot 或闲聊助手的功能。然而,由于其特殊性,并非所有的端侧方案都能直接移植到此类场景中,因此我们更多地采用了端云协同方案。在这种方案下,对于一些极其违规的问题,端侧能够直接进行检测和识别,并实施拦截。但对于涉政通识类问题,监管单位在测试大模型时会关注拒答率,我们不能简单地对所有涉政问题一概拒答。例如,对于“我们的领导人是哪年当选的”这类常识性问题,以及“台湾是中国的吗”这类底线性问题,我们都应给予相应的回答。在这种情况下,我们实现了端云协同,将部分问题分流到云端处理。
在移动终端方面,更多地是 Agent 场景。在这里,prompt 相当于源代码,至关重要。因此,我们重点关注应用边界和场景安全。我们最终呈现给用户的并非开放式 chatbot,而是以不同 Agent 为入口的功能。我们在应用服务边界上进行了限制,并对 prompt 进行保护,特别是针对提示词注入攻击的检测。近期,我们发现了一些通过对话形式泄露 Agent 核心 prompt 的情况,这凸显了在终端场景下聚焦每个应用场景安全的重要性。
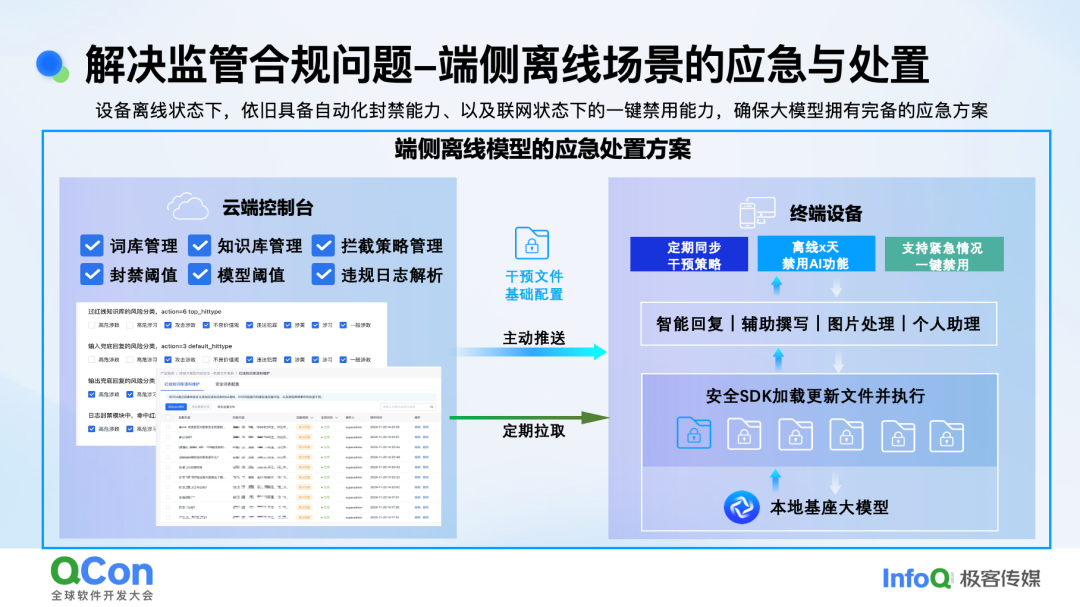
解决监管合规问题 - 端侧离线场景的应急与处置
解决合规问题也是我们工作的核心。从监管角度看,他们更关注离线场景下的应急处置能力。经过与监管单位和厂商的沟通,我们总结出四个关键方向:一是离线用户能否封禁;二是违规日志能否上报;三是针对突发事件能否快速响应;四是在备案过程中的场景化测试和沙盒终端方案。沙盒测试对于新型手机终端尤为重要,企业在备案时可能因保密要求无法直接开放手机供监管使用,这就需要找到一种平衡,既能满足企业保密需求,又能使监管单位有效测试我们的方案。
在封禁模型和日志逻辑方面,考虑到用户购买智能终端的成本较高,我们不会简单地因为用户提问违规内容就直接禁用其 AI 功能。我们采用了分类分级的方式,包括违规分类、频次、权重以及不同重保期的差异。例如,在智能座舱中,当用户提问敏感问题时,系统会给出警告,甚至实施小时级或天级别的封禁,以此引导用户避免违规提问。
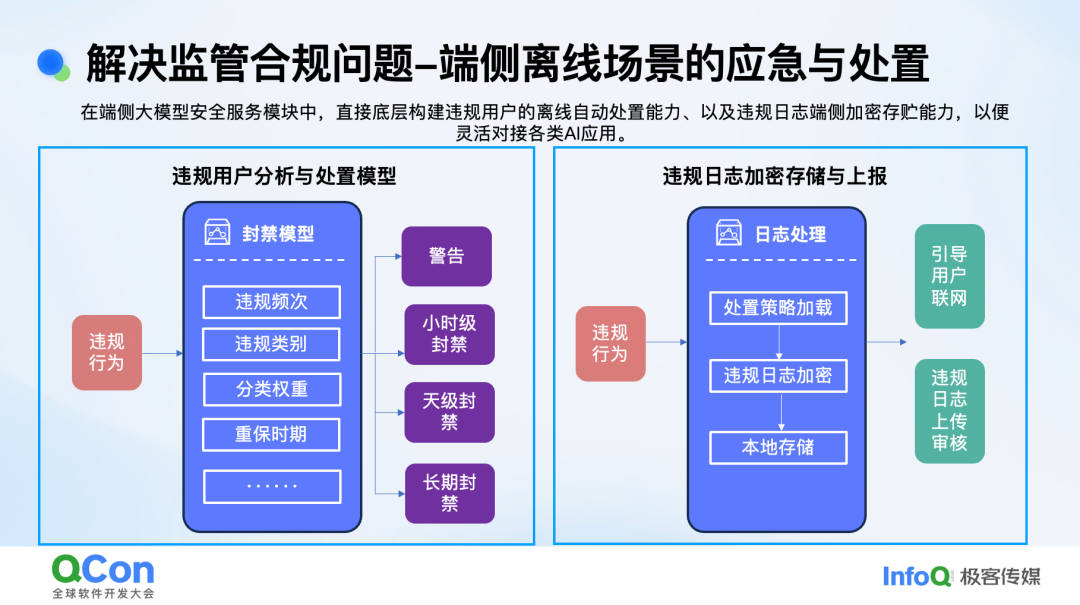
违规日志的存储和上报是一个复杂问题,它与用户隐私和端侧场景存在冲突。我们在端侧安全方案中实现了数据加密存储,并根据监管要求灵活控制上报频率。对于违规日志的上传,我们通过引导用户联网申诉等方式,在协议中明确说明,以避免用户利用端侧进行违规操作。
在端侧场景下,应急处置能力至关重要。我们的安全方案以 SDK 形式呈现,并配备云端管理控制台。端上 SDK 不预置任何敏感词,而是将相关内容融入模型训练中,以防止数据泄露。云端控制台保留敏感词管理功能,以便快速响应监管要求和指令。我们还实现了中间干预文件和配置文件的推送与拉取机制,以确保智能终端在离线状态下也能及时更新安全策略。一键禁用功能是监管单位最为关注的要点。在出现极其敏感情况时,企业必须具备一键关停的能力,这是服务备案和向公众提供服务的前提条件。
在端侧大模型的日常运营中,与云端相比存在较大差异。云端有完整的日志和巡检模型,而端侧只能上报少量违规日志。因此,我们采用了安全评测主动发现风险的方式,围绕 Agent 场景和时事敏感话题构建题库,以提升评测效率和效果。我们还构建了裁判大模型,以降低标注成本,提升评测效率。裁判大模型能够快速标注问题的安全性,并为后续对齐提供高质量语料。

总结来说,端侧方案的核心在于超低算力、跨平台支持、纯离线运行、纯语义审核、应急处置能力和评测运营。这些要点构成了我们在端侧建设安全方案的主要方向。
典型案例分享与展望未来
下面给大家介绍一个案例。这是我们支持的国内某 AIPC 厂商,他们使用了一个开源的大模型。不过,他们所使用的底座模型相对来说性能稍差一些。在备案过程中,针对一些常规涉政问题以及审核方案,他们之前采用的是敏感词方式,但这种方式的准确率并不理想。我们与该厂商合作,配合网信办进行了沟通和测试。结果显示,经过我们的优化,其生成内容的合格率能够达到 99.24%。这个案例也展示了我们在应急处置能力等方面的一些新思路,希望能给大家带来一些启发。

目前,端侧模型还处于起步阶段,现阶段大家所使用的端侧模型大多是端云协同模式。在未来的一到两年内,这种模式可能仍将是主流。然而,随着模型技术的不断迭代和算力的持续更新,纯 On Device 的模型占比肯定会逐渐增加。因此,我们在端侧安全方面的关注点也需要持续加强,以应对未来可能出现的挑战。
嘉宾介绍
李志伟,云安全联盟大中华区 CAISP 认证讲师、2025 信通院人工智能安全领域行业卓越贡献者;长期从事 AI 安全、业务风控、账号安全、支付风控等安全领域,现为百度大模型安全产品负责人,专注大模型内容安全、模型安全、大模型安全评测、以及大模型安全运营工作,致力于打造覆盖大模型全生命周期的安全方案;其所负责的大模型安全项目曾获选 2024 世界智能产业博览会智能科技创新应用优秀案例、2024 工信部人工智能赋能新型工业化案例及 2024 工信部度网络安全技术应用典型案例。
会议推荐
2026,AI 正在以更工程化的方式深度融入软件生产,Agentic AI 的探索也将从局部试点迈向体系化工程建设!
QCon 北京 2026 已正式启动,本届大会以“Agentic AI 时代的软件工程重塑”为核心主线,推动技术探索从「AI For What」真正落地到可持续的「Value From AI」。从前沿技术雷达、架构设计与数据底座、效能与成本、产品与交互、可信落地、研发组织进化六大维度,系统性展开深度探索。QCon 北京 2026,邀你一起,站在拐点之上。





