
Snowflake AI 研究团队发布的创新技术 SwiftKV,可显著降低企业级大语言模型(LLM)工作负载的计算成本。该方案已开源并上线 Hugging Face 平台。本期简报将深入解析 SwiftKV 的革命性突破及其对行业发展的实际影响。
什么是 Tokens、输入处理?它们又是如何影响计算成本的?
在企业级大型语言模型工作负载中,输入 tokens(即提示文本)的数量通常远超过输出 tokens(即生成内容)。输入 tokens 指提供给模型的文本(如指令或上下文),输出 tokens 则是模型生成的响应。
Token 是模型处理的基本文本单位,可以是一个单词或单词的组成部分。由于输入处理(预填充计算)主导了计算成本,优化该环节对提升效率至关重要。
以下典型企业级大型语言模型任务通常使用长提示文本,但仅生成少量输出 tokens:
● 代码补全:向模型提供部分代码片段或函数(输入),要求其生成剩余部分(输出);
● 文本转 SQL:以自然语言提出英文问题(用户输入),并附带相关表的语义信息(如系统输入的模式结构、列描述等),模型据此生成对应 SQL 查询(输出);
● 文本摘要:输入长文本(如完整文档),要求生成简洁摘要(输出);
● 检索增强生成:提出问题时(用户输入),系统会扫描多个知识源进行检索(检索输入),最终基于检索信息生成响应(输出)。
Snowflake AI 研究团队观察到,许多企业级大型语言模型应用场景中,提示词 tokens 与生成 tokens 的比例达到了 10:1。这意味着,输入提示词中每 10 个 tokens,模型仅生成 1 个 token 作为回应。因此,大型语言模型的计算成本中有相当一部分都与输入提示词的处理密切相关。

图 1:运行于 Snowflake Cortex 上的各类大型语言模型推理任务中输入与输出 token 长度对比,显示输入 token 数量
超过输出 token 数量的 10 倍以上
SwiftKV 的工作原理是什么?
大型语言模型由多层 Transformer 模块构成。这些 Transformer 层的关键组件之一是键值缓存,用于存储每个 Transformer 层产生的中间输出(即 keys 和 values)。在输入处理过程中,系统会为提示文本中的每个 token 计算键值缓存,随后将其存储并在输出 token 生成时重复使用。每个 Transformer 层的键值缓存通过轻量级的矩阵乘法(使用投影矩阵)计算得出。虽然该投影运算本身计算量较小,但投影矩阵的输入依赖于前一 Transformer 层的输出——而这项计算却极具成本。
由于提示文本的平均长度通常是输出的 10 倍,为输入提示生成键值缓存的过程主导了整体推理计算量。为此我们推出 SwiftKV 技术,其中包含名为 SingleInputKV 的创新方法:通过利用 Transformer 层输出随网络深度变化趋缓的经典观测现象,使用浅层输出结果直接通过轻量投影为后续多个层级生成键值缓存,从而显著减少键值缓存的计算负担。
通过跳过深层 Transformer 层的计算密集型操作,SingleInputKV 在输入提示处理阶段实现了 50% 的计算量降低。这使得提示处理速度显著提升,同时大幅优化了计算成本。
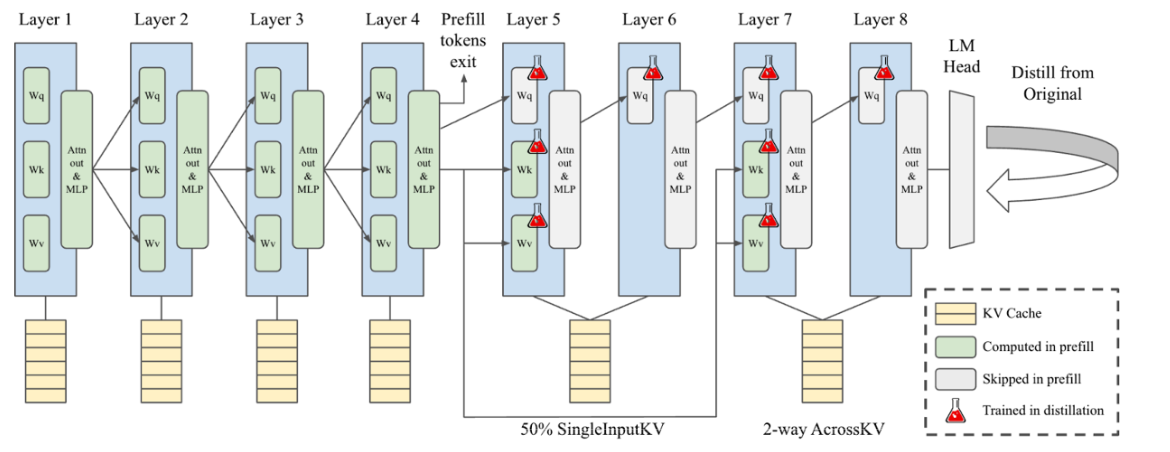
图 2. SwiftKV 对基于 Transformer 架构的大型语言模型进行重构,通过 SingleInputKV 减少预填充阶段计算量,利用 AcrossKV 压缩键值缓存,并采用轻量化蒸馏进行知识恢复。 具体而言,在本示例中,SingleInputKV 通过复用第 4 层产生的键值缓存,直接生成第 5 至 8 层的键值缓存,从而显著降低了预填充阶段的计算开销
什么是 SwiftKV 技术带来的端到端提升?
通过将 SingleInputKV 技术应用于 50% 的 Transformer 层,我们实现了预填充阶段计算量近 2 倍的降低。鉴于输入处理在推理工作负载中占主导地位,这一改进可转化为端到端吞吐量最高 2 倍的提升。

图 3:SwiftKV 的推理吞吐量提升效果
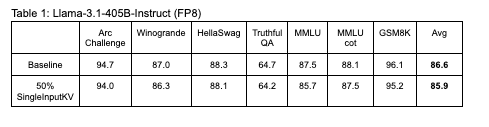
尽管吞吐量提升显著,但精度的折衷依然微乎其微,如表 1 所示。
使用方法
我们很高兴向社区开放 SwiftKV 的使用权限。以下是快速入门指南——
模型检查点:SwiftKV 模型检查点可通过 Hugging Face 获取:
● SwiftKV Llama 3.1-70B (coming soon)
使用 vLLM 进行推理:我们已将 SwiftKV 优化集成至 vLLM 以提升推理效率。如需通过 vLLM 体验这些模型,请使用我们专设的 vLLM 分支(目前正在推进上游合并),代码库位于 getting-started instructions。
训练专属 SwiftKV 模型:希望针对具体任务定制 SwiftKV?请关注我们即将发布的后训练库 ArcticTraining 中的 SwiftKV 知识蒸馏方案(即将推出)。
原文地址:
点击链接立即报名注册:Ascent - Snowflake Platform Training - China




