
DeepSeek发布DeepSeek-V3.2,这是一个开源的推理和代理 AI 模型家族。在多项推理基准测试中,其高性能计算版本 DeepSeek-V3.2-Speciale 表现优于 GPT-5,与 Gemini-3.0-Pro 相当。
DeepSeek 在开发 DeepSeek-V3.2 时应用了三项新技术。首先,他们使用了一种更高效的注意力机制,称为 DeepSeek 稀疏注意力(DSA),这降低了模型的计算复杂性。他们还扩展了强化学习阶段,使其消耗的计算资源超过了预训练。最后,为了改进模型使用工具的能力,他们开发了一个代理任务合成管道。最终,该模型在一系列编码、推理和代理基准测试中的表现超过了其他大多数开源模型,并且与 GPT-5 和 Gemini-3.0-Pro 等前沿闭源模型持平或更好。不过,DeepSeek 团队指出:
尽管取得了这些成果,我们承认,DeepSeek 与前沿封闭源模型相比还存在某些局限性……首先,由于训练过程的 FLOP 总数较少,DeepSeek-V3.2 在世界知识的广度方面仍然落后于领先的专有模型。在未来的迭代中,我们计划通过扩大预训练的计算量来解决这一知识差距问题。其次,令牌效率仍然是一个挑战……未来的工作将专注于优化模型推理链的智能密度以提高效率。第三,解决复杂任务的能力仍然不如前沿模型,这激励我们进一步完善我们的基础模型和后训练方法。
InfoQ 报道过 DeepSeek 之前的几个版本,包括最初的DeepSeek-V3以及他们的第一个推理模型DeepSeek-R1。这两个版本都是在 2025 年初发布的。2025 年晚些时候,InfoQ 报道了DeepSeek-V3.1,这是一个混合推理模型,在单一系统中融合了思考模式与非思考模式。
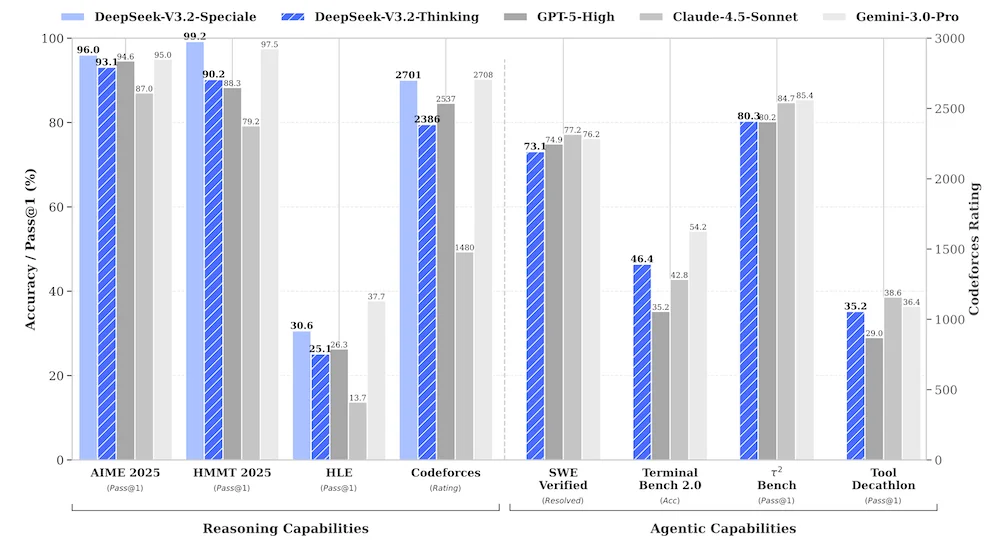
DeepSeek-V3.2 基准测试性能(图片来源:DeepSeek技术报告)
DeepSeek-V3.2 使用的架构与 DeepSeek-V3.1 相同,只是使用了新的 DSA 注意力机制。团队从 DeepSeek-V3.1 的一个检查点入手,在继续预训练并生成 DeepSeek-V3.2 之前,将上下文长度扩展到了 128K。新的注意力机制将计算复杂性从 O(L^2)降低到了 O(Lk),其中 L 是上下文长度,k<
对于后训练,团队使用了专家蒸馏(specialist distillation)技术。他们训练了一组专门针对特定领域的专家模型:编码、数学运算和几个代理任务。然后,这些专家模型生成合成训练数据,用于微调主模型。
在Hacker News上关于DeepSeek-V3.2的讨论中,部分用户指出了高性能开源模型的优势。一位用户写道:
如果你试图构建基于 AI 的应用程序,你应该比较基于供应商的解决方案和使用自己的硬件托管开源模型之间的成本……然后将其与 GPT-5 的成本进行比较,这比较简单,因为每(百万)令牌的成本可以从网站上获取。运行 DeepSeek(或更成熟的 Qwen3)这类系统能为你节省的云服务开支,绝对超乎想象……DeepSeek 和 Qwen 能在廉价 GPU 上流畅运行,而其他模型会直接卡死。
DeepSeek-V3.2 模型文件可以从Huggingface上下载,但高计算资源版本 DeepSeek-V3.2-Speciale 目前仅通过 DeepSeek 的 API 提供。
原文链接:




