
2026 年,智能体将在企业级应用中取得哪些实质性突破?点击下载《2026 年 AI 与数据发展预测》白皮书,获悉专家一手前瞻,抢先拥抱新的工作方式!
在本快速入门指南中,您将利用 Snowflake Cortex 的 AI_TRANSCRIBE 函数,构建一个支持语音交互的 AI 助手。用户可通过录制音频消息,经由系统自动转录并由大语言模型处理,实现智能化、自然的对话体验。
学习目标
使用 Snowflake Cortex 的 AI_TRANSCRIBE 函数实现语音转文本功能;
创建具备适当加密机制的存储阶段,以安全处理音频数据;
将 Streamlit 的音频输入功能与 Snowflake 进行集成;
构建一个支持语音交互的对话式智能助手。
构建内容
您将完成一个具备语音交互能力的聊天机器人应用。用户可录制音频消息,系统将自动完成语音转文本处理,并通过大语言模型生成智能回复,最终实现流畅的语音对话式交互体验。
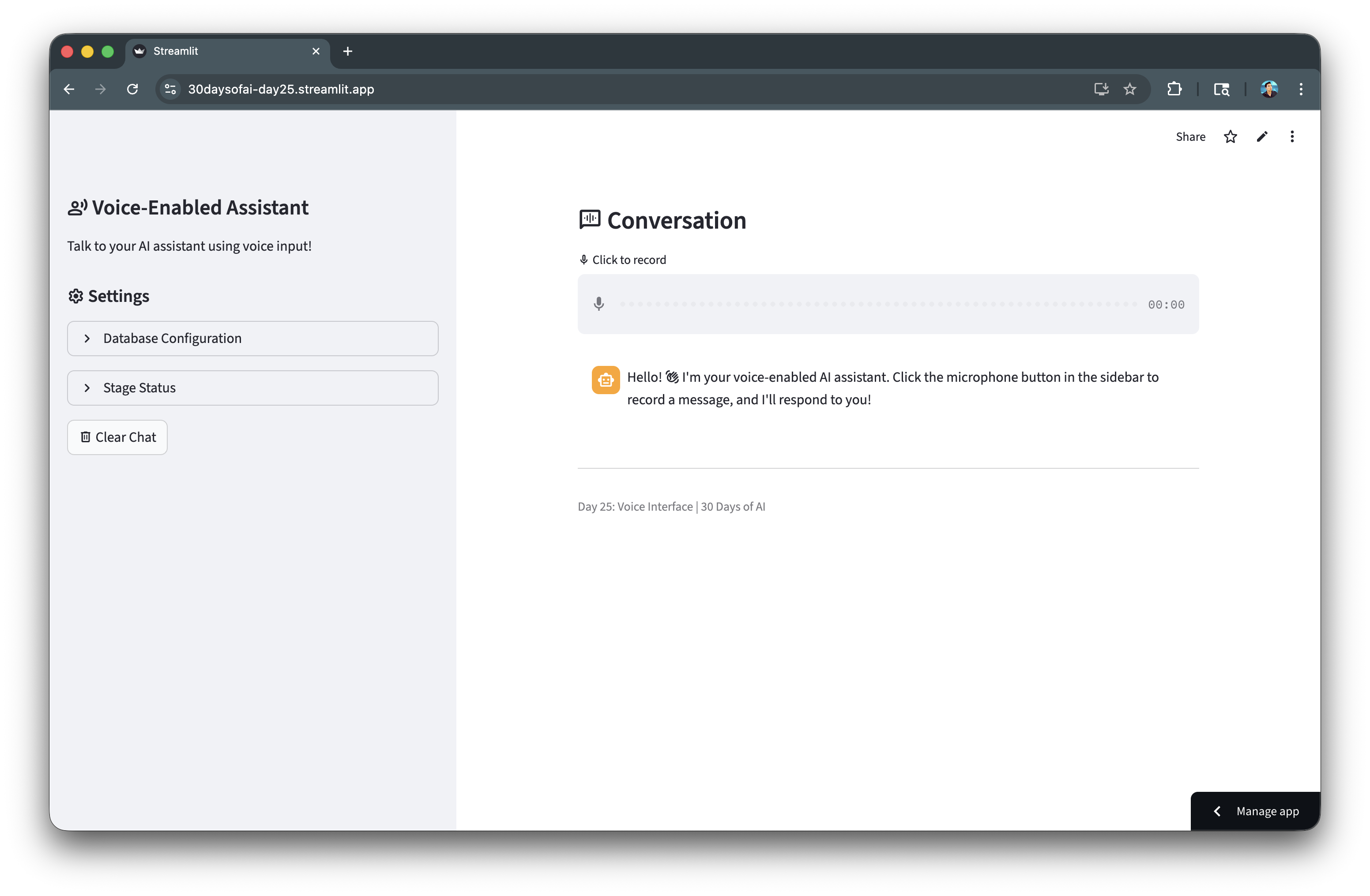
准备要求
具备可用的 Snowflake 账户访问权限;
掌握 Python 及 Streamlit 的基础知识;
拥有使用 Cortex AI_TRANSCRIBE 函数的相应权限。
开始使用
请从 30daysofai GitHub 代码仓库克隆或下载代码:
git clone https://github.com/streamlit/30DaysOfAI.gitcd 30DaysOfAI/app本快速启动对应的应用程序代码:
音频配置阶段
音频转录功能需要配置具有服务端加密的存储阶段。AI_TRANSCRIBE 函数只能访问存储在采用 Snowflake 托管加密(SNOWFLAKE_SSE)的存储阶段中的文件,这种加密方式可确保音频数据在 Snowflake 处理环境中的安全处理。
创建存储阶段
CREATE DATABASE IF NOT EXISTS RAG_DB;CREATE SCHEMA IF NOT EXISTS RAG_DB.RAG_SCHEMA;DROP STAGE IF EXISTS RAG_DB.RAG_SCHEMA.VOICE_AUDIO;CREATE STAGE RAG_DB.RAG_SCHEMA.VOICE_AUDIO DIRECTORY = ( ENABLE = true ) ENCRYPTION = ( TYPE = 'SNOWFLAKE_SSE' );创建采用 SNOWFLAKE_SSE 加密的存储阶段,这是 AI_TRANSCRIBE 访问音频文件的必要条件。
重要提示:存储阶段必须使用 SNOWFLAKE_SSE 加密,AI_TRANSCRIBE 才能访问音频文件。
构建语音界面
连接与状态设置
首先,导入所需库并建立与 Snowflake 的连接。通过 try/except 结构,使应用程序能够在 Snowflake 环境中的 Streamlit 和本地环境中正常运行:
import streamlit as stimport jsonfrom snowflake.snowpark.functions import ai_completeimport ioimport timeimport hashlibtry: from snowflake.snowpark.context import get_active_session session = get_active_session()except: from snowflake.snowpark import Session session = Session.builder.configs(st.secrets["connections"]["snowflake"]).create()def call_llm(prompt_text: str) -> str: df = session.range(1).select( ai_complete(model="claude-3-5-sonnet", prompt=prompt_text).alias("response") ) response_raw = df.collect()[0][0] response_json = json.loads(response_raw) if isinstance(response_json, dict): return response_json.get("choices", [{}])[0].get("messages", "") return str(response_json)if "voice_messages" not in st.session_state: st.session_state.voice_messages = []if len(st.session_state.voice_messages) == 0: st.session_state.voice_messages = [ {"role": "assistant", "content": "Hello! :material/waving_hand: I'm your voice-enabled AI assistant. Click the microphone button to record a message, and I'll respond to you!"} ]if "voice_database" not in st.session_state: st.session_state.voice_database = "RAG_DB" st.session_state.voice_schema = "RAG_SCHEMA"if "processed_audio_id" not in st.session_state: st.session_state.processed_audio_id = None会话状态用于跟踪对话消息、数据库配置以及最近处理音频的哈希值。该哈希值可防止在 Streamlit 重新运行时对同一录音进行重复处理。
侧边栏设置
侧边栏包含应用标题、配置选项以及阶段管理控件:
database = st.session_state.voice_databaseschema = st.session_state.voice_schemafull_stage_name = f"{database}.{schema}.VOICE_AUDIO"stage_name = f"@{full_stage_name}"with st.sidebar: st.title(":material/record_voice_over: Voice-Enabled Assistant") st.write("Talk to your AI assistant using voice input!") st.header(":material/settings: Settings") with st.expander("Stage Status", expanded=False): try: stage_info = session.sql(f"SHOW STAGES LIKE 'VOICE_AUDIO' IN SCHEMA {database}.{schema}").collect() if stage_info: session.sql(f"DROP STAGE IF EXISTS {full_stage_name}").collect() session.sql(f""" CREATE STAGE {full_stage_name} DIRECTORY = ( ENABLE = true ) ENCRYPTION = ( TYPE = 'SNOWFLAKE_SSE' ) """).collect() st.success(":material/check_box: Audio stage ready (server-side encrypted)") except Exception as e: st.error(f":material/cancel: Could not create stage") if st.button(":material/delete: Clear Chat"): st.session_state.voice_messages = [ {"role": "assistant", "content": "Hello! :material/waving_hand: I'm your voice-enabled AI assistant. Click the microphone button to record a message, and I'll respond to you!"} ] st.rerun()侧边栏提供设置界面及相关控件。阶段状态展开面板用于确保音频阶段已正确创建并加密。阶段重建功能可处理阶段配置错误等边界情况。
使用 AI_TRANSCRIBE 转录音频
处理录制的音频
主区域显示对话内容和音频输入组件。录制音频后,系统会将其上传至舞台并进行转录:
st.subheader(":material/voice_chat: Conversation")audio = st.audio_input(":material/mic: Click to record")for msg in st.session_state.voice_messages: with st.chat_message(msg["role"]): st.markdown(msg["content"])status_container = st.container()if audio is not None: audio_bytes = audio.read() audio_hash = hashlib.md5(audio_bytes).hexdigest() if audio_hash != st.session_state.processed_audio_id: st.session_state.processed_audio_id = audio_hash with status_container: transcript = None with st.spinner(":material/mic: Transcribing audio..."): try: timestamp = int(time.time()) filename = f"audio_{timestamp}.wav" audio_stream = io.BytesIO(audio_bytes) full_stage_path = f"{stage_name}/{filename}" session.file.put_stream( audio_stream, full_stage_path, overwrite=True, auto_compress=False ) safe_file_name = filename.replace("'", "''") sql_query = f""" SELECT SNOWFLAKE.CORTEX.AI_TRANSCRIBE( TO_FILE('{stage_name}', '{safe_file_name}') ) as transcript """ result_rows = session.sql(sql_query).collect() if result_rows: json_string = result_rows[0]['TRANSCRIPT'] transcript_data = json.loads(json_string) transcript = transcript_data.get("text", "") if transcript: st.session_state.voice_messages.append({ "role": "user", "content": transcript }) except Exception as e: st.error(f"Error during transcription: {str(e)}")st.audio_input() 在主区域提供麦克风按钮供录制使用。音频字节通过 MD5 哈希算法生成唯一标识符。put_stream() 将音频上传至舞台。AI_TRANSCRIBE 结合 TO_FILE() 将语音转换为文本。系统解析 JSON 格式的转录文本,并将其添加到对话记录中。
生成语音响应
构建对话上下文
经过转写后,对话历史将被格式化为大语言模型的上下文,以生成相关响应:
if transcript: with st.spinner(":material/smart_toy: Generating response..."): conversation_context = "You are a friendly voice assistant. Keep responses short and conversational.\n\nConversation history:\n" history_messages = [msg for msg in st.session_state.voice_messages[:-1] if not (msg["role"] == "assistant" and "Click the microphone" in msg["content"])] for msg in history_messages: role = "User" if msg["role"] == "user" else "Assistant" conversation_context += f"{role}: {msg['content']}\n" conversation_context += f"\nUser: {transcript}\n\nAssistant:" response = call_llm(conversation_context) st.session_state.voice_messages.append({ "role": "assistant", "content": response }) try: session.sql(f"REMOVE {stage_name}/{safe_file_name}").collect() except: pass st.rerun()else: st.session_state.processed_audio_id = None对话历史以对话形式呈现,为上下文提供语境支撑。大语言模型(LLM)负责生成符合对话场景的回复内容。REMOVE 命令用于清理临时音频文件。st.rerun()方法可刷新界面,确保新消息能够及时显示。最后,在 else 分支中,当检测不到音频输入时,系统会将 processed_audio_id 重置为 None,从而确保后续录音文件能够被正常处理。
完整应用
将这些代码整合在一起,我们就得到了一个完整的语音助手应用:
import streamlit as stimport jsonfrom snowflake.snowpark.functions import ai_completeimport ioimport timeimport hashlibtry: from snowflake.snowpark.context import get_active_session session = get_active_session()except: from snowflake.snowpark import Session session = Session.builder.configs(st.secrets["connections"]["snowflake"]).create()def call_llm(prompt_text: str) -> str: """Call Snowflake Cortex LLM.""" df = session.range(1).select( ai_complete(model="claude-3-5-sonnet", prompt=prompt_text).alias("response") ) response_raw = df.collect()[0][0] response_json = json.loads(response_raw) if isinstance(response_json, dict): return response_json.get("choices", [{}])[0].get("messages", "") return str(response_json)if "voice_messages" not in st.session_state: st.session_state.voice_messages = []if len(st.session_state.voice_messages) == 0: st.session_state.voice_messages = [ { "role": "assistant", "content": "Hello! :material/waving_hand: I'm your voice-enabled AI assistant. Click the microphone button to record a message, and I'll respond to you!" } ]if "voice_database" not in st.session_state: st.session_state.voice_database = "RAG_DB" st.session_state.voice_schema = "RAG_SCHEMA"if "processed_audio_id" not in st.session_state: st.session_state.processed_audio_id = Nonedatabase = st.session_state.voice_databaseschema = st.session_state.voice_schemafull_stage_name = f"{database}.{schema}.VOICE_AUDIO"stage_name = f"@{full_stage_name}"with st.sidebar: st.title(":material/record_voice_over: Voice-Enabled Assistant") st.write("Talk to your AI assistant using voice input!") st.header(":material/settings: Settings") with st.expander("Database Configuration", expanded=False): database = st.text_input("Database", value=st.session_state.voice_database, key="db_input") schema = st.text_input("Schema", value=st.session_state.voice_schema, key="schema_input") st.session_state.voice_database = database st.session_state.voice_schema = schema st.caption(f"Stage: `{database}.{schema}.VOICE_AUDIO`") st.caption(":material/edit_note: Stage uses server-side encryption (required for AI_TRANSCRIBE)") if st.button(":material/autorenew: Recreate Stage", help="Drop and recreate the stage with correct encryption"): try: full_stage = f"{database}.