
嘉宾 | 张颖
编辑 | 贾亚宁
目前京东实时计算平台已经发展到了一定规模,且在 Flink 的应用上也积累了很多经验与反思。本次我们专访了京东数据分析优化部的算法工程师张颖老师,期待能从京东落地 Flink 的过程中获得一些应用 Flink 的经验和启发。
同时张颖老师也是已经上线的 QCon+ 案例研习社「Flink 在实时计算应用场景中的落地实践」专题的讲师,带来了「基于 Alink 实现 Prophet 时间序列模型」的分享。
InfoQ:你最近主要在做什么呢?
我在京东数据分析优化部主要负责实时计算相关的工作,目前京东实时计算平台已经发展到了一定的规模,它紧跟社区,先后推动了批流一体、云原生等多个技术的落地。为了降低各业务实时计算的开发和学习成本,我们在原有的 Flink 计算引擎基础上研发了一套低代码的配置化编程系统,他学习成本低、易用性强、可移植性高,并且支持配置化编程。
InfoQ:方便重点讲讲这个低代码的系统吗?它和传统的低代码平台相比有什么不同?
这个低代码平台原计划是小白用户来使用的,可以通过拖拉拽直接生成一个 Flink 任务的引擎,但在实际使用的过程中,我们发现有开发经验的用户更倾向于通过简单编码来实现。这里举一个例子:对于复杂的 Flink SQL 而言,囿于产品本身的特性,需要限制部分操作或增加用户配置才能实现拖拉拽;但是有开发经验的用户直接修改 SQL 就可以直接达到目标。于是我们将这个平台调整了一下,在实现拖拉拽功能的同时开放一些配置,用户可以直接编程实现,这就完美地解决了上述问题。
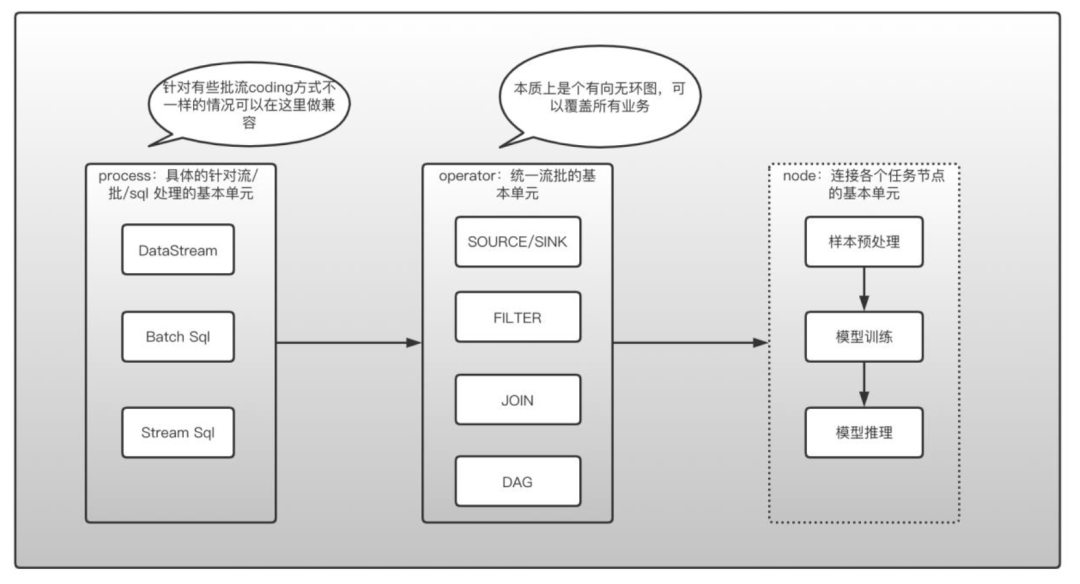
上面这张图是我们实时框架的主要结构,包含:
process 层:这里统一了 DataStream、StreamSQL 和 Batch SQL(社区基本不再维护 DataSet),支持用户 UDF;
operator 层,这里是具体的业务层,包括一些算子的执行策略,operator 之间的串联方式是有向无环图,可以实现用户任何方式的算子组装;
node 层,这里支持用户将每个业务串联执行,用户将任务放在 AIFlow 里面,AIFlow 负责将各个任务正常调度。
InfoQ:京东目前在哪些场景中使用 Flink,未来还会拓展哪些新的场景呢?
京东的大部分场景在实时计算方面都已经切换到 Flink 了,像比如说京东的榜单服务,流式计算就已经完全切到 Flink 上了。这个榜单任务流式计算类似一个 TopN 的 Flink 任务,因为数据量比较大,我们把数据经过过滤、排序等操作,再放到 HBase 里面来实现 TopN。
机器学习场景,除了使用 Alink 的固有模型之外,我们还支持 Alink 分布式调用 Python 和基 Python 的小模型分布式训练。还有诸如样本拼接、Label 拼接、Feature 拼接等拼接场景,我们都希望可以实现批流一体。如果模型实时训练时出现了效果降低的情况,我们就需要回退一个版本,与此同时样本也全部都回滚。但是直接回滚 Kafka 里面的数据可能已经过期了,这时就需要借助离线,这里面会涉及到一些数据的 gap,但是如果在代码层面上完全实现了批流一体的话,会非常有利于这种 back filled 的场景。
既然样本分实时和离线的话,那么 Feature 和 Label 势必也是要分实时和离线的,所以代码层面流批一体的统一对开发者来说有非常大的好处。我们希望利用 Flink 将大数据生态以及机器学习生态紧密联合起来,让数据和机器学习更好地支持和服务于业务场景。

InfoQ:你认为 Flink 会取代 Spark 吗?为什么呢?
Flink 在实时计算方面已趋于成熟,但是批流一体还是有待发展的,比如说我们在某个业务中用批式来实现,但是后来发现它不能完全解决问题,就想利用 Flink SQL 的批流一体无缝切换到实时,但在实现的过程中发现有些流式的 SQL 和批式的 SQL 写起来就是不一样的,并且他们包括 shuffle 等的底层原理也不一样。
经过实际的验证,我们发现当流式资源是批式资源的三倍时才能稳定下来,且在相同数据量的情况下,批式的处理时间也比流式小。这是因为流式的数据是一条一条的,大部分的数据都存在于内存中,涉及到 join 的话,哪怕是用到了 RocksDB,也还是需要配置一定的内存(WriteBuffer、BlockCache 等)。
但是对于 Batch Mode 是有很多数据直接 shuffle 到了硬盘上,并且它是分阶段来执行的。在这种情况下 Batch Mode 需要的资源相对来说要少很多,但是资源问题没有解决的话,我们又没有办法将这些批流一体的代码上线。如果社区能够逐步解决这些问题,相对 Spark 来说 Flink 的优势会持续增大,接下来社区也会着重发展这部分。
InfoQ:你对数据报警研究的比较深入,你认为一个好的报警系统要满足什么要求?
传统的同环比、统计类报警过度依赖规则与阈值超参数的设定,存在报警不稳定、误报率高等问题,且从故障发生到报警时间较长,会给业务带来困扰,要检查一个报警系统的好坏,除了报警的延时,报警的准确之外,还有很多其他的评判标准,在这里我们只关心一种情况,就是如何将这个报警智能化。
比如京东榜单服务每天高低峰分别是 2000、1000 QPS,我们在设置报警时,大概率会将最高值和最低值设置为:2000 和 1000,也可能会有一个浮动的报警(一般浮动值设置后误报的几率也会增加)。我们假设某一天晚高峰的流量是 1200 QPS,由于它高于最低值,报警是不会预测到的,但是晚高峰应该是 2000 呀,这就偏离了业务的需求。
于是,我们研发了一个基于机器学习的报警,一般分为三步:
FFT 检查数据是否有周期性特点
Prophet 进行时序预测
DBSCAN 检测异常点
任何一个公司或者是业务的报警数据量都非常庞大,在海量数据实时涌入的情况下,我们一般会采用根据数据指标的数据并行的方式来进行模型的训练及预测,映射到 Flink 里面,我们就是将这些指标数据作为 key,然后以此 key 来进行 keyBy,达到让这些数据都分别落到相同的 subtask 里面去的目的。
在实现的过程中我们采用数据并行的方式训练模型,并且采用了模型训练和预估一体化的技术策略。这种基于机器学习模型的报警模式完美地解决了传统链路的不足,因此也解决了业务问题,可以做到提供人性化的报警服务。
InfoQ:最后,对想要深入了解并应用 Flink 的小伙伴说些什么吧!
我给大家分享一个我平常学习 Flink 的时候,经常采用的方式。
大家在遇到 Flink 的一些相对来说比较陌生的函数或者功能的时候,一般可能会去百度或是 Google,这种学习方式肯定没问题。但是对我自身而言最快的一种方式是,在使用搜索引擎之前先去 Flink 官网查资料,也可以直接把 Flink 的代码从 GitHub 上复制下来,当我遇到一些问题时(比如遇到一个 Left join 不会写或是一个 data set 应该如何使用)就可以直接去代码库里全文搜索,得到的结果一般甚至都是带有测试用例的,这样就非常高效地解决了问题。
另外一种情况是遇到的新场景不知应该如何处理,大家最常见的应对方式可能是按照自己已有的思维来解决,这可能会因为自身的认识不足,使得方案明显不完善。我是这样应对的:访问一些 Flink learning 的网站,或者在社区内搜索相关的场景,有的时候也添加一些相关的钉钉群,在群里面问问别人的实现方案,这个时候往往都会有意想不到的收获。类似大厂案例的技术落地最佳实践的分享,也可以带来一些启发和指导。
概括来讲,我们日常就需要拓展一下自己的技术范畴和技术视野,比如 Flink learning 网站、社区公众号、钉钉群、Flink AI extend、Ververica 和 InfoQ 等媒体都会发一些相应的代码或者是测试包,这也是解决问题非常便捷的方式。
作者简介
张颖,京东数据分析优化部算法工程师,实时方向负责人。Alink、dl-on-flink Contributor,专注 Flink 数据处理方向和机器学习方向。




