
今天上午,在 2025 小米人车家全生态合作伙伴大会上,罗福莉首次公开亮相,Title 是 Xiaomi MiMo 大模型负责人。
罗福莉还在会上发表演讲,解读了小米的全新大模型 MiMo-V2-Flash 以及背后团队的故事。

MiMo-V2-Flash,是小米在今天凌晨发的新一代 MiMo 模型,而且还给开源了。

这里简单回顾下 MiMo 模型是什么:它是小米自研的大语言模型(LLM)系列;而 MiMo-V2-Flash 不仅在通用基准测试中和 DeepSeek-V3.2 相当,同时还拉爆性价比,对 Agent 场景友好。
MiMo-V2-Flash 采用了当前很流行但工程难度也很高的 MoE(混合专家)架构,其总参数规模达 3090 亿,但在每次推理时,真正被“点亮”的只有约 150 亿参数。
此外,它还搭载了多词元预测(MTP)技术,专为高速推理和 Agent 工作流程而设计。与很多追求“参数越大越好”的模型不同,MiMo-V2-Flash 的设计目标可谓是:“要跑得快、跑得久、被高频调用也跑得起”。
不过在罗福莉看来,MiMo-V2-Flash 还处于小米在大模型和 AI 探索的早期阶段:
“这只是我们在 AGI 路线图上的第二步。”
跟着罗福莉的视角,看懂 MiMo-V2-Flash
罗福莉,就是那位网传“雷军用千万年薪挖来”的 AI 技术大牛。
她硕士毕业于北大计算机体系,在校期间就曾一次性在国际顶会 ACL 中标 8 篇论文,其中 2 篇一作,还登上过知乎热搜。
毕业后,曾前后加入阿里巴巴达摩院和 DeepSeek 母公司幻方量化,在幻方期间曾担任 DeepSeek 的深度学习研究员,参与研发 DeepSeek-V2 等火出圈的模型。
今年 11 月 12 日,罗福莉对外官宣了她加入小米并任职一事。
今天是罗福莉入职小米后的首次公开演讲,有点小紧张,但她依然条理清晰地向大家讲清了 MiMo-V2-Flash 背后的技术取舍。她没有按普通新品发布套路那样去讲,而是给大家讲清了为什么下一代大模型必须为 Agent 和真实世界而设计。

