
当短剧出海、跨境电商等新兴领域打造全球化内容时,面临着一个棘手的基础问题——原始视频的中文字幕。原始字幕对于海外观众来说,不仅是无效信息,还严重干扰观看体验。传统方案——直接添加对应外语字幕会导致画面杂乱,而使用马赛克或基于 GAN 的字幕擦除补全方案会导致画面模糊、帧间闪烁,都无法彻底解决这一挑战,使得优质内容的出海之路障碍重重。
如今,火山引擎视频点播带来了破局之道——应用基于 DiT 大模型与字体级分割的无痕字幕擦除功能。该方案以两大核心技术突破和强大工程能力,重新定义字幕擦除标准,不仅可以实现全片真实自然的“无痕擦除”,更灵活支持多字幕框、指定时间段的精准擦除。
先通过一段视频体验视频字幕无痕擦除效果:
一、两大技术突破:从"能用"到"优质"的代际跨越
1. 基于 DiT 的视频字幕擦除模型:视频修复的“大模型革新”
视频擦除修复(Video Inpainting)技术旨在移除视频字幕区域并修复背景,需确保修复区域在像素空间和时序维度上均保持稳定与一致。尽管当前主流学术方法(如 ProPainter、DiffuEraser)较早期技术已有显著进步,但在字幕擦除场景下仍面临关键挑战:
未知像素区域修复伪影与幻觉显著:基于 GAN 或 UNet 架构的扩散模型对视频中未出现的像素区域进行“脑补”时,常产生不真实的伪影或内容扭曲(幻觉),且时间稳定性差。生成内容的真实性和时序稳定性不足。
已知像素区域修复模糊问题突出:传统方案依赖光流、前后向传播等帧间特征融合手段,本质为平滑处理,易导致修复区域模糊。
辅助先验依赖制约性能:需输入光流(Optical Flow)、文本提示(Text Prompt)等先验信息,不仅增加计算开销,且光流精度直接限制修复上限。
笔画级精细修复能力薄弱:常规训练基于随机掩码(Random Mask),对字幕这类需要像素级精准处理的场景适配性不足,导致笔画边缘修复效果粗糙。
针对上述问题,我们设计了基于 DiT 的视频字幕擦除修复创新型模型架构。其核心点有:
1.1 强鲁棒性预训练基底
本模型基于 DiT 架构,在大规模数据上进行了预训练,对二次元、现代、古装、奇幻等多种风格的短剧内容展现出强大的泛化能力。尤其在图像未知区域的生成上,其内容的合理性与真实性大幅领先于传统方案。
1.2 摆脱辅助先验依赖
Transformer 自注意力机制驱动时序连贯:与传统的光流计算与特征前后向传播不同,火山引擎视频点播通过 Transformer 捕捉视频序列的长距离时间依赖,直接学习帧与帧之间的时间依赖信息,使得生成的相邻帧在内容、动作、物体位置等方面保持了合理的连贯性。
MMDiT 架构轻量化改造:移除文生视频任务中必需的 Text Prompt 与 Cross-Attention 模块,并通过大量实验验证,在字幕修复场景中,该调整既不降低生成质量,又能大幅减少计算量,避免因文本描述不准确导致的内容幻觉问题。
轻量化主体架构如下:
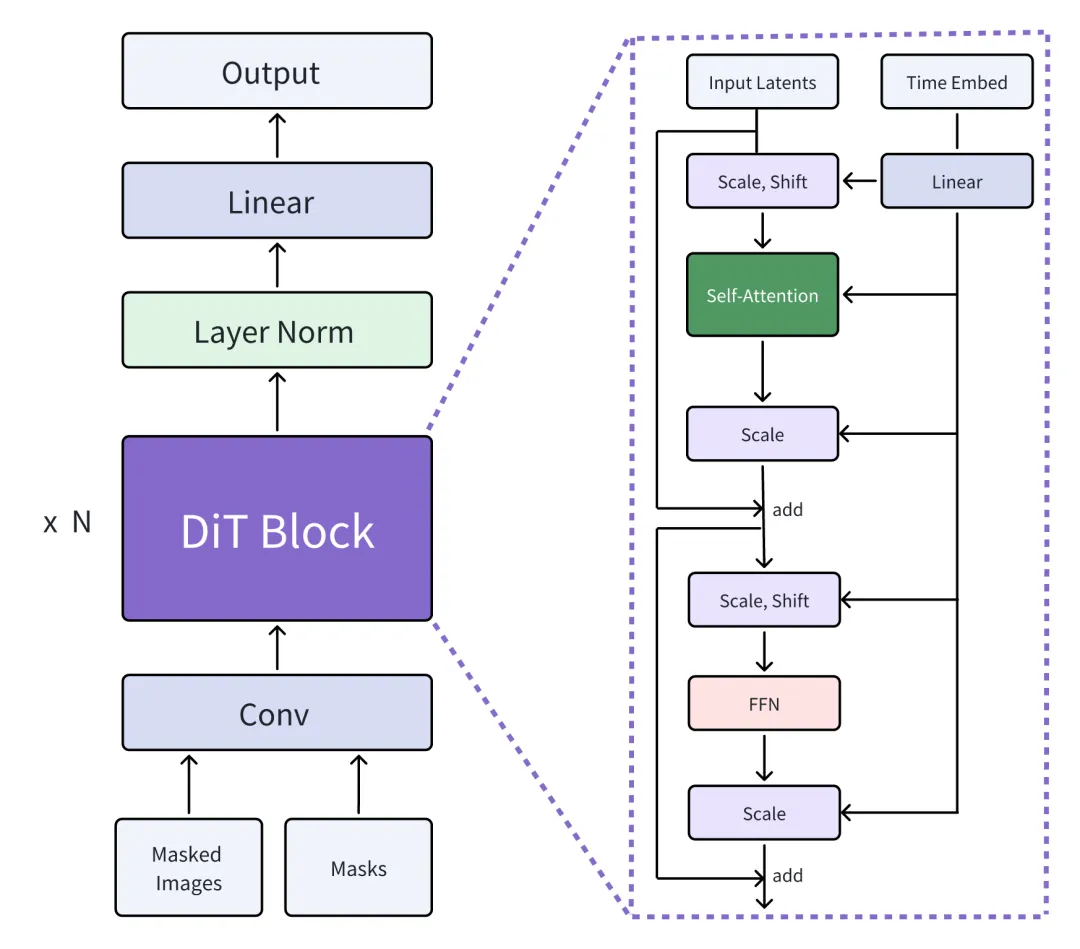
基于 DiT 的视频擦除修复创新型模型架构
1.3 两阶段训练策略提升鲁棒性与修复精细度
由于原始视频生成模型不具备修复能力,且模型已移除 Cross-Attention 模块,我们采用两阶段渐进式训练框架,通过分阶段优化实现性能提升:
基于 DiT 架构的模型以大模型底层能力重构视频修复逻辑,实现“像素级无痕”修复,无论是对手、脸等人体部位,还是衣物纹理、栅格等复杂结构,均能做到无痕擦除与修复,画面整体 PSNR 达 38 以上,推动视频编辑从传统算法迈向大模型驱动的智能系统。
擦除在首饰区域上的字幕,完美还原首饰的纹理,在动态场景下表现依然稳定

擦除覆盖在衣服上的字幕,呈现与背景一致的质感与图案

擦除覆盖在衣服上的字幕,裙子和方巾的图案贴近原片

2. 字体级分割模型:从“粗放擦除”到“像素级修复”
字幕擦除前需要精准定位目标区域。通常来说,擦除区域越大,修复范围越大,越容易产生伪影、模糊等问题,实现无痕修复的难度随之显著增加。当前主流技术多依赖 OCR 检测框进行整体覆盖(如下图),但这种方式存在明显局限:一方面,它忽略了字体间距与字符内部空隙,导致不必要的修复面积扩大,既增加技术难度与耗时;另一方面,字体空隙中关键的指导性像素信息被丢失,严重制约了修复效果的上限。

基于 OCR 检测框进行整体擦除的分割方案

基于 OCR 检测框进行整体擦除的分割方案
要实现字体级的精细分割仍面临诸多挑战,其中最突出的两点在于:
字体样式的复杂性:视频字幕可能包含宋体、黑体、手写体等多字体混合排版,同时存在阴影、描边、渐变等复杂样式,还可能带有滚动、淡入淡出等动态效果,或涉及中英双语叠加等多语言混排场景。
背景干扰问题:部分字幕与背景颜色、纹理高度相似,例如白色字幕叠加在浅色背景上,或存在半透明效果,进一步增加分割难度。
针对上述挑战,我们从数据构建和模型架构两方面进行了针对性设计:
数据层面:为提升分割算法的鲁棒性,确保对不同样式字体的精细处理,我们收集了 2000+常见字体库,借助像素级 2D 图形渲染库 Skia 生成了 20 万+训练数据,全面覆盖中英双语、多字体类型及阴影描边等复杂样式。
模型架构:考虑到字体领域的特殊性,例如部分字体笔画纤细、结构稀疏等,我们设计了 CNN 与 Transformer 融合的分割模型。其中 CNN 部分借鉴了 OCR 检测网络的结构,并采用相关预训练模型进行初始化,以增强对文字特征的捕捉能力。
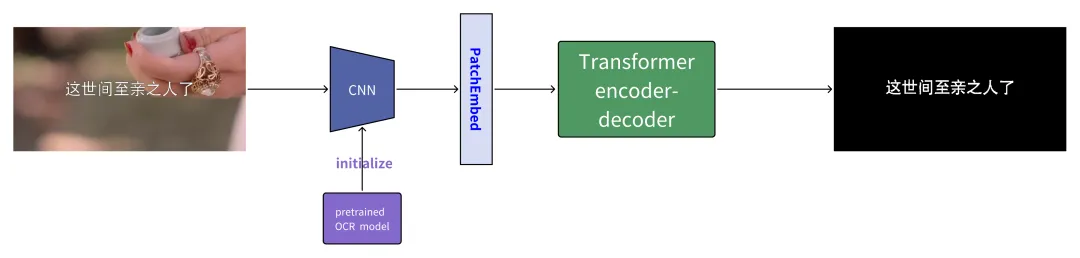
字体级分割模型架构
通过上述技术手段,字体级分割模型可助力擦除补全模型实现对单个字符的独立背景填充,有效避免了传统块填充导致的背景模糊或纹理重复问题。该技术以像素级精度平衡了字幕移除与背景保护,推动视频字幕擦除从“能用”迈向“优质”阶段。
鞋部上的字幕可通过精细分割,保留图案轮廓的完整性,避免修复后出现“马赛克”

衣服配饰上的精美花纹可通过精细分割,保留更多参考像素,提升后续的修复质量

二、工程实力与全球化方案:高效驱动多语言内容流转
在工程层面,火山引擎多媒体实验室联合工程团队构建了兼顾精度与效率的技术体系:
万集测试,稳定如磐:经过超万集视频数据集验证,擦除任务成功率 100%,支持跨境电商批量处理千支商品视频、影视公司高效修复百集短剧,全程稳定;
分镜处理+集群高并发,速度飞跃:创新视频分镜技术,结合服务器集群分布式计算,视频越长处理效率提升越显著——1 小时视频处理耗时较传统方案压缩 50%以上,彻底终结 “漫长等待”。
在多语言支持上,方案突破了中英文限制,支持处理多个小语种字幕擦除,既能助力中国短剧出海移除中文字幕,也能为海外视频进入国内提供小语种字幕擦除服务,双向打通全球内容流转。
火山引擎视频点播形成了“擦除-翻译-口型同步”的一站式闭环:集成英文、日文、西班牙语等多种语言翻译能力,针对短剧场景优化俚语与文化语境适配,结合语音韵律与面部动作分析技术,实现翻译字幕与人物口型的动态对齐,较传统人工流程效率提升 20 倍,一键完成从原视频到多语言本地化内容的全流程处理。
三、尾话
当字幕不再是跨语言传播的障碍,当修复后的画面以卓越品质呈现,火山引擎正用技术消弭视觉隔阂,让每一个精心打磨的镜头,都能在全球观众眼中绽放原有的光彩,让出海内容创作更简单,传播更高效。
立即访问 [火山引擎视频点播官网],感受“像素级无痕”的震撼效果。
火山引擎视频点播官网:




