
作者|冯绪
编辑|李忠良
策划|AICon 全球人工智能开发与应用大会
当 AI 编程助手迈入 Agentic 阶段,它不再只是“补全工具”,而是能自我规划、跨文件协同、按反馈迭代的开发伙伴。围绕这一转变,Trae 团队走过“补全 + Chat → Apply → Builder + Cue”的三阶段路径,逐步攻克文件精准定位、跨文件修改与效率—准确性—资源开销的平衡。InfoQ 荣幸邀请到了冯绪字节跳动 /Trae 架构师 在 AICon 全球人工智能开发与应用大会·深圳站上分享了《Trae 插件在 Agent 代码编辑的落地实践》,他系统拆解 Apply 与 Search/Replace 的取舍、Cue 的智能补全机制,以及在“太阳系行星页面”等真实案例中的落地经验,提供可复用的工程方法论。
12 月 19~20 日的 AICon 北京站 将锚定行业前沿,聚焦大模型训练与推理、AI Agent、研发新范式与组织革新,邀您共同深入探讨:如何构建起可信赖、可规模化、可商业化的 Agentic 操作系统,让 AI 真正成为企业降本增效、突破增长天花板的核心引擎。
详细日程见:
https://aicon.infoq.cn/202512/beijing/schedule
以下是演讲实录(经 InfoQ 进行不改变原意的编辑整理)
AI 编程助手正加速走向智能化。凭借自主定位文件、修改代码以及自动规划与执行任务,AI Agent 既能高效完成开发工作,又能对结果进行自我校正与迭代,显著提升开发效率。然而,要实现上述能力,仍面临两项挑战:文件精准定位不足与跨文件修改困难。
TRAE 编程助手的发展阶段
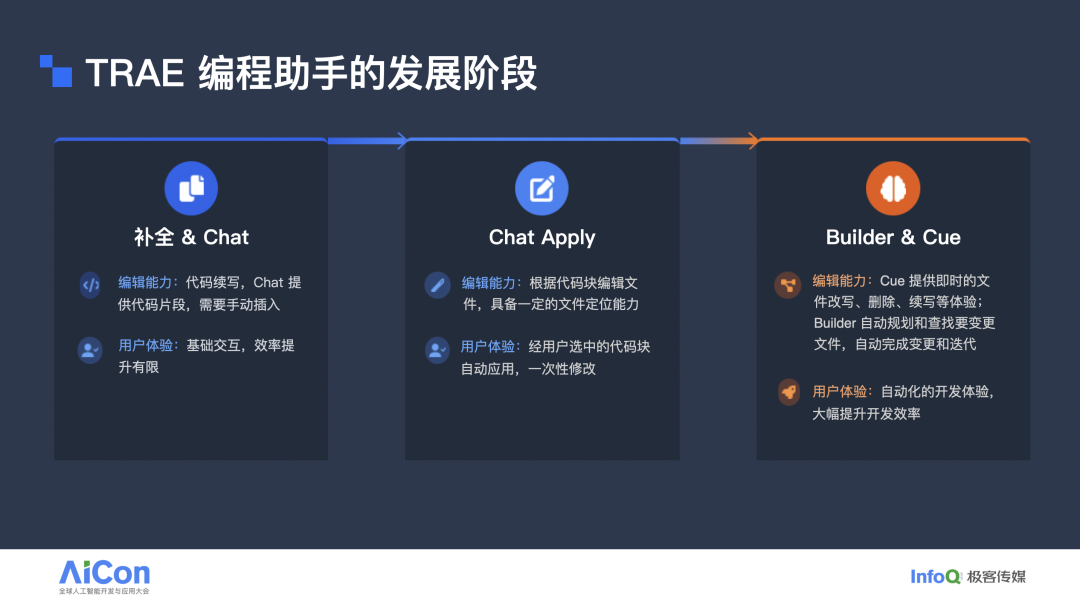
在介绍 Trae 如何解决这些问题之前,先回顾其产品形态的演进,整体分为三个阶段。
第一阶段是最初、也是最基础的“补全 + Chat”。编辑能力以代码续写为主:根据用户在编辑器中的输入,系统自动提示可能的后续内容;同时提供聊天面板,用户可在其中提问并获得代码建议。但用户仍需手动复制粘贴,整体效率提升有限。
为解决手动复制粘贴的问题,进入第二阶段:Check & Apply。核心变化是在代码块上提供“Apply”能力,用户点击即可将生成的代码自动应用到原始文件,实现一定程度的自动化编辑。同时,我们开始探索模型的自动定位能力:当模型给出代码块时,会同时指明期望应用的目标文件。