首先,她对当下大模型的发展状态做出了一个清晰的定界:语言模型通过规模化训练确实取得了突破,但本质上,它们更多是解码了人类思维在文本空间中的一种投影,是一条自顶向下的捷径,而非真正理解了物理世界。
这一判断,为后续所有技术选择提供了前提——语言是强工具,但不是终点。
然后,她解释了 MiMo-V2-Flash 背后的工程逻辑:该模型的设计目标并不是“更聪明”,而是更好用、更可部署。
她将问题归结为三个现实挑战:
一是 Agent 需要高效的“沟通语言”,这意味着代码能力和工具调用能力要优先于泛聊天;
二是 Agent 之间的交互带宽过低,因此推理效率必须成为第一设计目标;
三是模型范式正在从预训练转向后训练和强化学习,这要求一个稳定、可扩展的训练体系来承载持续演化。
所以,MiMo-V2-Flash 无论是采用 MoE 架构、控制活跃参数规模,还是引入混合注意力、多词元预测以及面向后训练的蒸馏范式,本质上都是被 Agent 场景“倒逼”出来的工程取舍,而非单纯的技术炫技。
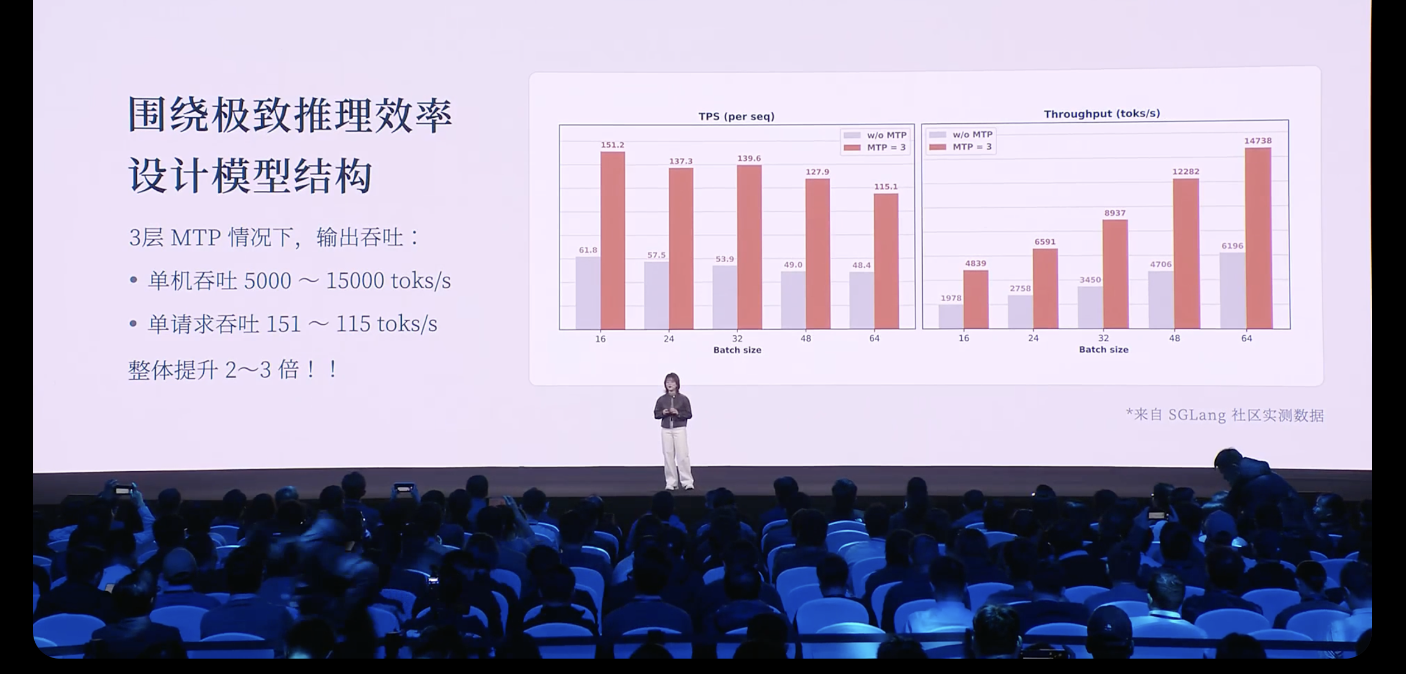
罗福莉指出,虽然 MiMo-V2-Flash 这个模型规模不算很大,但他们通过大量结构和工程优化,让其达到了更极致的推理效率。
她分享称,在推理阶段,团队使用三层 MTP 并行推理,在实际场景中实现了约 2 到 2.6 倍的推理加速。
从社区测试结果来看,在三层 MTP 的情况下,模型输出吞吐与成本高度相关。在单机环境下,吞吐可以达到 5000 到 15000 token/s,而单请求输出速度也能达到 150 token/s。相比不使用 MTP,整体速度提升约 2-3 倍。
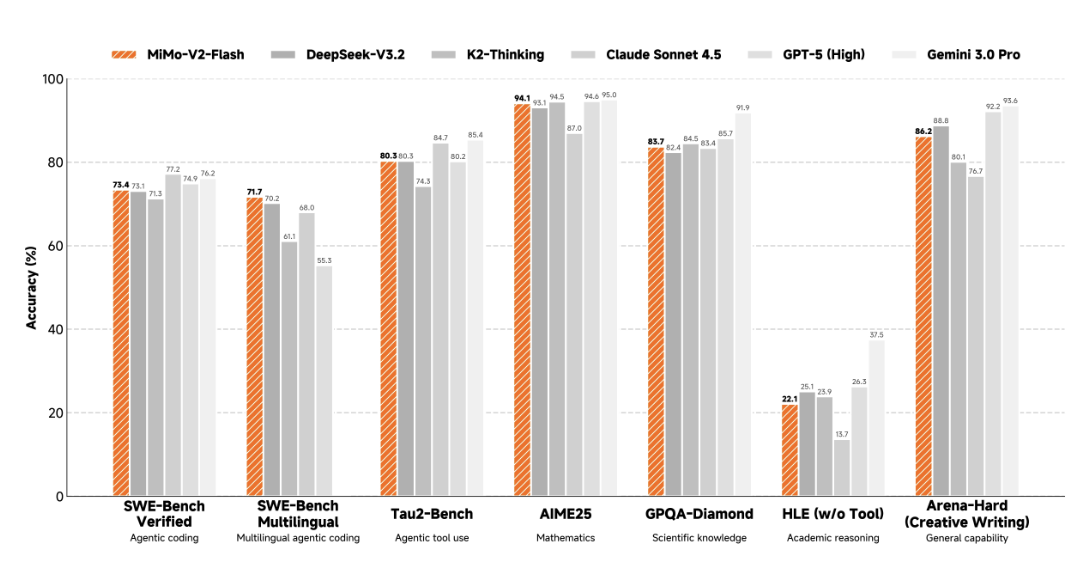
小米官方也公布了 MiMo-V2-Flash 在 7 项主流评测中的成绩,覆盖 Agent、代码、工具调用、数学、科学、学术推理和综合能力;并且和开源的 DeepSeek-V3.2、K2-Thinking,以及闭源的 Claude Sonnet 4.5、GPT-5(High)、Gemini 3.0 Pro“掰手腕”。
结果显示,MiMo-V2-Flash 在 Agent、代码、工具调用、复杂任务执行方面已进入第一梯队。
尤其在 SWE-Bench(评估“LLM 在真实软件工程任务中表现”的权威基准测试)中, MiMo-V2-Flash 在多语言模式下,还以 71.7%的准确率斩获了一项第一。
在演讲的后半段,罗福莉将视角拉高,把讨论从模型本身推向更长远的方向。
她强调,当前的大模型已经可以写代码、解奥数、模仿文学风格,但并不真正理解物理一致性、时空连续性以及与环境之间的因果关系,这也是“具身幻觉”频繁出现的根源。
在她看来,真正的下一代智能体,必须能够与真实环境持续交互。
这意味着,通往下一阶段智能的路径,并不只是增加多模态输入,而是构建一个统一、动态的世界模型:
“智能不是从文本中‘读出来的’,而是要在交互中‘活出来的’。”
这种判断,也构成了她对 AGI 路线的基本立场:她并不否认语言路线的价值,但并不认为只凭语言就能自然通向 AGI。
这种克制的态度同样体现在她对开源的理解中。在她看来,开源并不仅仅是共享模型权重或代码,更是一种分布式的技术加速机制,是缩短开源与闭源差距、推动 AGI 走向普惠化的现实路径。
以下为罗福莉本次讲演全文速记,AI 前线在不改变原意的情况下进行了订正编辑。
其实,大模型是通过语言能力的爆发,通过不断 scaling 计算力、scaling 数据,逐渐理解了人类的思维方式,以及人类对世界的认知。
但严格来说,它(大模型)并不像人类一样真正具备对整个物理世界的感知能力。更严谨地说,它是成功解码了人类思维在文本空间中的一种投影。
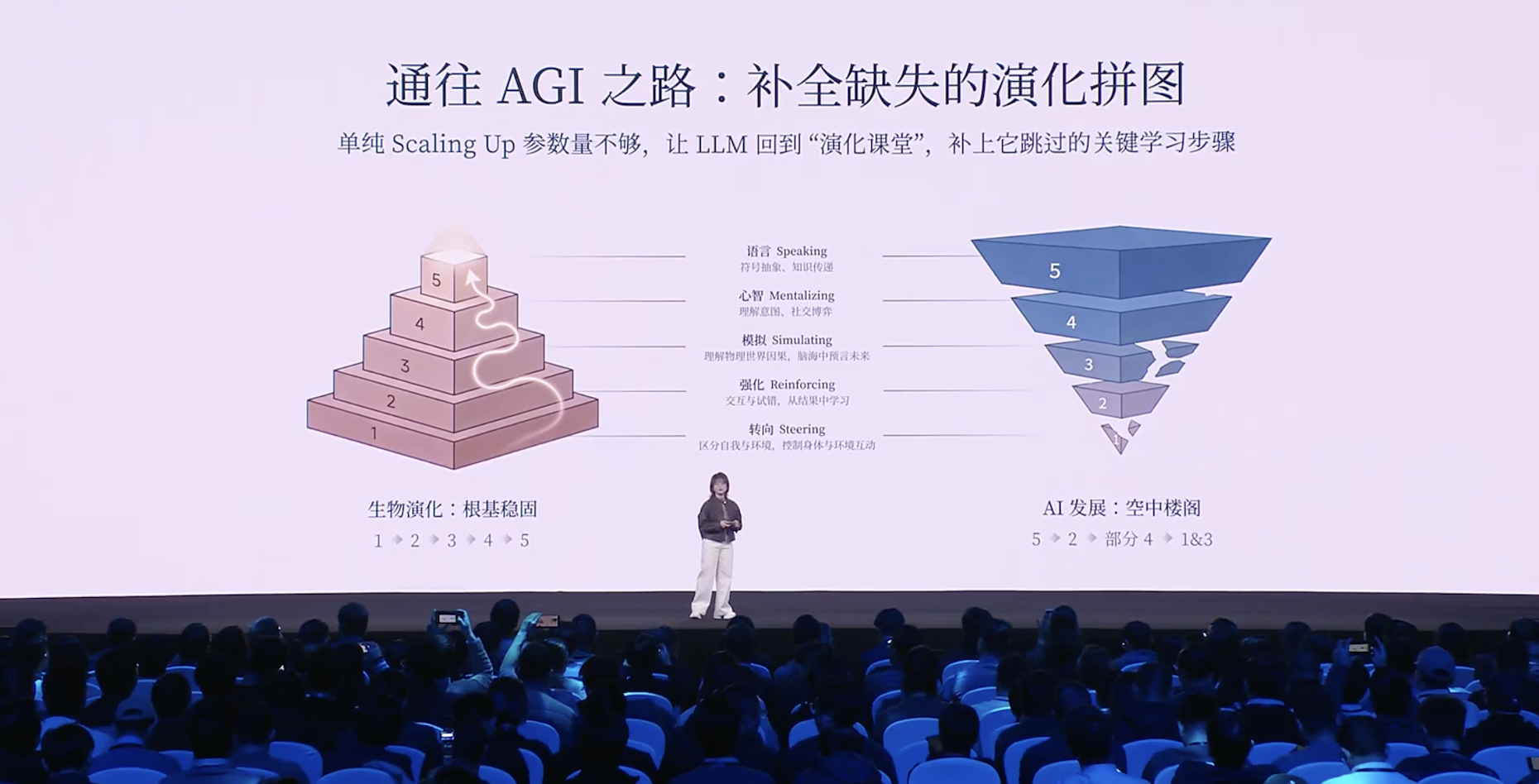
大家也能看到,这其实是一种自顶向下的捷径:模型学习到的是智能的结果,再去倒推智能产生的过程。
但不管怎么说,语言本身包含了人类对世界的极致压缩,是智慧的结晶;同时,它也是高阶智能体之间进行高效协作的关键工具。
因此,小米选择从语言出发,去构建新一代面向 Agent 的基座模型 MiMo-V2-Flash。
在研发之初,我们主要围绕三个非常关键的问题展开。
第一个,我们认为当代的智能体必须具备一种高效的沟通语言,而这种语言主要体现在代码能力和工具调用能力上。
第二个,目前智能体之间的沟通带宽其实是非常低的,我们需要思考如何去加速这种带宽。这就要求模型具备非常高的推理效率,因此我们需要围绕推理效率,重新设计模型结构。
第三个,大模型的范式正在逐步从预训练转向后训练,尤其是在强化学习阶段,需要投入更多算力 compute。这就非常依赖一个稳定、可扩展的后训练范式。
这三个问题,是我们在构建 MiMo-V2-Flash 这一代模型时,最核心关注的方向。
在这三个问题的驱动下,我们看到了 MiMo-V2-Flash 作为基座模型的巨大潜能。虽然从参数规模上看,它并不算一个“非常大的模型”,我甚至不太愿意称它为一个大模型——它的总参数量是 309B,激活参数约为 15B。
但在代码能力和 Agent 能力相关的世界级、公开且公正的评测榜单中,在我看来,它已经进入了全球开源模型的第一梯队,整体表现与 DeepSeek-V3.2、Kimi-K2-Thinking 基本相当,而这些模型的总参数规模往往是 MiMo-V2-Flash 的两到三倍。
虽然模型规模不大,但我们通过大量结构和工程优化,达到了更极致的推理效率。这里这张图展示的是,在全球同一水平线的大模型中,它们在推理价格和推理速度上的对比。
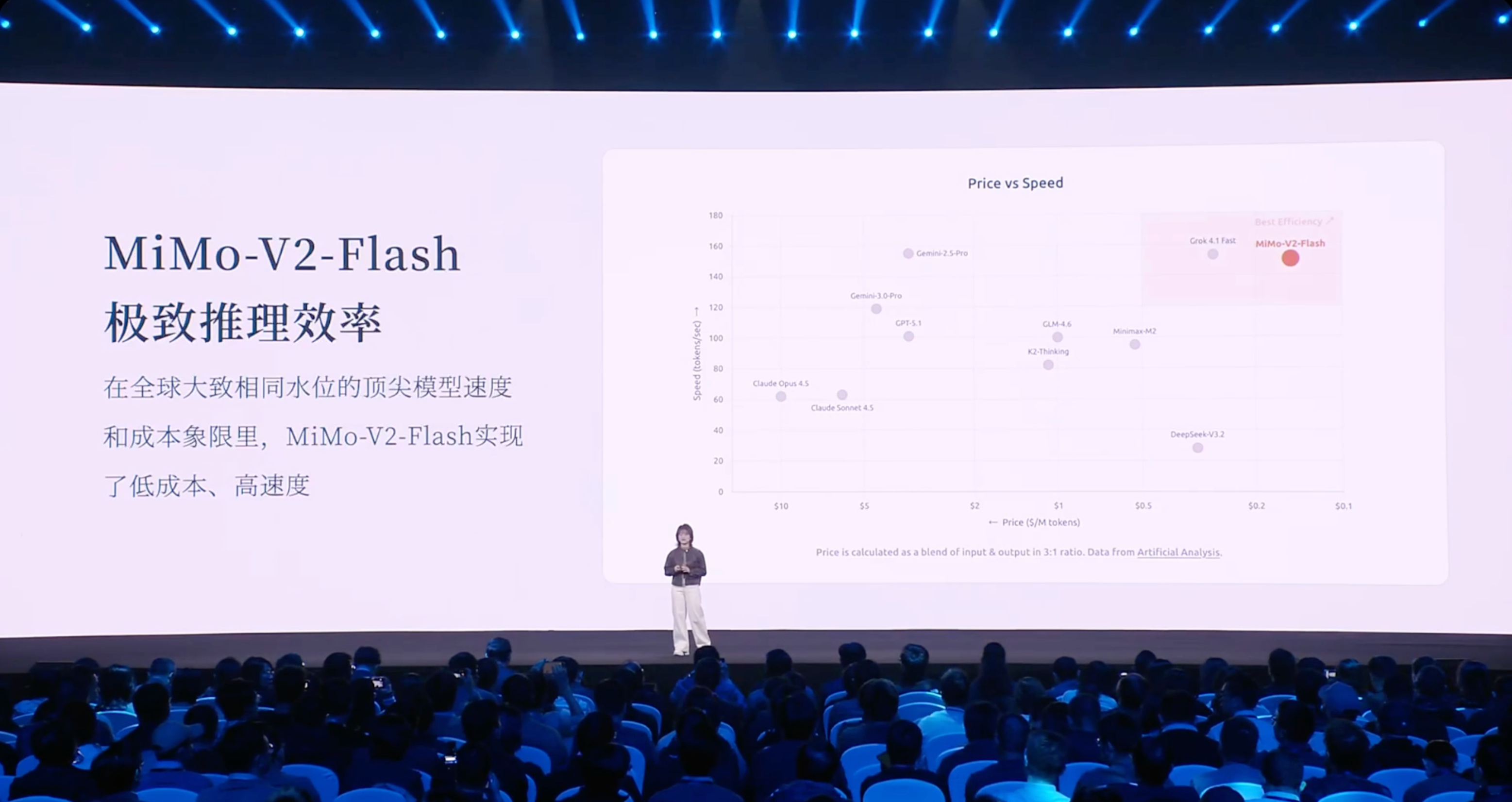
横轴是推理成本,从高到低;纵轴是推理速度,从低到高。可以看到,MiMo-V2-Flash 位于右上角,代表着低成本和高速度。
举两个 baseline 对比:
以 DeepSeek-V3.2 为例,MiMo-V2-Flash 的推理成本略低,但推理速度大约是 V3.2 的三倍左右;
再比如与综合能力相近的 Gemini 2.5 Pro 相比,MiMo-V2-Flash 的推理速度接近,但推理成本大约低了 20 倍。
那么我们是如何做到这一点的?核心在于围绕极致推理效率重新设计模型结构,主要依赖两项创新。
第一是 Hybrid Attention 结构,我们将 Sliding Window Attention 和 Full Attention 进行混合,比例大约是 5:1。
我们之所以选择 Sliding Window Attention,是因为尽管它看起来非常简单,只关注局部的 128 个 token,但通过大量实验发现,在兼顾长短文本推理和知识检索方面,它的综合表现反而优于一些复杂的注意力结构。同时,Sliding Window Attention 的 KV Cache 是固定的,非常适合现有推理基础设施。
此外,我们也进一步挖掘了 MTP(多词元预测)的潜力。
MTP 最早是作为一种推理加速方法提出的,后来 DeepSeek 将其用于提升基座模型能力。我们在预训练阶段引入 MTP 层,以提升基座模型潜能;在微调阶段加入更多 MTP 层,用很少的算力提升了模型的接受率。
最终,在推理阶段,我们使用三层 MTP 并行推理,在实际场景中实现了约 2 到 2.6 倍的推理加速。
从社区测试结果来看,在三层 MTP 的情况下,模型输出吞吐与成本高度相关。在单机环境下,吞吐可以达到 5000 到 15000 token/s,而单请求输出速度也能达到 150 token/s。相比不使用 MTP,整体速度提升约 2 到 3 倍。
在后训练阶段,我们同样围绕如何充分利用高效结构,去扩展强化学习的 compute。强化学习训练往往不稳定,因此我们提出了一种 Multi-Teacher On-Policy Distillation(MOPD)范式。

其核心在于:Student 模型基于自身概率分布进行 rollout,由多个专家模型对序列进行 token-level 的概率打分,提供非常稠密的监督信号。这种学习方式效率极高,通常只需几十步训练,就能将多个专家模型的能力蒸馏到 Student 模型中。
我们还观察到一个有趣的现象:当 Student 很快超过 Teacher 后,是否可以用 Student 替换 Teacher,继续自我迭代提升?这仍然是一个进行中的研究方向。
我们也发现,MiMo-V2-Flash 已经初步具备在语言空间中模拟世界的能力。当然,这种模拟仍然是通过语言完成的,并不是真正的物理感知。比如,它可以通过 HTML 模拟一个操作系统,或者模拟整个太阳系的运行,甚至可以用来做一些小 demo,比如画一棵圣诞树,并与用户产生交互。
昨天,MiMo-V2-Flash 已经正式发布并开源,我们同步开放了模型权重和技术报告,也提供了 API,方便开发者接入到 Web Coding、IDE 等场景中。同时,体验 Web 也已经上线,大家可以直接和模型进行交互。
但即便如此,我认为大家仍然很难放心把复杂任务完全交给模型。因为真正的下一代智能体系统,并不只是一个语言模拟器,而是需要与真实世界共存的智能体。
在我看来,下一代智能体至少需要具备两个潜能:
第一,它要从“回答问题”转向“完成任务”;
第二,它必须具备与世界交互的能力。
这也意味着,它需要具备记忆、推理、自主决策和规划等能力。
更重要的是,它需要一个统一的、动态的系统,用来理解和模拟真实世界。在此基础上,模型才能更自然地嵌入到眼镜等智能终端中,真正融入生活流。
回到大模型本身,它本质上依赖的是算力的“暴力美学”,在语言和强化学习层面取得了突破,但跳过了对世界感知、世界模拟以及实体交互等关键步骤。
这也是为什么当前模型可以解数学竞赛、模仿文学风格,却并不真正理解重力等物理概念,甚至会产生具身幻觉——它们拥有精致的语言外壳,却缺乏锚定现实世界的物理模型。
因此我认为,AI 进化的下一个关键点,一定是能够与真实环境持续交互的物理模型。真正的智能不是从文本中“读出来的”,而是要在交互中“活出来的”。
参考链接:




