
Discord 工程团队分享了他们是如何在支撑数百万并发用户的情况下,为自家的 Elixir 基础设施加入分布式追踪的。他们做了一个自定义的 “Transport” 库,把追踪上下文包在 Elixir 的消息传递机制外面,从而解决了在 actor 架构里做可观测性埋点的一个核心难题。
和基于 HTTP 的微服务不同(trace context 通常放在 header 里传递),Elixir 的 actor 模型是在进程之间直接传任意消息,本身并没有元数据这一层。Discord 希望在整个聊天系统里实现端到端的可观测性,但遇到了一个问题:OpenTelemetry 的标准追踪只能在单个服务内部生效,没法在 Elixir 进程之间传递上下文。
团队总结了三个必须满足的要求:一是对开发者足够友好,方便落地;二是既支持原始消息,也支持 GenServer 抽象;三是能够在生产环境实现无停机部署。
Discord 的方案引入了一个叫 “Envelope(信封)” 的基础结构,用来把 trace context 包进消息里。实现看起来非常简单,本质上就是一个结构体,里面包含原始消息和序列化后的 trace carrier:
defmodule Discord.Transport.Envelope do defstruct [:message, trace_carrier: []] def wrap_message(message) do %__MODULE__{ message: message, trace_carrier: :otel_propagator_text_map.inject([]) } endend
这个库提供了可以直接替换的 GenServer call 和 cast 方法,会自动把发出去的消息包一层。在接收端,通过一个 handle_message 函数统一处理旧的裸消息和新的 Envelope 消息:如果有 trace context 就提取出来,用完之后再清理掉。
这个“统一处理”的设计在上线过程中非常关键。Discord 不可能一夜之间改掉所有消息传递逻辑,也没法同时更新所有节点。这个库可以同时处理已埋点和未埋点的消息,从而支持逐步迁移,而且不需要重启服务。
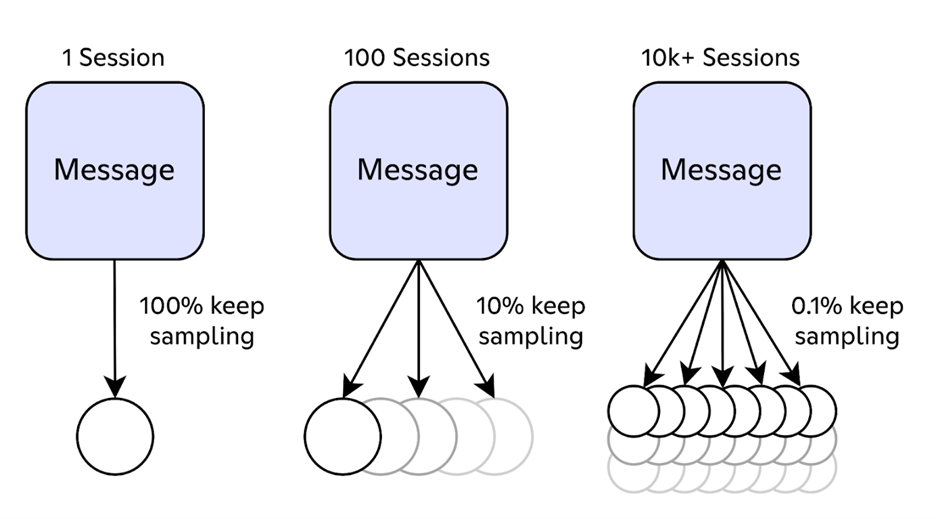
Discord 的架构在扩展性上有一些独特挑战。比如一个用户在一个有一百万在线成员的服务器里发消息,这一个带追踪的操作就可能生成一百万个子 span——每个会话一个,用来把消息转发给客户端。
团队基于 fanout(消息扩散规模)做了动态采样。发给单个用户的消息,100% 保留采样结果。发给 100 个用户时,采样率降到 10%。当接收人数超过 1 万时,只有 0.1% 的会话会记录会采样。这样既能保留有价值的追踪数据,又不会把可观测性系统压垮。
来源:Discord 博客
最初上线时,追踪带来的开销超出了 Discord 的预期。那些最活跃、拥有数百万成员的服务器,一度跟不上消息流量。性能分析发现,即使 99% 以上的操作没有被采样,进程仍然花了大量时间在解析 trace context 上。
解决方案是:只对被采样的请求传递 trace context。未采样的请求在 Envelope 里就不带 context,从而省掉序列化和解析的开销。这对传统的 head sample 语义做了一点小改动,但成功消除了 CPU 峰值问题。
第二个优化针对 sessions 服务:在 fanout 过程中记录 span 会让 CPU 使用率提高 10 个百分点。Discord 选择禁止 sessions 在接收到 fanout 消息后再开启新的 trace。它们可以继续已有的 trace,但不会自己决定是否采样。这一改动几乎消除了所有额外开销,把 CPU 使用率从 55% 降到 45%。
最显著的一次优化来自对 gRPC 请求处理的分析。在 Elixir 服务和 Discord 的 Python API 交互时,有 75% 的请求处理时间都花在解析 trace context 上。团队为此做了一个过滤器,可以直接从编码后的 trace context 字符串里读取采样标志,而不需要完整反序列化。如果没有被采样,就完全不传 context。
这套投入在最近一次故障中发挥了作用,当时某个服务器跟不上用户的活动。追踪数据显示,用户连接该服务器进程时出现了长达 16 分钟的延迟——这是一个指标和日志都很难直接看出来的用户影响。追踪还揭示了下游的连锁反应:故障期间用户甚至无法点击进入这个服务器。
Discord 工程师 Nick Krichevsky 表示,这种严重性能下降虽然很少见,但分布式追踪已经成为排查问题的关键手段——很多问题“以前根本无从下手”。
Transport 这个库代表了一种在 actor 系统中实现分布式追踪的务实做法。它不是强行套用 HTTP 那种 metadata 模式,而是直接包裹 Elixir 的消息传递机制,让 Discord 在保持原有架构优势的同时,也获得了可以支撑生产规模的可观测性。