第三阶段(也是当前阶段)是 Builder 与 Cue,目标是打造高度自动化的开发体验。其一,Cue 提供更智能的补全,支持多行编辑与智能改写,甚至可以预测下一步的光标位置;其二,Builder 能感知项目级上下文,自动规划任务,并完成多文件的编辑与迭代。在这三个阶段中,模型的编辑能力持续增强:早期仅能进行简单续写;中期具备一定的文件定位与修改能力;到第三阶段,已能自动定位与修改文件,并执行更为精确的编辑。
从代码补全到 Agentic Edit
现在来看 Trae 产品在代码编辑能力上的三阶段演进。代码补全是大模型最基础、也最擅长的能力。通过 Fill-in-the-middle、基于最近打开文件的上下文等策略,我们进一步提升了光标位置的续写效果。然而局限也很明显:只能在光标处编辑。
同一时期的 Trae 功能则显得较为鸡肋——模型生成代码后,用户仍需手动复制、粘贴,与直接打开 GPT 页面问答差别不大。为了解决这一问题并提升可用性,我们引入了 Apply 机制,使模型生成的代码片段能够准确无误地应用到原始文件中。
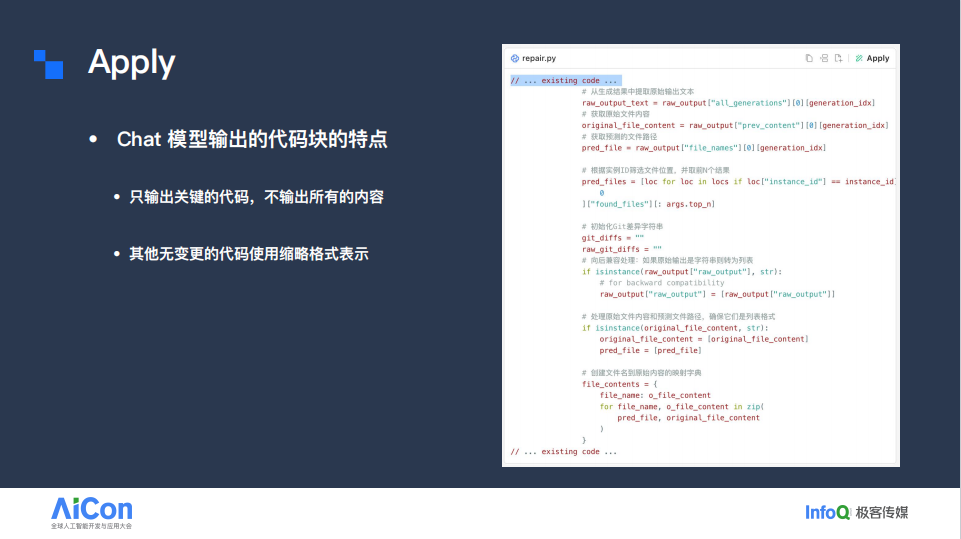
为实现这一目标,可以先分析当时 Trae 模型生成代码块的特征。
如上图所示,模型的实际输出并非完整文件,而是仅给出需要修改的核心片段。以该示例为例,模型按指令插入了注释,因此中间部分被完整展示;至于未涉及修改的上下文,则以 existing code 等简写形式标注,表示这些区域无需改动。
之所以采用这种输出方式,主要是为了显著减少 token 消耗,从而提升生成效率。众所周知,模型的上下文窗口存在限制。当时模型能力尚未达到如今水平,应用场景仍以问答式交互为主;受限于上下文窗口,模型难以一次性输出完整全文。此外,在生成回答时,大量 token 还需用于拼接所采集的上下文信息。
有人会问,为什么不采用 Diff 格式进行输出,就像 Git 那样?事实上,我们在实践中也尝试过这种方式,但发现存在两个主要问题。
首先,模型并不擅长输出 Diff 格式。Diff 格式对语法和符号(如“+”“-”)等要求非常严格,一旦输出的格式不符合标准,就会直接影响代码编辑的准确性;其次,用户在使用过程中需要良好的阅读体验。通常,用户在看到模型输出的代码后,会先确认其是否正确、是否符合预期,然后才会采纳。然而 Diff 格式本身可读性较差,阅读和理解起来比较费力。因此,我们最终放弃了采用 Diff 格式作为直接输出的方案。
由此带来的核心挑战是:如何将模型输出的带有缩略格式的代码块精准地合并到原始文件中?
由于代码在格式和内容上差异巨大,不同开发者的代码风格也千差万别,如果仅依赖规则匹配来完成合并,几乎不可能覆盖所有情况。
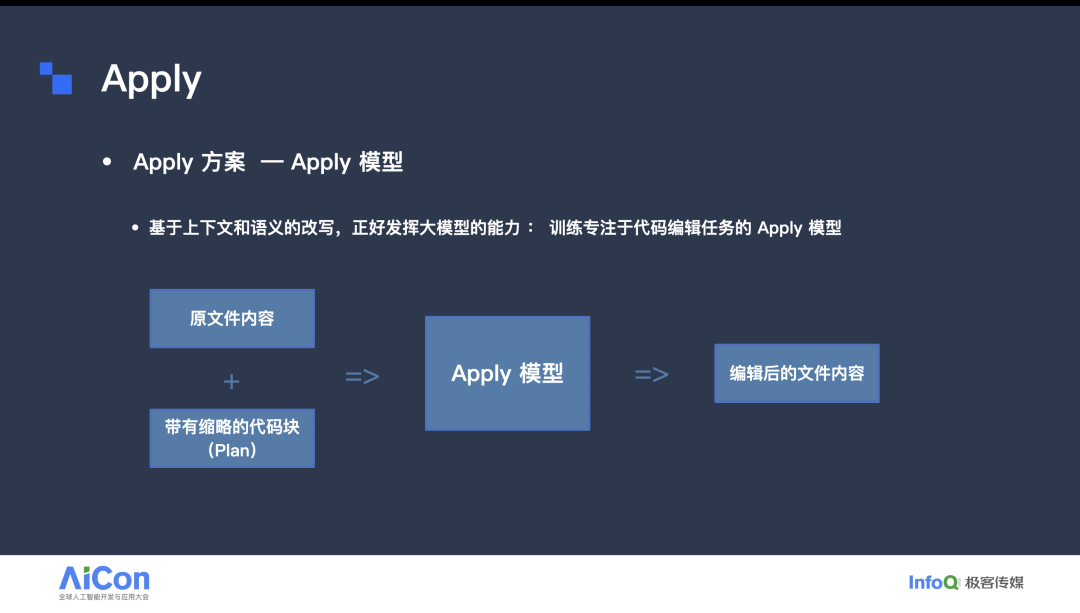
基于上下文与语义的改写任务,正是大模型能够发挥优势的场景。因此,我们训练了一个专用于代码编辑的 Apply 模型。该模型接收两类输入:一是原始文件内容,二是 Chat 模块 /Chat 模型输出的带有缩略的代码块(我们称之为 Plan)。在获取上述输入后,模型对内容进行改写与编辑,并输出编辑后的完整文件。随后,我们用该完整内容替换原文件,并以 Diff 形式展示给用户,便于判断哪些变更需要采纳、哪些可以忽略。
要实现这一目标,对模型的选型与训练提出了要求:其一,低时延;其二,良好的指令遵循能力;其三,支持长上下文。原因也不难理解:低时延可确保用户点击 Apply 按钮后快速看到编辑结果;而在编辑任务中,模型需要严格遵照 Plan 的指令输出,因此必须具备良好的指令遵循能力;同时,跨片段、跨文件的编辑需要更长的上下文支持。由于输入和输出会共享模型的 Token 窗口,而我们的方案要求将完整的原始文件交给模型处理,这会占用相当一部分上下文空间,导致留给生成内容的窗口减少。因此,模型必须具备较长的上下文处理能力,以确保能够覆盖更广的修改范围。
基于上述三点选型后,我们在训练数据的构造上投入了大量精力。具体而言,我们针对不同 Chat 模型的输出习惯,生成多种缩略格式的数据。不同的 Chat 模型对缩略格式的表达并不一致,甚至同一模型在不同次输出中采用的缩略方式也可能不同:有的会输出“existing code”,有的只会用“.”占位。为提升任务的准确性,我们对模型进行微调。
除了缩略格式,我们还面向不同场景构造数据:例如为“添加注释”“import 依赖”“删除代码”“代码重构”等需求准备样例。通常需要先理解用户意图,再生成相应数据,以提升模型在具体场景中的准确性。此外,我们也针对常用编程语言构造数据,使模型能够处理更丰富多样的场景。
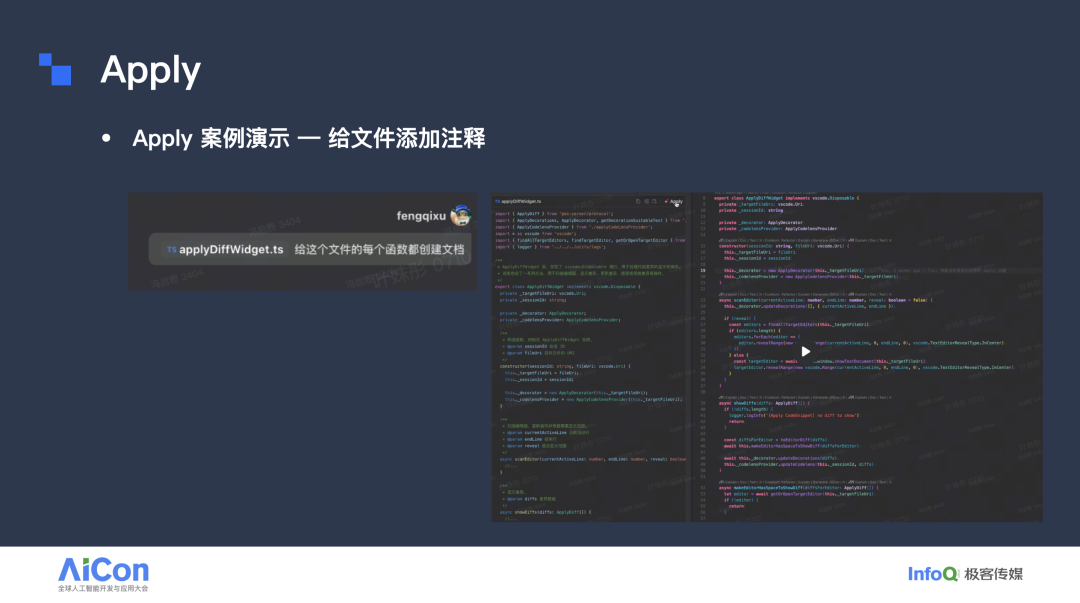
经过一系列训练后,Apply 方案上线。这里有一个实际案例:我需要为某个文件的每个函数补充文档注释,只需给出“请为每个函数补上文档”的指令,模型就自动生成了相应内容;模型会输出相应的内容,部分函数细节可能采用了省略形式。随后,当我点击 apply 按钮后,模型能够根据生成的结果,为整个文件自动补充完整的注释。
这一方案的上线确实显著提升了用户体验,但也存在三方面的局限:其一,额外的资源开销——除了调用 Chat 模型生成代码块,还需再调用一个模型执行编辑任务,整体资源消耗上升;其二,效率不足——在部分场景中,Chat 模型只需改一行,Apply 模型却会重写整个文件,导致效率偏低;其三,长文件限制——输入与输出共享上下文窗口,文件过长不仅可能无法处理,还会影响生成结果的准确性。工程上我们通过设置长度上限来规避风险,但当超长文件被拒绝服务时,用户体验仍会受影响。
尽管存在这些限制,Apply 在当时确实带来了明显的体验提升,也启发我们反思:代码补全不应只做“续写”,还应进一步优化整体体验。
基于此,我们推出了更智能的代码补全功能 Cue。Cue 支持多点编辑,不再局限于续写,而是可以在多行中同时进行删除、替换与插入;同时具备光标预测能力,例如当用户在某一行引入方法时,它会提示在文件开头补充相应的 import;此外还能跨文件编辑,智能识别需要变更的目标文件,从而突破“仅限当前文件与当前行”的限制。
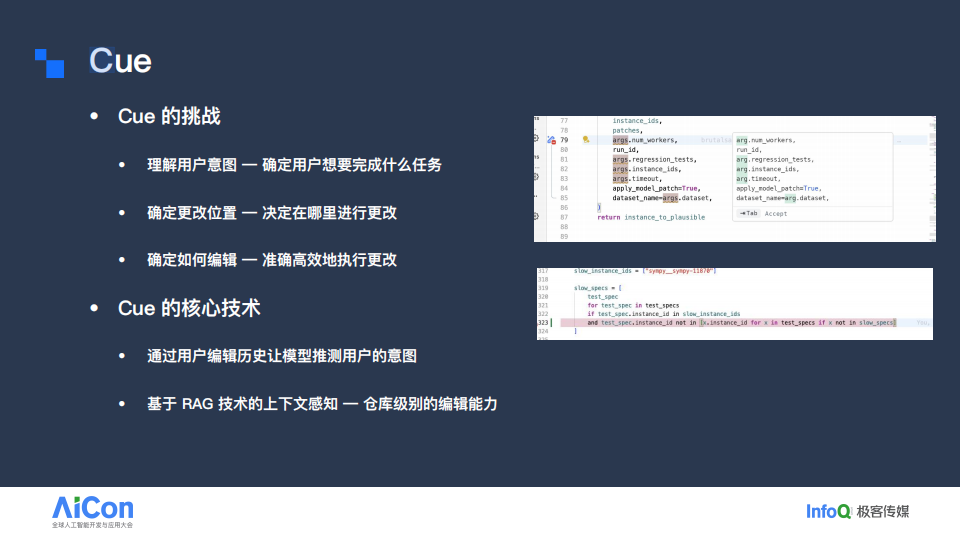
与 Apply 相比,Cue 的挑战更大,因为它需要理解更隐蔽的用户意图。用户可能连续输入大量字符或频繁移动光标,这些操作往往暗含需求但不直接显现。为此,我们通过分析用户的编辑历史来推断真实意图;在此基础上,Cue 还需要支持仓库级的跨文件编辑。我们基于 RAG 技术实现上下文感知,判断与当前编辑内容相关的其他位置是否也应同步修改,从而提供更智能的补全能力。
随着模型能力的快速提升,我们来到了 Authentic Edit 的时代——其特点是模型可以自主完成文件级编辑。与此同时,我们也开始探索更适合这一范式的代码编辑方案。
随着模型能力的持续增强,Builder 这一产品形态应运而生。它是一种 Agentic 的代码编程助手,能够自主搜索整个代码仓库,自行决定需要编辑的文件,并可对不同文件或同一文件进行多次编辑,同时保持逻辑一致性。围绕这一形态,我们也提供了更契合的编辑能力。
具体而言,我们为 Builder 配备了更丰富的编辑工具集:Write to File(用于新建文件)、Delete File(用于删除文件)以及 Update File(用于编辑文件)。其中,Update File 无疑是最复杂的应用场景。
在 Builder 模式下,Apply 的局限被进一步放大。原因在于,Agentic 的一次任务往往涉及多次文件修改;如果每次都必须经过“Chat 模型输出”与“Apply 模型编辑”这两个阶段,系统开销会非常大。此外,这种双阶段叠加不仅增加资源消耗,也放大误差,导致整体编辑失败率偏高。另一个问题是 Apply 对长文件的处理能力不足,这在 Agentic 场景下尤为明显。

基于上述判断,我们在这一阶段转向了 Search/Replace 方案。该方案的核心机制相对简单:首先有一个原始文件,模型会明确告知需要查找并替换的旧内容,同时给出对应的替换内容。最后,系统根据这两部分信息执行查找与替换,从而得到编辑后的结果。该方案的优势也十分明显。一方面,它无需进行二次调用,从而避免了额外的开销和误差叠加。另一方面是该方案不受上下文窗口的限制。也就是说,在任意长度的文件中,模型只需输出需要查找的那一行内容,就能够被准确定位。
然而,这一方案并非完美,同样存在一些挑战。首先,对模型输出的要求较高。模型必须严格遵循指定格式,并确保 _old_str_ 与原文精确匹配。此外,工具调用通常使用 JSON 作为格式化方式,但在将 _old_str_ 等字符串写入 JSON 时,往往需要进行转译,否则会导致解析失败。而转译本身又是模型容易出错的环节。
其次,该方案在效率上也存在问题。当进行大规模变更时, _old_str_ 与 _new_str_ 可能会非常冗长,从而再次触发上下文窗口的限制。虽然可以通过拆分为多次编辑来解决,但效率会降低。我们也尝试过采用数组方式以提升效率,但数组格式对模型输出的规范性提出了更高要求。
第三,工程复杂度相对 Apply 方案更高。为了应对输出不确定性,需要引入更多防御机制,例如模糊匹配、相似度查找,以及在出错时进行自动修复和重试。
因此,这两种方案并非互相替代,而是适用于不同场景。在 Chat 模式下,我们更倾向于使用 Apply 方案,以提升用户体验;而在 Builder 模式下,则优先采用 Search/Replace 方案,因为其准确性更高,且不受文件长度限制。
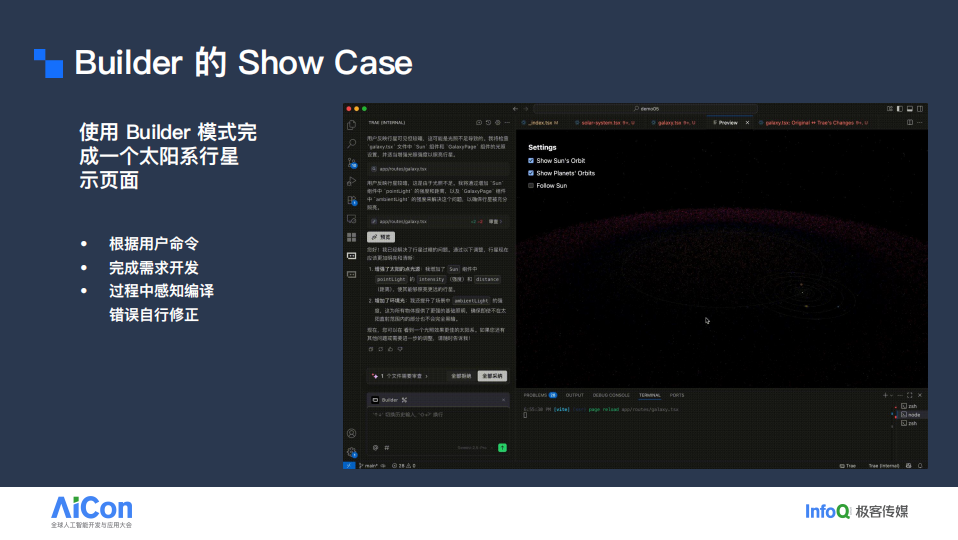
以上是我们对 Agentic Edit 的探索。上图展示了一个 Builder 场景的 Showcase:需求是实现一个简易的太阳系行星运行页面。在此过程中,我会针对系统生成的不正确部分提出反馈;系统将依据这些反馈和我的需求持续改进,直至完成页面,并逐步完善相关展示功能。
总结与展望
本次分享回顾了 TRAE 编程助手 的三个发展阶段及对应的产品形态,并探讨了其背后代码编辑能力的演进过程:包括专注于完成代码编辑任务的 Apply 模型,提供更加即时和智能补全体验的 Cue 功能,以及充分利用大模型能力的 Agentic Edit 能力。面向未来,我们将从三方面继续探索:进一步提升编辑的准确性与效率;探索 Multi-Agent 协作框架;持续激发模型的思考与规划能力。感谢大家的聆听!
嘉宾介绍
冯绪,字节跳动 Trae 插件架构师,曾就职于腾讯,具备丰富的一线研发和实践经验。当前专注在 AI 编程助手的建设中,参与 AI 编程助手从 0 到 1 搭建以及 Apply 能力的建设。致力于探索大模型与编程工具的深度融合,在 AI Agent 架构设计、代码编辑技术优化等方向持续深耕,为提升开发者编程效率贡献技术力量。




