
据报道,Meta 推出的 LLaMA-13B 的性能优于 ChatGPT 同类技术,但体积却只为后者的十分之一。
Meta 推出全新大语言模型,单 GPU 上可运行
在OpenAI 的 ChatGPT 带来一场 AI 技术革命之后,Google 推出了 BARD,其他几家科技巨头也不甘示弱,纷纷开始“秀肌肉”。目前,全力押注元宇宙的 Meta 公司正准备在其同行中占据优势。近日,这家总部位于加利福尼亚的科技巨头推出了一种新的研究工具,该工具将帮助开发者快速构建基于 AI 的聊天机器人。
当地时间 2 月 24 日,Meta公司宣布一款名为 LLaMA-13B 的新型 AI 大语言模型(LLM),宣称尽管规模仅为竞争对手 ChatGPT 的“十分之一”,但性能却优于 OpenAI 的 GPT-3 模型。
这种小体量 AI 模型的优势,在于有望通过 PC 和智能手机等设备本地运行类 ChatGPT 式的语言助手。顺带一提,LLaMA 的全称为“Large Language Model Meta AI”,即“Meta AI 大语言模型”。
根据 Meta 官方发布的消息,LLaMA 是一种先进的基础语言模型,旨在协助研究人员在 AI 相关领域迅速开展工作。有趣的是,LLaMA 是继 Glactica 和 Blender Bot 3 之后 Meta 的第三个 大规模语言模型,前两个大模型在实际应用效果不尽如人意后立即被关闭。
使用公开数据集训练,后续或将开源
LLaMA 语言模型家族的参数量从 70 亿到 650 亿不等。相比之下,作为 AI“巨星”ChatGPT 的底层模型,OpenAI GPT-3 则拥有 1750 亿个参数。
根据 Meta 的说法,LLaMA 本质上不是聊天机器人,而是一种研究工具,可能会解决有关 AI 语言模型的问题。
“像 LLaMA 这种体积更小、性能更高的模型,能够帮助社区中无法访问大量基础设施的其他人能够研究这些模型,进一步使这个重要、快速变化的领域的访问民主化,”Meta 在其官方博客中这样描述该模型。
Meta 训练其LLaMA模型所使用的是各类公开可用的数据集(例如 Common Crawl、维基百科以及 C4),意味着该公司可能会开源发布模型及其权重设置。在大语言模型行业当中,这代表着一波转折性的新发展,或将打破科技巨头在竞赛中永远把最好的 AI 技术“藏”起来的定式。
项目组成员 Guillaume Lample 在推文中指出,“与 Chinchilla、PaLM 或者 GPT-3 不同,我们只使用公开可用的数据集,这就让我们的工作与开源兼容且可以重现。而大多数现有模型,仍依赖于非公开可用或未明确记录的数据内容。”
现在,我们发布了 LLaMA 的 4 个基础模型,参数从 70 亿到 650 亿不等。LLaMA-13B 在大多数基准测试中优于 OPT 和 GPT-3 175B。LLaMA-65B 则可与 Chinchilla 70B 和 PaLM 540B 正面抗衡。
Meta 将自己的 LLaMA 模型称为“基础模型”,意味着该公司打算以此为基础构建起更加完善的 AI 模型。这类似于 OpenAI 以GPT-3为基础构建 ChatGPT 的作法。Meta 方面希望 LLaMA 能在自然语言研究当中发挥作用,进而在“问答、自然语言理解或阅读理解、理解能力以及解决现有语言模型的局限性”等方面贡献力量。
虽然顶级 LLaMA 模型(LLaMA-65B,拥有 650 亿个参数)明显是在叫板竞争对手 DeepMin、谷歌及 OpenAI 的同类方案,但此次公布阵容中最有趣的反而可能是家族中的“小弟弟”LLaMA-13B,此外,Meta 也表示将提供 7B、13B、33B 和 65B 等参数尺寸的 LLaMA。
前文提到,在接受八大标准“常识推理”基准测试(包括 BooIQ、PIQA、SIQA、HellaSwag、WinoGrande、ARC 和 OpenBookQA 等)时,其在单 GPU 上运行的性能优于 GPT-3。而且跟 GPT-3 系列模型必须依赖于数据中心的庞大设施不同,LLaMA-13B有望在不久的将来,让消费级硬件也能获得趋近 ChatGPT 的 AI 性能表现。
参数规模在 AI 领域意味着什么?
参数规模在 AI 领域非常重要,是负责在机器学习模型当中根据输入数据进行预测或分类的变量。语言模型中的参数规模往往直接决定其性能,较大的模型通常可以处理更复杂的任务、并产生更连贯的输出。然而,参数越多、模型占用的空间也越大,运行时消耗的算力也越夸张。因此,如果一个模型能够以更少的参数获得与另一模型相同的结果,则表示前者的效率有显著提高。
根据 Meta 的说法,训练 LLaMA 等较小的基础模型是理想的,因为它们需要极低的计算能力和资源来测试、验证和探索新的用例。众所周知,基础语言模型可以训练大量未标记的数据,这使得它们非常适合根据各种任务进行定制。
Meta 在其研究论文中指出,LLaMA-13B 在大多数基准测试中都优于 OpenAI 的 GPT-3 (175B),并且 LLaMA-65B 与最佳模型 DeepMind 的 Chinchilla70B 和谷歌的 PaLM-540B 具有竞争力。一旦经过更广泛的训练,LLaMA-13B 可能会成为希望在这些系统上运行测试的小型企业的福音,但是,它要让它脱离开发者独立工作,还有很长一段路要走。
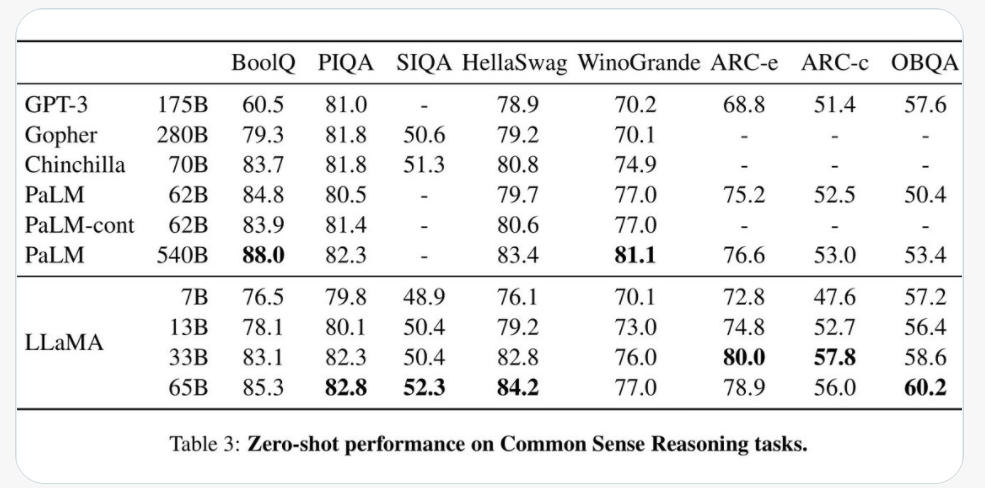
LLaMA 与其他大模型参数对比
独立 AI 研究员 Simon Willison 在文章中评论称,“我认为,我们有望在未来一、两年内通过自己的(旗舰级)手机和笔记本电脑,运行具备 ChatGPT 中大部分功能的语言模型。”
目前,精简版的 LLaMA 已经登陆 GitHub。要了解完整的代码的权重(即神经网络「学习」到的训练数据),Meta 已向感兴趣的研究人员开放访问申请表(https://forms.gle/jk851eBVbX1m5TAv5)。Meta 目前还未宣布更广泛的模型与权重公布计划。
LLaMA 项目地址:https://github.com/facebookresearch/llama
LLaMA 论文地址:https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
参考链接:




