
要点
对于使用人工智能/机器学习 (AI/ML) 技术的组织而言,系统地追踪机器学习生命周期的碳足迹,并在模型开发和部署阶段实施最佳实践是非常重要的。
应对能源需求时所面临的挑战包括缺乏标准化的能耗计算方法,以及准确衡量人工智能碳足迹的复杂性。
排放可分为两类:运营排放,指运行训练模型和推理的能源成本以及机器学习硬件支持的成本;生命周期排放,包括从芯片到数据中心建筑等所有相关组件在制造过程中产生的碳排放。
构建可持续机器学习生命周期的最佳实践包括:优先选择高效的模型、进行模型优化以降低复杂性、选择高效的硬件(CPU、GPU 和 NPU),以及选择云托管而非本地部署的基础设施。
有一些开源工具(例如 CodeCarbon 和 MLCarbon)可用于追踪和降低能耗。谷歌云平台(GCP)和亚马逊网络服务 (AWS) 等云平台通过提供减少碳足迹的工具,实现了人工智能工作负载的可持续性。
引言
在过去几年中,人工智能(AI)的采用率急剧增加,催生了很多复杂且计算密集型的 AI/ML 系统。组织不断更新他们的机器学习基础设施以支持模型训练和部署,这消耗了大量的能源和资源,促使数据中心升级他们的设施以满足这些不断增长的需求。一些大型科技公司,如谷歌、微软和亚马逊,也在探索核能作为为他们的 AI 基础设施提供动力的潜在解决方案,但这是将来的事情。
在当前的 ML 系统中,困难在于准确测量和跟踪整个模型生命周期的能源需求。因此,系统地跟踪 ML 生命周期的碳足迹并持续实施模型开发和部署阶段的最佳实践是非常重要的。只要能在 ML 过程中在性能和能效之间取得平衡,研究人员和实践者就可以为 AI 的更可持续创新做出贡献。
然而,跟踪能源需求并不容易,因为它带来了几个挑战:
AI 系统中缺乏碳足迹意识。
缺乏计算能源消耗的标准化方法。
准确测量 AI 的碳足迹是很复杂的工作,使得比较不同模型和跟踪进展的需求难以实现。
在性能与能效之间,后者总是一个权衡。
转向高效的绿色能源的做法受到了地理和技术限制的阻碍。
性能和成本效率是软件开发的主要关键绩效指标(KPI)。但能源不是。
在过去几年中,大型语言模型(LLM)变得更加复杂,能力更强,它们的规模也呈指数级增长。基于 Transformer 的架构和专家混合(MoE)架构的出现进一步加速了模型规模的增长。到 2022 年,像 GPT-3 这样的大型语言模型取得了显著进展,参数量超过了 1750 亿。自 2022 年以来,增长持续加速,GPT-4 这样的模型架构甚至更大了。这一趋势在新模型中仍在持续。

图 1:显示了用于训练的模型和数据集规模。图片来源:Epoch AI,‘Data on Notable AI Models’。
在线发布于 epoch.ai。从epoch.ai [在线来源]检索。访问日期:2025 年 5 月 1 日。
上述图表展示了 AI 模型的规模和复杂性在过去三四年里的增长趋势。我们再来看看几个模型规模的稳定增长情况,见表 1。
表 1:模型及其参数
受益于大型模型,许多自然语言处理任务在性能上有了很大提高,但这些模型显然需要更多的计算资源、内存和能源来训练和运行,引发了人们对它们的环境影响的质疑和担忧。
深入了解模型本身并理解浮点运算(FLOPS)和参数这两个术语有助于我们理解模型规模和所需计算量之间的关系。这里 FLOPS 用来衡量模型的计算复杂性,参数代表模型的规模和容量。随着模型增长到巨大的规模,FLOPs 和参数值通常同步增长,导致训练和推理期间的精度和能源消耗更高。这提醒我们平衡模型性能和效率是很重要的。
研究人员正在探索创建更高效模型的方法,这些参数较小的模型可以通过模型压缩、知识蒸馏以及开发能够更有效地利用较小参数量的更复杂架构来实现类似或更好的性能。
ML 生命周期的碳足迹
ML 生命周期包括数据处理、训练和推理几个阶段。数据处理涉及数据收集和特征工程等任务,这些任务的计算量比训练和推理要轻。训练需要密集的计算以构建准确的模型,然后这些模型被部署,并反复用于许多应用中的推理任务。一些模型全天候运行,导致整体能源需求更高。每个人都认为训练需要大量数据和资源,因此训练阶段的能源强度比推理阶段更高,但事实并非如此。
与训练相比,推理占能源消耗的更大比例,因为其在数十亿用户中累积的能源使用量迅速增加。大型科技公司报告称,ML 能源使用的大部分来自推理阶段,而不是训练大型语言模型的阶段。
排放可以分为与 ML 训练相关的两种类型。
运营排放指的是运营训练和推理以及 ML 硬件支持的成本,包括数据中心开销,如冷却需求。生命周期排放包括在制造所有涉及的组件过程中排放的碳含量,像运营排放一样也涉及从芯片到数据中心建筑的各个类型。这些排放造成了一个非常大的问题,非常难以解决。
软件工程师对运营排放的了解可以比生命周期排放更多。仅仅提高对运营排放的认识和监控就极大地有助于可持续性。有很多开源工具和云平台功能可以跟踪和减少能源消耗。AI/ML 工程师可以专注于优化模型大小,选择高效的硬件,并选择位于可再生能源源附近的能效高的数据中心,从模型构建到模型部署和维护做出明智的决策,这可以显著减少能源消耗。
如何测量你的代码的碳足迹
有几个工具和框架具有独特的功能和用例,用于测量 ML 模型的碳足迹。在本文中,我们将查看以下两个框架:
CodeCarbon 是一个开源的轻量级 Python 库,用于估计 ML 模型训练期间的排放。它跟踪本地机器和云环境使用的能源。它支持与 PyTorch、Keras 和 Scikit-learn 等 ML 框架的集成。CodeCarbon 允许你跟踪多个训练运行,比较不同的模型大小,并监控不同地区的 GPU 与 CPU 排放。
可以使用以下命令安装该工具。CodeCarbon GitHub 仓库上也提到了设置说明:
pip install codecarbon让我们看一个例子,了解不同数据集大小和模型复杂性如何影响排放。
我使用 scikit-learn 训练了三个复杂性不同的随机森林分类器,并使用 CodeCarbon 测量了它们的碳排放。实验是在有 10 个 CPU 核心的 Apple M1 Pro 处理器上进行的。为了模拟不同的计算负载,我创建了三个复杂性递增的场景。每个模型都是使用 scikit-learn 的 RandomForestClassifier 进行训练的,n_estimators(树的数量)和数据集大小各不相同。排放是通过 CodeCarbon 的 EmissionsTracker 跟踪的,它测量了模型训练期间的能源消耗,并将其转换为 CO2 当量排放。结果如表 2 和图 2 所示,代码可作为 GitHub 上的笔记本脚本获取。
加载并实例化一个 EmissionsTracker 对象,并将其作为参数传递给函数调用,以开始和停止机器学习代码的排放跟踪。
def compare_model_complexities(): scenarios = [ { 'name': 'Basic RF (100 trees)', # More specific naming 'n_samples': 10000, 'n_estimators': 100, 'max_depth': 5 }, { 'name': 'Intermediate RF (500 trees)', 'n_samples': 50000, 'n_estimators': 500, 'max_depth': 10 }, { 'name': 'Complex RF (1000 trees)', # Clearer description 'n_samples': 100000, 'n_estimators': 1000, 'max_depth': None } ] results = [] for scenario in scenarios: # Generate dataset for this scenario X, y = make_classification( n_samples=scenario['n_samples'], n_features=50, n_informative=40, random_state=42 ) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) # Train and track emissions tracker = EmissionsTracker( project_name=f"rf_{scenario['name']}", output_dir="emissions", log_level="warning", measure_power_secs=15 ) tracker.start() #emissions start tracking start_time = time.time() model = RandomForestClassifier( n_estimators=scenario['n_estimators'], max_depth=scenario['max_depth'], random_state=42 ) model.fit(X_train, y_train) accuracy = model.score(X_test, y_test) duration = time.time() - start_time emissions = tracker.stop() #emissions stop tracking results.append({ 'scenario': scenario['name'], 'samples': scenario['n_samples'], 'n_trees': scenario['n_estimators'], 'duration': duration, 'emissions': emissions, 'accuracy': accuracy, 'emissions_per_sample': emissions/scenario['n_samples'] }) return pd.DataFrame(results)# Run comparisonresults_df = compare_model_complexities()要分析结果,只需使用 pandas dataframes 打印 CSV 文件。
results_df = pd.read_csv('emissions/emissions.csv')print("Emissions details:", results_df)CodeCarbon 有一个内置的记录器,将数据记录到项目根目录下名为 emissions.csv 的 CSV 文件中,每次运行都会记录。然而,输出也可以发送到像 Prometheus 这样的监控平台和像 LogFire 这样的可观测性平台,以更好地跟踪。
表 2:RF 配置的模型复杂性与性能和排放对比
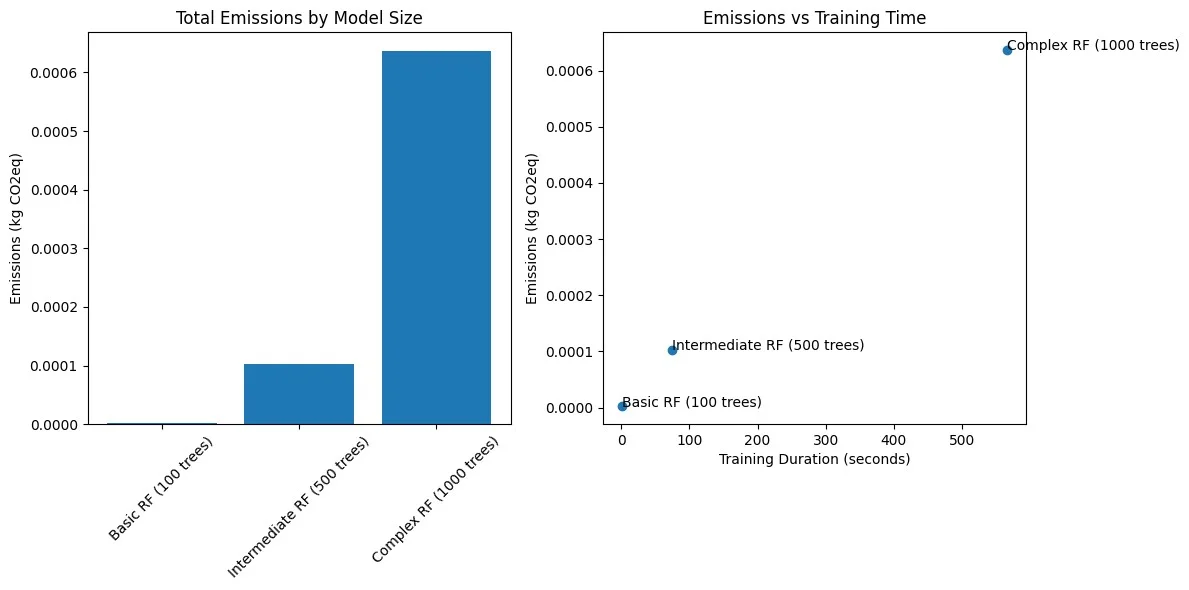
图 2:RF 配置的模型复杂度、性能和排放量。
一个简单的随机森林模型,包含 100 棵树,用 1 万个样本训练,其排放量仅为 0.000002 千克二氧化碳当量,运行时间为 1.53 秒,精度为 85.1%。
一个中等规模的随机森林模型,包含 500 棵树,用 5 万个样本训练,其排放量为 0.000103 千克二氧化碳当量,运行时间为 74.29 秒,精度为 92.95%。由此可见,排放量的显著增加与计算需求的增加相关。
一个复杂的随机森林模型,包含 1000 棵树,用 10 万个样本训练,其排放量为 0.000637 千克二氧化碳当量,实际运行时间为 566.99 秒,精度为 96%。这反映了样本量增大和树数量增加导致的计算成本增加,从而导致了排放量的增加。
结果表明,虽然模型的精度随着复杂性的增加而提高,但环境成本却急剧上升。中等复杂度的模型代表了精度与排放之间的最佳平衡。它在排放适度增加的情况下,显著提高了精度。这些发现表明,实践者应该仔细考虑模型性能的边际改进是否值得相关的环境成本。
常见问题与解决方案
整体设置是一个简单的过程。然而,有一个结构化的方法可以为机器学习工作流程中的环境影响优化提供可操作的洞察。在设置 codecarbon 和运行时,可能会遇到的一些常见问题包括:
“另一个 codecarbon 实例正在运行”。这个锁定文件错误可以通过实现自动清理来解决。在开始之前使用 cleanup_tracker()确保一个干净的跟踪环境,并在运行之间进行清理。
“没有记录排放数据”。这个错误是由于计算负载不足。确保机器学习工作负载是可测量的,推荐的最小训练时间超过 5 分钟。
有时,由于跟踪器在停止时默认写入排放数据的行为,等待看到排放数据的时间会变得太长。然而,对于更长时间的运行,你可以通过调用 flush()方法来保存中间数据。
CodeCarbon 有效地跟踪代码执行期间产生的运营排放,包括 CPU、GPU 和 RAM 消耗的能量,并且适用于较小的机器学习模型。然而,它目前不适合大规模 LLM 排放跟踪。它不能扩展到密集型或 MoE 或 LLM,因为它忽略了关键的模型架构参数。
MLCarbon 是一个开源的碳足迹建模工具,考虑了架构参数,是 LLM 最全面的框架。它支持 LLM 生命周期的端到端阶段:训练、推理、实验和存储。这包括运营碳排放(来自运营期间的能源使用)和内含碳排放(来自硬件制造和基础设施)。
让我们通过一个例子来了解如何使用 MLCarbon,然后讨论其关键结果。
示例场景:
想象一下,一位机器学习或数据科学工程师在设计一个新的大型语言模型用于文本摘要的早期阶段。他们正在考虑使用基于 Transformer 的架构,并在两个潜在的模型大小之间发起争论:一个大约有 300 亿参数,另一个计算上更密集,大约有 1000 亿参数。他们计划在一个大的文本语料库上训练这些模型,并可以访问一个提供 NVIDIA A100 GPU 的云计算平台,在数据中心的报告功率使用效率(PUE)为 1.15,估计碳强度为 0.35 tCO2eq/MWh。他们预计较小模型的训练时间为 30 天,较大模型为 60 天,使用一定数量的 GPU。
工程师需要收集以下信息,以便在开始训练之前使用 MLCarbon 估计运营碳足迹。只需克隆 GitHub 仓库,更新 database.csv 文件中的相关信息,并执行 llmcarbon_tutorial.py 脚本来生成排放数据。
database.csv 文件的参数包括:
LLM 架构:基于 Transformer(尽管 MLCarbon 可能允许直接输入参数数量)。
参数数量:300 亿(对于第一种情况)和 1000 亿(对于第二种情况)。
训练数据集大小(以 Token 计):基于他们的语料库的估计。
硬件配置:NVIDIA A100 GPU,以及每个模型大小计划的 GPU 数量。
训练时长:30B 参数模型为 30 天,100B 参数模型为 60 天。
数据中心规格:PUE 为 1.15,碳强度为 0.35 tCO2eq/MWh。
对于 GPT3 密集型模型,值如下:
GPT3,dense,175,,300,0.429,1.1,V100,300,330,125,24.6,0.197,10000,314,14.8,552.1,1287下面的表 3 提供了一个清晰简洁的值及其相应解释的分解。
表 3:数据库文件中的模型配置键值
MLCarbon 将使用其内部模型(FLOP 模型、硬件效率模型和运营碳模型)来估算两种潜在模型配置的能量消耗(以 MWh 计)和由此产生的运营碳排放量(以 tCO2eq 计)。获取和保存上述信息的过程需要自动化,以便工程师可以轻松访问这些数据,以便在训练或推理阶段之前获得碳足迹的洞察,因为如果软件工程师不得不投入太多手动工作来收集这些数据,它将不会对测量碳足迹的过程产生积极影响。
结果将显示差值:(预测值 / 实际值)- 1。负值表示碳排放量的低估,正值表示碳排放量的高估,值越接近 0 表示精度越高。对于 GPT 3,结果是 0.00225,显示出最小的误差和最佳性能。
虽然像 CodeCarbon 这样的工具可能对机器学习环境影响的事后分析更有价值,但像 MLCarbon 这样的工具通过允许工程师在模型开发和资源密集型训练之前估算不同模型架构和硬件配置的碳足迹,填补了在机器学习模型选择阶段预先评估环境影响的空白。具备这种预测能力的同时,通过积极策划模型选择和优化以及利用能效高的云资源,也可以实现进一步的减排和更大的可持续性。
构建可持续机器学习生命周期的最佳实践
为了进一步减少排放并增强机器学习的可持续性,结合深思熟虑的模型选择、持续的模型优化和战略性使用能效高的云计算的综合方法是至关重要的。AI/ML 从业者应该了解以下策略,以减少运营排放并构建可持续的 ML 系统。
1. 优先选择高效的模型
初始模型架构的选择对能源消耗和碳排放有重大影响。正如论文“机器学习训练的碳足迹将趋于平稳,然后缩小”中强调的,选择高效的 ML 模型架构,如稀疏模型而不是密集模型,可以导致计算量减少约 5 到 10 倍。
在选择闭源或开源 LLM 之前,工程师应该考虑这个问题:给定问题是否可以用计算量或资源消耗较少的模型解决?例如,考虑实现 Distil BERT 而不是 BERT 和 GPT-3.5/4 Turbo 而不是 GPT-3/4。Distil BERT 是 BERT 的压缩版本,保留了 97%的性能,参数减少了 40%,推理时间快了 60%,使其更加节能。Turbo 模型每次推理使用的资源更少。它们成本效益高,适合于效率至关重要的高容量任务。
2. 降低复杂性的模型优化措施
在保持性能的同时减少给定模型所需的计算是一个重大挑战。表 4 中展示了各种优化技术及其好处。
因此,考虑构建针对特定任务的模型,针对特定任务的模型旨在专注于一个领域特定的应用,而不是通用任务。拥有这个领域知识使它们非常高效,非常适合减少延迟和总体计算成本。
使用低计算能力的模型,例如小型语言模型(SLMs),是另一种优化策略,可以在保持特定任务性能的同时最小化资源消耗。这种方法在计算能力有限的环境中特别有用,如边缘设备上。SLMs 是构建在 Transformer 架构上的,语言模型的小参数子集。因为它们需要的参数更少,这些模型需要的训练数据和计算资源也往往更少,减少了训练时间和成本。它们非常适合资源受限的环境,如边缘设备,但可以处理领域内的多个任务。
其他技术,如微调架构和剪枝,可以带来更高效的模型,而不会牺牲性能。微调会将预训练模型调整到特定任务,并在减少从头开始进行广泛训练的需求的同时提高性能。即使在模型压缩和剪枝之后,它也可以恢复精度和鲁棒性。
修剪可以去除模型中不重要的参数和连接,减少模型的大小和计算需求,提高推理速度。如果谨慎实施,修剪可以在不显著损失精度的情况下保持甚至提高模型效率。例如,修剪后的模型可能保留其原始精度的 90%,同时只使用其原始参数的 10%。然而,权衡点在于找到模型大小减小和性能保持之间的正确平衡。修剪后可能需要微调以恢复部分丢失的精度。
量化是另一种减少计算负载和能源消耗的技术。它降低了模型权重的精度,而不会显著影响模型性能,从而减少了计算负载。
优化技术与能源效益
表 4:各类优化技术与其能源效益
3.选择高效硬件
选择能效高的硬件,如为深度学习负载优化的 TPU 或 GPU 而不是 CPU,可以帮助减少能源消耗,而不影响 ML 系统的性能。下表比较了在 AI 工作负载中使用的硬件类型(CPU、GPU 和 NPU),重点关注它们的功能、处理能力、性能水平和能源使用。对比显示了选择平衡性能与能源使用的硬件的重要性,有助于 AI 开发中的可持续性努力。请注意,就能源使用而言,尽管 GPU 总体上能耗高,但它们在某些 AI 工作负载(如 AI 训练)上比 CPU 更节能。请参阅表 5 进行快速对比。
表 5:各种硬件类型与其效率
4.本地与云
利用能效高的云计算通常比本地解决方案更能提高数据中心的能效,因为定制的仓库设计得更好,具有更好的 PUE 和无碳能源(CFE)。它要求用户选择具有更清洁能源组合的数据中心位置。选择 CFE 最高或低碳区域来构建新的计算应用和优化模型效率。
像 Google Cloud Platform(GCP)和 Amazon Web Services(AWS)这样的云平台通过提供多种工具来最小化碳足迹,为 AI 工作负载带来可持续性。GCP 允许用户根据 CFE 百分比和电网碳强度等指标选择低碳区域,像蒙特利尔和芬兰这样的地区实现了接近 100%的 CFE。AWS 通过优化基础设施、过渡到可再生能源和利用专用硅芯片,减少了 AI 工作负载的碳足迹,与本地配置相比实现了高达 99%的碳减排。这两个平台都帮助组织将 AI 运营与可持续性目标对齐。然而,许多工程师和组织在选择区域时忽视了这些云平台提供的 CFE 或 PUE 指标。查看 CFE 等可持续性指标并不总是用户在选择区域时的首要考虑因素;他们通常优先考虑性能、成本和满足业务指标。
谷歌的文章《机器学习训练的碳足迹将趋于平稳,然后缩小》展示了通过战略性地应用 4Ms(模型、机器、机制和地图)最佳实践,机器学习训练的能源使用可以减少高达 100 倍,CO2 排放可以减少高达 1000 倍。
4Ms 是谷歌提出的最佳实践,可以显著减少机器学习训练和开发过程的环境影响。首先,模型(Model)侧重于选择高效的 ML 模型架构,如稀疏模型,可以减少 5 到 10 倍的计算量。其次,机器(Machine)使用为 ML 优化的处理器,如 TPU 或最新的 GPU,与通用处理器相比,可以提高 2 到 5 倍的每瓦性能。第三,机制(Mechanization)指的是使用云计算,它提供了更好的数据中心能效,并且可以比本地数据中心减少 1.4 到 2 倍的能源成本。最后,地图(Map)强调选择具有更清洁能源来源的云计算位置,可能将总碳足迹减少 5 到 10 倍。将这四种实践一起应用可以大幅减少能源消耗和 CO2 排放。
总结
人工智能模型的复杂性增加和规模增长,特别是大型语言模型(LLMs)的发展,显示了人工智能系统正变得能源密集。在整个机器学习生命周期中,从数据处理到训练,以及至关重要的推理阶段,测量能源足迹至关重要。测量足迹使我们能够在模型开发和部署阶段做出明智的决策,从而构建能效高的人工智能/机器学习系统。CodeCarbon 和 MLCarbon 等工具提供了测量和跟踪这些排放的有价值手段。然而一定要意识到,仅仅测量是不够的。
走向可持续人工智能的路径在于多方面的策略。除了跟踪排放外,深思熟虑的模型选择、减少计算负载、选择能效高的硬件,以及在低碳区域战略性地利用云基础设施,可以进一步减少能源足迹。通过采用这些最佳实践,我们可以构建能效高的人工智能/机器学习系统,并负责任地推动创新。