{schema}.VOICE_AUDIO" session.sql(f"DROP STAGE IF EXISTS {full_stage}").collect() session.sql(f""" CREATE STAGE {full_stage} DIRECTORY = ( ENABLE = true ) ENCRYPTION = ( TYPE = 'SNOWFLAKE_SSE' ) """).collect() st.success(f":material/check_circle: Stage recreated successfully!") st.rerun() except Exception as e: st.error(f"Failed to recreate stage: {str(e)}") with st.expander("Stage Status", expanded=False): database = st.session_state.voice_database schema = st.session_state.voice_schema full_stage_name = f"{database}.{schema}.VOICE_AUDIO" try: stage_info = session.sql(f"SHOW STAGES LIKE 'VOICE_AUDIO' IN SCHEMA {database}.{schema}").collect() if stage_info: st.info(f":material/autorenew: Recreating stage with server-side encryption...") session.sql(f"DROP STAGE IF EXISTS {full_stage_name}").collect() session.sql(f""" CREATE STAGE {full_stage_name} DIRECTORY = ( ENABLE = true ) ENCRYPTION = ( TYPE = 'SNOWFLAKE_SSE' ) """).collect() st.success(f":material/check_box: Audio stage ready (server-side encrypted)") except Exception as e: st.error(f":material/cancel: Could not create stage") if st.button(":material/delete: Clear Chat"): st.session_state.voice_messages = [ { "role": "assistant", "content": "Hello! :material/waving_hand: I'm your voice-enabled AI assistant. Click the microphone button to record a message, and I'll respond to you!" } ] st.rerun()st.subheader(":material/voice_chat: Conversation")audio = st.audio_input(":material/mic: Click to record")for msg in st.session_state.voice_messages: with st.chat_message(msg["role"]): st.markdown(msg["content"])status_container = st.container()if audio is not None: audio_bytes = audio.read() audio_hash = hashlib.md5(audio_bytes).hexdigest() if audio_hash != st.session_state.processed_audio_id: st.session_state.processed_audio_id = audio_hash with status_container: transcript = None with st.spinner(":material/mic: Transcribing audio..."): try: timestamp = int(time.time()) filename = f"audio_{timestamp}.wav" audio_stream = io.BytesIO(audio_bytes) full_stage_path = f"{stage_name}/{filename}" session.file.put_stream( audio_stream, full_stage_path, overwrite=True, auto_compress=False ) safe_file_name = filename.replace("'", "''") sql_query = f""" SELECT SNOWFLAKE.CORTEX.AI_TRANSCRIBE( TO_FILE('{stage_name}', '{safe_file_name}') ) as transcript """ result_rows = session.sql(sql_query).collect() if result_rows: json_string = result_rows[0]['TRANSCRIPT'] transcript_data = json.loads(json_string) transcript = transcript_data.get("text", "") if transcript: st.session_state.voice_messages.append({ "role": "user", "content": transcript }) else: st.error("Transcription returned no text.") st.json(transcript_data) else: st.error("Transcription query returned no results.") except Exception as e: st.error(f"Error during transcription: {str(e)}") if transcript: with st.spinner(":material/smart_toy: Generating response..."): conversation_context = "You are a friendly voice assistant. Keep responses short and conversational.\n\nConversation history:\n" history_messages = st.session_state.voice_messages[:-1] if len(st.session_state.voice_messages) > 1 else [] history_messages = [msg for msg in history_messages if not (msg["role"] == "assistant" and "Click the microphone button" in msg["content"])] for msg in history_messages: role = "User" if msg["role"] == "user" else "Assistant" conversation_context += f"{role}: {msg['content']}\n" conversation_context += f"\nUser: {transcript}\n\nAssistant:" response = call_llm(conversation_context) st.session_state.voice_messages.append({ "role": "assistant", "content": response }) try: session.sql(f"REMOVE {stage_name}/{safe_file_name}").collect() except: pass st.rerun()else: st.session_state.processed_audio_id = Nonest.divider()st.caption("Day 25: Voice Interface | 30 Days of AI")现在,让我们来看看我们构建的语音助手应用程序:
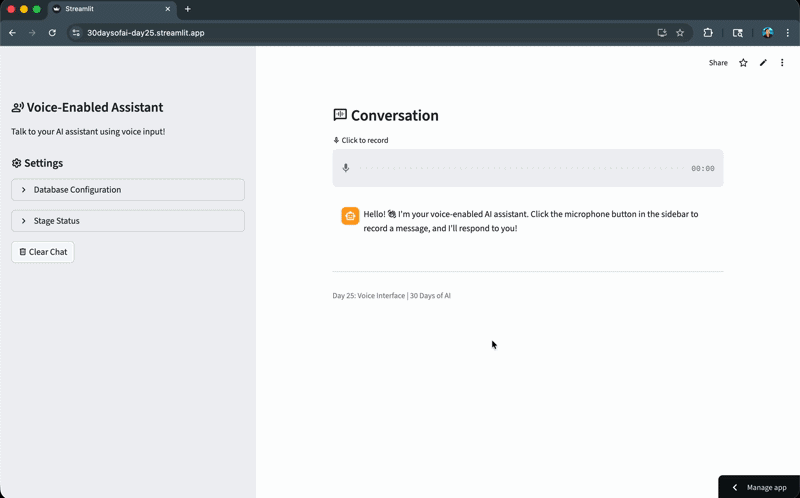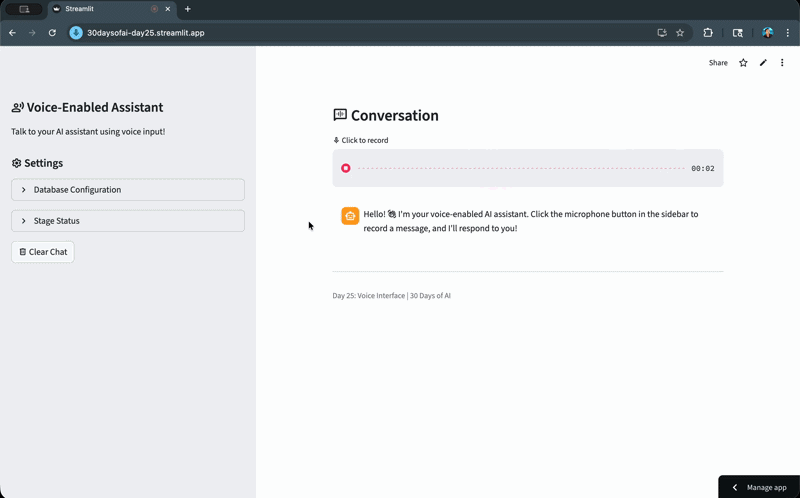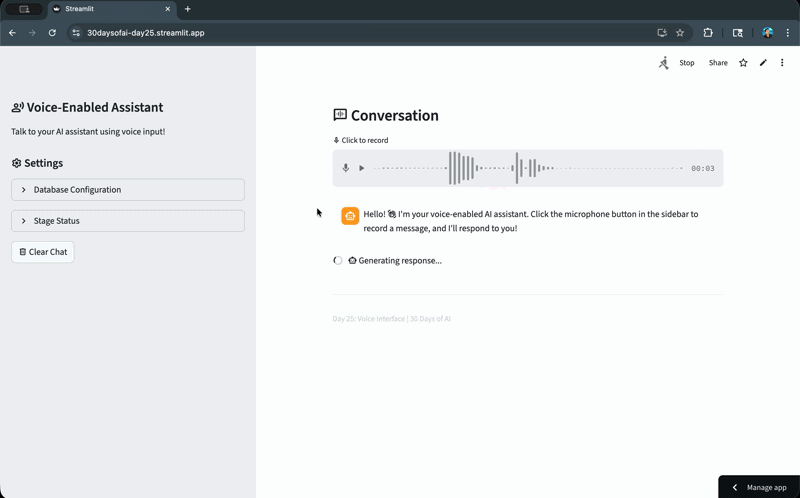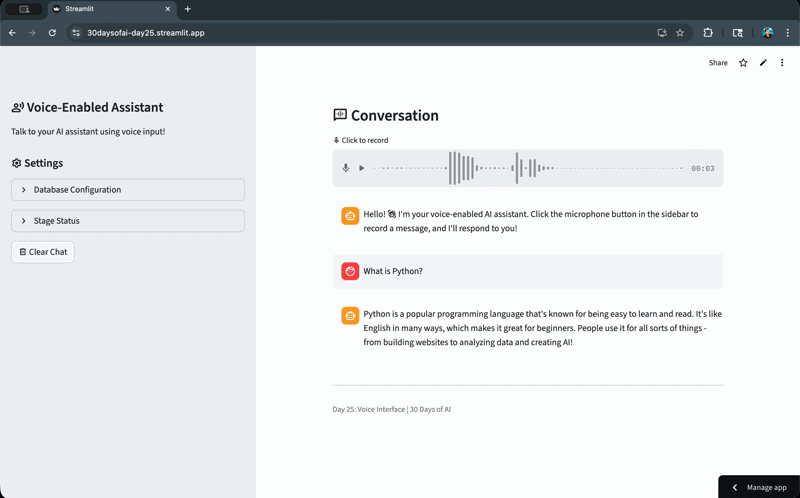
部署应用
将上述代码保存为 streamlit_app.py,并使用以下任一方式进行部署:
本地部署:在终端中运行
streamlit run streamlit_app.py;Streamlit Community Cloud:通过 GitHub 仓库部署应用;
Streamlit in Snowflake(SiS):直接在 Snowsight 中创建 Streamlit 应用。
总结与资源
恭喜您!您已成功利用 Snowflake Cortex 的 AI_TRANSCRIBE 函数构建了一个支持语音交互的 AI 助手。现在,用户可以通过语音提问,并获得智能化的对话式回复。
本课要点
• 使用 Snowflake Cortex AI 服务中的 AI_TRANSCRIBE 函数实现语音转文本;
• 创建具备适当加密机制的内部阶段以处理音频文件;
• 将 Streamlit 的音频输入组件与 Snowflake 平台进行集成;
• 构建一个具备对话能力的语音助手。
相关资源
技术文档:
• Snowflake AI_TRANSCRIBE 官方文档
扩展阅读:
点击链接立即报名注册:Ascent - Snowflake Platform Training - China,更多 Snowflake 精彩活动请关注专区。




