
从 Hadoop 迁移到基于云的现代架构(比如 Lakehouse 架构)的决定是业务决策,而非技术决策。我们在之前的文章中探讨了每一个组织都必须重新评估他们与 Hadoop 的关系的原因。当来自技术、数据和业务的利害关系方决定将企业从 Hadoop 转移出去之后,在开始真正的转变之前,需要考虑https://databricks.com/blog/2021/07/22/top-considerations-when-migrating-off-of-hadoop.html。本文中,我们将特别关注实际的迁移过程本身。你将学习成功迁移的关键步骤,以及 Lakehouse 架构在激发下一轮数据驱动创新中所扮演的角色。
迁移步骤
坦白的说吧,迁移从来不是一件简单的事情。不过,可以对迁移进行结构化,从而最大限度地减少不利影响,确保业务连续性,并有效地管理成本。为此,我们建议将你从 Hadoop 的迁移分解成以下五个关键步骤:
管理
数据迁移
数据处理
安全及管治
SQL 和 BI 层
第一步:管理
让我们从管理的角度回顾一下 Hadoop 中的一些基本概念,以及它们与 Databricks 的对比。
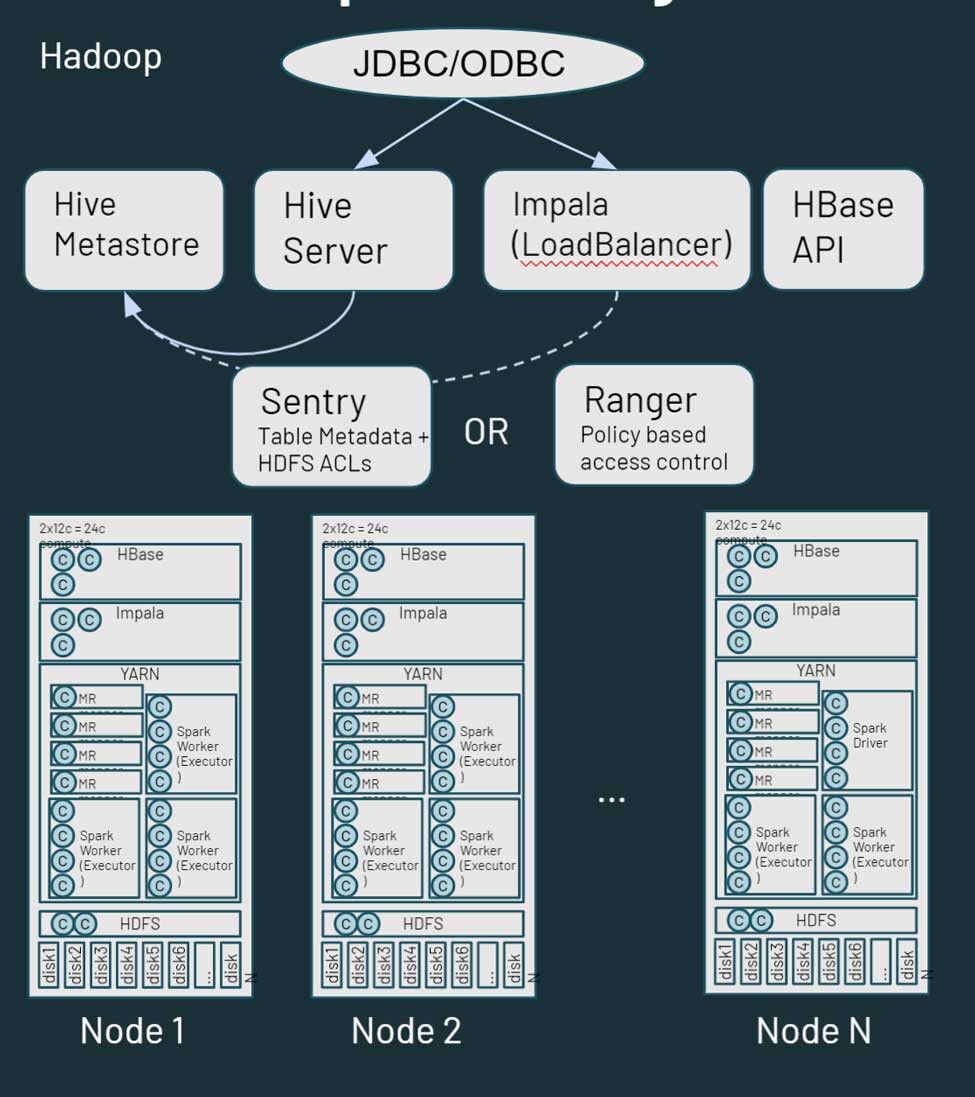
Hadoop 本质上是一个单体分布式存储和计算平台。它由多个节点和服务器组成,每个节点都有自己的存储、CPU 和内存。任务被分配到所有这些节点。通过 YARN 来实现资源管理,它力图确保工作负载能够获得其计算份额。
Hadoop 也包括元数据信息。有一个 Hive 元存储,它包含了存储在 HDFS 中的资产的结构化信息。你可以使用 Sentry 或 Ranger 来控制对数据的访问。从数据访问的角度来看,用户和应用程序可以直接通过 HDFS(或相应的 CLI/API)或通过 SQL 类型的接口访问数据。另外,SQL 接口可以通过 JDBC/ODBC 连接,使用 Hive 来执行通用 SQL(或在某些情况下使用 ETL 脚本),或者在 Impala 或 Tez 上使用 Hive 进行交互式查询。Hadoop 还提供了一个 HBase API 和相关的数据源服务。有关 Hadoop 生态系统的更多信息,请点击这里。
接下来,我们来讨论如何在 Databricks Lakehouse 平台中映射或处理这些服务。在 Databricks 中,首先要注意的一个区别是,你在 Databricks 环境中看到的是多个集群。每个集群可以用于特定的用例、特定的项目、业务部门、团队或开发小组。更重要的是,这些集群都是短暂的。对于作业集群来说,集群的存在时间可以在工作流程的持续期间保持。这将执行工作流程,并且在完成后,环境将自动拆毁。同样,如果你考虑一个交互式用例,即你有一个可供开发者共享的计算环境,这样的环境可以在工作日开始,并且开发者全天运行他们的代码。在非活动期间,Databricks 会通过平台内置的(可配置的)自动终止功能自动关闭它。
不同于 Hadoop,Databricks 并不提供诸如 HBase 或 SOLR 那样的数据存储服务。你的数据驻留在对象存储中的文件存储。许多类似 HBase 或 SOLR 这样的服务都可以在云中找到与之相当的替代品。这可以是云原生或 ISV 解决方案。
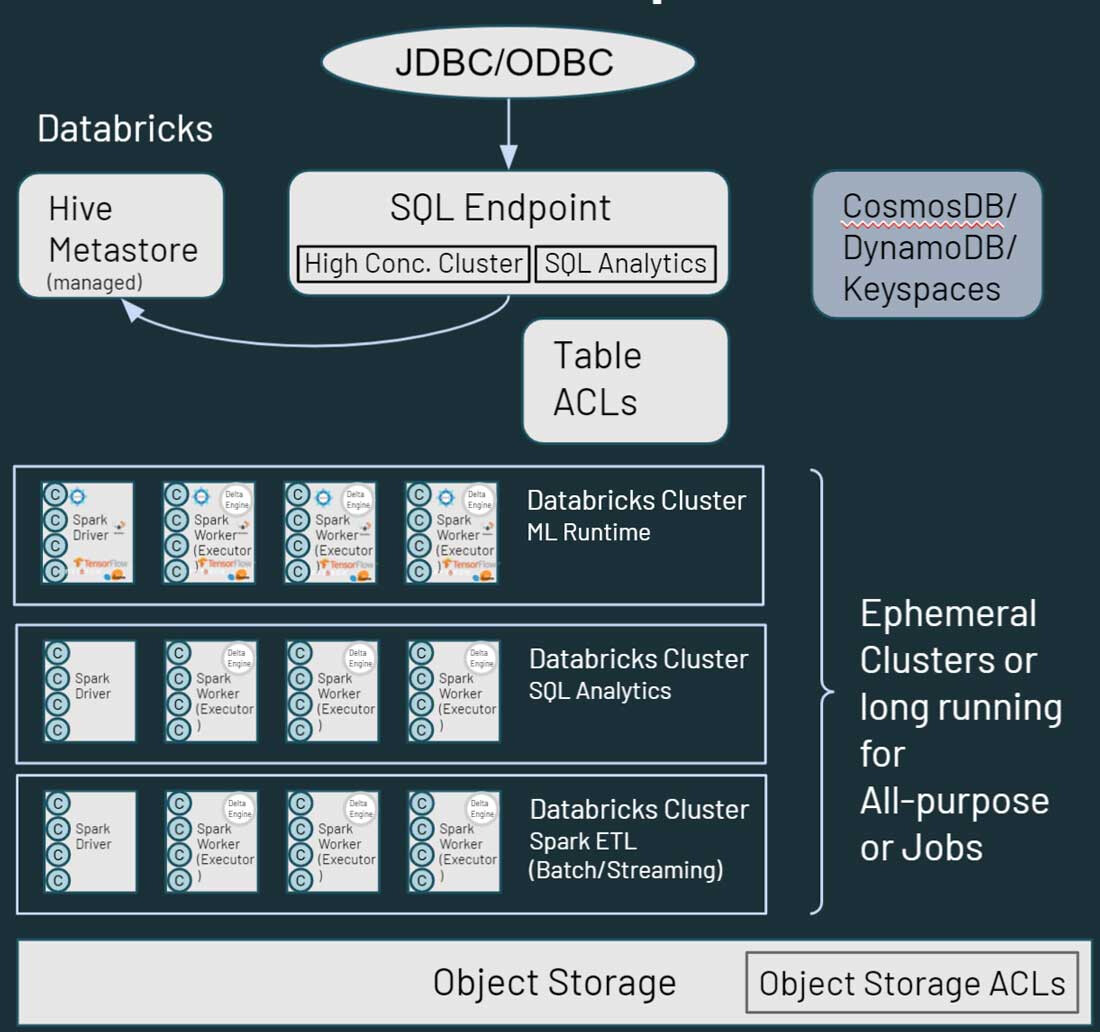
从上图可以看出,Databricks 中的每个集群节点都对应于 Spark 驱动或工作器。关键在于,不同的 Databricks 集群彼此完全隔离,这样,你就可以确保在特定的项目和用例中符合严格的 SLA。你可以将流媒体或实时用例与其他以批处理为导向的工作负载隔离,并且你不必担心手工隔离可能会占用集群资源的长期运行作业。你只需要为不同的用例派生新的集群作为计算。Databricks 还将存储与计算解耦,使你能够利用现有的云存储,如 AWS S3、Azure Blob Storage 和 Azure Data Lake Store(ADLS)。
Databricks 也有一个默认的管理型 Hive 元存储,用于存储驻留在云存储中的数据资产的结构化信息。同时,它也支持外部元存储,比如 AWS Glue、Azure SQL Server 或 Azure Purview。你还可以在 Databricks 内指定安全控制,如表 ACL,以及对象存储权限。
当涉及到数据访问时,Databricks 提供了类似于 Hadoop 的功能,它可以处理用户如何处理数据。你可以通过 Databricks 环境中多种路径访问存储在云存储的数据。使用 SQL Endpoints 和 Databricks SQL,用户可以进行交互式查询和分析。他们也可以使用 Databricks 笔记本对存储在云存储中的数据进行数据工程和机器学习功能。Hadoop 中的 HBase 映射到 Azure CosmosDB,或 AWS DynamoDB/Keyspaces,可以作为下游应用的服务层加以利用。
第二步:数据迁移
在 Hadoop 的背景下,我认为大部分读者已经对 HDFS 很熟悉。HDFS 是存储文件系统,用于 Hadoop 部署,它利用了 Hadoop 集群节点上的磁盘。所以,当你扩展 HDFS 时,你需要增加整个集群的容量(也就是说,你需要同时扩展计算和存储)。若要购买和安装额外的软件,可能要花费很多时间和精力。
在云中,你拥有几乎无限的存储容量,比如 AWS S3、Azure 数据湖存储或 Blob 存储或谷歌存储等形式的云存储。无需维护或健康检查,从部署开始,它就提供了内置的冗余和高水平的持久性和可用性。我们建议使用原生云服务来迁移你的数据,为了方便迁移,有几个合作伙伴/ISVs。
