
采访嘉宾|Denodo 的创始人兼 CEO Angel Viña
数据编织:生成式 AI 时代,深挖数据的生产力
“无数据,不 AI”,如果说 AI 是火箭,那么数据就是 AI 发展的高质量燃料。最近几年全球企业数智化转型如火如荼,加之如今生成式 AI 浪潮席卷之下,企业对数据的需求空前激增,如何管理数据,释放数据价值成为企业的必答题。
在生成式 AI 时代,企业在数据管理过程中面临数据规模庞大、数据多元、数据孤岛、数据治理复杂、数据获取耗时等诸多挑战。很多 AI 项目因数据自身缺陷、难以理解等原因而出现成果与预期不符,最终导致项目延误或成本超支。一项调研数据显示,企业认为有 60%的业务数据是有价值的,而这些数据中仅有 56%被分析,18%的企业认为高质量数据缺乏是其使用生成式 AI 的障碍之一。
数据越来越成为生成式 AI 时代的决胜关键,企业需要有新的数据管理技术来应对多重挑战,数据编织(Data Fabric)正是在这样的背景下日益受到关注。
数据编织,简单理解,就是把分散在各个系统中的数据“编织”起来,形成一个统一的逻辑访问层,并对数据进行分析和管理,还为用户提供可视化的数据视图,这样就打破了数据孤岛,用户可以便捷获得数据访问权限,来跨系统查询数据,由此实现将多元异构数据快速交付给数据的消费者。
Denodo 是数据编织领域的头部厂商之一,创立于 1999 年,已在逻辑数据编织领域深耕 25 年,其核心产品是以公司命名的逻辑数据管理平台 Denodo 平台,通过逻辑数据编织技术,为企业提供可信、可用、易于理解的数据服务,帮助提升决策效率。
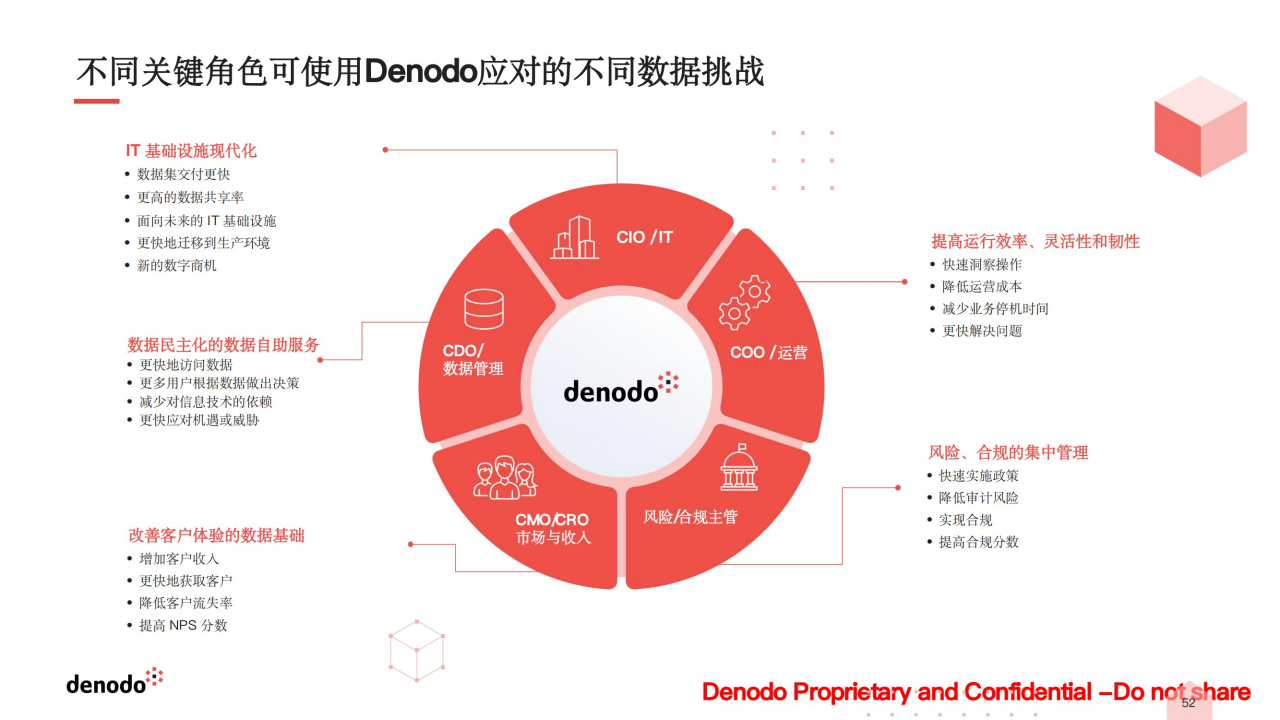
Denodo 主张的逻辑数据编织技术包括数据获取、数据处理、数据发现、数据管理和数据访问、智能查询等能力。尤其,Denodo 特别强调“数据虚拟化”作为数据编织的能力核心,这也是 Denodo 及其创始人的起家技术。
Denodo 的创始人兼 CEO Angel Viña 被称为“数据虚拟化之父”、“逻辑数据编织之父”。Angel Viña 大学期间的研究方向是实时数据管理。早在 40 年前,他在做一个研究核反应堆容器预测性维护的项目时,遇到了数据碎片化、分散问题,很难统一处理,而建数据仓库要花很长时间,无法满足实时管理数据的要求。传统方法行不通,Angel Viña 想到,建立一个虚拟层来实时连接数据,虚拟层记录了数据的关键要素,将数据实现虚拟化,这样无需像数据仓库那般物理地复制、移动数据,最终让项目周期从 4 周缩短到了 1 周。Angel Viña 提出的数据虚拟化方法奠定了逻辑数据编织的基础。

这一技术突破在 25 年前,Denodo Technologies 正式成立,意义是十分巨大的。放到对数据管理实时性和经济性要求更高的今天看依然如此。
与物理数据库、数据仓库、数据湖等相比,上一代数据管理技术更侧重将数据存储到实体系统中,并将不同实体系统的数据迁移到集中系统中去,再为用户提供数据服务,而中间的存储、转化、更新等十分复杂、成本更高。数据编织通过建立逻辑抽象层,对数据封装、打包,屏蔽了分布式数据环境的底层复杂性,将有用的信息编织到一块,并且以合规、安全的方式提供给用户,很好地兼顾了实时性、安全性与降本增效。
数据管理向 AI 进化:Denodo 平台接入 AI 大模型能力
数据管理技术与 AI 融合的趋势也越发明显。
Angel Viña 在接受 InfoQ 采访时表示,当前数据管理的一个核心、主流的改变是数据管理流程的自动化。数据管理包括在数据收集、数据迁移、数据可视化等方面都需要大量人力、财力、物力。应用 AI 技术进行数据管理的核心作用就是把“手动的”转化为“自动的”,将一些手动、人工的工作取缔掉,从而在数据获取上提速,缩短数据获取到与用户交互的周期。
紧跟 AI 时代的技术演进,早在 4 年前,Denodo 就着力布局 AI,在自家技术与产品上“注入”AI 能力。例如在一年多前发布的 Denodo Platform 8.0 版本,为了优化平台功能和用户体验,该平台的“含 AI 量”十足,具备 AI 驱动的智能查询加速、自动化安全云数据集成等功能。
Angel Viña 介绍,在 Denodo 平台的数据查询和分析速度的提升优化策略上,AI 发挥了很大作用。比如当处理成千上万条、甚至成百万、上千万条查询要求时,AI 要能够通过学习来将流程自动化,还要能优化决策的过程。“我们经常有一句话,过去是人找数(数据),将来是数找人,不用关心数在哪,它会来。”Angel Viña 说。
具体来说,当 Denodo 平台收到查询后,后端计算将查询重写为可执行和优化的内容。重写后采用了一些优化策略,优化机制中加入了一些人工智能自动化的技术,AI 会根据过去的经验进行学习,并根据不同的执行者(不同公司后端系统不同)生成相应的优化策略。
伴随着以大模型为代表的生成式 AI 技术逐渐起势,Denodo 自去年开始又逐步将生成式人工智能与大模型技术应用到 Denodo 8.0、Denodo9.0 产品体系中,提供自然语言查询、用户建议等功能,将数据管理使用门槛下放的同时提升用户体验。
自然语言查询,降低数据管理使用门槛
Denodo 8.0 和 Denodo 9.0 支持用户自然语言查询功能,这尤其对非技术背景的用户十分友好。
如果用户想要从 Denodo 平台获取数据,他需要用 SQL(结构化查询语言)来访问,然后平台生成查询。而用上 AI 大模型之后,即使不了解 SQL 的人,只要会中文、英文或其他语言,就能在 Denodo 平台上做相关的查询,加速了用户对数据的访问和采用过程。而且大模型让用自然语言进行数据管理成为可能,降低了数据管理的使用门槛。
比如,针对“2023 年,给我带来利润最多的客户是谁?”查询,以往的方式是需要有专业程序员来做 SQL,然后生成相关数据。而现在,用户只需将自然语言输入 Denodo 平台,AI 大模型会自动生成 SQL,然后自动跑系统数据,用户实时就能获得答案。
为用户生成数据建议和提示
AI 大模型加持下的 Denodo 平台可以在用户使用过程中为其提出相应的建议。
比如,当公司 A 在使用一批数据时,Denodo 平台会给出使用同一数据的其他公司的提示,并说明其他公司使用的合理性、合法性等情况,给出相应的建议。
再比如在医疗行业,做创新药研发的研究者想要研制一款新药,一款药研发可能要分析 1 万个药分子,如果市场上已有相关研究,Denodo 平台就会给出提示,这样可以帮助科研人员缩短制药时间。
为大模型研发与落地提供数据基石
在大模型研发与应用落地领域,像 Denodo 这样的数据管理厂商也有广阔的“用武之地”。
大模型依赖庞大的数据量积累,数据越好,模型效果越好,大模型只有训练数据足够大、高质量和智能,才能够涌现出强大的理解、生成、逻辑和记忆能力。数据规模以及数据质量参差不齐是目前制约大模型发展的主要因素之一。
当前大模型的训练数据,多采用互联网上的公开数据,如何提升数据的规模、质量、安全可信、多元等对企业来说十分重要,但同时做到却非一己之力能完成。Denodo 可以快速获取到不同来源、不同系统的数据,将可信的数据提供给大语言模型训练,帮助减少模型幻觉,提高模型生成的准确性和相关性。
如今大模型已进入到应用落地的下半场,越来越多的企业开始拥抱大模型。企业拥抱大模型有几种方式,一种是在通用大模型基础上基于垂直数据训练,还有一种是从垂直领域出发,基于通用模型精调建立行业大模型。在落地过程中,企业如何将自有垂直数据与通用大模型结合是最为关键的环节。
但要想结合好并不容易。一方面大模型主要基于通用的公开互联网数据,如果到企业应用,有些数据是外部所没有的,将企业内部数据加入到通用模型中,其实需要 Denodo 这样的数据管理平台建立中间层来整合不同的数据源,比如将企业的财务数据、经营数据等内部数据通过中间层与通用大模型的外部数据结合。此外,很多企业重视安全与隐私,“自己的数据不想给别人看,又想占通用模型的‘便宜’”,因此用中间层作连接就是绝佳的平衡之选。
在这个过程中,Denodo 通过数据编织(数据虚拟化)和中间层的能力,帮助企业跨越内部数据与大模型之间的 Gap,搭建一个高效、可信的数据桥梁,一边帮助大模型看懂企业数据的业务语义,一边也打消了企业的安全顾虑。
未来行业大模型将是大模型落地千行百业的主流方向,而行业 Know-how 就是行业大模型的护城河。但行业 Know-how 需要时间积累,而且一些行业如医疗、能源等知识门槛很高。从这个角度看,做行业大模型的企业与在深具行业经验积累的数据管理厂商结合或是获得行业 Know-how 的快速路径之一。
Denodo 在过去 25 年里已服务过金融、保险、制造、高新技术、零售、教育、医疗、能源等多个行业。在这些行业,Denodo 可以将多元的数据连接起来,将通用数据与行业数据对接,结合起来训练大模型,让大模型能在产业纵深处实现价值。
逻辑数据编织用业务语言、业务速度交付数据,释放数据价值,为企业带来新质生产力,为中国数字经济高质量发展提供助推作用。




