
经过几个月时间的开发测试工作,Katalyst 近日完成了 v0.5.0 版本的发布。在该版本中,我们解耦了 Katalyst 常态混部能力对 kubewharf enhanced kubernetes 的依赖,用户可以在原生 Kubernetes 上安装和使用 Katalyst;另外我们也对上个版本中新加入的资源超分功能做了进一步的优化。期望这个版本可以帮助用户更平滑地使用 Katalyst,实现资源效能提升。
Out-of-Band Resource Manager (ORM)
为了保证业务的 QoS 不受影响,Katalyst 最初在 kubelet 中引入了一个 QoS Resource Manager (QRM) 框架,通过插件化的方式来扩展容器的资源分配策略。虽然该方案在功能上较好地满足了字节跳动内部业务的需求,但 QRM 框架侵入修改了 kubelet,不方便使用和维护。
为此,我们近期对 Katalyst 进行了重构,将 QRM 框架从 kubelet 中解耦出来,实现了一套新的方案叫 ORM。ORM 也就是 Out-of-Band Resource Manager 的缩写,顾名思义就是带外的资源管理框架。
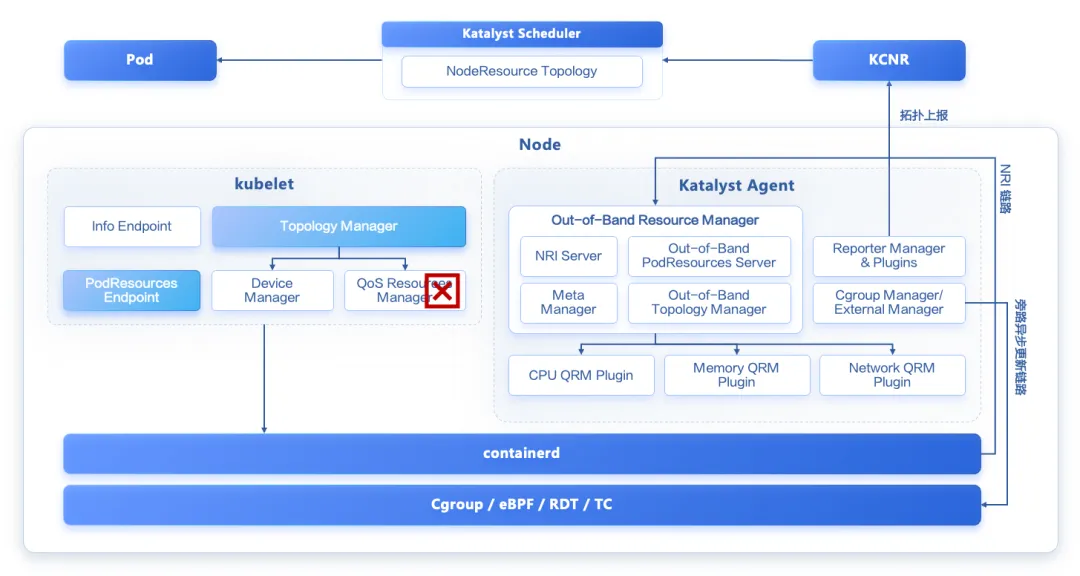
从上面的架构图中可以看到,我们将 QRM 从 kubelet 中移除,在 Katalyst Agent 中新增了一个 ORM 模块。
在注入资源管理策略的 Hook 点的选择上,不同于 QRM,v0.5.0 中新增的 ORM 支持两种模式:NRI 模式(v0.6.0 上线)和旁路异步更新模式。我们在 ORM 中实现了一个 NRI 的 Server,当 Pod 或容器的一些生命周期事件(如 RunPodSandbox/CreateContainer/RemovePodSandbox 等)发生时,containerd 会同步调用 ORM 的 NRI Server,从而实现资源管理策略的注入。此外,对于 containerd 版本比较低的场景,ORM 也提供了一种 Bypass 模式,周期性从旁路异步更新容器的 Cgroup 等配置。
在 NUMA 亲和的实现方式上,因为我们将 QRM 从 kubelet 中解耦出来了,不能再复用 Topology Manager 的撮合能力,因此我们在 ORM 中实现了一个带外的 Topology Manager。此外,解耦之后 kubelet 原生的 PodResources API 返回的数据也和实际的分配情况不一致了,所以我们在 ORM 中也实现了一个带外的 PodResources Server,从而像 Reporter 这样的模块可以从中获取到准确的 CPU 和内存的分配情况,上报到 KCNR CRD 中供调度器感知。
在混部场景下,运行以下命令可以通过 Helm 安装启用了 ORM 的 Katalyst:
helm repo add kubewharf https://kubewharf.github.io/chartshelm repo updatehelm install colocation -n katalyst-system --create-namespace kubewharf/katalyst-colocation-ormORM 相关的配置项在 charts/katalyst/charts/colocation-orm/values.yaml 文件中,主要包括:
katalyst-agent:customArgs:# QRM Plugin 注册的 Socket 路径,改为注册到 ORMqrm-socket-dirs: "/var/lib/katalyst/plugin-socks"
katalyst-agent: customArgs: # QRM Plugin 注册的 Socket 路径,改为注册到 ORM qrm-socket-dirs: "/var/lib/katalyst/plugin-socks" # Reporter 访问 PodResources API 的 Socket 路径,改为访问 ORM 旁路的 PodResources Server pod-resources-server-endpoint: "/var/lib/katalyst/pod-resources/kubelet.sock" # ORM 旁路的 PodResources Server 从何处获取 Device 的分配信息。默认值为 "";可配置为 "kubelet",表示 ORM 从 kubelet 原生的 PodResources Server 获取 Device 的分配信息 orm-devices-provider: "kubelet" # 如果将 orm-devices-provider 配置为 kubelet,则可通过该配置指定 kubelet 原生的 PodResources Server 的 Socket 路径 orm-kubelet-pod-resources-endpoints: "/var/lib/kubelet/pod-resources/kubelet.sock" # ORM 旁路的 Topology Manager 的 NUMA 亲和策略,可选值:none / best-effort / restricted / single-numa-node / numeric topology-policy-name: "none" # ORM 的资源名映射,比如将 Reclaimed Resources 映射到 cpu、memory 等原生的资源名 orm-resource-names-map: "resource.katalyst.kubewharf.io/reclaimed_millicpu=cpu,resource.katalyst.kubewharf.io/reclaimed_memory=memory"资源超分
在 v0.4.0 中,Katalyst 发布了在线超分功能,用户可以为节点池配置超分比来实现整机的资源超售。但实际的集群运营过程中,通过人工进行静态超分比配置会带来一些风险:
由于 Pod 在节点间的扩缩行为以及业务流量的变化,导致配置的超分比不符合预期,节点出现负载过高的问题;
用户在 kubelet 开启了 CPUManager,绑核行为导致共享池的 CPU 资源被过度超分。
针对以上问题,Katalyst 对超分能力进行了扩展,基于节点实时监控指标以及绑定 CPU 数量对超分比进行动态调整,在提升利用率的同时规避过度超分的风险。
动态超分
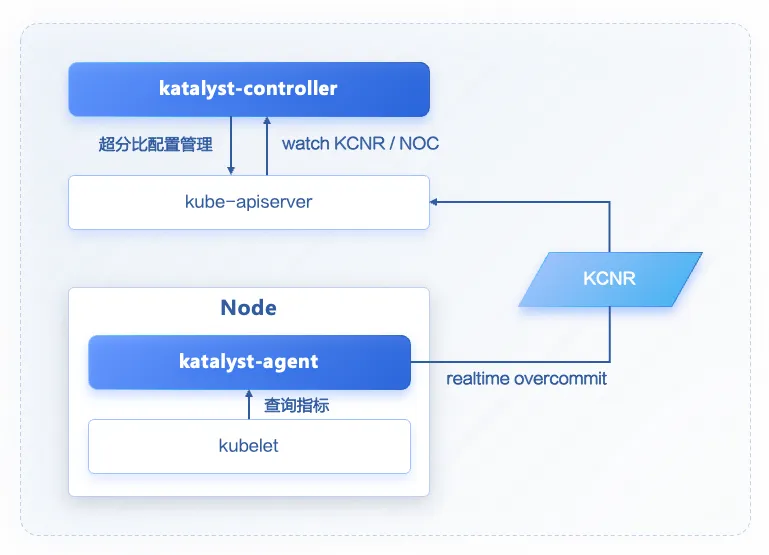
Katalyst-agent:Katalyst-agent 通过监控组件(malachite)查询节点 pod 实时指标,并根据指标与配置预估节点的超分比,通过 KCNR 进行上报。
Katalyst-controller:Katalyst-controller watch 并缓存 KCNR(实时超分比)与 NOC(用户超分配置),选择更小的超分比计算节点的超分后资源并进行更新。
兼容原生绑核能力
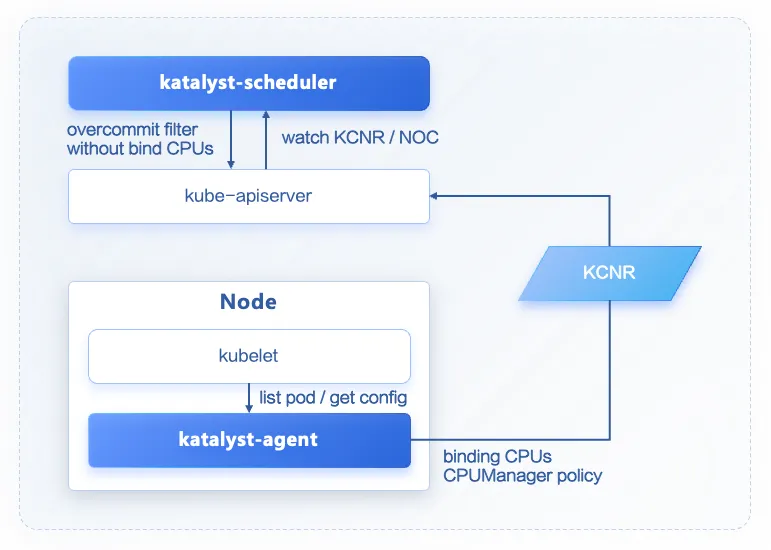
Katalyst-agent:Katalyst-agent 通过查询 kubelet config 获取 CPUManager 的状态,当 CPUManager 开启并且 policy=static 时,katalyst-agent 统计节点所有 pod 独占 CPU 的数量(具有整数型 CPU requests 的 Guaranteed Pod),并通过 KCNR 上报相关信息。
Katalyst-scheduler:Katalyst-scheduler watch 并缓存节点的 KCNR。
当节点 CPUManager 开启并且 policy=static 时,被独占的 CPU 不会被超分,只有共享资源池中的 CPU 会根据超分比进行放大;同时,新调度的 pod 如果需要独占 CPU,其需要占用的 CPU 资源也不允许通过超分比进行放大。
使用
● 部署监控与资源超分组件
helm repo add kubewharf https://kubewharf.github.io/chartshelm repo update# 部署malachite监控组件helm install malachite -n malachite-system --create-namespace kubewharf/malachite# 部署katalyst超分组件helm install overcommit -n katalyst-system --create-namespace kubewharf/katalyst-overcommitkubectl get deployment -n katalyst-systemNAME READY UP-TO-DATE AVAILABLEkatalyst-controller 2/2 2 2 katalyst-webhook 2/2 2 2 katalyst-scheduler 2/2 2 2kubectl get daemonset -n katalyst-systemNAME DESIRED CURRENT READY UP-TO-DATE AVAILABLEkatalyst-agent 3 3 3 3 3可以看到 katalyst-webhook、katalyst-controller、katalyst-scheduler 以及 katalyst-agent 组件被部署完成。
● 使用动态超分
1. 动态超分配置
可在 charts/katalyst/charts/overcommit/values.yaml 中通过 katalyst-agent.customArgs 对节点的动态超分比计算进行配置:
# 通过修改参数为"-overcommit_aware"可以关闭katalyst-agent中的超分计算与上报功能sysadvisor-plugins: "overcommit_aware"# 动态超分比计算周期,默认每10秒进行一次计算并上报realtime-overcommit-sync-period: "10s"# 节点CPU目标负载,表示在当前的pod分配情况下,通过超分比将节点预期的CPU负载调整至目标值realtime-overcommit-CPU-targetload: 0.6# 节点内存目标负载,表示在当前的pod分配情况下,通过超分比将节点预期的内存负载调整至目标值realtime-overcommit-mem-targetload: 0.6# 集群pod预估CPU负载,节点未分配的CPU资源会基于节点当前负载与这个参数进行超分realtime-overcommit-estimated-cpuload: 0.4# 集群pod预估内存负载,节点未分配的内存资源会基于节点当前负载与这个参数进行超分realtime-overcommit-estimated-memload: 0.6# 计算CPU超分使用的负载指标,支持cpu.usage.containerCPU-metrics-to-gather: "cpu.usage.container"# 计算内存超分使用的负载指标,支持mem.rss.container、mem.usage.container# 默认使用rss内存,建议根据集群内存使用情况进行指标与目标负载的配置memory-metrics-to-gather: "mem.rss.container"2. 观察测试节点 KCNR,可以看到增加了超分相关的 annotation 信息
kubectl describe kcnr node1...Annotations: # 根据负载计算的CPU超分比 katalyst.kubewharf.io/cpu_overcommit_ratio: "1.54" # 根据负载计算的内存超分比 katalyst.kubewharf.io/memory_overcommit_ratio: "1.93" # 节点当前已经绑核的CPU数量 katalyst.kubewharf.io/guaranteed_cpus: "0" # 节点 kubelet CPUManager policy katalyst.kubewharf.io/overcommit_cpu_manager: "static" # 节点 kubelet memoryManager policy katalyst.kubewharf.io/overcommit_memory_manager: "None"... 3. 观察 Node 对象,发现相比静态超分场景,节点 annotation 新增了部分超分与资源信息
可以看到,实际超分后的资源量通过节点计算并上报的超分比计算得到。由于该值相比于配置值更小,规避了可能出现的过度超分风险。
