
当地时间 5 月 10 日,英特尔举办了 2022 英特尔 On 产业创新峰会。在此次峰会上,英特尔公布了其在芯片、软件和服务方面取得的多项进展,并宣布了包括第 12 代英特尔酷睿 HX 处理器家族、阿波罗计划、Greco AI 加速芯片在内的一系列重大发布。
英特尔 CEO 帕特·基辛格在峰会上表示:“全球市场正处于最具活力的时代。企业目前面临的挑战错综复杂且相互关联,而成功的关键取决于企业快速采用和最大化利用领先技术和基础设施的能力。在当下复杂的环境中,英特尔将展示如何运用规模、资源、芯片、软件及服务,帮助客户及合作伙伴加速数字化转型。”
宣布多项重大发布
人工智能、无所不在的计算、无处不在的连接、从云到边缘的基础设施——这四大超级技术力量,正驱动着世界对半导体的空前需求,开启无限可能,实现从真正的混合算力环境到全新的沉浸式体验。与此同时,企业在供应链、安全、可持续性,以及对全新复杂工作负载的适应能力等方面,面临着与日俱增的压力。英特尔正致力于通过从云到边缘到客户端引入全新的硬件、软件和服务,来帮助用户解决这一系列挑战。
推出全新第 12 代英特尔酷睿 HX 处理器家族
为了更快地迭代内容,为专业人士和创作者提供更强大的处理能力和更高的平台带宽,英特尔宣布推出全新第 12 代英特尔酷睿 HX 处理器,完善了第 12 代酷睿产品家族。值得一提的是,英特尔酷睿 i9-12900HX 处理器最多拥有 16 个核心和高达 5GHz 的时钟频率。
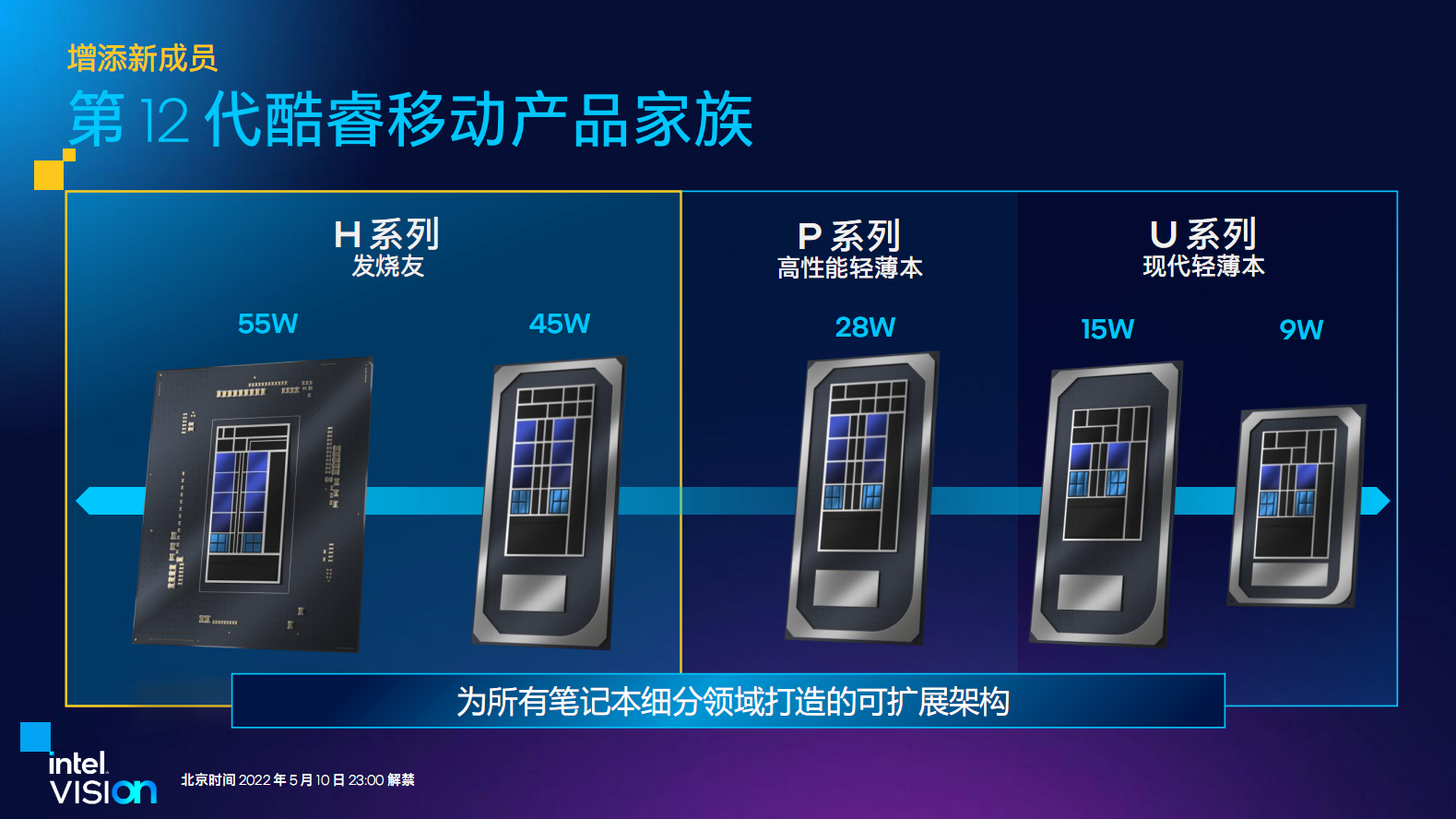
据英特尔方面称,第 12 代英特尔酷睿 HX 处理器,通过更多的核心数、更大内存和 I/O 支持,把多线程工作负载的性能提升 64%,同时借助英特尔硬件线程调度器来充分释放性能核和能效核蕴含的迅猛性能,让专业人士可以在办公室、家中或旅途中以超高效率进行创作、编程、渲染和工作。除了作为工作的得力助手,第 12 代酷睿 HX 处理器还是游戏平台强者,为骨灰级游戏玩家以更高帧率畅玩熟知且喜爱的游戏。
第 12 代英特尔酷睿 HX 处理器家族在创新的移动设备中,能够提供满足生产力、协作、内容创建、游戏和娱乐体验等方面的真实场景应用需求,其特性包括:
最多 16 核心(8 个性能核和 8 个能效核)和 24 线程,处理器基础功率为 55W;
16 条处理器直连 PCIe Gen 5.0 通道,和 4x4 专用平台控制器集线器(PCH)的 PCIe Gen 4.0 通道,增加了带宽并加快了数据传输速度;
业界率先全线未锁频和可超频处理器;
支持高达 128GB 的 DDR5/LPDDR5(高达 4800MHz/5200MHz)和 DDR4 内存(高达 3200MHz/LPDDR4 4267MHz),支持纠错码(ECC)功能;
采用英特尔 Wi-Fi 6/6E(Gig+),实现更好的连接性能,并支持全新的 6GHz 频段。
戴尔、惠普、联想等众多 OEM 厂商,预计将在今年推出 10 余款搭载第 12 代英特尔酷睿 HX 处理器的工作站和游戏设备。
发布两款 AI 处理器新品:Gaudi2、Greco
在此次峰会上,英特尔不仅公布了在酷睿 HX 处理器家族上取得的最新进展,其 Habana Labs 团队也宣布推出两款 AI 处理器新品:第二代 Gaudi 深度学习训练处理器——Gaudi2 和 Goya 深度学习推理处理器的后续产品——Greco。
对于数据中心客户而言,由于数据集和人工智能业务的规模和复杂性日益增长,训练深度学习模型所需的时间和成本越来越高。Gaudi2 旨在为云和本地客户带来更高的深度学习性能和效率,及更好的选择。
为提高模型的准确性和实时性,用户需要更频繁地进行训练。根据IDC的数据,在 2020 年接受调查的机器学习从业者中,有 74%的人对其模型进行过 5-10 次迭代训练,超过 50%需要每周或更频繁地重建模型, 26%的人则每天甚至每小时会重建模型。56% 的受访者认为培训成本是阻碍其组织利用人工智能解决问题,创新和增强终端客户体验的首要因素。基于此,第一代 Gaudi 和 Gaudi2 在内的 Gaudi 平台解决方案应运而生。
英特尔表示,相对于其上一代产品和市场上的同类型产品而言,这些处理器提供了显著的加速。Habana 的客户现在可以使用 Gaudi2 处理器,而 Greco 将在今年下半年开始为选定的客户提供样品。
Habana Labs 成立于 2016 年,旨在打造世界级的 AI 处理器,仅仅三年后就被英特尔以 20 亿美元的高价收购。上述第一代 Goya 推理处理器是由 Habana 团队于 2018 年默默推出的产品,而第一代 Gaudi 训练处理器于 2019 年推出,正好在英特尔收购之前。
因此,这些新品的推出标志着英特尔 Habana Labs 完成了一个重要的里程碑时刻:虽然 Gaudi 和 Goya 在过去几年中以各种形式呈现出来,但这些是 Habana Labs 自收购以来发布的第一批新处理器。
Gaudi2 和 Greco (通过两者的制造商台积电)都实现了从 16nm 到 7nm 工艺的飞跃。以 Gaudi2 为例,第一代 Gaudi 训练处理器中的 10 个 Tensor 处理器内核已增加到 24 个,而封装内存容量从 32GB (HBM2) 增加了两倍至 96GB (HBM2E),板载 SRAM 增加了一倍,从 24MB 增加到了 48MB。“这是第一个也是唯一一个集成了如此大量内存的加速器,”Habana Labs 的首席运营官 Eitan Medina 在谈到 Gaudi2 中的 HBM2E 时如是说。
该处理器的 TDP 为 600W(与 Gaudi 的 350W 相比),但是,Medina 表示,其冷却方式仍然使用被动冷却并且不需要液体冷却。
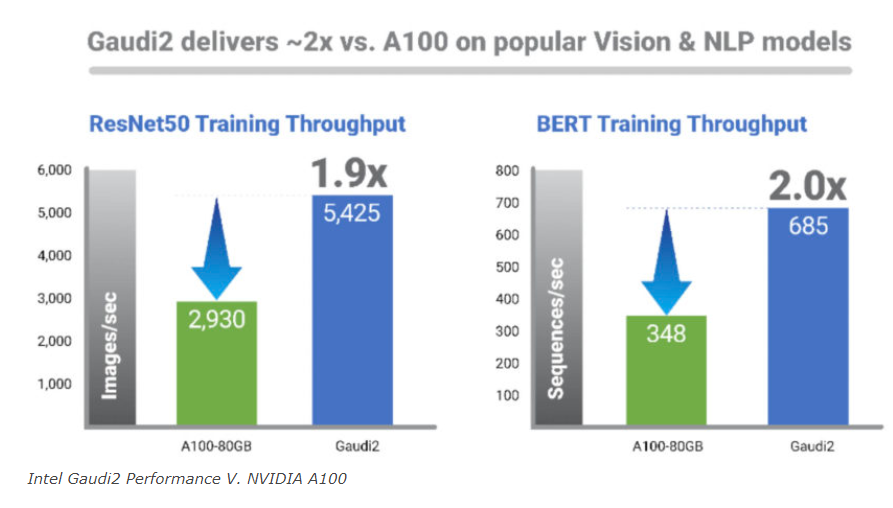
在此次峰会上,Medina 还展示了 Gaudi2 与上一代 Gaudi 和同类型产品在某些热门任务上的性能比较,这让会场气氛呈现出了一波小高潮。
例如,在 ResNet-50 上,Gaudi2 的输出是 Gaudi 的 3.2 倍,是 80GB Nvidia A100 的 1.9 倍,是 Nvidia V100 的 4.1 倍。在其他一些 benchmark 中,Gaudi 和 80GB A100 之间的差距更加明显:对于 BERT Phase-2 训练吞吐量,Gaudi2 比 80GB A100 高出 2.8 倍。“与 V100 和 A100 相比很重要,因为两者实际上都大量用于云和本地,”Medina 解释说。
Gaudi2 现在可供 Habana 客户使用,它以夹层卡形式提供,并作为 HLS-Gaudi2 服务器的一部分,旨在支持客户对 Gaudi2 的评估。该服务器配备了 8 个 Gaudi2 卡和一个双插槽 Intel Xeon 子系统。对于更实质性的部署,Habana 正在与 Supermicro 合作,预计将在 2022 年下半年将配备 Gaudi2 的训练服务器(Supermicro Gaudi2 Training Server)推向市场,并与 DDN 合作开发一种增强 DDN 人工智能的 Gaudi 训练服务器的变体-集中存储。此外,一千个 Gaudi2 已经部署到 Habana 在以色列的数据中心,用于软件优化和推进 Gaudi3 处理器的开发。
第四代至强可扩展处理器 Sapphire Rapids 正式发货
在峰会开幕式上,英特尔公司数据中心与人工智能事业部执行副总裁兼总经理 Sandra Rivera 透露,英特尔面向服务器、数据中心领域的产品被称作至强可扩展处理器——代号为 Sapphire Rapids,正式出货。她表示:“该处理器今天开始发货,它面向现代化的云端的基础设施,能够帮助云服务商高效管理所有的 CPU 内核,提高利用率。”
第四代英特尔至强可扩展处理器提供强大的整体性能,将支持 DDR5、PCIe 5.0 和 CXL 1.1,并凭借全新的集成加速器,通过针对 AI 工作负载的软硬件优化,相较上一代产品实现了性能提升。其次,该产品亦具备针对电信网络的新功能,可以为虚拟无线接入网(vRAN)部署,提供高达两倍的容量增益。此外,内置高带宽内存(HBM)的代号为 Sapphire Rapids 的英特尔至强处理器将显著提高处理器的可用内存带宽,从而为高性能计算提供超级动力。
启动“阿波罗计划”,提供超 30 种开源 AI 解决方案
会上,英特尔还宣布也与埃森哲联手启动“阿波罗计划”,旨在通过为企业提供经过优化设计的超过 30 种开源 AI 解决方案,让其能在本地、云端亦或是边缘环境中都更易于部署 AI。“阿波罗计划”的首批套件预计将在未来几个月内发布。
此外,英特尔还公布了其到 2026 年的 IPU 产品路线图,其中包括基于全新 FPGA 和英特尔架构平台的代号为 Hot Springs Canyon 的产品,Mount Morga(MMG)ASIC,以及下一代 800GB 产品。IPU 是具有强化加速功能的专用产品,旨在满足基础设施计算需求,使企业能够高效处理任务和解决问题。