那么,你该如何开始呢?最常见的推荐路线是从双摄取策略开始(也就是,在你的内部环境之外,添加一个源来上传数据到云存储)。这样你就可以在不影响你现有设置的情况下开始使用云中的新用例(利用新数据)。如果你在组织中寻求其他团队的支持,你可以将其作为一项备份策略。因为 HDFS 的庞大规模和相关的工作,传统上对备份提出了挑战,所以把数据备份到云端是一种有效的举措。
在大多数情况下,你可以利用现有的数据交付工具来复刻(fork)Feed,不仅写到 Hadoop,也写到云存储。举例来说,如果你正在使用 Informatica 和 Talend 这样的工具/框架处理数据并向 Hadoop 写入数据,那么可以轻松地添加一些附加步骤,以便将数据写入云存储。一旦数据在云中,就有许多办法来处理数据。
就数据方向而言,数据要么从内部拉取到云端,要么从内部推送到云端。可用于将数据推送到云端的工具有云原生解决方案(Azure Data Box、AWS Snow Family 等)、DistCP(一种 Hadoop 工具)、其他第三方工具以及任何内部框架。推送选项通常更容易得到安全团队的必要批准。
对于将数据拉取到云端,你可以使用 Spark/Kafka Streaming 或 Batch 从云端触发摄取管道。对于批处理,你可以直接摄取文件,或者通过 JDBC 连接器连接到相关的上游技术平台,并提取数据。当然,还有一些第三方工具可以实现这一目的。在这两个选项中,推送选项是一个被广泛接受和理解的选择,因此,让我们来深入研究一下拉取方法。
你首先要做的是在你的企业内部环境与云端之间建立连接。可通过互联网连接和网关来实现。你还可以使用 AWS Direct Connect、Azure ExpressRoute 等专用连接选项。有些情况下,如果你的组织对云计算并不陌生,那么这些设置已经就绪,因此你可以为你的 Hadoop 迁移项目重新使用它。
要考虑的另一个问题是 Hadoop 环境中的安全性。若为 Kerberized 环境,则可以从 Databricks 方面进行调整。你可以配置 Databricks 初始化脚本在集群启动时运行,安装并配置必要的 kerberos 客户端,访问存储在云存储位置的 krb5.conf 和 keytab 文件,并最终执行 kinit() 函数,从而允许 Databricks 集群与你的 Hadoop 环境直接交互。
最后,你还需要一个外部共享的元存储。尽管 Databricks 的确有一个默认部署的元存储服务,但是它也支持一个外部的。Hadoop 和 Databricks 将共享外部元存储,并可以部署到企业内(在 Hadoop 环境中)或云中。举例来说,如果你在 Hadoop 中运行已有 ETL 流程,但你无法将它们迁移到 Databricks,则可以利用此设置和现有的企业内部元存储,让 Databricks 使用 Hadoop 的最终规划数据集。
第三步:数据处理
首先要记住的是,从数据处理的角度来看,Databricks 的一切都在利用 Apache Spark。所有的 Hadoop 编程语言,如 MapReduce、Pig、Hive QL 和 Java,都可以转换为在 Spark 上运行,无论是通过 Pyspark、Scala、Spark SQL 甚至 R。在代码和 IDE 方面,Apache Zeppelin 和 Jupyter 笔记本都可以转换为 Databricks 笔记本,但是导入 Jupyter 笔记本要简单一些。导入之前,Zeppelin 笔记本需要转换为 Jupyter 或 Ipython。如果你的数据科学团队希望继续使用 Zeppelin 或 Jupyter 进行编码,则可以使用 Databricks Connect,这样你能够在 Databricks 上运行本地 IDE(Jupyter、Zeppelin 甚至 IntelliJ、VScode、RStudio 等)来运行代码。
当涉及到迁移 Apache Spark™ 作业时,需要考虑的主要问题是 Spark 版本。你的内部 Hadoop 集群可能运行的是较老版本的 Spark,你可以使用 Spark 迁移指南确定所做的更改,以查看对代码的影响。要考虑的另一个方面是将 RDD 转换为数据框(DataFrame)。RDD 通常用于 Spark 的 2.x 版本,尽管它们仍可用于 Spark 3.x,但是这样做会妨碍你充分利用 Spark 优化器的功能。我们建议你将 RDD 转换为数据框。
最后但并非最不重要的是,在迁移过程中,我们和客户一起遇到的一个常见问题就是本地 Hadoop 环境的硬编码引用。当然,这些都需要更新,否则代码将在新的设置中出现中断。
接下来,让我们看看转换非 Spark 工作负载的问题,在大多数情况下,这涉及重写代码。对 MapReduce 来说,在某些情况下,如果你以 Java 库的形式使用共享逻辑,那么这些代码就可以被 Spark 利用。然而,你可能仍然需要重写代码的某些部分,以便在 Spark 环境中运行,而不是 MapReduce。Sqoop 的迁移相对容易一些,因为在新的环境中,你使用 JDBC 源运行一组 Spark 命令(相对于 MapReduce 命令)。如同在 Sqoop 中指定参数一样,你可以在 Spark 代码中指定参数。在 Flume 中,我们看到的大部分用例都是围绕着从 Kafka 消耗数据并写入 HDFS。使用 Spark 流媒体可以很容易地完成这个任务。在 Spark 中迁移 Flume 的主要任务是将一个基于配置文件的方法转换成 Spark 中更多的程序化方法。最后,我们有 Nifi,它主要用于 Hadoop 之外,主要用作拖放、自我服务的摄取工具。Nifi 也可以用于云,但是我们看到很多客户正在利用迁移到云中的机会,用云中的其他较新的工具取代 Nifi。
迁移 HiveQL 可能是最简单的任务。Hive 和 Spark SQL 之间具有高度兼容性,并且大多数查询都可以在 Spark SQL 上正常运行。在 HiveQL 和 Spark SQL 之间,DDL 有一些微小的变化,例如 Spark SQL 使用 “USING”子句,HiveQL 使用 “FORMAT” 子句。我们建议对代码进行修改,使其使用 Spark SQL 格式,因为它允许优化器为你的代码在 Databricks 中准备最佳的执行计划。你仍可以利用 Hive Serdes 和 UDF 的优势,使你在将 HiveQL 迁移到 Databricks 时更加容易。
对于工作流编排,你必须考虑可能改变提交作业的方式。你可以继续利用 Spark 提交语义,但是还有其他更快、更无缝集成的选择。你可以使用 Databricks 作业和 Delta Live Tables 进行无代码 ETL,以取代 Oozie 作业,并在 Databricks 内定义端到端的数据管道。为了实现自动化/调度,对于涉及外部处理依赖的工作流,你必须在 Apache Airflow、Azure Data Factory 等技术中创建相应的工作流/管道。利用 Databricks 的 REST API,可以使用 Databricks 集成并配置所有的调度平台。
还有一种叫做 MLens 的自动化工具(由 KnowledgeLens 创建),它可以帮助你将工作负载从 Hadoop 迁移到 Databricks。MLens 可以帮助迁移 PySpark 代码和 HiveQL,包括把一些 Hive 细节转换成 Spark SQL,这样你就可以充分利用 Spark SQL 优化器的功能和性能优势。它们还计划很快支持 Oozie 工作流向 Airflow、Azure Data Factory 等等的迁移。
第四步:安全及管治
让我们来看看安全和管治。在 Hadoop 世界中,我们有用来连接到诸如 Ambari 或 Cloudera Manager 这样的管理控制台的 LDAP 集成,甚至 Impala 或 Solr。Hadoop 还拥有 Kerberos 认证其他服务。在授权方面,Ranger 和 Sentry 是使用最多的工具。
有了 Databricks,单一登录(Single Sign On,SSO)可以集成到任何支持 SAML 2.0 的身份提供器。其中包括 Azure Active Directory、Google Workspace SSO、AWS SSO 和 Microsoft Active Directory。为了进行授权,Databricks 向 Databricks 对象提供 ACL(访问控制列表),允许你设置笔记本、作业、集群等实体的权限。有了数据权限和访问控制,你可以定义表的 ACL 和视图,以限制列和行的访问,并利用类似的凭据传递等方式,Databricks 将你的工作空间登录凭据传递到存储层(S3、ADLS、Blob 存储),以确定你是否获得访问数据的授权。如果你需要基于属性的控制或数据屏蔽等功能,你可以利用 Immuta 和 Privacera 等合作伙伴工具。从企业管治的角度来看,你可以将 Databricks 连接到企业数据目录,如 AWS Glue、Informatica Data Catalog、Alation 和 Collibra。
第五步:SQL 和 BI 层
在 Hadoop 中,正如前面所讨论的,你有 Hive 和 Impala 作为接口来执行 ETL 以及特别的查询和分析。在 Databricks 中,你通过 Databricks SQL 实现类似的功能。Databricks SQL 还通过 Delta 引擎提供了极高的性能,并支持自动扩展集群的高并发使用案例。Delta 引擎也包括了 Photon,这是一种用 C++ 重构的新的 MPP 引擎,并向量化以利用数据级和指令级并行性。
Databricks 提供了与 Tableau、PowerBI、Qlik 和 looker 等 BI 工具的原生集成,以及高度优化的 JDBC/ODBC 连接器,这些工具可以使用。新型 JDBC/ODBC 驱动程序的开销非常小(¼秒),使用 Apache Arrow 的传输率提高了 50%,以及一些元数据操作,可以显著加快元数据的检索操作。Databricks 也支持 PowerBI 的 SSO,对其他 BI/仪表盘工具的 SSO 支持也即将推出。
Databricks 除了上述的笔记本体验外,还具有内置的 SQL 用户体验,为 SQL 用户提供了 SQL 工作台的镜头,还提供了轻量指示板和警报功能。这样就可以对数据湖内的数据进行基于 SQL 的数据转换和探索性分析,而无需将其转移到下游的数据仓库或其他平台。
下一步
在考虑迁移到像 Lakehouse 架构这样的现代云架构时,需要记住以下两件事:
记住要把关键的合作伙伴带到这一过程中来。这既是一个技术决策,也是一个业务决策,你需要你的合作伙伴接受这一过程及其最终状态。另外,请记住,并非只有你一个人,Databricks 和我们的合作伙伴都拥有熟练的资源,他们在构建可重复的最佳实践方面已经做了足够多的工作,节省了企业的时间、金钱资源,并且减少了总体压力。在开始迁移之前,下载 Hadoop 到 Databricks 技术迁移指南(Hadoop to Databricks Technical Migration guide),以获得逐步指导、笔记本和代码。
原文链接:
关联阅读:




