
演讲嘉宾|李锐
策划|QCon 全球软件开发大会
近年来,大前端技术领域呈现出迭代速度加快、功能复杂度和业务耦合度增加的特点,加之快手亿级 DAU 的用户规模和超长使用时长,面临着多种技术栈并存、高资源占用的挑战,性能稳定性风险持续增大。传统的性能稳定性排障工具使用门槛高,依赖领域专家多年积累的深度知识和隐性经验判断。那么,AI 是否是破解有限的人力和无限的复杂问题之间矛盾的答案? 本文整理自快手移动端稳定性负责人李锐在 2025 年 QCon 全球软件开发大会(上海站) 的分享“AI x 大前端性能稳定性:快手亿级 DAU 下的智能诊断实践”。重点分享在大前端性能稳定性保障中,如何借助快手「柯南 AI」 赋能,实现性能稳定性问题排障经验平民化,显著提升诊断效率。
预告:将于 4 月 16 - 18 召开的 QCon 北京站设计了「下一代交互架构:LUI 与 GUI 的融合」专题,将探讨如何在复杂系统中平衡自由输入与结构化操作,构建高效、可控的新一代人机交互范式。敬请关注。
以下是演讲实录(经 InfoQ 进行不改变原意的编辑整理)。
最近,AI 赛道的“卷”已从国内蔓延到硅谷:“996” 乃至 “007” 的传闻不绝于耳;ACM 总决赛冠军被大模型摘下;IMO 金牌水平的自动编码能力,也足以让大多数程序员自叹弗如。如果 AI 既能写代码又能自动完成调试,是否就形成了一个自我迭代的闭环,把“人”彻底挤出了开发流程? 热度之下,我更想冷静地思考下,在快手这样体量的复杂业务里,从性能稳定性视角来看看 AI 到底能走多远。今天,我就以亲历者的身份,聊聊我们团队在“AI x 性能稳定性”上的思考和构建「柯南 AI」平台躺过的那些坑。
我 2019 年加入快手,此后一直负责稳定性领域的建设。个人偏好钻研系统底层原理,折腾过不少“硬核”技术,也是快手移动端第一个开源项目 KOOM 的作者。接下来的分享分五部分:先回答“为什么”和“怎么做”,再聚焦两个关键场景,最后谈谈认知和感受。
快⼿性能稳定性背景
我把自己在快手经历的稳定性演进,粗略地划成四个阶段。回头去看,每一阶段都站在上一阶段的肩膀:最早自研 APM,接着把逐个零散工具沉淀成 APM 平台,再基于平台做问题治理,最后是体系化的稳定性故障防御。节奏与移动互联网技术浪潮同频——从移动互联网红利期到存量用户竞争期,性能和稳定性被重新定义为用户的体验带来的公司竞争优势,再到今天的 AI 浪潮时代。
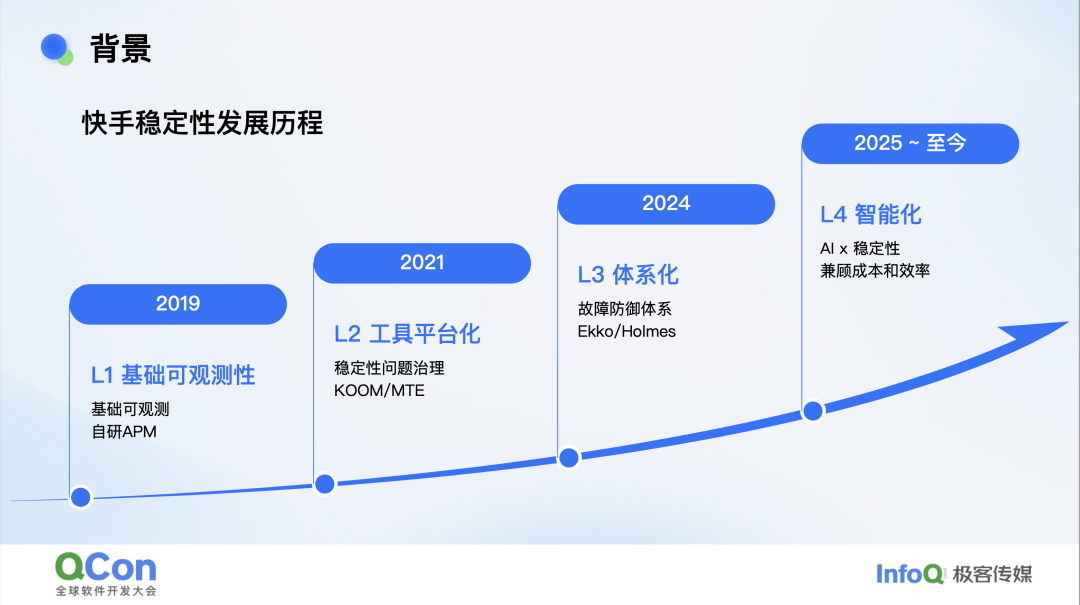
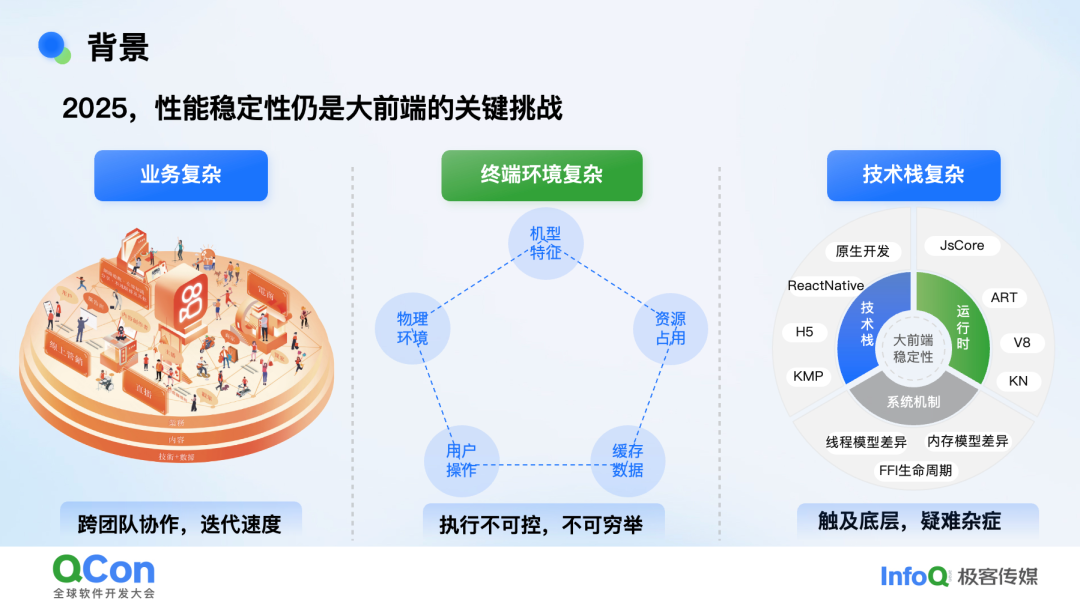
大前端的性能稳定性议题已伴随移动互联网十余年。硬件层面,iPhone 的算力较初代已提升百倍;软件层面,QCon、GMTC 年年设专场。可问题真的被完全扫清了吗? 并没有。上半年 QCon 的主题叫“越挫越勇的大前端”,下半年又变成“AI 与跨端的高效融合”——主题本身就在暗示:复杂度并未消解,我们仍在受挫,效率依旧不足。若用算法复杂度打比方,过去十年我们面对的场景和其解决算法本身并未升级,且复杂度还因鸿蒙等新变量持续膨胀水涨船高,输入规模也增加了。因此,我们确实面临不小的挑战。
AI x 性能稳定性介绍
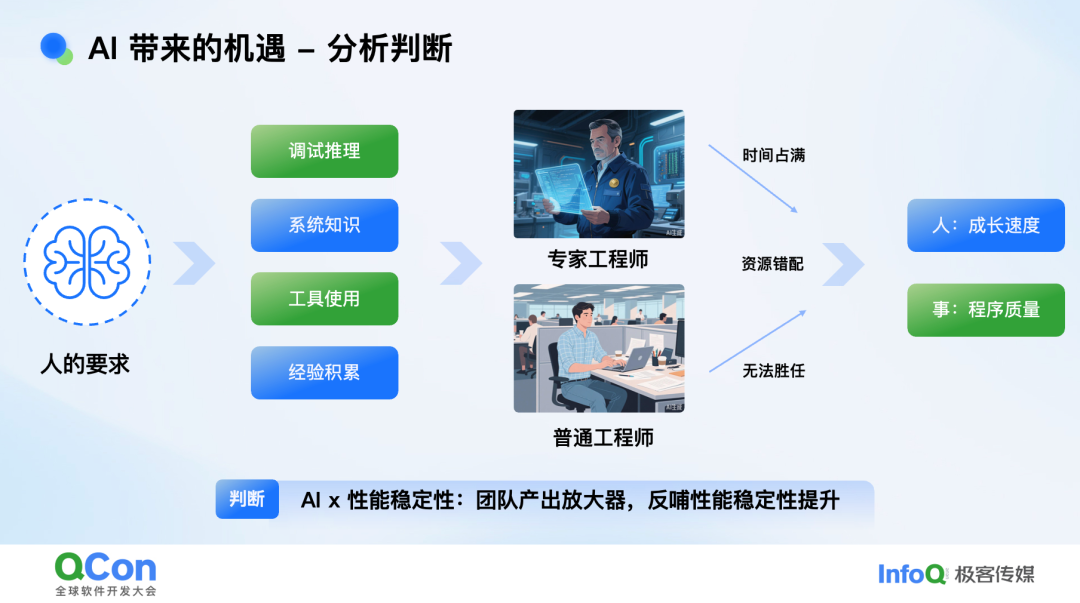
那么 AI 能否破局?先从人的角度谈下我的思考,在诸位的团队中是否发现存在一个现象:团队里总 有些 Bug 只有特定“老专家”能解,新人插不上手,得不到锻炼;专家又持续被这些 bug 缠身,没法释放出人力做更有价值的事情,进而导致恶性循环质量下滑。 从这个角度出发,在性能稳定性领域,我最初的思考:AI 定位首先不是取代谁,而是成为团队产出放大器,把“专家经验”转化为组织能力。
要让放大器不失真,得先搭好稳定的“电路”。我们稳定性体系本就分阶段演进,每一阶段都是下一阶段的底座;AI 也必须长在这套体系之上再去改造这套体系,否则就是无源之水、无本之木。 但是,稳定性横跨技术、流程、运营几十个小域,AI 该从哪切入?
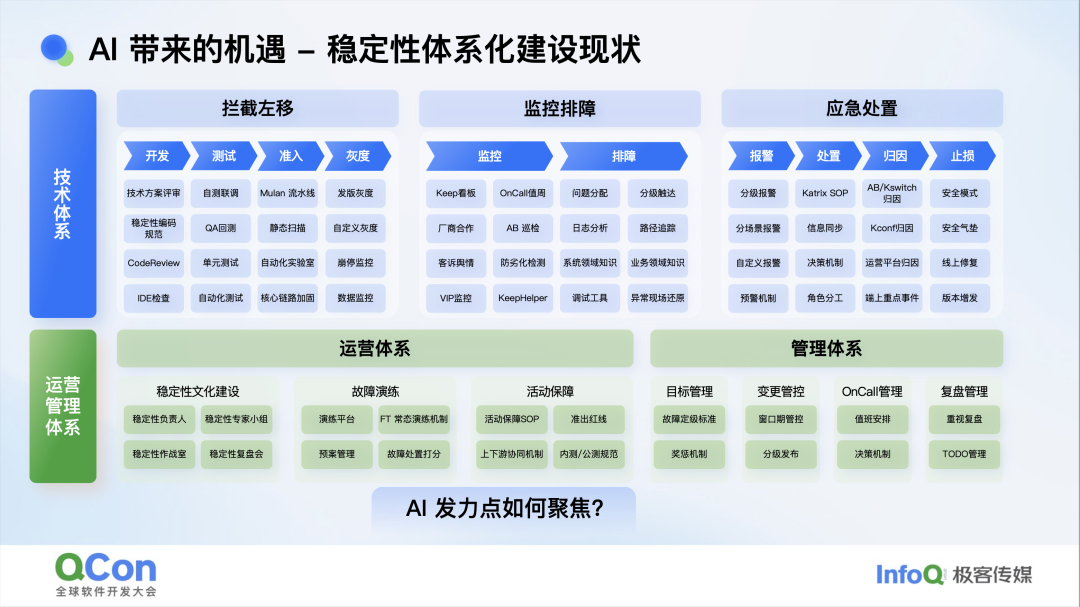
内部多轮推演后,我们锁定“问题处置”——它最吃研发时间,也最影响用户体验,且能弥补人在排障时处置时的盲区(研究表明人脑同时做多处理四个变量)。 具体拆成两条线:根因处置与应急止血;根因里又分疑难与简单两类,恰好与大模型的推理、检索、生成能力相呼应。

我们自顶向下设计了一套可扩展的 Agent 架构,搭建了「柯南 AI」平台。业务目标明确:把根因定位与应急响应做得更快、更准。产品形态先以内部 IM 机器人落地,支持问题根因排查建议 和 MR 自动修复;再逐步演进为嵌入 IDE、Coding Agent 、内部排障平台多轮会话。技术选型上,Agent 框架我们的发展经历了两个阶段:从 AutoGen 到基于 OpenAI Agent SDK 原语自研 Agent 框架,支持图编排、多种模式策略,也能接入和各 CLI Agent 结合。 基建层分两头:AI 侧按场景选模型——简单任务用轻量模型,推理密集型上强模型,多模态场景再叠加视觉能力;同时把推进内部平台 MCP 化演进,让工具随调随用。服务端同样关键:系统必须可观测、可调试、可压测,还要提前算清成本,避免规模上去后失控。

实践:AI 辅助根因排障
前面谈了“为什么”与“怎么做”,接下来我想用一次真实案例回答“我们到底做了什么”。案例是一枚被内部戏称为“五星 NPE”的异常。乍看只是空指针,加个判空似乎就能了事;可它偏偏只在大型活动爆发,且堆栈里只剩系统帧,连崩溃触发源头都无处寻觅。 把日志丢给 ChatGPT、Claude 或 DeepSeek,它们同样抓瞎,因为上下文太少,推理链断裂。那么,通过我们的工具链能定位出问题根因吗?

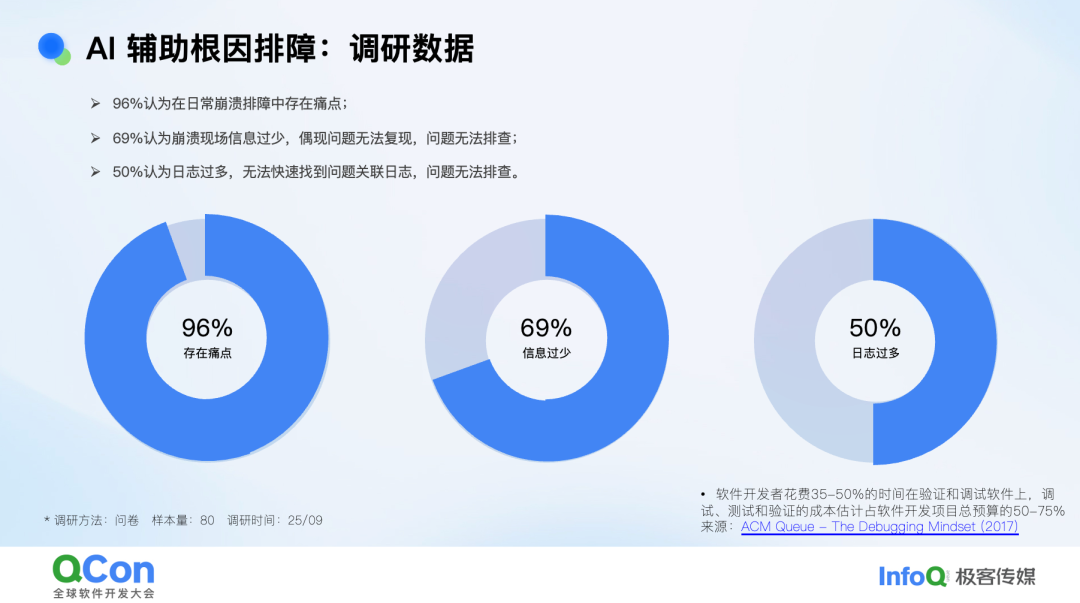
在动手之前,我们先对研发同学做了一次摸底:96 % 的人承认线上排障痛苦,却又在不出事时抱怨日志太多,出事后嫌日志太少。刚刚前面友商的演讲可以看到,工程师 60 % 的时间花在修 Bug 上;我查到的 ACM Queue 报道数据也落在 30 %–50 % 区间。两相映照,可见“写代码易,排障难”并非个例。
近来,行业里 Linus 那句“Talk is cheap, show me the code” 被广为流传在 AI 时代变为了 “Code is cheap, show me the talk” ,但我想说的是:“Code is cheap, debug is expensive—show me the fix。” 写出能跑的代码只需几分钟,但要交付工业级、零缺陷的版本,仍然需要一套能把“昂贵排障”降本增效的体系,这正是我们接下来要展开的内容。

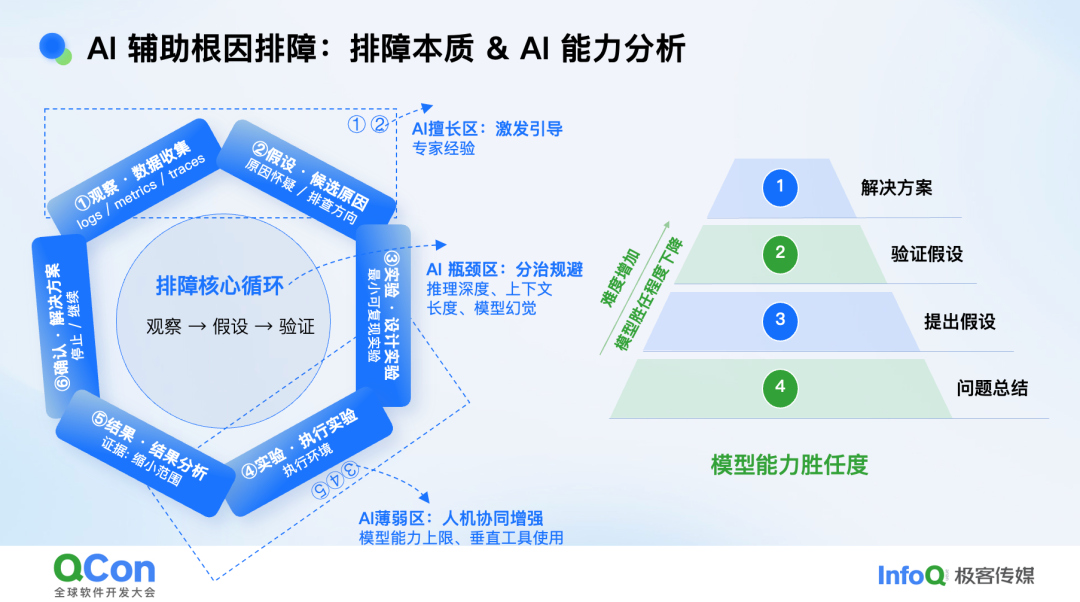
为什么修一个 Bug 会如此耗时?我把这些年的踩坑经历抽象成一句话:排障本质上是一场科学推理实验,本质上是演绎推理、归纳推理、溯因推理、类比推理等推理方法论的组合。 我发现 MIT 有一门课也持同样观点——先观察现象、收集数据,再提出假设,用排除法迭代,直到去伪存真。AI 能否胜任这场实验?基于此思路,我把它拆成“摸高”与“短板”两条线。
我们再来思考,目前 AI 的推理能力有多大程度能解决排障的问题。AI 的长板显而易见:总结日志快、联想模式多、见过的异常广。只要通过 Agent 策略或提示词稍加引导,它就能把碎片化信息迅速拼成一张“线索图”。然而,一旦触及天花板,它就会碰壁:私域代码、内部工具链、超长推理链,都是它的盲区。最棘手的是“深度 Bug”,触发条件多、路径长,需要连续十几步推理,模型往往在中途失焦。
我们给 AI 建了一套四级胜任度评估体系: 最底层是“问题总结”,几乎百发百中;往上是“提出假设”,准确率开始下降;再往上是“验证假设”,需要人工补位多论会话;顶层是“给出可落地方案”,直接把问题进行修复,目前只能当辅助解决简单问题。先把标尺立起来,再持续往里填数据、调策略,才能看清 AI 到底站在哪一级台阶,下一步该往哪迈,并据此评估体系,伴随着模型能力的提升,持续观测迭代 AI x 稳定性的能力。
把排障比作破案,是我这些年最贴切的感受:都要在零散线索里还原动机,再锁定真凶。想做出一个实践中切实有效的稳定性 Agent,开发者自己得先是一名老侦探——见过千奇百怪的案发现场,才能把经验沉淀成规则。最难的 Bug 就像“完美犯罪”,现场干净得连指纹都没有;前面提到的“五星 NPE”便是如此,只剩一条光秃秃的系统堆栈,几乎没有任何可供推理的痕迹,缺少上下文 AI 也会巧妇难为无米之炊。
为了在这种“零线索”场景里也能破案,我们内部做了一套叫 Holmes 的工具。 它把传统手段拆成“静态”与“动态”两条线:静态侧是日志、Coredump、内存转储这些“尸体报告”;动态侧则是调试器、Profiler 这类“让程序再死一次”的利器。老程序员偏爱调试器,正是因为它能一步步重演死亡过程,把瞬间定格成连续画面。
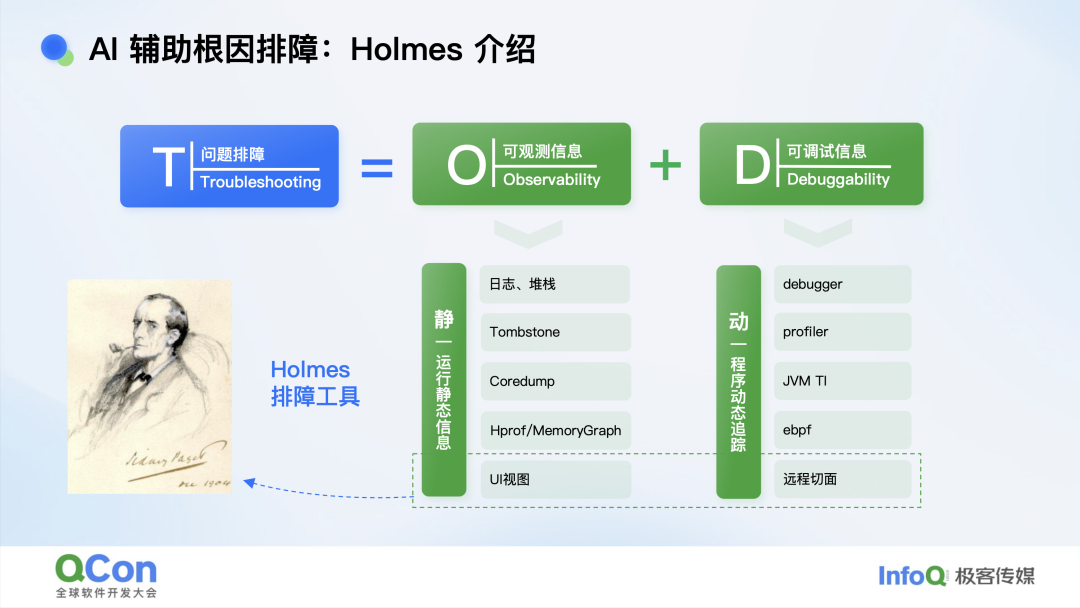
Holmes 的思路是在两条线上同时做延伸:静态侧,我们将日志与转储映射为可视化 UI;动态侧,则通过远程热插桩实时采集运行时数据。
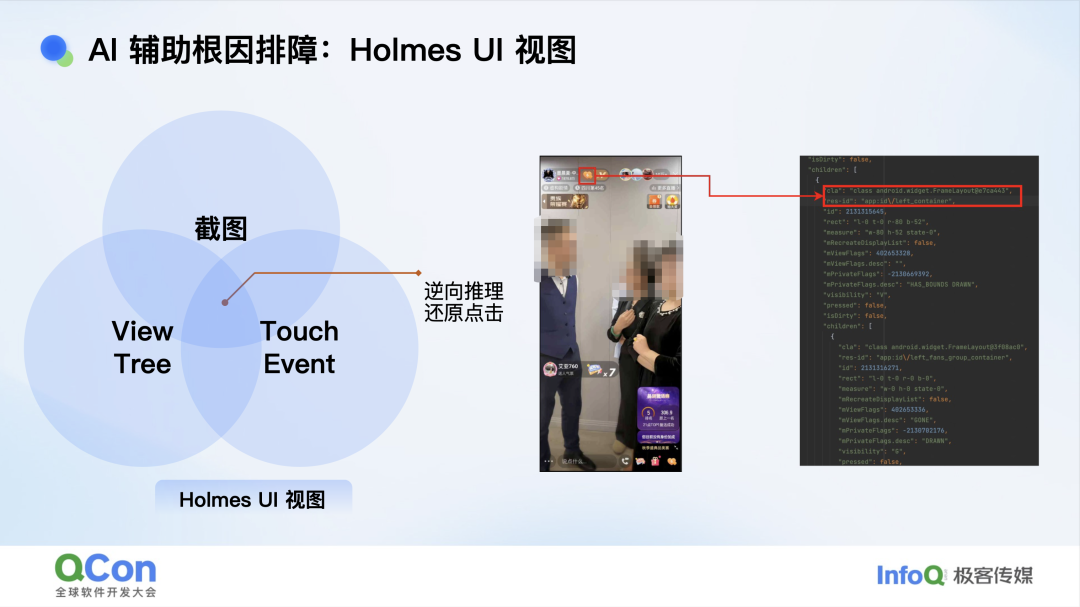
今天我想重点说说 UI 视图在排障中的实际价值。移动端程序以 GUI 交互为主,bug 中天然有很大占比是来源于 UI 视图相关的问题,复杂应用遇到的 UI 视图难题通常是组合式问题,需要跨越应用层直达系统框架层。 我们曾遇到一类极难定位的崩溃:只有一张截图、一份 ViewTree 和一串点击事件。把这三样拼在一起,就能还原用户到底点了哪个按钮、触发了哪段逻辑,从而把“毫无关联”的系统堆栈翻译成“按钮 A 崩溃”。别小看这一步,它让研发立刻联想到最近的 MR 和需求,排障时间从小时级缩到分钟级。
具体落地时,Holmes 的 UI 视图采集必须“刚刚好”:信息不能多也不能少,多了干扰判断,少了缺关键线索;同时要对系统 UI 框架足够熟悉,才能在不显著损耗性能的前提下,把 View 层级、布局参数、事件链路一次性抓全。
第一次看采集结果的人常被密密麻麻的参数吓到。确实,只有写工具的同学才记得住每个字段含义。这又回到老问题:工具越复杂,会用的人越少,资源再次错配。
AI 时代给了我们打破循环的机会。我们沿用了前面提到的 Agent 框架:先让大模型把版本、系统、堆栈等基础信息做一轮预处理;再用 专家沉淀的经验规则让大模型把问题分桶,每个桶对应响应的问题分析 Agent(作者注:AI 发展很快,2026 最新架构已在 Skill 方向发展,但思想一致)**,例如 UI 视图 Agent 会读取 Holmes 采集的数据并结合源码,用 ReAct 策略不断自问“是否需要进一步工具”“是否已定位根因”,在限定轮次内给出结论;若超时仍未解决,则标记失败并交由人工兜底。如此,复杂参数被 Agent 自动消化,研发只需关注“哪个按钮崩了”,工具终于从“个人绝技”变成“团队标配”。
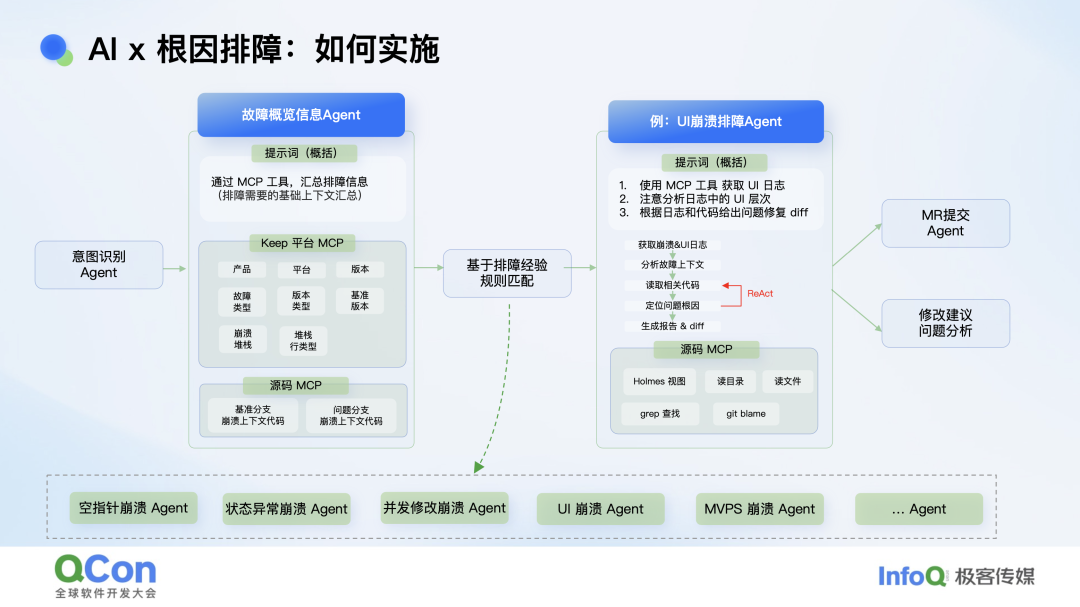
看起来顺理成章,是吧?先粗判问题,再分类,最后给出源码。但真正动手做过 Agent 的人都知道,大模型的幻觉远比想象严重,且每一步都伴随概率衰减:一步 80 %,两步就只剩 64 %。工业级场景要求接近 100 %,于是工程细节被放大成决定性因素。
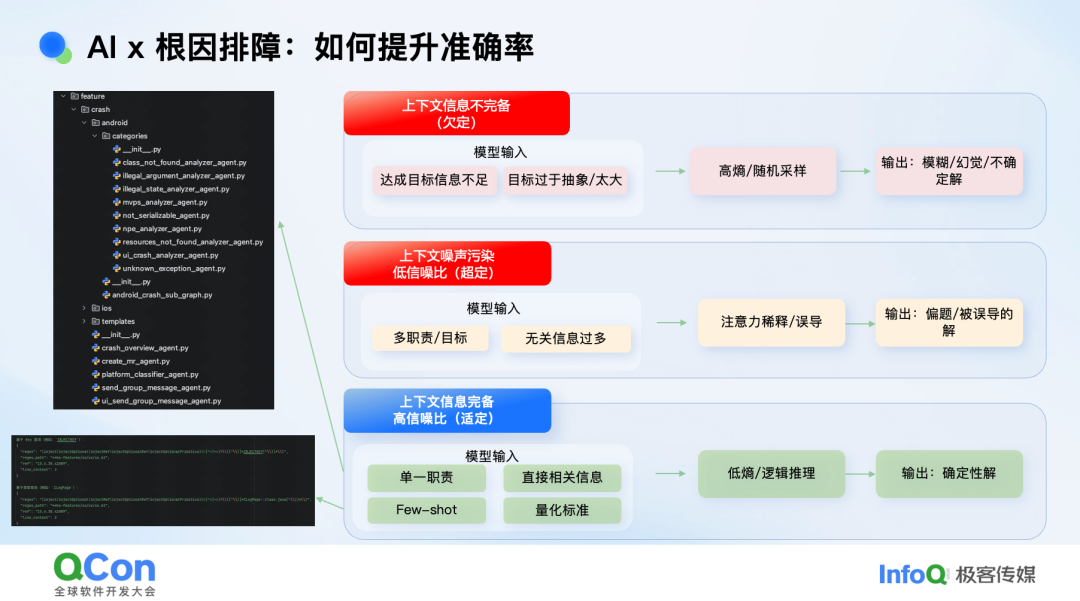
在上下文工程上,我们踩的坑可以归为两类。第一类是信息不足,目标过于宏大:直接让模型“分析一下这次崩溃”,效果往往稀碎。第二类是信息过载,职责边界模糊,模型反而迷失。用数学语言讲,前者是“欠定”,后者是“超定”,我们要的是“适定”:不多不少,刚好足够。为此,我们把问题拆成若干单一职责的 Agent,每个 Agent 的提示词都经过精心裁剪,并通过 few-shot 示例教会它如何调用私域工具。最终呈现的效果是:系统先给出根因推测,再列出排查方向。若问题简单,可直接生成 MR,一键采纳;若问题复杂,研发可沿线索继续深挖。
前面谈的多是崩溃类场景。在“动”的另一侧,Profiler 负责性能问题。最广为人知的便是火焰图。细究名字,它源于十多年前 Netflix 工程师 Brendan Gregg 用 Perf 工具生成的可视化:调用栈越高,火焰越旺,瓶颈一目了然。如今,火焰图已“名不副实”——Android 的 Perfetto 不再仅仅画火焰,而是把 CPU、内存、调度、应用事件(atrace)与内核追踪(ftrace)全部塞进一张图。十几秒的采集即可产出 60 MB 数据:采样太短,信号不足;采样稍长,数据便膨胀到难以处理。 复杂问题需要复杂工具,复杂工具又带来复杂用法,而场景本身还在持续膨胀。
过去我们面对性能问题时,通常的做法是:先花时间去学习火焰图工具的使用,再在图中来回拖拽、放大缩小,逐层定位瓶颈。这一步对工程师的底层知识要求极高,完成后才能正式进入分析阶段:查看历史案例、比对相似问题,整个链路长、门槛高、效率低,还容易遗漏关键线索,这些正是 AI 可以发力的痛点。
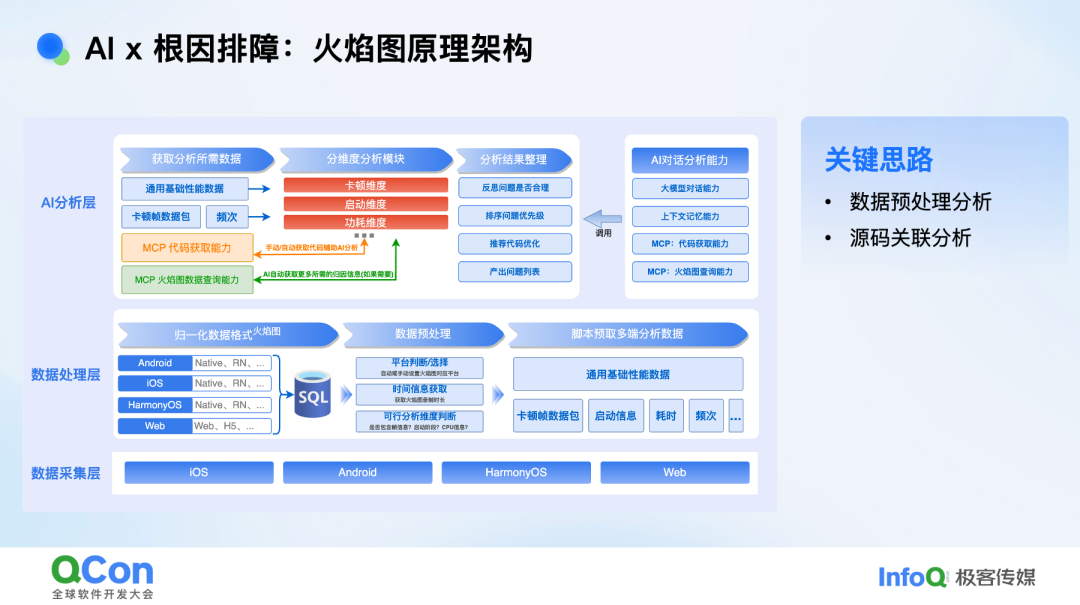
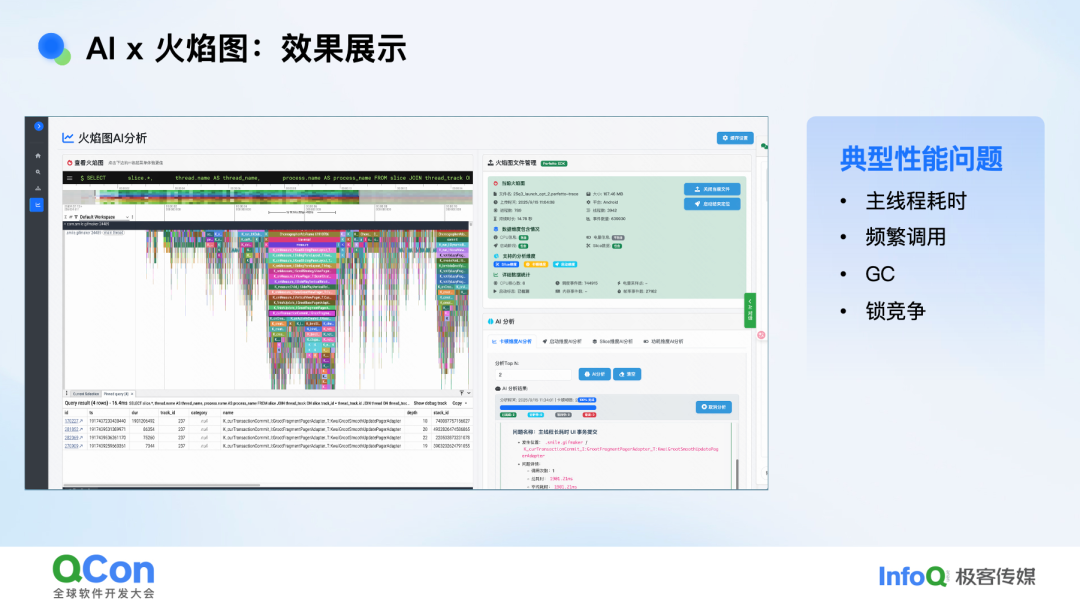
我们给出的火焰图方案依旧沿用“专家经验前置”的思路:做 AI 火焰图排障的人,首先得是一位能熟练解读火焰图的性能专家。方案的核心在于数据预处理算法,如何把 60 MB 的原始火焰图压缩成可供模型高效消费的上下文,并与源码、trace 事件精准关联,从而完成粗筛,然后再又后续的处理环节按需加载必要信息进行分析。最终,火焰图分析结果按四种维度呈现:卡顿、启动、Slice 与自定义查询。系统直接给出结论,并指出对应源码位置,支持一键跳转;无需再像过去那样手动拖拽寻找瓶颈,排障路径被大幅缩短。
实践:AI 加速应急处置
接下来我想谈谈应急故障处置。它的核心只有一个字:急。
先说一个真实案例。iOS 26 升级后,苹果再次引入兼容性变动——25 年后仍在修改 Objective-C Runtime,并在文档里“善意”提醒:此处会崩(作者注:详见《iOS 26 你的 property 崩了吗?》)。结果,快手线上仍在运行的上百个历史版本,在升级 iOS 26 后瞬间集体崩溃。只有真正经历过的人,才体会得到那种痛:版本多、用户广,止损无从下手。我们盘点现有手段,有以下三种:
应用商店更新——一周覆盖率 50%,剩下 50% 的用户必崩一次;
变更回滚——这次是苹果改动,无法让苹果回滚;
于是,我们问自己:有没有一种工具,能在崩溃发生的瞬间直接“兜底”,像《英雄联盟》里的 Ekko 开大招——时光倒流,让程序回到正常状态?我们内部也把这个工具命名为 Ekko。它的思路很朴素:无论异常由谁引入、因何触发,先跳过错误,保证用户不崩。当然,实现起来并不简单。
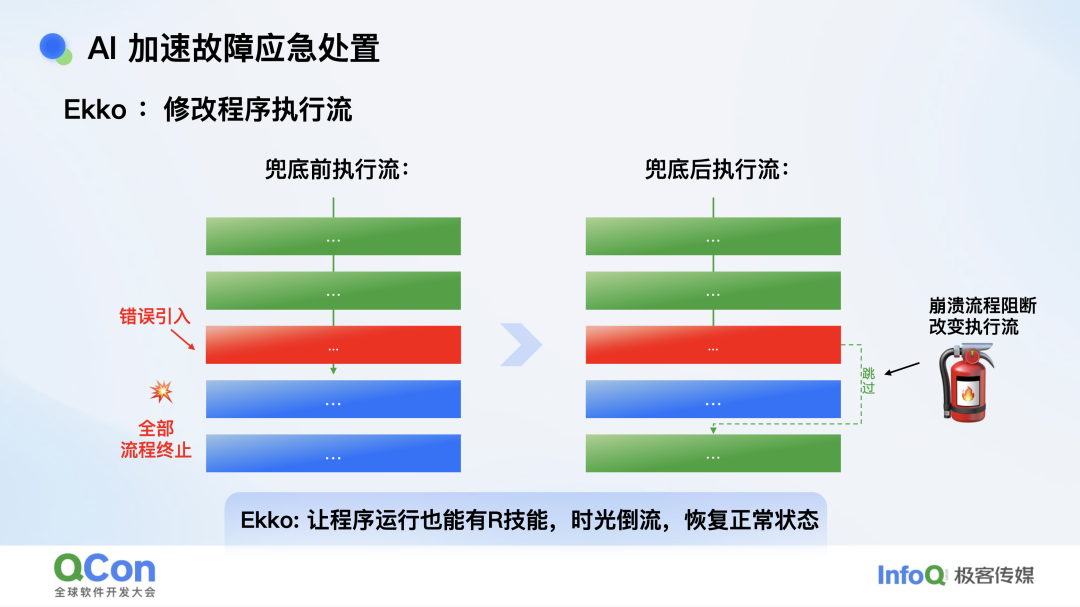
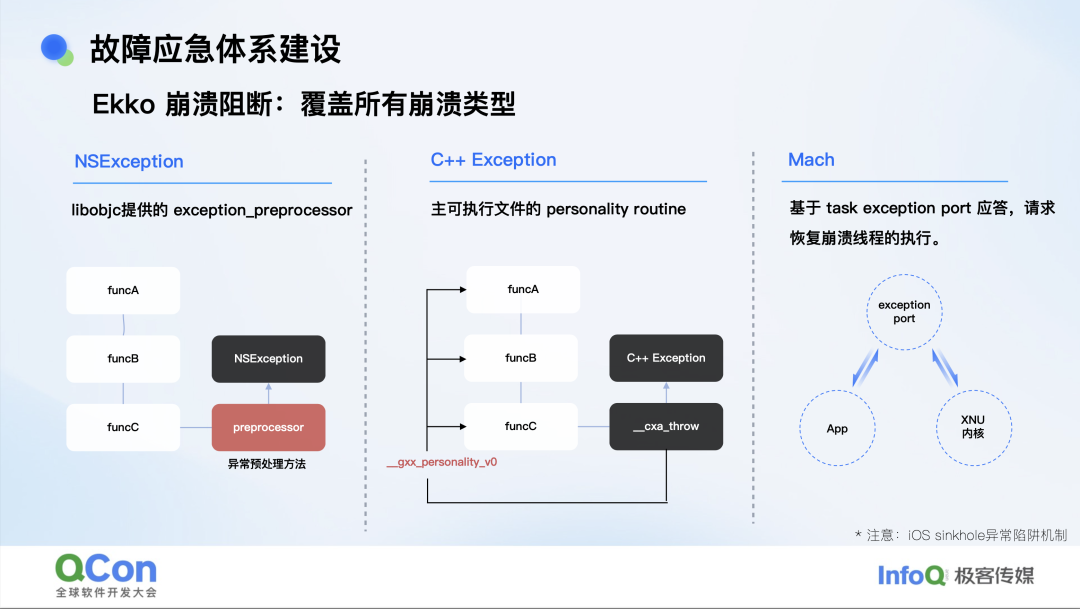
行业里曾有一种前置 Hook 方案,但它必须在异常发生前就介入,对所有用户生效,哪怕他们从未崩溃,Ekko 规避了这个缺点。Ekko 与行业方案的最大区别,在于它是“事后”的:只有当用户真正崩溃时,才进入兜底流程,从而把对正常用户的干扰降到零。 这听起来简单,实现却层层递进。以 NSException 为例,我们注册 exception_preprocessor;C++ 异常则要 hook personality routine;Mach 异常还得与内核通信,难度逐级升高。
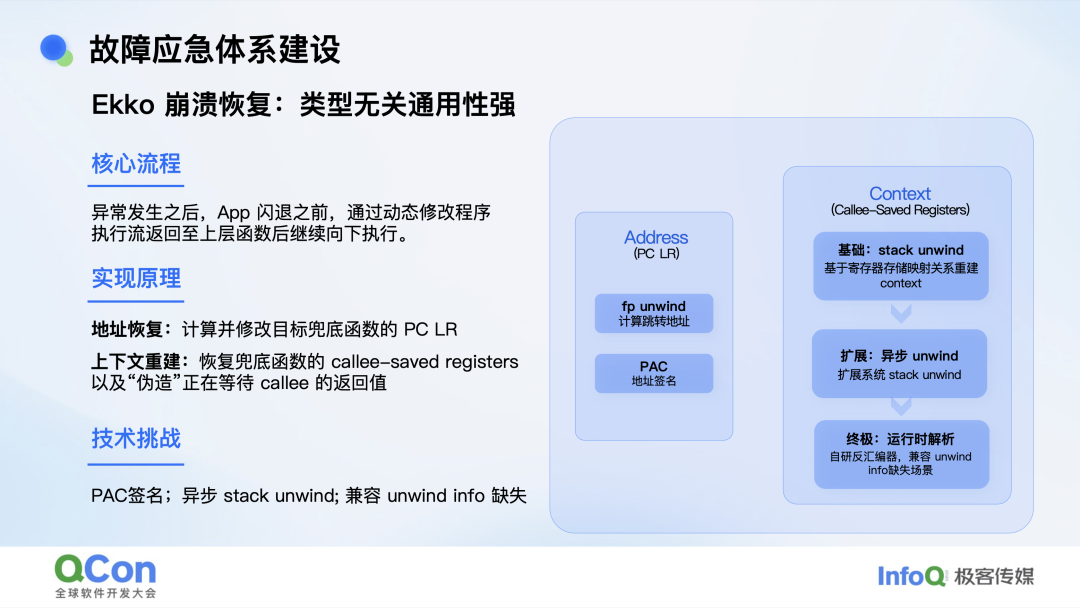
崩溃被捕获后,执行流已被打断,必须精确恢复现场:指令地址、寄存器、栈帧、局部变量,一个都不能错。我们的方案也经历了多次迭代:1.0 版基于常规栈回溯,遇到 Mach 异常就束手无策;2.0 版引入异步 unwind,又碰上因包体积优化而被裁剪的 unwind info 带来的兼容性问题;最终,我们干脆自研反汇编器,把控制权完全握在自己手里。
工具虽强,落地仍难。配置跳转指令、恢复上下文等步骤依旧繁琐,只能由少数专家操作。一旦线上告警,专家不在场,风险便陡增。于是我们把 AI 接进来:由 Agent 自动分析崩溃现场,生成兜底配置,并给出影响范围与推荐参数,既降低门槛,也减少人为失误。
再讲一个故事。我不知道大家历史上见过多大的事故,我见过的是千万级崩溃,而且只发生在半小时内。起初只是一个小崩溃,一小时才崩一两百次;大家在处理时做了一个善意的止损——把弹气泡功能关掉,以为这样就能止血。没想到“关掉气泡”这个动作本身的问题根因原理一致,结果崩溃量从几百次瞬间涨到几十万次。这件事给我们最大的教训是:故障处置里依赖人做判断非常不靠谱。人在高压下会紧张、肾上腺素飙升,很容易漏掉关键信息。
于是我们把 AI 引入进来。它不会紧张,也能把历次操作都总结下来,并提供处置建议,发展至终局阶段甚至能够自动处置。做法还是基于前面说的 Agent 架构:故障来了先分析,给出建议结论;如果判断需要兜底,就调用兜底工具生成配置并发布。
直接看效果。第一,Checklist:你现在很紧张,就按我们处理了一年几百次报警总结出的步骤一条条列出来给处置建议,防止遗漏。第二,问题总结:崩溃上报字段有 100 多个维度,人眼看肯定漏。很多问题其实有维度特征,比如展示图里提示“Android 35、高通芯片”等限定条件,有了这些信息,第一步定界就很快。第三,在给出维度后,继续提供源码级分析,并推送可能的修复方向,省去人工翻查。

总结展望
接下来想说说我们在开发 Agent 过程中的真实体感,也算一次认知升级。首先是一次思维切换。写传统程序时,我们默认“图灵机”式的确定性:输入固定,输出必达。但大模型需要概率思维,若仍以确定性思维调试,只会徒增烦恼。只有先摸清楚它擅长什么、薄弱在哪、天花板多高,才能决定哪里用 AI、哪里留硬代码,省下大量返工时间。
其次,要识别瓶颈并主动拆解。提示词工程本身并不能提高模型本身的上限,因为模型权重并未改变;但一份精心设计的提示词能把模型已有的能力充分激发出来,这需要专家多年隐性知识与直觉释放模型能力的天花板。模型单次推理深度有限,也需要基于专家经验,把复杂问题切成可管理的子部分,并尽可能的完善公司内部各个系统的数据打通串联。与此同时,评测体系必须同步建立:AI + 稳定性的能力是个螺旋上升的过程,传统程序只耗时间,AI 还耗 Token,烧钱速度倒逼我们把评估做得像上下文工程一样严谨。
回到最初的问题:AI 会不会把人替代?我倾向听听“祖师爷”的声音。Linus Torvalds 被问到“是否已有 LLM 代码未经请求就提交给你”时,回答干脆:“肯定发生了,而且规模还会扩大。”在他看来,工具演进从未停歇:机器码 → 汇编 → C → Rust,如今只是又多了一层 AI。代码审查与维护同样如此,Linus 希望 AI 能先帮他抓“那些显而易见的蠢 bug”,毕竟连他自己也免不了犯低级错误。
面对主持人试图把话题引向“AI 会取代程序员”的负面预设,Linus 并未接茬,反而强调:自动化工具历来只是人类能力的延伸,从机器码到汇编再到高级语言,每一次演进都让开发者走得更远;AI 也不例外——真正决定价值的,始终是我们如何驾驭它。

当下 AI 话题很热,越在热潮越要冷静。我们认为,体力型的排障动作终将被自动化,但人类需要更高阶的能力:提出正确问题、识别模型幻觉、在恰当时机介入。俗话说 AI 一天人间一年,AI 发展非常快,伴随着模型能力的提升,我们也会把流程从 “human-in-the-loop” 向 “human-on-the-loop” 延伸发展。面向 AI Native 时代,一切才刚刚起航。
演讲嘉宾介绍
李锐,快手移动端稳定性负责人。2019 年加入快手,主导了发版拦截、监控报警、排障工具、止损工具、应急处置多个领域的建设,现为移动端稳定性方向负责人。个人擅长移动操作系统、虚拟机、编译器等底层基础技术,现在探索 AI+ 性能稳定性方向,KOOM 开源项目作者。




