本系列文章从一个全新的视角来思考 web 性能优化与前端工程之间的关系,通过解读百度前端集成解决方案小组(F.I.S)在打造高性能前端架构并统一百度 40 多条前端产品线的过程中所经历的技术尝试,揭示前端性能优化在前端架构及开发工具设计层面的实现思路。
在上一部分,我们介绍了静态资源版本更新与缓存。今天的部分将会介绍静态资源管理与模板框架的用法。
静态资源管理与模板框架
让我们再来看看前面的优化原则表还剩些什么:
优化方向
优化手段
请求数量
合并脚本和样式表,拆分初始化负载
请求带宽
移除重复脚本
缓存利用
使Ajax 可缓存
页面结构
将样式表放在顶部,将脚本放在底部,尽早刷新文档的输出
很不幸,剩下的优化原则都不是使用工具就能很好实现的。或许有人会辩驳:“我用某某工具可以实现脚本和样式表合并”。嗯,必须承认,使用工具进行资源合并并替换引用或许是一个不错的办法,但在大型web 应用,这种方式有一些非常严重的缺陷,来看一个很熟悉的例子:

某个web 产品页面有A、B、C 三个资源
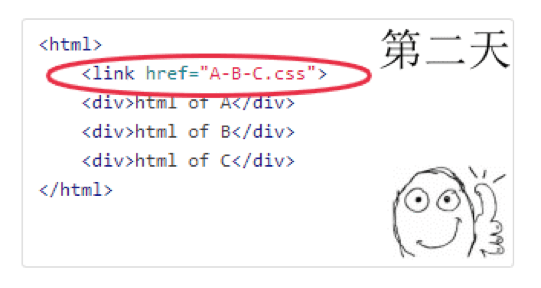
工程师根据“减少HTTP 请求”的优化原则合并了资源
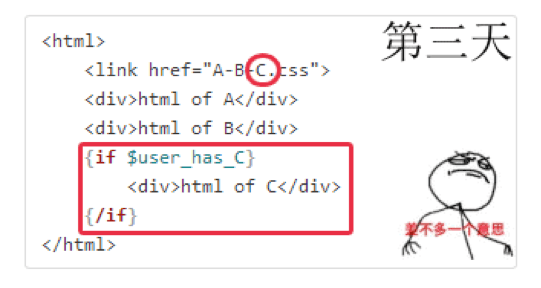
产品经理要求C 模块按需出现,此时C 资源已出现多余的可能

C 模块不再需要了,注释掉吧!但 C 资源通常不敢轻易剔除
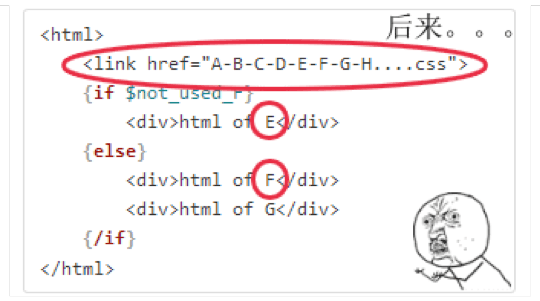
不知不觉中,性能优化变成了性能恶化……
事实上,使用工具在线下进行静态资源合并是无法解决资源按需加载的问题的。如果解决不了按需加载,则势必会导致资源的冗余;此外,线下通过工具实现的资源合并通常会使得资源加载和使用的分离,比如在页面头部或配置文件中写资源引用及合并信息,而用到这些资源的 html 组件写在了页面其他地方,这种书写方式在工程上非常容易引起维护不同步的问题,导致使用资源的代码删除了,引用资源的代码却还在的情况。因此,在工业上要实现资源合并至少要满足如下需求:
- 确实能减少 HTTP 请求,这是基本要求(合并)
- 在使用资源的地方引用资源(就近依赖),不使用不加载(按需)
- 虽然资源引用不是集中书写的,但资源引用的代码最终还能出现在页面头部(css)或尾部(js)
- 能够避免重复加载资源(去重)
将以上要求综合考虑,不难发现,单纯依靠前端技术或者工具处理是很难达到这些理想要求的。现代大型 web 应用所展示的页面绝大多数都是使用服务端动态语言拼接生成的。有的产品使用模板引擎,比如 smarty、velocity,有的则干脆直接使用动态语言,比如 php、python。无论使用哪种方式实现,前端工程师开发的 html 绝大多数最终都不是以静态的 html 在线上运行的。
接下来我会讲述一种新的模板架构设计,用以实现前面说到那些性能优化原则,同时满足工程开发和维护的需要,这种架构设计的核心思想就是:
基于依赖关系表的静态资源管理系统与模板框架设计
考虑一段这样的页面代码:

根据资源合并需求中的第二项,我们希望资源引用与使用能尽量靠近,这样将来维护起来会更容易一些,因此,理想的源码是:

当然,把这样的页面直接送达给浏览器用户是会有严重的页面闪烁问题的,所以我们实际上仍然希望最终页面输出的结果还是如最开始的截图一样,将 css 放在头部输出。这就意味着,页面结构需要有一些调整,并且有能力收集资源加载需求,那么我们考虑一下这样的源码:
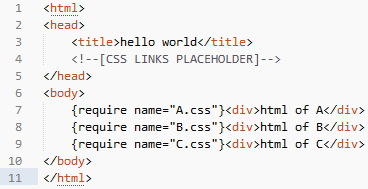
在页面的头部插入一个 html 注释“<!–[CSS LINKS PLACEHOLDER]–>”作为占位,而将原来字面书写的资源引用改成模板接口(require)调用,该接口负责收集页面所需资源。require 接口实现非常简单,就是准备一个数组,收集资源引用,并且可以去重。最后在页面输出的前一刻,我们将 require 在运行时收集到的“A.css”、“B.css”、“C.css”三个资源拼接成 html 标签,替换掉注释占位“”,从而得到我们需要的页面结构。
经过 fis 团队的总结,我们发现模板层面只要实现三个开发接口,既可以比较完美的实现目前遗留的大部分性能优化原则,这三个接口分别是:
- require(String id):收集资源加载需求的接口,参数是资源 id。
- widget(String template_id):加载拆分成小组件模板的接口。你可以叫它为 load、component 或者 pagelet 之类的。总之,我们需要一个接口把一个大的页面模板拆分成一个个的小部分来维护,最后在原来的大页面以组件为单位来加载这些小部件。
- script(String code):收集写在模板中的 js 脚本,使之出现的页面底部,从而实现性能优化原则中的“将 js 放在页面底部”原则。
实现了这些接口之后,一个重构后的模板页面的源代码可能看起来就是这样的了:

而最终在模板解析的过程中,资源收集与去重、页面 script 收集、占位符替换操作,最终从服务端发送出来的 html 代码为:

不难看出,我们目前已经实现了“按需加载”,“将脚本放在底部”,“将样式表放在头部”三项优化原则。
前面讲到静态资源在上线后需要添加 hash 戳作为版本标识,那么这种使用模板语言来收集的静态资源该如何实现这项功能呢?答案是:静态资源依赖关系表。
假设前面讲到的模板源代码所对应的目录结构为下图所示:
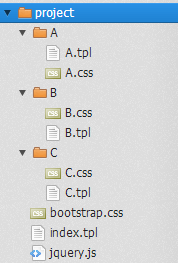
那么我们可以使用工具扫描整个 project 目录,然后创建一张资源表,同时记录每个资源的部署路径,可以得到这样的一张表:

基于这张表,我们就很容易实现 {require name=”id”} 这个模板接口了。只须查表即可。比如执行{require name=”jquery.js”},查表得到它的 url 是“/jquery_9151577.js”,声明一个数组收集起来就好了。这样,整个页面执行完毕之后,收集资源加载需求,并替换页面的占位符,即可实现资源的 hash 定位,得到:

接下来,我们讨论如何在基于表的设计思想上是如何实现静态资源合并的。或许有些团队使用过 combo 服务,也就是我们在最终拼接生成页面资源引用的时候,并不是生成多个独立的 link 标签,而是将资源地址拼接成一个 url 路径,请求一种线上的动态资源合并服务,从而实现减少 HTTP 请求的需求,比如:
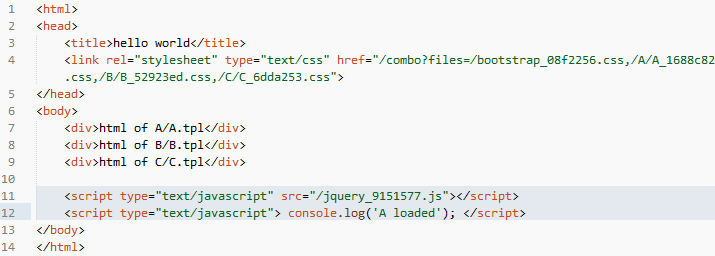
这个“/combo?files=file1,file2,file3,…”的 url 请求响应就是动态 combo 服务提供的,它的原理很简单,就是根据 get 请求的 files 参数找到对应的多个文件,合并成一个文件来响应请求,并将其缓存,以加快访问速度。
这种方法很巧妙,有些服务器甚至直接集成了这类模块来方便的开启此项服务,这种做法也是大多数大型 web 应用的资源合并做法。但它也存在一些缺陷:
- 浏览器有 url 长度限制,因此不能无限制的合并资源。
- 如果用户在网站内有公共资源的两个页面间跳转访问,由于两个页面的 combo 的 url 不一样导致用户不能利用浏览器缓存来加快对公共资源的访问速度。
对于上述第二条缺陷,可以举个例子来看说明:
- 假设网站有两个页面 A 和 B
- A 页面使用了 a,b,c,d 四个资源
- B 页面使用了 a,b,e,f 四个资源
- 如果使用 combo 服务,我们会得:
- A 页面的资源引用为:/combo?files=a,b,c,d
- B 页面的资源引用为:/combo?files=a,b,e,f
- 两个页面引用的资源是不同的 url,因此浏览器会请求两个合并后的资源文件,跨页面访问没能很好的利用 a、b 这两个资源的缓存。
很明显,如果 combo 服务能聪明的知道 A 页面使用的资源引用为“/combo?files=a,b”和“/combo?files=c,d”,而 B 页面使用的资源引用为“/combo?files=a,b”,“/combo?files=e,f”就好了。这样当用户在访问 A 页面之后再访问 B 页面时,只需要下载 B 页面的第二个 combo 文件即可,第一个文件已经在访问 A 页面时缓存好了的。
基于这样的思考,fis 在资源表上新增了一个字段,取名为“pkg”,就是资源合并生成的新资源,表的结构会变成:

相比之前的表,可以看到新表中多了一个 pkg 字段,并且记录了打包后的文件所包含的独立资源。这样,我们重新设计一下{require name=”id”}这个模板接口:在查表的时候,如果一个静态资源有pkg字段,那么就去加载 pkg**** 字段所指向的打包文件,否则加载资源本身。比如执行{require name=”bootstrap.css”},查表得知 bootstrap.css 被打包在了“p0”中,因此取出 p0 包的 url“/pkg/utils_b967346.css”,并且记录页面已加载了“bootstrap.css”和“A/A.css”两个资源。这样一来,之前的模板代码执行之后得到的 html 就变成了:
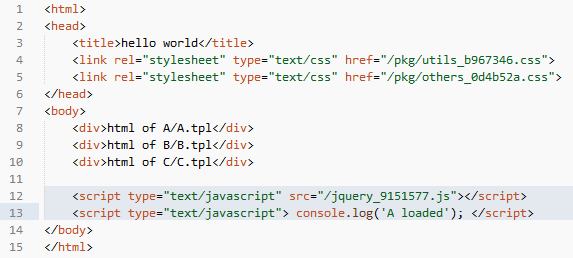
css 资源请求数由原来的 4 个减少为 2 个。
这样的打包结果是怎么来的呢?答案是配置得到的。
我们来看一下带有打包结果的资源表的 fis 配置:

我们将“bootstrap.css”、“A/A.css”打包在一起,其他 css 另外打包,从而生成两个打包文件,当页面需要打包文件中的资源时,模块框架就会收集并计算出最优的资源加载结果,从而解决静态资源合并的问题。
这样做的原因是为了弥补 combo 在前面讲到的两点技术上的不足而设计的。但也不难发现这种打包策略是需要配置的,这就意味着维护成本的增加。但好在它有两个优势可以一定程度上弥补这个问题:
- 打包的资源只是原来独立资源的备份。打包与否不会导致资源的丢失,最多是没有合并的很好而已。
- 配置可以由工程师根据经验人工维护,也可以由统计日志生成,这为性能优化自适应网站设计提供了非常好的基础。
关于第二点,fis 有这样辅助系统来支持自适应打包算法:
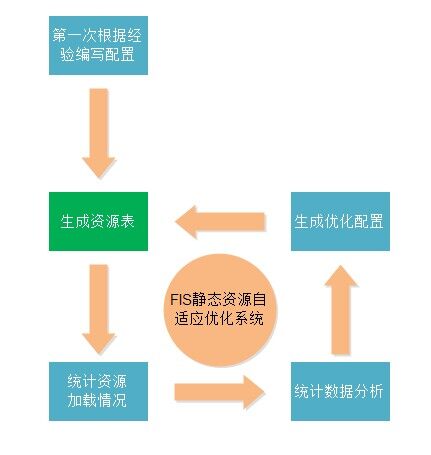
至此,我们通过基于表的静态资源管理系统和三个模板接口实现了几个重要的性能优化原则,现在我们再来回顾一下前面的性能优化原则分类表,剔除掉已经做到了的,看看还剩下哪些没做到的:
优化方向
优化手段
请求数量
拆分初始化负载
缓存利用
使 Ajax 可缓存
页面结构
尽早刷新文档的输出
“拆分初始化负载”的目标是将页面一开始加载时不需要执行的资源从所有资源中分离出来,等到需要的时候再加载。工程师通常没有耐心去区分资源的分类情况,但我们可以利用组件化框架接口来帮助工程师管理资源的使用。还是从例子开始思考:
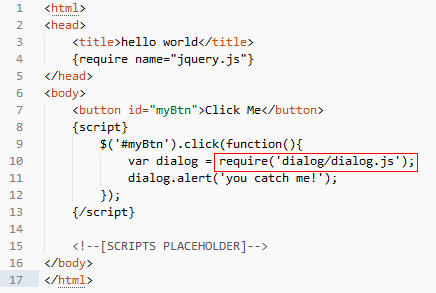
模板源代码
在 fis 给百度内部团队开发的架构中,如果这样书写代码,页面最终的执行结果会变成:
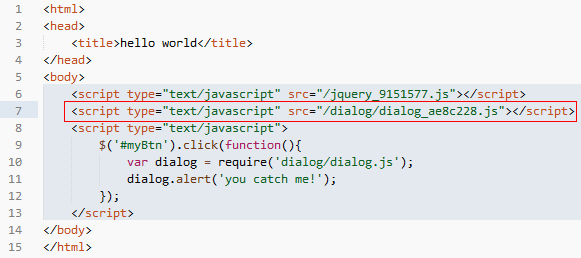
模板运行后输出的 html 代码
fis 系统会分析页面中 require(id) 函数的调用,并将依赖关系记录到资源表对应资源的deps字段中,从而在页面渲染查表时可以加载依赖的资源。但此时 dialog.js 是以 script 标签的形式同步加载的,这样会在页面初始化时出现资源的浪费。因此,fis 团队提供了 require.async 的接口,用于异步加载一些资源,源码修改为:

这样书写之后,fis 系统会在表里以async字段来标准资源依赖关系是异步的。fis 提供的静态资源管理系统会将页面输出的结果修改为:
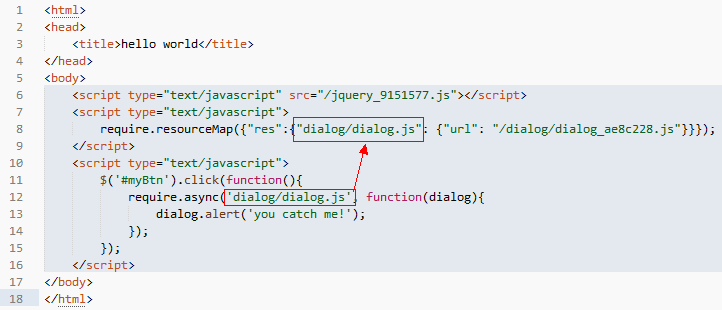
dialog.js 不会在页面以 script src 的形式输出,而是变成了资源注册,这样,当页面点击按钮触发 require.async 执行的时候,async 函数才会查表找到资源的 url 并加载它,加载完毕后触发回调函数。
到目前为止,我们又以架构的形式实现了一项优化原则(拆分初始化负载),回顾我们的优化分类表,现在仅有两项没能做到了:
优化方向
优化手段
缓存利用
使 Ajax 可缓存
页面结构
尽早刷新文档的输出
剩下的两项优化原则要做到并不容易,真正可缓存的 Ajax 在现实开发中比较少见,而尽早刷新文档的输出的情况 facebook 在 2010 年的 velocity 上提到过,就是 BigPipe 技术。当时 facebook 团队还讲到了 Quickling 和 PageCache 两项技术,其中的 PageCache 算是比较彻底的实现 Ajax 可缓存的优化原则了。fis 团队也曾与某产品线合作基于静态资源表、模板组件化等技术实现了页面的 PipeLine 输出、以及 Quickling 和 PageCache 功能,但最终效果没有达到理想的性能优化预期,因此这两个方向尚在探索中,相信在不久的将来会有新的突破。
总结
 其实在前端开发工程管理领域还有很多细节值得探索和挖掘,提升前端团队生产力水平并不是一句空话,它需要我们能对前端开发及代码运行有更深刻的认识,对性能优化原则有更细致的分析与研究。fis 团队一直致力于从架构而非经验的角度实现性能优化原则,解决前端工程师开发、调试、部署中遇到的工程问题,提供组件化框架,提高代码复用率,提供开发工具集,提升工程师的开发效率。在前端工业化开发的所有环节均有可节省的人力成本,这些成本非常可观,相信现在很多大型互联网公司也都有了这样的共识。
其实在前端开发工程管理领域还有很多细节值得探索和挖掘,提升前端团队生产力水平并不是一句空话,它需要我们能对前端开发及代码运行有更深刻的认识,对性能优化原则有更细致的分析与研究。fis 团队一直致力于从架构而非经验的角度实现性能优化原则,解决前端工程师开发、调试、部署中遇到的工程问题,提供组件化框架,提高代码复用率,提供开发工具集,提升工程师的开发效率。在前端工业化开发的所有环节均有可节省的人力成本,这些成本非常可观,相信现在很多大型互联网公司也都有了这样的共识。
本文只是将这个领域中很小的一部分知识的展开讨论,抛砖引玉,希望能为业界相关领域的工作者提供一些不一样的思路。欢迎关注 fis 项目,对本文有任何意见或建议都可以在 fis 开源项目中进行反馈和讨论。
作者简介:张云龙,百度公司 Web 前端研发部前端集成解决方案小组的技术负责人,目前负责 F.I.S 项目,读者可以关注他的微博: http://weibo.com/fouber/ 。
感谢崔康对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




