
作者 | 王硕
策划 | 华卫
1.背景与问题
平台审核场景介绍
在我们运营的内容审核业务平台中,用户生成内容(UGC)是核心。用户在分享经验、发表评论或创建内容时,常常会在文本中附带网址,用于引用资料、分享资源或进行推广。这些网址极大地丰富了内容的生态,但同时也带来了一系列潜在的安全风险。
核心痛点
我们的主要挑战在于,部分用户会利用网址传播非法或不当内容。这些内容通常涉及色情、赌博、暴力、诈骗等,不仅严重违反了平台规定,也对用户,尤其是未成年用户的网络安全构成了直接威胁。
审核挑战
传统的审核方法在面对这些恶意网址时,显得力不从心,主要体现在以下几个方面:
● 文本层面的伪装: 恶意行为者经常使用大量伪装域名或短链接,这些域名从文本上看与普通网址无异,但最终都指向同一个或同一类非法站点。单纯依靠文本黑名单,覆盖范围有限,且容易被绕过。
● 跳转与嵌套规避:为了规避自动化检测,许多恶意网站会采用多次跳转或使用 iframe 跨域嵌套的方式来加载最终的非法内容。传统的爬虫可能只能抓取到入口页面的信息,而无法触达其真实的内容载体。
● 成本与效率的矛盾:如果将所有网址都交由人工审核,无疑会耗费巨大的人力成本,并且审核效率低下,无法满足平台海量内容的实时性要求。因此,如何在保证检测准确率的前提下,最大化地提升自动化效率,是我们需要解决的核心问题。
为了应对这些挑战,我们设计并实践了一套结合了文本匹配、图像向量检索和多模态大模型辅助的综合性恶意网址识别方案。
2.总体方案设计
思路概览
我们的核心思路是构建一个“由快到慢、由简到繁”的多层过滤漏斗。整个检测流程遵循“文本库快速匹配→动态抓取与截图相似度检测→ LLM 多模态辅助提示→人工审核确认”的路径。
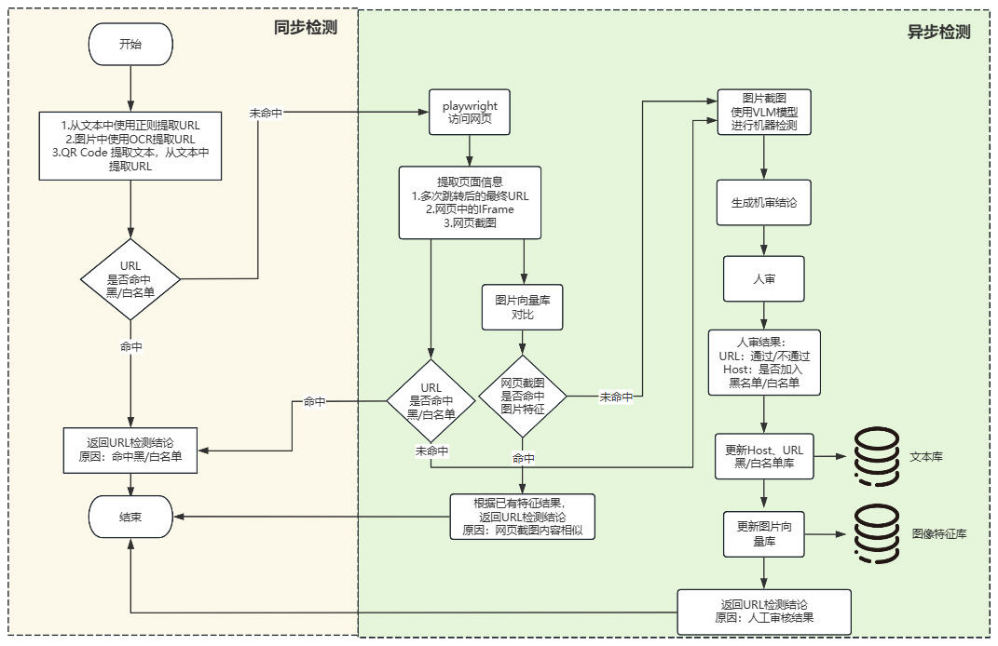
方案目标
本方案旨在实现以下几个关键目标:
1. 提升准确率:有效识别通过域名伪装、跳转、iframe 嵌套等手段隐藏的恶意网址。
2. 提升自动化效率:通过多层自动化检测,过滤掉绝大部分无风险或已知的恶意网址,将人工审核的压力降到最低。
3. 构建反馈闭环:将人工审核的结果反哺到自动化检测库中,使系统具备自我进化和持续学习的能力。
核心组件
为了实现这一目标,我们的系统由以下几个核心组件构成:
● 文本网址检测结果库:一个高效的键值存储系统,用于存放已知网址的黑白名单。白名单用于快速放行(如知名、可信的网站),黑名单则用于直接拦截。
● 截图特征向量库:基于 Milvus 构建,用于存储海量网页截图的特征向量。它能够实现毫秒级的相似图片检索,是识别同质化非法网站的关键。
● 网页动态抓取与跟踪模块:使用 Playwright 实现。它能模拟真实用户访问网页,精准跟踪 301/302 跳转,并解析页面中的 iframe 结构,获取最真实的页面截图和最终地址。
● 多模态大语言模型(LLM):作为辅助判断工具。当自动化规则无法明确判定时,调用多模态 LLM,结合网址和截图信息,生成一份参考性的安全提示,供人工审核员参考。
3.技术实现步骤
3.1 从用户上传信息中提取网址
这是所有流程的入口。我们使用正则表达式从用户上传的信息中提取所有符合规范的 URL。我们的正则表达式经过精心设计,能够兼容多种格式,包括:
● 用户上传的二维码图片。
● 用户上传的文本
● 用户上传图片内容进行 OCR 提取
● 使用大语言模型从用户上传的视频截图中提取
● 使用 Whisper 等模型从音频中提取文本,获取 URL
3.2 文本库快速匹配
提取出网址后,第一步是进行最高效的文本匹配。
1.将 URL 直接查询检测历史,如果当前 URL 曾经检查过,则直接返回历史结果。
2.从 URL 中提取 Host,直接从主域名下手,在文本网址库检测,Host 是否命中 白名单(如 baidu.com, weibo.com 等)黑名单。如果命中,则判定为相应结果,检测流程终止。其中,Host 的白名单可以快速过滤掉大量常见网站。
3.如果网址在库中不存在,则进入下一步的动态抓取环节
3.3 动态访问与抓取
对于未命中本地库的未知网址,我们需要深入其内部一探究竟。这里我们选择使用 Playwright,因为它具有强大的浏览器自动化能力。
● 启动浏览器实例:在一个隔离的环境(如 Docker 容器)中启动一个无头浏览器实例。
● 访问与跟踪:使用 Playwright 打开原始网址,并监听网络请求。通过捕获 HTTP 状态码(301, 302)或页面重定向事件,我们可以准确记录下最终跳转的 URL 地址。
● 提取 iframe 链接:页面加载完成后,我们解析 DOM 树,提取所有 iframe 标签的 src 属性,这些是潜在的内容嵌套地址。
● 截取页面截图:在所有内容(包括 iframe)加载完成后,对当前视口进行完整截图,生成一张最能代表该网址内容的图片。
部分代码如下
1.@app.get("/screenshot_resolve")2.async def screenshot_resolve(url: str = Query(..., description="目标网站 URL")):3. try:4. async with async_playwright() as p:5. browser = await p.chromium.launch(headless=True)6. page = await browser.new_page()7. try:8. await page.goto(url, timeout=10*1000, wait_until="networkidle")9. except Exception as e:10. print("goto failed:", e)11.12. # 获取最终跳转后的 URL13. final_url = page.url14.15. # 获取 iframe 的 URL 列表16. iframe_urls = [frame.url for frame in page.frames if frame.url and frame.url != final_url]17.18. # 截图(转 base64,放到 JSON 返回)19. img_bytes = await page.screenshot(full_page=True, type="jpeg", quality=80,20. timeout=10*1000)21. img_base64 = base64.b64encode(img_bytes).decode("utf-8")22.23. await browser.close()24.25. return {26. "final_url": final_url,27. "iframe_urls": iframe_urls,28. "screenshot": img_base6429. }30.31. except Exception as e:32. return JSONResponse(content={"error": str(e)}, status_code=500)这一步至关重要,它帮助我们穿透了伪装域名和跳转欺骗的迷雾,获取了最核心的三个信息:最终跳转地址、iframe 地址、页面截图。
3.4 再次进行文本检测
在获取到最终跳转地址和 iframe 地址后,我们并不会立即进入复杂的图像检测。而是利用这些新获取的文本信息,再次查询我们的文本网址检测结果库。
● 查询逻辑:将最终跳转地址和所有 iframe 地址,逐一查询文本库。
● 命中逻辑:只要其中任意一个地址命中了黑/白名单,就直接返回相应的结果。黑名单优先级更高。
这一步是文本检测的补充,旨在处理“不同入口,相同归宿”的场景,进一步提升了文本库的利用效率。
3.5 截图相似度检测
如果经过两轮文本检测后,网址依然无法被定性,我们就启用基于视觉的检测手段。
● 生成特征向量:首先,我们将上一步获取的网页截图输入到一个预训练的 Vision Transformer (ViT) 模型中,生成一个高维的特征向量。ViT 模型在捕捉图像全局特征方面表现出色,非常适合网页这种结构化场景。
● 存入与检索 Milvus:
○ 检索:我们将新生成的特征向量放入 Milvus 中,执行相似度检索。我们使用 L2 距离 作为相似度度量,并设置一个非常严格的阈值(如 0.1)。如果找到了一个或多个 L2 距离小于 0.1 的历史向量,我们认为这张新截图与历史截图在内容和布局上高度相似。
○ 判定: 一旦发现相似图片,系统会直接采用历史截图所对应的审核结果(可能是“通过”,也可能是“违规”),并将该结果返回。
○ 未命中:如果没有找到相似图片,则说明这是一个全新的、前所未见的网页样式,需要进入下一环节。
3.6 多模态 LLM 提示
当一个网址通过了所有自动化检测规则,但系统依然无法判定其安全性时,我们引入多模态 LLM 作为人工审核前的“军师”。
● 输入:我们将原始网址、最终跳转地址和网页截图一同输入给多模态 LLM。
● Prompt 设计:我们设计的 Prompt 会引导模型从“内容安全”的角度进行分析,例如:“请分析这个网页截图和网址,判断它是否可能包含色情、暴力、赌博等不良内容,并给出你的理由。”
● 作用:LLM 的输出不作为最终结论,而是作为一条重要的“辅助提示”展示给人工审核员。例如,它可能会提示“该页面包含大量真人图片和挑逗性文字,建议关注色情风险”,从而帮助审核员快速聚焦问题。
3.7 人工审核与库更新
自动化流程的最后一道防线是人工审核。审核员会看到所有自动化流程收集到的信息:原始网址、跳转路径、截图、LLM 提示等。
● 人工审核:审核员基于所有信息,做出最终的“通过”、“违规”或“白名单”判定。
● 审核结果更新:这个最终结果是整个系统实现自我进化的关键。
○ 如果判定为“违规”,系统会将原始网址、最终跳转地址、iframe 地址全部更新到文本网址检测结果库(黑名单)中。同时,将截图的特征向量及其“违规”标签存入截图特征向量库。
○ 如果判定为“通过”,则更新当前网址 URL 的文本、图像特征结果。同时,由审核人员认定当前 Host 是否可以加入到白名单。
● 形成反馈闭环:通过这一步,每一次人工审核都在为自动化系统贡献新的知识。下次再遇到相同的网址、或指向同类内容的网址、或页面布局相似的网站时,系统就有可能在前面的自动化环节直接将其识别出来。
4.技术选型与实现细节
● Milvus:选择 Milvus 是因为它专为海量特征向量的相似性搜索而设计,支持多种索引类型和距离度量,能够提供高并发、低延迟的查询性能,完美契合我们的需求。
● ViT 模型:我们选用通用的 ViT 预训练模型,因为它对图像的全局和局部特征都有很好的捕捉能力,无需针对网页截图场景进行复杂的微调即可获得不错的效果。
● Playwright:相比于其他工具,Playwright 对现代网页技术的支持更好,API 友好,运行稳定,能够可靠地处理复杂的页面加载、JavaScript 渲染和反爬虫机制。
5.效果与收益
● 检测准确率大幅提升:通过动态抓取和视觉检测,有效解决了传统文本匹配无法应对的域名伪装和跳转欺骗问题。
● 自动化程度显著提高:此功能上线后,线上 99.36%网址请求能够被自动化流程处理,无需人工介入。
● 审核成本显著降低:人工审核团队的压力得到极大释放,他们只需聚焦于少数自动化无法判定的边界情况和新型恶意网站。
● 检测能力持续迭代:随着人工审核数据的不断回流,文本库和向量库的覆盖面越来越广,系统的检测能力形成了一个“越用越准”的良性循环。
6.总结与展望
本方案通过整合文本匹配、浏览器自动化、向量检索和多模态大模型,成功构建了一套能够有效应对复杂恶意网址威胁的纵深防御体系。它解决了在审核实践中遇到的文本伪装、跳转欺骗和多模态内容识别等多个核心难点。
展望未来,我们还可以在以下几个方面进行优化:
● 增加 OCR 能力:我们现在使用通用 OCR 模型对图片进行文本识别,针对一些由艺术字、表情符号组成的网址识别效果不好,后续我们将针对这类图片微调一个识别能力更强的专向 OCR 模型,提升网址识别准确率。
● 提升 LLM 的深度应用:探索专门针对网页截图语义进行微调的 LLM 模型,使其不仅能提供提示,甚至能在某些场景下直接给出更准确的判定结论。
● 优化审核效率:针对待审网址,优化推送给审核人员审核的算法。例如:优先审核重复次数多的,LLM 模型判定危险的网址,缩短系统从“未知”到“已知”的学习周期。
我们相信,随着技术的不断演进,人机协同的审核模式将变得更加智能和高效,为构建清朗的网络空间提供更坚实的技术保障。




