
GitHub 的工程师近期排查发现,用户反馈意外出现了“请求过多(Too Many Requests)”错误,其根源在于部分滥用防护规则在触发其生效的安全事件结束后,仍被意外长期启用。
据GitHub说明,受影响的用户并非产生了高流量请求,只是“发起了少量常规请求”,却依然触发了防护机制。经调查,这些早期为应对安全事件制定的规则,其依据的流量特征在当时与滥用行为高度相关,但后续却开始匹配部分未登录用户的合法请求。GitHub 表示,这类检测机制结合了行业标准的指纹识别技术与平台专属的业务逻辑,而“多维度信号组合偶尔会产生误判”。
GitHub 还量化了这套多层级检测信号的实际运行表现。在匹配到可疑指纹的请求中,仅有一小部分会被拦截,只有同时触发业务逻辑规则的请求才会被阻断,这类请求约占指纹匹配请求的 0.5%~0.9%;而误判请求在总请求量中的占比则极低,约为每 10 万次请求仅出现数次。尽管如此,GitHub 在博文里强调,该问题对用户造成的影响仍不可接受,并以此次事件揭示了一个更普遍的运维问题:应急防护规则在安全事件发生时通常能正常发挥作用,但随着威胁模式的演变以及合法工具和使用场景的变化,这些规则会逐渐 “失效脱节”。
GitHub 此次复盘的核心结论之一就是,多层级防护体系会增加定位故障根本原因的难度。工程师需要跨多层基础设施追踪请求链路,才能确定拦截行为发生在哪个环节,而实际排查的难点在于,每一层基础设施都具备合理的限流、拦截权限,要定位具体是哪一层做出的拦截决策,就必须对多个采用不同数据格式的系统日志进行关联分析。
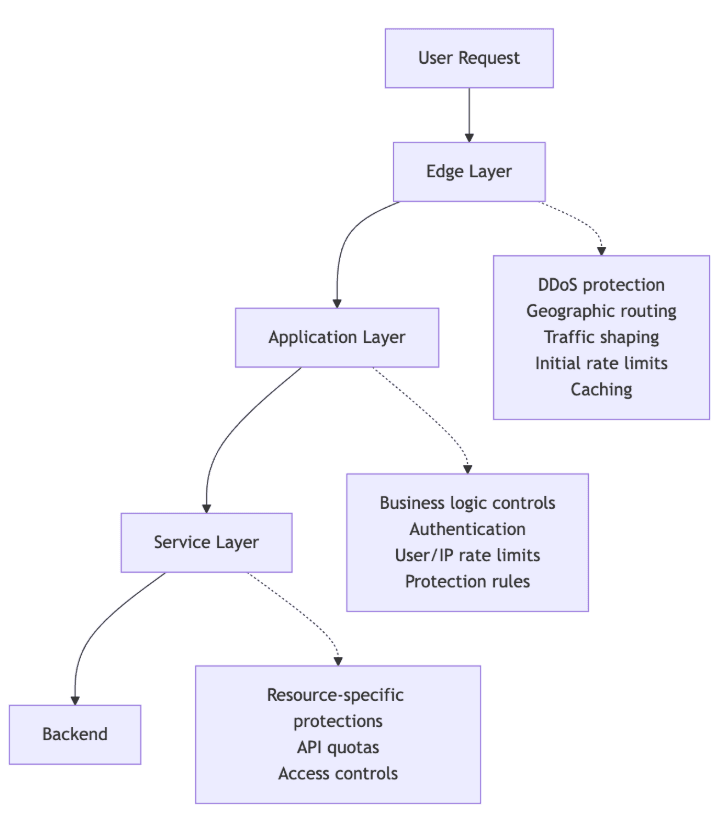
图片来源:GitHub
为了解决当下的问题,GitHub 对所有防护规则开展了全面复核,对比每条规则当前的拦截范围与最初设计的防护目标,移除了已经没有实际防护意义的规则,同时保留了针对现存威胁的防护措施。从长期来看,GitHub 表示正投入资源完善防护规则的生命周期管理体系,打造更完善的跨层级可观测的能力,实现限流与拦截行为的源头追踪;将应急防护规则默认设为临时生效;新增事件后复盘机制,推动应急防护规则向可持续、精准化的解决方案演进。

尽管 GitHub 的博文聚焦于规则生命周期管理与跨层级可观测性,但这种采用“纵深防御”架构的请求处理流水线,在其他处理互联网流量的大型平台中也十分常见。例如,Vercel公开的请求处理生命周期中提到,请求会经过其防火墙的多个防护阶段,覆盖网络层(L3)、传输层(L4)和应用层(L7),后续还会针对项目级策略增加 Web 应用防火墙(WAF)防护环节。Vercel 还指出,各防护层级间存在反馈机制,若某条 WAF 规则触发了持续性拦截动作,上游防护层会提前拦截后续的同类请求。
这种分层防护的设计并非仅存在于边缘流量管理领域:Kubernetes的API服务器安全模型也采用了明确的阶段式设计,准入控制器会在身份认证、授权校验完成后,数据持久化之前拦截请求,形成一套结构化的校验链路,后续可在此基础上不断叠加新的策略与安全检查规则。
这些案例共同揭示了大型系统中一种普遍的设计权衡:多层级防护机制能提升系统的抗风险能力与灵活性,但也会增加防护规则“脱离其设计背景,依然失效存在”的风险。GitHub 的此次经历也印证了,纵深防御体系的长期有效性,不仅取决于防护规则的部署层级,更在于随着系统与使用模式的演变,能否清晰把控每条规则的设计初衷、实际影响与生效周期。
原文链接:
GitHub Reworks Layered Defenses After Legacy Protections Block Legitimate Traffic




