
优步详细介绍了最近向在 Kubernetes 上运行基于Ray的机器学习负载的迁移过程。这一基础设施的标志性演变旨在增强可扩展性、效率和开发体验。该公司最近发布了由优步工程团队撰写的两篇文章,深入探讨了在这次迁移过程中遇到的动机、挑战和解决方案。
最初,优步的机器学习工作流由米开朗基罗深度学习作业(MADLJ)服务管理,该服务使用 Apache Spark 进行 ETL 流程,使用 Ray 进行模型训练。
优步之前的机器学习基础设施面临几个挑战,它们影响了可扩展性和效率。一个主要问题是资源管理不够自动化——机器学习工程师必须自己确定正确的计算资源,同时考虑到 GPU 的可用性和当前集群容量。这种人工流程经常导致次优选择和不必要的延迟。对资源和集群的静态配置设置让问题雪上加霜,这些设置被硬编码到了系统中。这种僵化导致了不均匀的负载分配和资源的低效利用,限制了平台的整体效率。
此外,系统无法灵活规划容量也是个问题。平台要么过度配置资源——结果浪费计算能力,要么配置不足,导致作业失败或延迟。这些限制加起来就搞出了一个既低效又难以扩展的环境,促使优步通过迁移到 Kubernetes 和 Ray 来寻求一个适应性更强和更加自动化的解决方案。
为了解决这些问题,优步将其机器学习负载迁移到 Kubernetes,目标是实现一个更具声明性和更加灵活的基础设施。这次迁移过程还开发了一个统一平台,让用户可以在不深入了解底层基础设施复杂性的情况下指定作业类型和资源需求。然后系统将根据当前集群负载和作业规范自动分配最优资源。
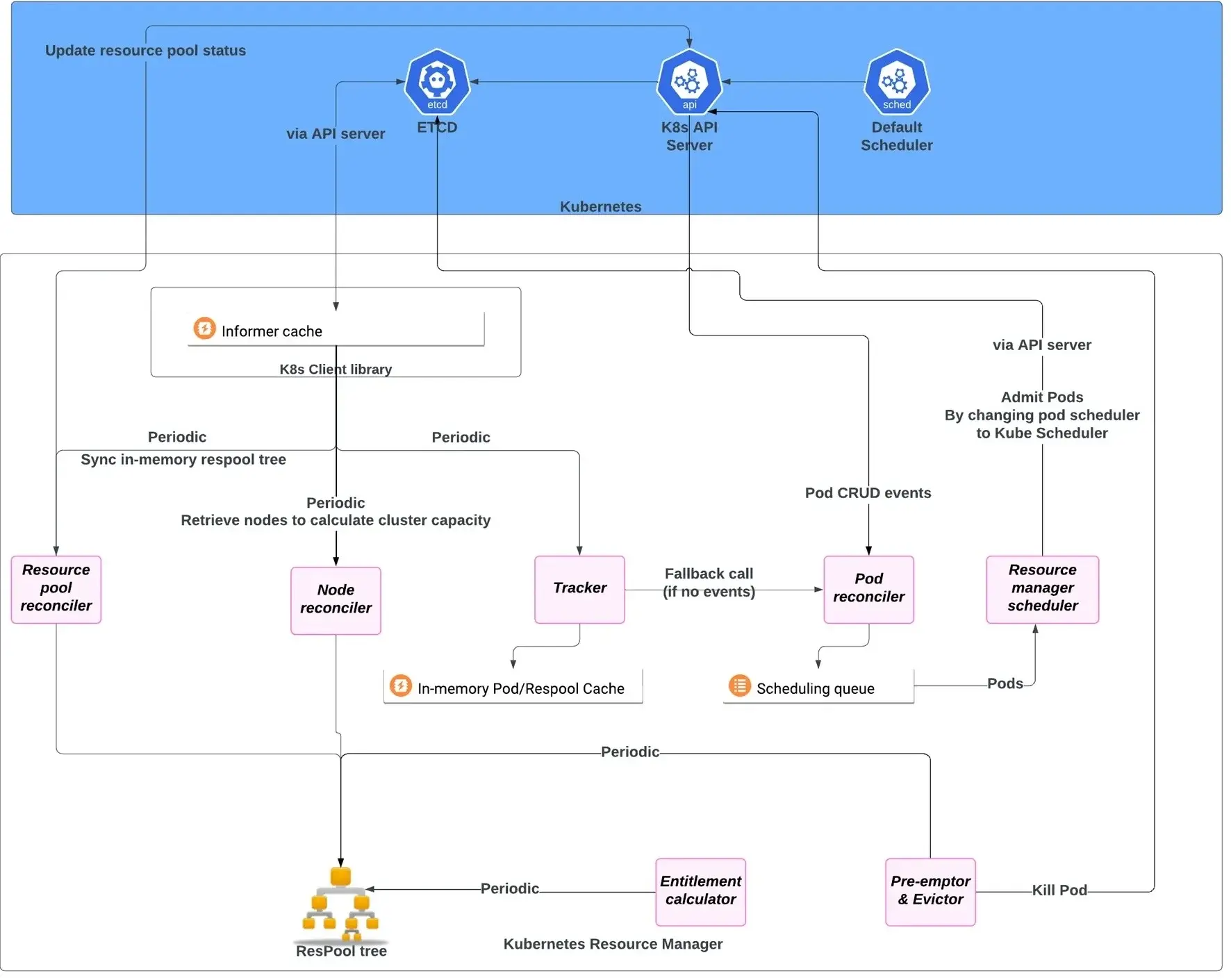
Kubernetes 中的弹性资源共享。
优步将其机器学习负载迁移到 Kubernetes 时,一个重点是通过弹性资源管理提高资源利用率。为了实现这一点,团队实施了一系列策略,使整个组织能够更灵活、更高效地使用计算资源。其中一项策略是引入层化资源池,根据团队或组织边界组织集群资源。这种结构使团队能够更精细地控制其分配的计算资源,并提高了对使用模式的可见性。
另一大改进是这些资源池之间的弹性共享。如果一个池有空闲资源,它们可以临时被另一个池借用,提高整体利用率,而无需永久重新分配容量。这些借用的资源是可抢占的,意味着它们可以在需要时被原始池收回。为了确保公平并避免资源争用,团队使用最大/最小公平原则强制执行资源配额。这意味着每个池都保留了资源的保证份额,同时仍能够根据当前需求动态访问额外容量。这些机制使优步能够更有效地扩展并应对机器学习负载的波动需求。
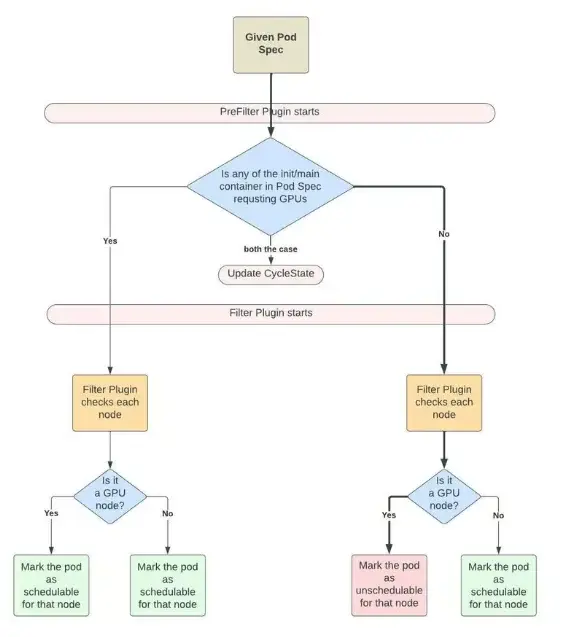
GPU Pod 的过滤器插件。
此外,优步实施了优化异构硬件使用的策略。集群配置了支持 GPU 和仅 CPU 的节点。不需要 GPU 的任务,如数据加载和预处理,被分配给 CPU 节点,而 GPU 节点只用于训练任务。
优步还开发了一个 GPU 过滤器插件,以确保只有 GPU 负载被安排在 GPU 节点上。Kubernetes 调度器也得到了增强,使用负载感知策略分发非 GPU Pod,并使用装箱策略分发 GPU 负载,以尽量减少资源碎片化。
通过这些变化,优步为其机器学习负载实现了一个更高效、更灵活的基础设施,使资源利用和可扩展性得到了更好的提升。




