
噪声是决定音视频质量是否良好的关键。近年来 AI 降噪技术取得了很大的突破,但目前的 AI 降噪方案仍大多存在如下两个问题:一是网络模型过于复杂,性能消耗巨大,给实时场景交付提出了很大的挑战;二是容易将音乐当成噪声,对音乐场景的覆盖存在明显弊端。
基于上述挑战,即构科技首发行业内场景化 AI 降噪解决方案。本文为 ZEGO 即构科技引擎开发中心音频处理专家 Jacob 活动分享内容——《 ZEGO 即构科技场景化 AI 降噪技术解析》的回顾。
ZEGO 即构科技实时互动 RTI
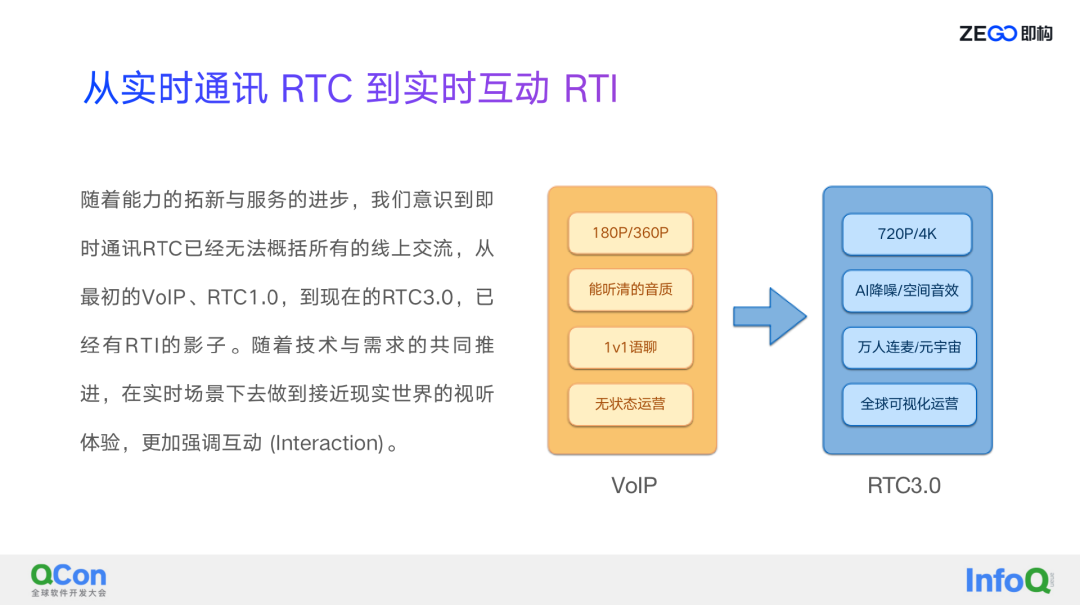
即构的实时互动 RTI 被提出,是随着能力的拓新与服务的进步,即构意识到现在的用户场景越来越丰富,之前 RTC 实时通讯这个概念已经没办法完全支撑线上的业务。
从 VoIP 到 RTC3.0,通过上图中可以看出,从视频方面,以前 VoIP 主要是可视的视频,小分辨率 180p 或 360p,到现在的话可能就要高清的视频 720p 或者 4K;音频像以前的低码率只要听得清就行,到现在需要有清晰的经过 AI 降噪的音频,或者是有一些空间音效的音频,在一些游戏场景会经常被用到;以前的 1V1 语聊场景到现在万人连麦,特别是未来可能比较火的元宇宙概念;从无状态到现在状态的可视化,所有的这些改变都是在从以前的实时通讯一步步往实时交互的方向发展。
所以即构提出的 RTI 这里面的“I”就是交互(Interaction)的概念,就是在技术与需求的共同推进下,在实时场景下做到接近现实世界的视听体验效果,由实时通信 RTC 转变为更加强调互动、并围绕互动发展出更多场景的实时互动 RTI 时代。

所谓实时互动 RTI,即构定义它代表现在和未来整个即构能力的总和,包括了客户端方面的技术,包括音频的一些算法,例如 3A、AI 音频,还有视频,包括视频编解码还有现在的一些 AI 超分等技术的总和,另外还包括服务器的一些数据的融合分发,包括我们经常会玩儿一些游戏有分组这些,这都需要服务器这边来做,另外服务器还有包括状态的维护,所有这部分东西我们都把它认为是一个 RTI 所需要的技术。相比于传统的 RTC,RTI 是以信息、通过数字化的方式,而不是以单纯的信息交互为目标,会更强调互动,使人与人之间共享时空,用可视化的服务体系来保障更好的互动体验,在高效准确的基础之上满足用户在精神上的追求。
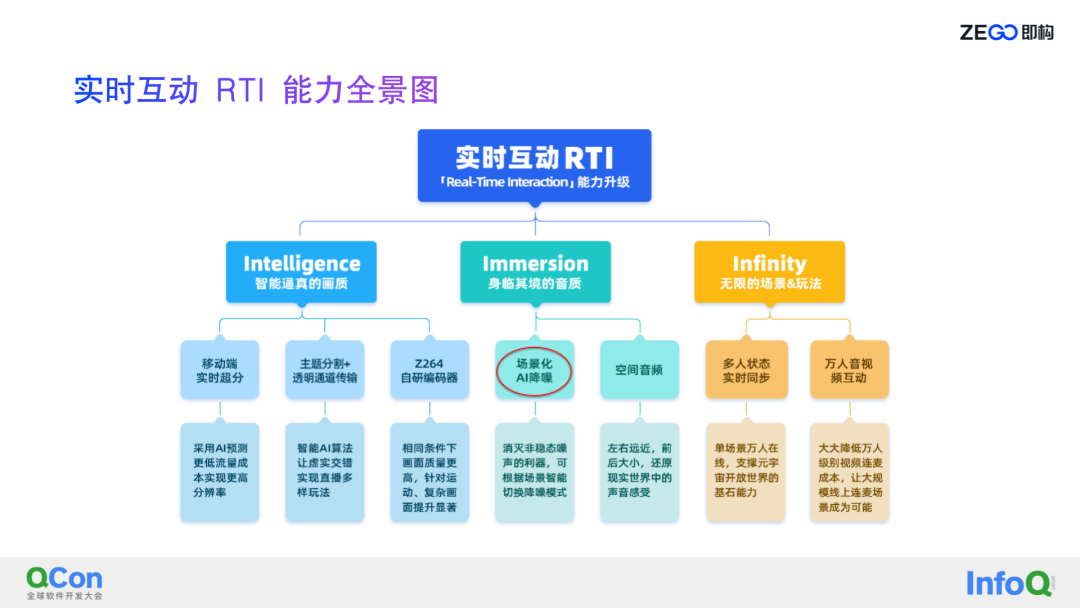
即构实时互动 RTI 包括三个“I”,第一个“I”是 Intelligence ,指视频能力,AI 视频增强引擎的全面升级包括编解码的升级,还有一些新功能的发展,包括 AI 超分、弱光增强、实物检测,通过这些视频技术来让用户拥有更加智能和逼真的画质;第二个“I”是音频方面的 Immersion,讲的是未来音频需要有类似于空间音效、场景化 AI 降噪、场景化音视频配置、范围语音、分组语音等技术,所有这些技术都是为了支撑实现身临其境的音质体验;第三个“I”是 Infinity,是指实现万人连麦、万人范围音视频、万人状态实时同步,来实现更多的场景和玩法。
降噪算法的发展历程
1、噪声分类

关于降噪算法的发展,其实在整个实时交互过程当中,噪声无处不在,语音的音质对交互的体验影响非常大,而降噪技术对语音音质的影响又比较大,所以在整个从 RTC 到现在的 RTI 升级的过程中,大家都在努力的去做到更好的降噪效果,简单来讲就是希望可以在不失真的情况下尽量的把噪声去除的更干净,保证用户听的更清晰。
噪声,我将它分为稳态噪声、非稳态噪声。噪声在日常生活当中非常常见,在各种场景中都有,例如办公场景有鼠标、键盘、空调、远处同事说话声音、房间的混响,还有家里的洗碗、风声、雨声、汽笛声,还有菜市场的声音,种类非常多。在实时通讯过程当中怎么做到既能保证人声不失真又能保证音频噪声能降的更干净,这是即构音频算法工程师的一个至高的要求也是一个追求。
2、降噪算法发展历程
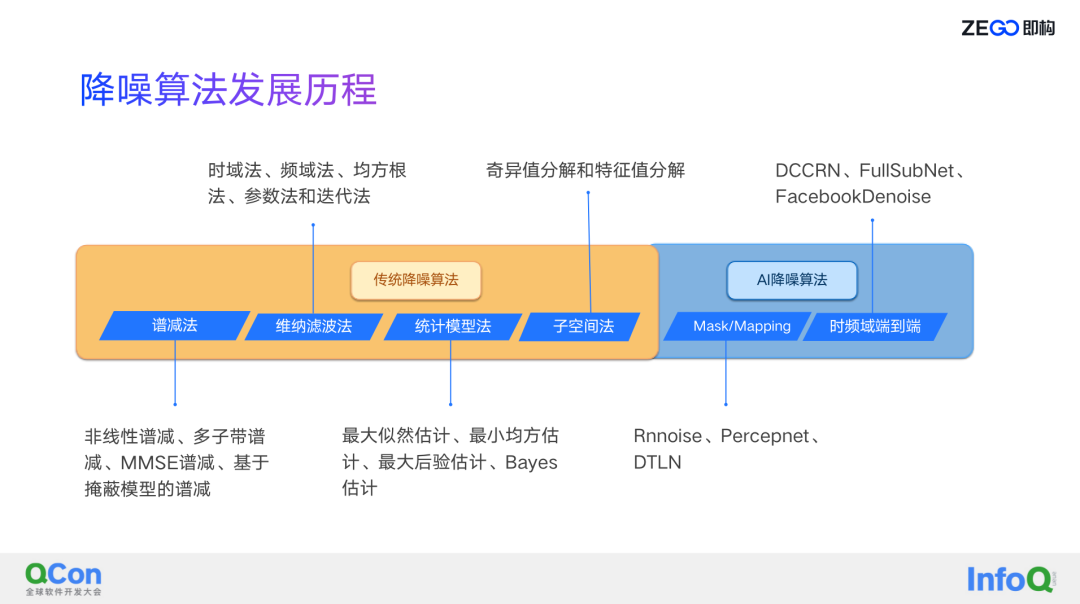
将降噪发展历程分两个部分,一个是传统降噪,还有一个是 AI 降噪,这个分类不一定对,后面跟大家去讲。
传统降噪主要是包括像传统的谱减法、维纳滤波法、统计模型法、子空间法,这些算法主要的降噪思路是差不多的,基本都是通过频谱能量,辅以一个 VAD 的估计来判断,当它是噪声的时候估算噪声谱,得到噪声谱后就可以得到一个先验的信噪比,并根据增益函数将先验信噪比转换为频点的增益,最终得到估计的纯净语音。
这些算法最大的不同之处是用什么样的方式来更准确的估计噪声,从而得到更准确的先验信噪比,来最终得到一个更好的纯净语音。像维纳滤波,它最主要的算法是类似像 MMSE,像谱减法、维纳滤波,统计方法的话大部分是最大最小似然估计的这种方式。