apiVersion: v1kind: Nodemetadata: annotations: # 节点根据负载计算的CPU超分比 katalyst.kubewharf.io/realtime_cpu_overcommit_ratio: "1.51" # 节点根据负载计算的内存超分比 katalyst.kubewharf.io/realtime_memory_overcommit_ratio: "1.93" # 手动配置的 CPU 超分比 katalyst.kubewharf.io/cpu-overcommit-ratio: "2.5" # 手动配置的 Memory 超分比 katalyst.kubewharf.io/memory-overcommit-ratio: "2.5" spec: ...status: # 超分后的资源量 allocatable: cpu: 11778m memory: 56468160982220m capacity: cpu: 12080m memory: 64452751810560m ...4. 指定节点创建一个高负载 pod,观察节点超分比变化
由于 CPU 负载升高,katalyst-agent 计算得到了更小的超分比,节点可用资源进一步降低,避免更多负载调度到节点上。
apiVersion: v1kind: Podmetadata: name: testpod1 namespace: katalyst-system...spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - node1 containers: - name: testcontainer1 image: polinux/stress:latest command: ["stress"] args: ["--cpu", "4", "--timeout", "6000"] resources: limits: cpu: 8 memory: 8Gi requests: cpu: 4 memory: 8Gi tolerations: - effect: NoSchedule key: test value: test operator: Equalkubectl describe kcnr node1Annotations: # 由于负载升高,katalyst-agent计算得到超分比减小 katalyst.kubewharf.io/cpu_overcommit_ratio: 1.00 katalyst.kubewharf.io/guaranteed_cpus: 0 katalyst.kubewharf.io/memory_overcommit_ratio: 1.93 katalyst.kubewharf.io/overcommit_cpu_manager: static katalyst.kubewharf.io/overcommit_memory_manager: None其他更新
API 扩展
CNR 支持 socket-level 设备亲和性上报;
SPD 支持扩展 extended-indicator,方便外部系统自定义画像能力。
QoS 增强
share-cores with numa-binding 精细化微拓扑分配能力达到生产可用状态。
策略扩展
内存:支持 drop cache、TMO、动态跨 NUMA 迁移内存页、基于 min/max 实现内存保护 等策略;
IO:引入 io.cost,io.weight,wbt,根据优先级针对不同负载进行 IO 限速;
基于原生 fake-numa 机制实现自定义 NUMA 调度、分配和内存带宽限制能力。
单机组件
metrics-fetcher:和 malachite 解耦,并支持对接 cgroup,kubelet stats 等多种不同的数据源;metrics 增加采集时间戳并支持数据过期检查;
reporter:支持实时上报 node-metrics 到 CNR,配合调度器实现基于负载的重调度能力;
meta-server:优化单机查询 SPD 频率,避免对 APIServer QPS 过高而引发的稳定性风险;
单机组件 healthz 接口集成各个模块核心功能健康检查,并接入 readiness-check。
中心组件
controller(s):支持 transformed-informer 机制优化中心组件内存占用;
recommender:原生规格推荐推荐能力增强并实现和 vpa 体系的集成;
KCMAS:支持根据 metric label 进行分组聚合查询;
此外,也修复了 goroutine 泄漏、gRPC 连接泄漏,nil allocation-info 导致 panic 等若干问题。
非常期待更多开发者和用户能加入到 Katalyst 开源社区中,和我们一起交流和探讨在离线混部以及资源效能的相关话题。如需开源交流,添加字节跳动云原生小助手,加入云原生社群:




