
优步将其内部搜索索引系统迁移到了OpenSearch,引入了面向大规模流式数据的拉取式(pull‑based)数据摄入框架。此次改造的目标是提升实时索引工作负载的可靠性、回压(backpressure)处理能力与故障恢复能力。此前,不断演进的产品需求暴露出很多问题,例如,维护自研搜索平台的成本与复杂度持续攀升,还面临着模式演进、相关性调优以及多区域一致性等方面的挑战。
优步的搜索基础设施支撑行程发现、配送选择和基于位置的查询,以近实时方式处理持续的事件流。他们自研的搜索平台原本基于推送式(push‑based)数据摄入,也就是上游服务直接向集群写入数据。这种方式在小规模场景下效果不错,但在流量突增与故障场景下表现乏力,会导致写入丢失、重试逻辑复杂等问题。
拉取式数据摄入将责任转移到OpenSearch集群本身。分片会从Kafka、Kinesis等持久化流中主动拉取数据,这些消息队列充当缓冲层,实现可控速率、内置回压与可重放恢复。优步的工程师表示,该方案在流量峰值期间显著减少了索引失败,并简化了运维恢复流程。此前会压垮分片队列的突发流量,现在可被每个分片的有界队列平滑吸收,提升了吞吐量与稳定性。
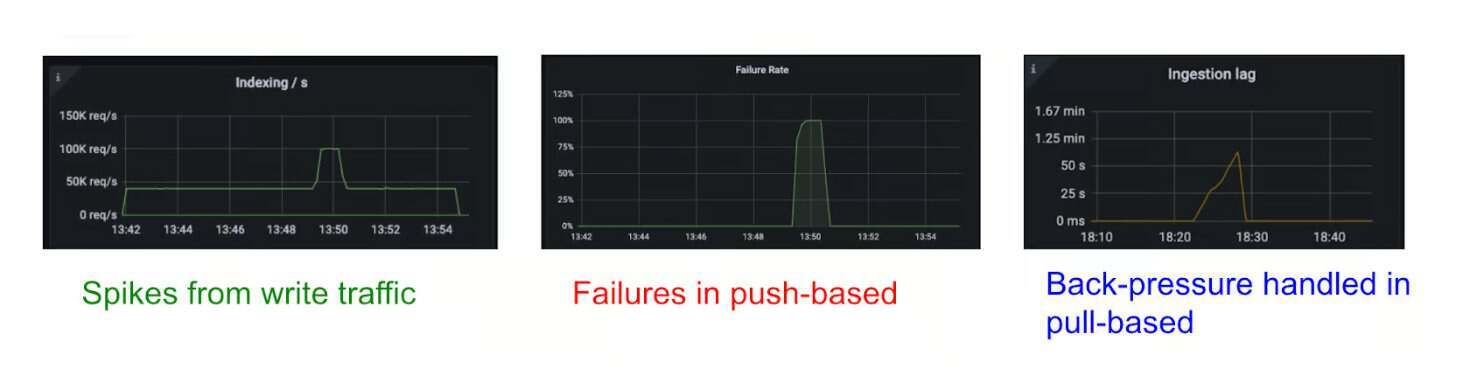
在流量突增期间,推送式和拉取式摄入表现对比(图片来源:优步的技术博客)
拉取式管道由多个交互组件构成。事件会被写入 Kafka 或 Kinesis 主题,每个分片映射到一个流分区以支持确定性重放;流消费者将消息拉取到阻塞队列,实现消费与处理解耦,并支持并行写入;消息由独立线程完成校验、转换与索引请求准备,再交给摄入引擎;引擎直接写入 Lucene,绕过事务日志(translog),同时跟踪已处理的偏移量以支持确定性恢复。
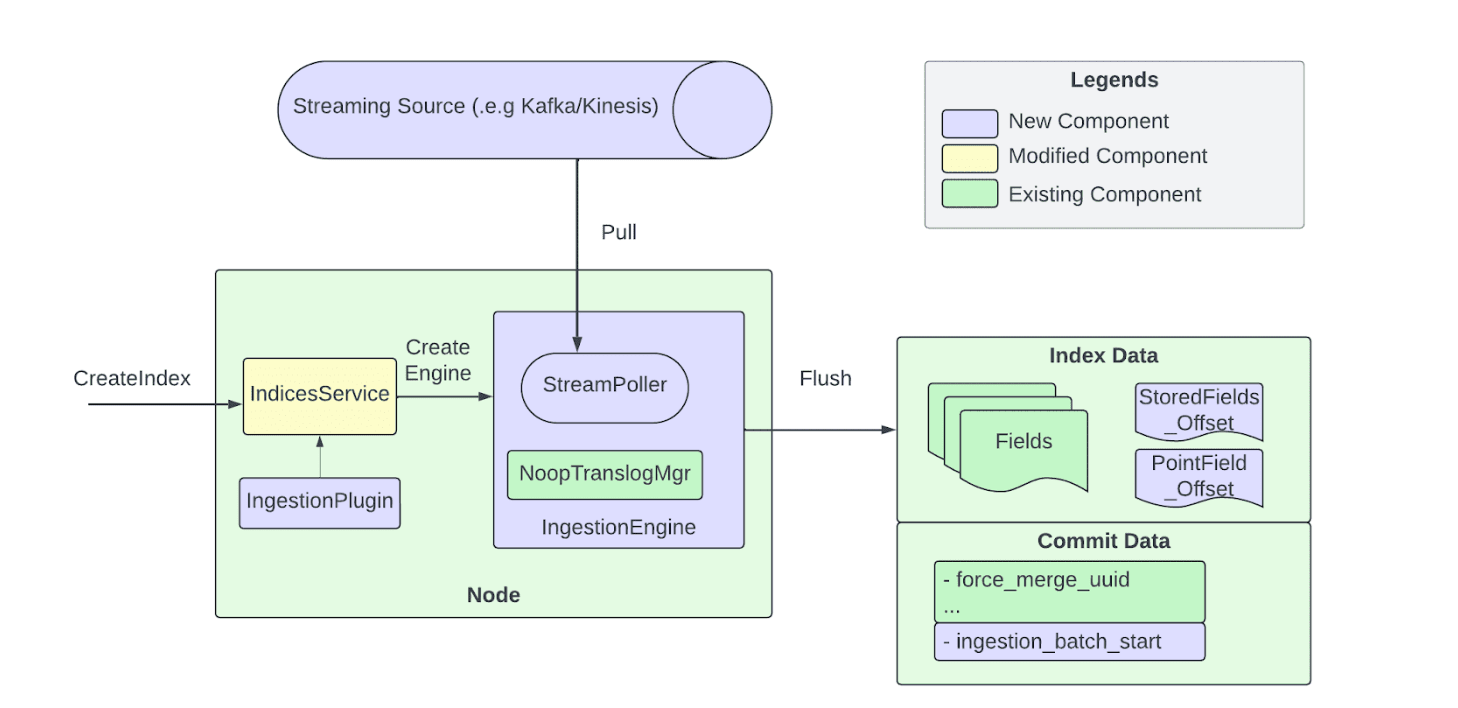
拉取式摄入的流式索引架构(图片来源:优步的技术博客)
据优步工程师介绍,拉取式摄入还提供细粒度的运维控制能力。外部的版本机制确保乱序消息不会覆盖更新数据,至少一次投递能够保证一致性;运维人员可配置失败策略:丢弃策略下消息会直接丢弃,阻塞策略下则会无限重试;通过 API 可暂停、恢复或重置到指定偏移量,帮助团队在故障后快速处理积压。
优步支持两种摄入模式。段复制模式仅在主分片上摄入数据,副本从主分片拉取完整段,这可以降低 CPU 开销,但存在轻微可见性延迟。全活模式会在所有分片副本上同时摄入,实现近乎实时可见,但计算成本更高。
拉取式摄入是优步高可用、多区域搜索架构的核心。每个区域的 OpenSearch 集群从全局聚合的 Kafka 主题消费数据,构建完整、最新的索引。该设计保证了冗余性、全局一致性与无缝故障转移,让全球用户都能获得一致的搜索视图,同时保持高可用。
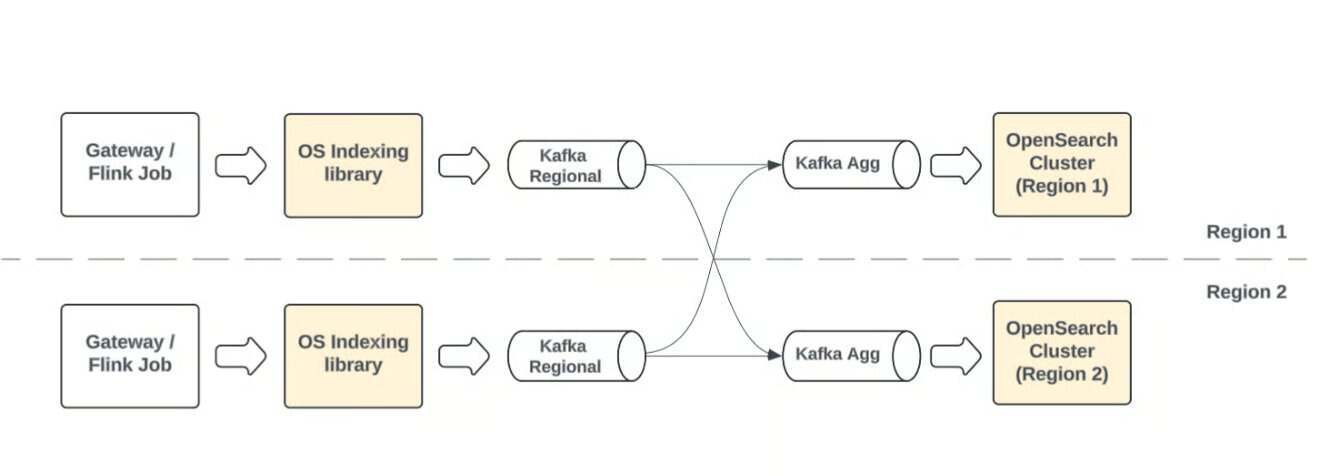
拉取式的索引模型(图片来源:优步的技术博客)
优步正逐步将所有搜索场景迁移到 OpenSearch 的拉取式摄入架构,向云原生、可扩展架构演进,并持续优化平台和回馈 OpenSearch 社区。
原文链接:
Uber Moves In-House Search Indexing to Pull-Based Ingestion in OpenSearch