对于 AI 降噪来讲,我分成了两类,第一类是 Mask/Mapping,第二类是端到端:
Mask/Mapping 与传统降噪其实是类似的,并没有完全脱离传统降噪,它是用深度学习的方式去估计噪声,然后根据噪声再估计频点增益,就是语音的增益,整个思路跟传统降噪是一样的。
而端到端的方式区别就是不需要去估计这些增益,直接输入一个要么是全频点的语音谱,要么是时域的语音谱,并且大部分除了会去估计谱能量还会去估计相位,从最终的效果来讲肯定是端到端一般来说更好一些,但它带来的最大问题是很难落地,因为它的输入太多,要估计频点的相位导致整个运算量非常大,特别是在移动端,很难落地。这里面比较有代表性的端到端像 DCCRN、FullSubNet。
所以此次主要讲的是要落地,要实现设备、场景的全覆盖,用的就是 Mask/Mapping 的方式。这种方式最大的好处是估计的是谱能量,没有去估计相位,所以这里面的运算量低了很多,另外即构发现大部分场景下其实信噪比还是比较 OK 的,信噪比 OK 的情况下带噪的相位和纯净语音的相位会有差别,但没有相差很远,所以说估计出来的纯净语音的音质还是不错的,当然这里面做了一点点牺牲,也是为了能够落地才去这样做的。
3、传统降噪与 AI 降噪算法对比

关于传统算法和 AI 算法的对比,这里我给出来几点总结:
传统信号处理算法对稳态噪声的处理效果较好,这主要因为传统处理算法都是根据历史的带噪语音来估计噪声,但它对非稳态噪声估计不准,所以降噪效果就不是特别理想,特别是一些瞬态噪声,所以就会有一些环境适应能力较差的问题。但它的优点同样很明显,它的性能开销很小,在任何设备上基本都能跑,实时性也有保证,并且对于稳态噪声的处理上,稳定性还算是比较不错的。
AI 降噪算法的优点是它的环境适应能力很强,因为它经过大量的数据训练,知道各种模型的噪声状态,所以无论是在稳态噪声环境还是非稳态噪声环境下,它在处理上都有一个比较好的表现,但它的问题就是性能开销比较大,另外很有可能像有一些推理库之类的内存占用比较高,所以对于它的落地,特别是实时交互这种场景下它的落地会有一些比较尖锐的问题。
另外, AI 降噪里面专门提出来一点就对音乐场景不友好,因为 AI 降噪降的是非人声,它估计的是人声,但对于音乐场景来讲,音乐是非人声的,那怎么来处理音乐场景?这就是本次演讲的主题,就是即构提出来的场景化 AI 降噪解决方案。
4、实时互动场景的困难与挑战

实时互动场景的困难和挑战,一个是它的场景比较复杂,实时互动场景可能发生在任何时间、任何地点、任何方式。比较典型的两个例子,一个是钢琴教学,涉及到音乐场景,还有一个是语聊场景,并且语聊场景大家很多时候是不戴耳机的,是用设备的喇叭和麦克风直接做场景的交互,所以场景是非常复杂的。
另外还有低时延的要求,所谓的低时延这里面主要是说实时交互很多是在线的业务,比如说在线的连麦、在线 K 歌还有在线合唱,特别是合唱的场景对时延的要求是极高的,如果时延高了两个人合唱效果就较差。
另外一个是低开销,移动端设备有老设备有新设备,经常我们用的话像苹果 6 这种很老的设备,性能参差不齐,应用玩法现在越来越丰富,各种应用,大家都在抢资源,那么要想跑起来的话低开销才能实现全覆盖,所以一定要求低开销,所谓低开销是低到什么程度?从经验来谈,因为降噪是整个应用过程当中很小的一个部分,如果性能开销太大会占用其他算法的一些资源,同时也不能去用 GPU,因为视频是性能开销的大头,有很多应用包括视频的超分之类都需要用到 GPU,还有一些硬编硬解,也需要用到,所以这里面低开销不光是说整个降噪要低开销,并且是它的限制场景,你不能用太多加速的处理器。
另外要说的是高保真和高鲁棒性,因为即构追求的是在语音不失真的情况下尽量消除噪声,这样才能保证有一个更好的交互体验,所以基于以上的挑战,结合传统算法和 AI 算法的优势和局限性,为了满足各种应用场景,即构引入了一个场景化 AI 降噪解决方案,就是通过 AI 音乐检测判断当前是否是音乐场景。

这里有一个整体方案的流程图,即构把整个的场景化 AI 降噪融入到语音增强模块当中,先回声抵消之后做场景化 AI 降噪,然后通过自动增益,出来增强后的语音。
这幅图其实不够完整,但是为了更好的表现即构是怎么做的,不够完整的原因其实是传统降噪跟 AI 降噪在整个引擎里面其实就是降噪的一个模块,只是说分了不同的降噪等级,所以当音乐检测检测到音乐状态的时候,需要去调整它的降噪等级,它有可能从 AI 降噪降为传统降噪,也有可能从传统降噪降到级别更低或者甚至没有降噪这种场景,这些用户都可以自由配置。
一般通讯场景,即构 AI 降噪技术实现
场景化 AI 降噪包含两部分,一部分是 AI 降噪,还有一部分是 AI 的音乐检测。
第一部分就是一般场景下即构 AI 降噪的技术实现。一般场景下其实要的是保留人声,去除非人声的噪声,相当于把音乐场景单拎出来,单独去做处理,除开音乐场景即构都认为是一般的通讯场景。
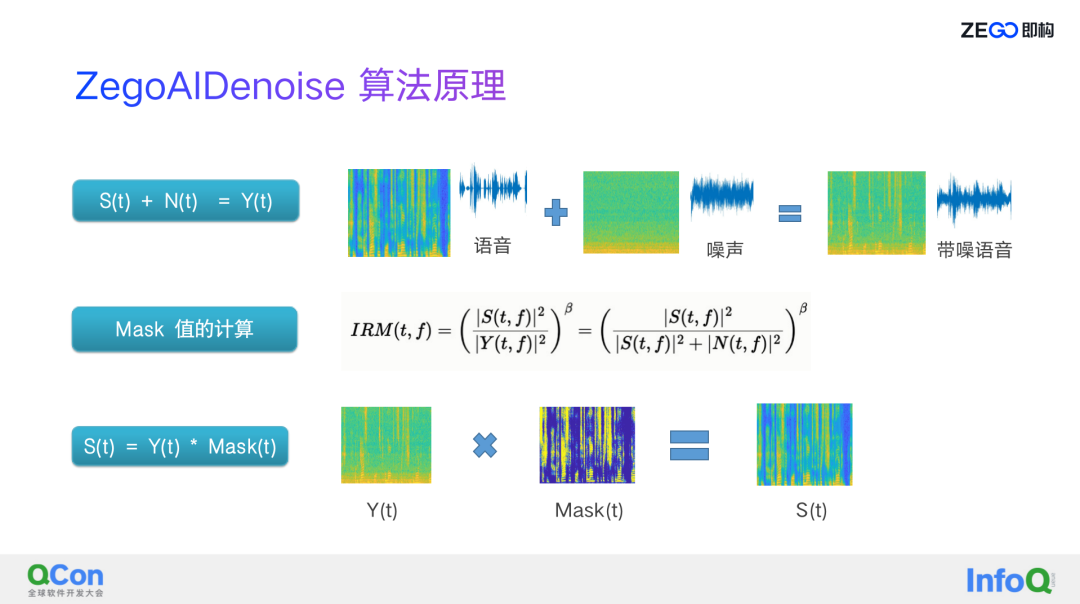
关于 AI 降噪,即构用的算法原理是跟传统降噪非常类似的,即构认为一个带噪语音就是语音加上噪声,语音和噪声的相关性没有或者很弱,基本上可以认为是一个加性噪声,当我们有带噪语音之后,根据 IRM Mask 值,再通过卷积的方式可以得到 S(t),就是 Y(t) * Mask,那么这个 Mask 怎么来的呢,其实就是即构 AI 降噪的一个目标,这个 Mask 是用 IRM,是语音能量跟带噪语音能量的比值,公式里面有一个 beta,像谱减法,维纳滤波法,每一种方法系数稍微不太一样,但系数可以根据我们的需要去调整。
在这里面整个即构 AI 降噪对 beta 做了一些调整,大部分场景即构用的是维纳滤波系数,但有时候即构会对它做一些微调,为什么会做微调?因为在一些低信噪比情况下,经常出现过抑制的问题,所以即构发现通过调整 beta 值可以很好的规避这个问题,来自动调整低信噪比下的 beta 值,可以解决低信噪比下的过抑制问题。
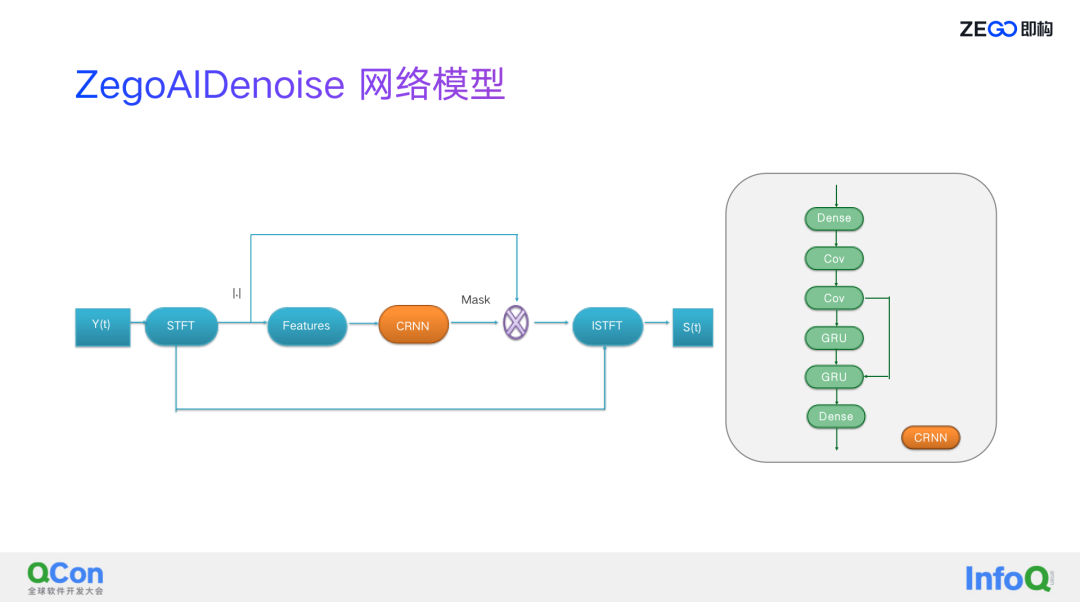
ZegoAIDenoise 的网络结构如上图所示,这个网络模型非常简单,从左边来看是个流程图,网络是 CRNN,是右边的图,通过短时傅里叶变换,把时域信号转成频域信号,然后我们只估计幅值,最后得出来 Mask 值,后面会做一些简单的后处理,比如谐波增强之类的传统技术,得到频点增益,根据频点增益再加上带噪信号的相位,最后来恢复纯净语音信号。
这里为什么即构选择这样的方式,即构要落地,要网络极简,所以就没有办法去做相位的估计,但现在即构也在做优化,特别在低信噪比下,相位对降噪的效果影响非常大,怎么来做到在低信噪比情况下又能增加不大的计算量情况下估计出比较好的相位,得到比较好的纯净语音,这个正在做这样的优化。
后面的网络比较简单,是两个 CONV 卷积加上两个 GRU,两个 Dense 层,整个输入用的是提取特征值,用的是传统信号处理方式,这里的特征值主要包括频谱能量,频谱的相关性,还有基因周期,这里跟 RNNOISE 里面有些类似,即构也做了一些改进,加了其他的一些特征,比如谱平坦度、谱重心这样的一些系数在里边,另外即构算基因周期的时候也做了一些自己的优化,可以让它的基因周期算的更准,这个对深度学习来讲可以学的更好。
另外为什么用这么简单的一个网络模型,其实现在网上有很多基于二维的网络模型去学习 Mask,但即构发现二维网络模型要学的是什么?卷积学的是什么?卷积最终也是希望学到语音的特征,但很多情况下一个比较小的网络是很难学到即构传统的信号处理方式提取出来的这些特征,比如说基因周期或者说频谱的相关性。
这里面还要分享一点就是在整个网络优化过程当中,即构加了一点跳连,从第二个一维卷积跳连到第二个 GRU,这里边加了一点运算量,但对整个结果的影响比较大,效果会好不少。

整个极简化,即构 ZegoAIDenoise 做了很多的优化,关于 AI 降噪的训练我个人认为深度学习学的好或者不好,取决于几个比较关键的因素,第一个是数据,数据的覆盖性越广,特别是纯净语音信号越干净,越有利于网络的训练,另外一个目标还有 loss 的设计。
1、高鲁棒性
从训练数据方面,即构为了增加它的高鲁棒性实时采了很多数据,实现多平台、多场景覆盖,在不同的场景,工厂、办公室还有地铁、公交,以及自己经常出去走一走,或者开车的时候打开麦克风把数据录上,这些数据毕竟是有限的,所以即构加入了多种数据增广的方式,加频扰、加混响、低通滤波、削波处理。
削波处理相当于是即构把它放大后来做削波处理,因为有些场景的主播喜欢说话的时候让嘴巴靠近麦克风,同时又有比较强的呼麦的效果,所以削波处理还是比较关键的因素。
2、低开销
在特征提取方面,即构基于人耳听觉特性做了分子带,将输入特征压缩至 40+个,一开始的特征量比较多,后来即构做了类似于蒸馏以及其他的像老师学生的这些方式,通过各种方式来把特征量压到最少,并且对训练结果影响不大。
在推理库方面,包括现在的开源的 TNN、MNN,其实整个推理库是很大的,但即构的降噪要用到的算子很少,没必要用那么大的框架,即构借鉴的是 RNN 的那套方案,用即构自己极简的推理库,整个网络训练里面要用到什么算子,即构就加什么算子,并且对算子进行推理库指令集的优化,最终减少整个内存的占用,指令集优化对性能开销有影响,推理库内存的占用很小。所以整个 AI 降噪下来即构包量是很小的,现在是 1M 多一点。
3、低延时、高保真
在特征这方面,即构参考了 Percepnet 的方案,引入了梳状滤波器,虽然提高了语音特征的有效性,但是也带了一定的时延。梳状滤波器有几个作用,可以使基于基因周期得到的频谱相关性更准确,可以用未来帧的信号特征来表征当前帧的特征,笼统来讲就是提高了当前帧的特征有效性,可以有效抑制谐波间的噪声。低信噪比场景自适应的调整 Mask 值,这个是为了前边讲的公式里的 beta 值,通过调整 beta 值来解决低信噪比下的过抑制问题。
当然这里面我们还有其他的问题,大家遇到比较多的比如从非语音到语音,这个转换过程当中最初始的语音部分很容易过抑制,另外比较大的问题是清音过抑制,即构在这方面也做了很多的事情,一个是尝试在 AI 降噪的前面加一个传统降噪的方式,这种方式有一定的效果;第二种方式是清洗了音频数据,就是纯净语音的数据,增加了很多清音语音的占比,让它去学习在这种场景下我应该保留更多的一些清音。
4、训练优化
在网络训练方面调整数据的分布,即构做的是极简化的 AI 降噪,整个网络模型非常小,它的表征能力不是很强的,没有办法去覆盖所有实时互动的场景,虽然说我们的场景非常丰富多样,但还是有我们的主要场景,所以为了让这些主要场景可以得到更好的降噪效果,即构去调整数据的分布来提升重要及常用场景降噪的效果。
另外是 loss 的优化,调整 L2 及 L4 的权重,即构还做了一些其他的事情,比如说我们根据 IRM 的值做一个加权的 WIRM loss,这样也可以更有效的表征整个学习的收敛度以及最终降噪的效果。
最后即构还引入了注意力机制,减少对清音的损伤,同时为了提升泛化能力即构增加了数据的乱序和 drop 机制。这其实是整个框架的问题,我们最开始用的 TF 的框架,现在用的是 Pytorch 框架,并且我们做了实时数据生成这样的方式,在训练的时候对数据做一些乱序或者 drop 机制,来提高泛化能力,尽量提升整个 AI 降噪的鲁棒性。
5、ZegoAIDenoise 效果展示
AI 降噪对办公场景的降噪处理效果
AI 降噪对音乐场景的降噪处理效果
关于上方的音乐场景降噪效果视频,包含了几个部分:非音乐、纯伴奏、伴奏+人声,从伴奏开始都是音乐,从主观的听感来讲这里的音乐是很明显的,从整个 AI 降噪来看把伴奏也当成了噪声,对非音乐还有伴奏其实都是做了一个比较过的抑制,把伴奏给消完了,同时对人声的抑制也比较明显。
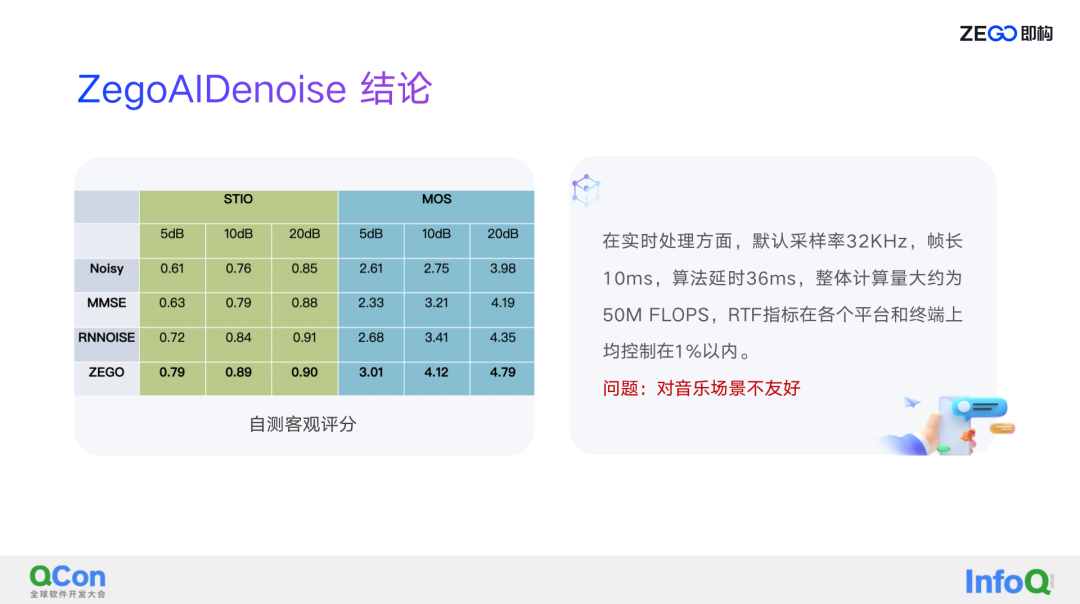
客观评分只是一个参考,更主要的是即构要通过主观的多听,多去区分,这样才会有比较好的效果。
从客观评分来讲,我做了传统算法的降噪对比和对标 RNNOISE 在 5dB、10dB、20dB 的简单对比,可以看到效果有明显的改善,并且从主观听觉来看,即构 AI 降噪其实取得了不错的表现。整体的运算量因为即构用的是极简的网络,总共加起来是 50M FLOPS,整个实时比在各平台和终端上都控制在 1% 以内,这个 1% 即构取的是 iPhone 6 的实时比,在一些主流手机上它的实时比可以达到 0.4-0.5%。
音乐场景下,即构降噪技术实现
前面讲到 AI 降噪对音乐场景不是太友好,因为在处理中把音乐当成了噪声,为了解决这个问题即构将音乐场景单拎出来做了降噪,也就是接下来要讲的音乐场景下的即构降噪技术实现。
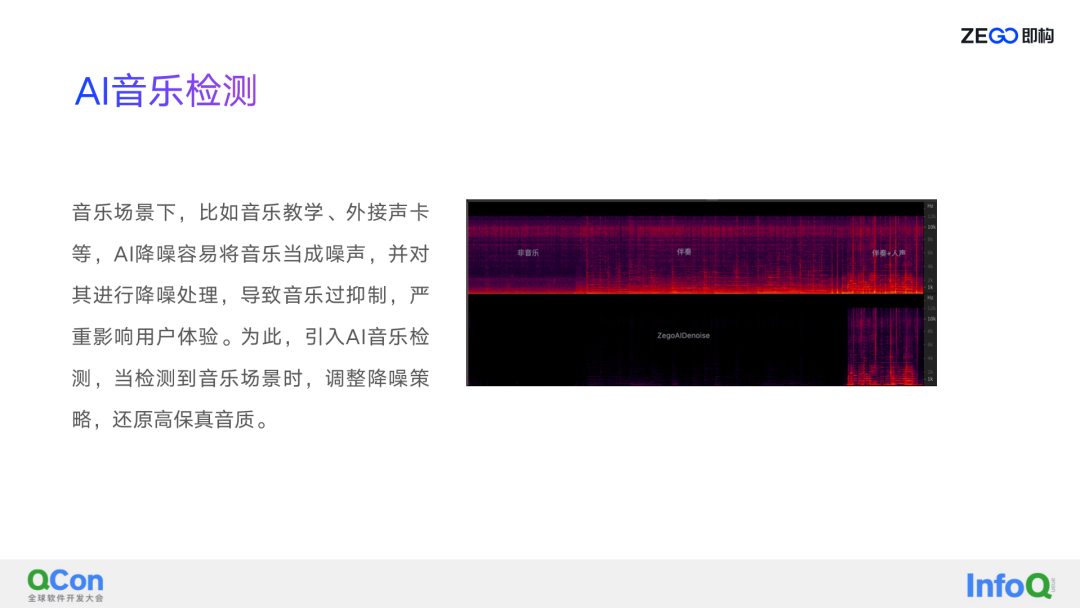
这里面主要解决的是 AI 音乐检测的问题,在实际过程当中会碰到很多问题,比如什么场景下该如何定义音乐场景,有些像一部分主播用声卡场景的音乐是很明显的,但在一些场景下比如说有些是拿着一个第三方设备站在那儿播放音乐,这个时候有可能信噪比比较低,所以怎么定义音乐场景是比较困难的事情。即构选择的是相对复杂的场景,音乐场景主要有音乐教学、外接声卡之类的,引入 AI 音乐检测,当检测到音乐场景时即构做一些特殊处理。

这是 AI 音乐检测的网络模型,跟 AI 降噪是一脉相承,它秉承着轻量级的设计理念,通过传统音频处理算法做特征提取,整个特征量现在是 27 个,实时比的指标差不多是 AI 降噪的 1/5,在比较差的手机上面它可以控制在 0.2% 以内,整个音乐检测的误检率在即构加了一些后处理后,误检率低于 1%,准确率达到 95% 以上,当然这里面还有一些优化的空间。
场景化 AI 降噪处理效果
场景化 AI 降噪之后把伴奏部分保留下来了,当然其中还会残留一部分噪声,这就是场景化 AI 降噪的一个效果。
ZEGO 实时语音处理技术

实时语音增强技术展望,首先当前的技术为了支持 RTI 即构现在有万人范围音视频、万人连麦、美声、变声、空间塑造等等,这些技术支撑当前客户 RTI 基本的所有业务,包括元宇宙、在线教学、虚拟现实、视频会议、秀场直播、在线 K 歌等等。

未来即构会将 AI 更多地融入到产品当中,给大家提供更好的音视频使用体验!




