
货拉拉是国内领先的同城货运数字化平台,成立于 2013 年。截⾄2025 年 4⽉ ,货拉拉业务覆盖全球 14 个市场 ,400+ 城市 ,其中中国内地总共覆盖 363 座城市 ,⽉活司机达 120 万 ,⽉活⽤户达 1400 万, 并在全球设有 6 个数据中⼼。作为共享经济模式的代表企业 ,货拉拉通过移动互联⽹技术整合社会运⼒资源 ,为⽤户提供即时货运、企业物流、搬家服务等多元化解决⽅案。
在庞⼤的业务规模下 ,构建完善的⽤户画像平台成为实现精细化运营的重要基础 ,可以有效提升运营效率和⽤户体验。
画像服务背景与架构
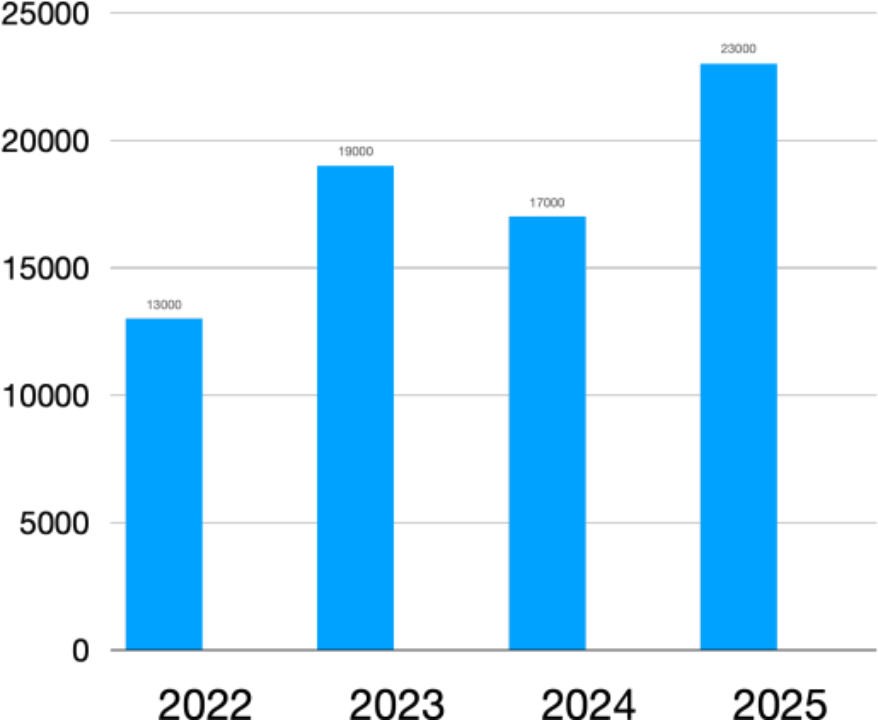
目前货拉拉的画像平台已深度应用于多个核心业务场景,各业务场景对标签的使⽤⽅式和时效性要求各不相同。从 22 年到 25 年,用户呈现稳定增长趋势,业务对服务的压力也是逐年递增,累计接入了 300+ 业务,3,000+ 个标签以及 5 万多人群。
01 应用架构
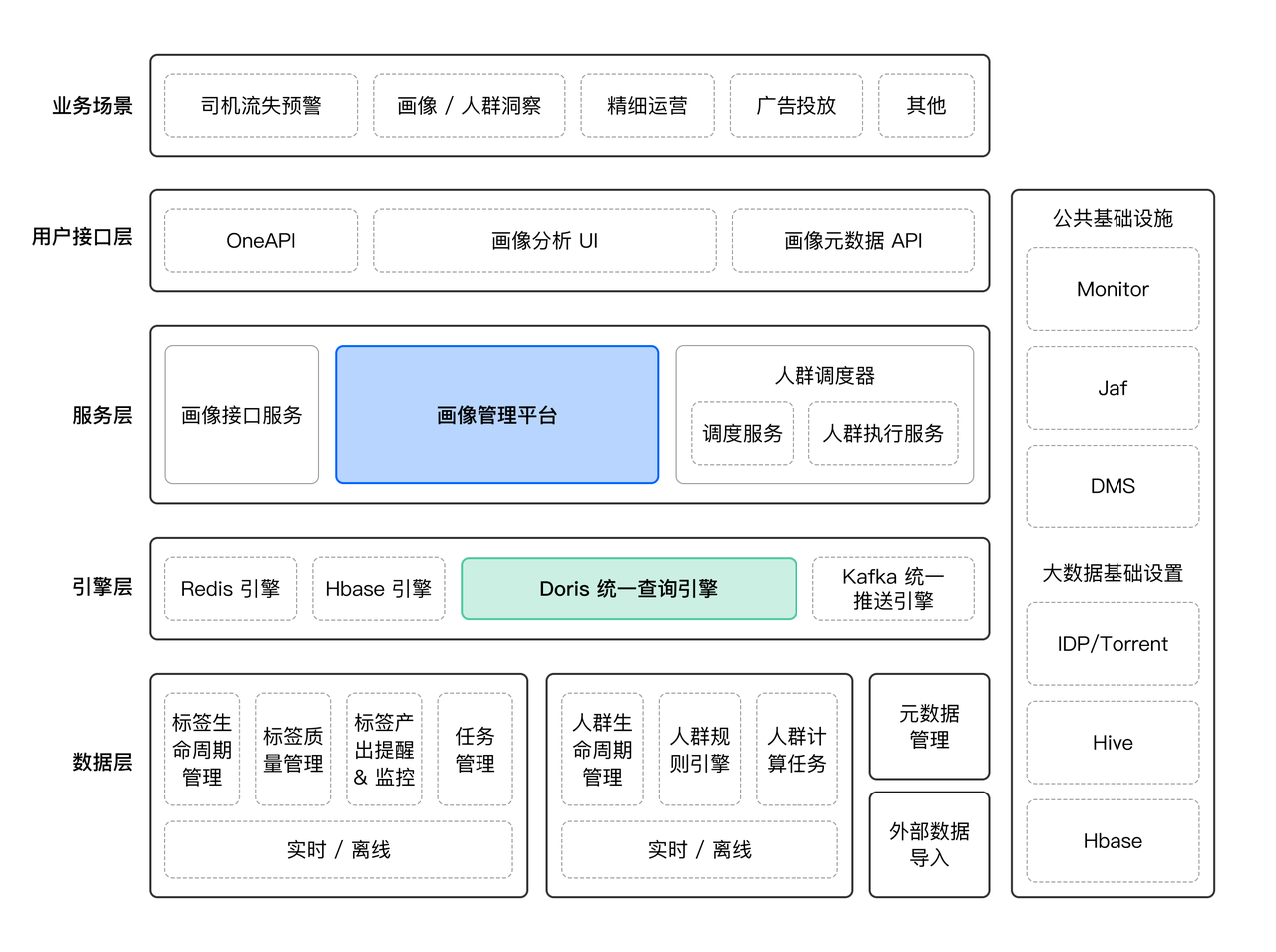
上图是货拉拉画像平台整体架构图,Apache Doris 作为统一查询引擎,为人群画像提供高效的分析能力。该平台通过架构分层实现了业务需求与技术能力的精准匹配。其中有两个核心模块:
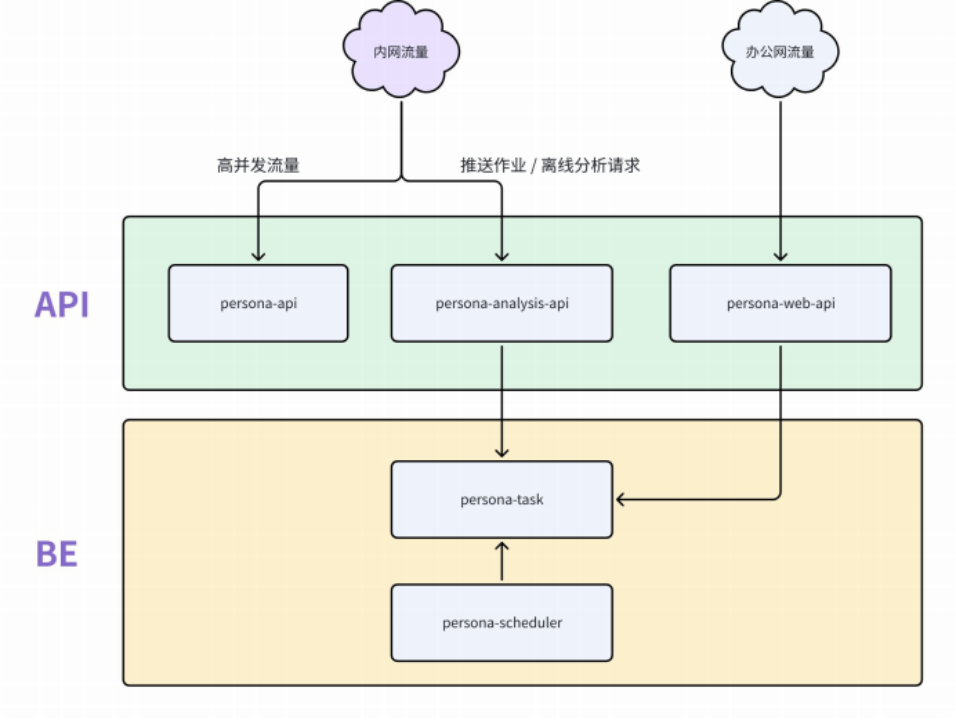
API 层(接⼝服务层):基于重点使⽤场景和对接系统搭建的画像接口服务 ,从⽽精准地⽣成用户画像 ,给到对接业务⽅使⽤。其中包括:
persona-api:⾯向⾼并发查询场景
persona-analysis-api:承接分析计算与推送作业请求
persona-web-api:⽀持管理后台的 Web 服务
BE 层(计算引擎层) :建造基于大数据体系的用户标签链路的画像管理平台 ,⽤于在特定业务形态下描述业务主体;其中包括:
persona-task:执⾏分布式计算作业 ,⽀持横向扩展
persona-scheduler :调度⼈群计算任务
两大模块协同工作,共同支撑业务方的精细化运营需求。
02 画像平台计算引擎演进
在核心计算引擎的选型与演进过程中,技术团队经历了三个主要阶段。
第一阶段,受限于成本因素,采用了三方服务结合 Impala+KUDU 的架构作为用户画像计算引擎。该架构在实际应用中暴露出诸多问题:单次人群计算耗时 10 分钟以上,高峰期甚至超过 30 分钟;同时,数据导入耗时较长,经常超时。此外,该架构存在横向扩展困难、复杂查询效率偏低及运维复杂等不足。
第二阶段,为寻求改进,我们尝试引入 Elasticsearch,虽在一定程度上有所缓解,但仍面临开发成本高、语法复杂、多维分析能力不足等挑战,且在动态扩展和复杂查询方面未实现根本性改善。尤其在处理人群间存在依赖关系的特殊业务场景时,Elasticsearch 架构难以有效支持。
基于此,我们最终转向采用 Doris 作为核心计算引擎。选择 Doris 的关键因素如下:
性能优越:基于 MPP 架构、具备向量化引擎和先进的优化器能力,查询性能优秀。
社区资源丰富:Doris 拥有活跃的社区支持以及丰富的文档资料,自行搭建遇到卡点时,可向社区帮助寻求专业的指导与帮助。
支持多种数据类型:画像场景可以使用 BITMAP 实现高效的交并集运算,成为支撑多样化标签类型与人群分析业务的技术基础。
支持多种数据模型:针对多维复杂的人群画像,可以使用不同的数据模型支撑各种标签类型与人群业务。
自引入 Doris 后,系统稳定性得到了显著提升,至今未出现过重大稳定性问题,整体链路的时效性与可靠性均实现了根本性的优化,具体如下:
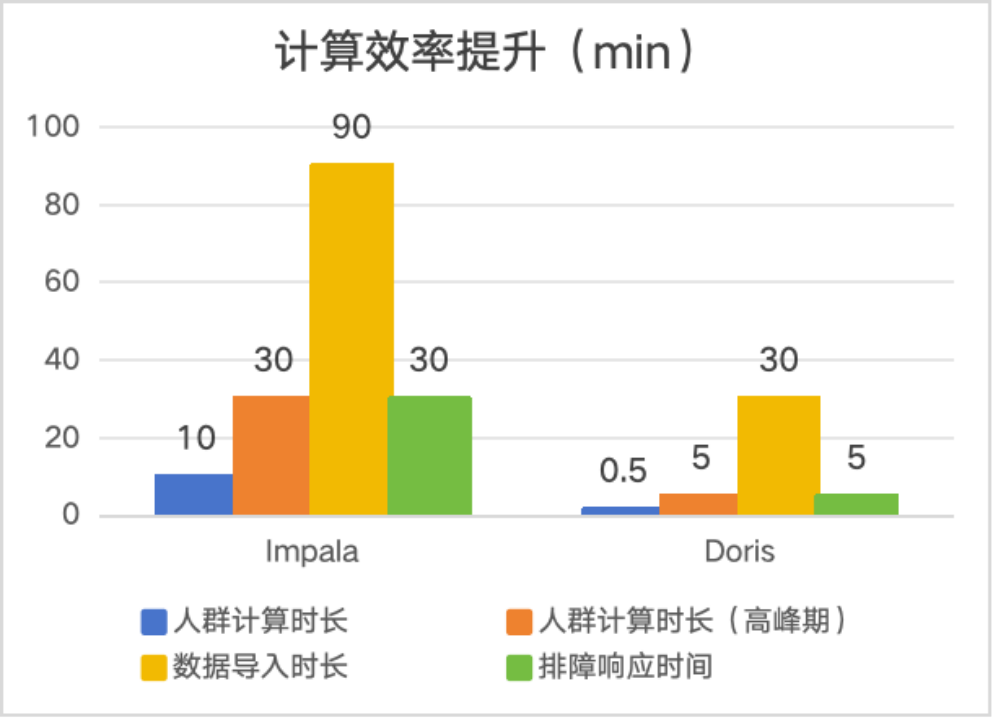
在计算效率方面,单个人群的计算能够实现秒级响应,即使在高峰期,响应时间也保持在 1 分钟以内。相比之下,Impala 架构下该计算过程通常需要 10 至 30 分钟。采用 Doris 后,计算效率提升了近 30 倍。
在数据导入方面,Doris 同样表现出色。在处理 4 亿行 200 列的单表数据时,Doris 可在 30 分钟内完成导入操作。而在同等条件下,Impala 架构则需要 90 分钟以上,Doris 数据导入效率是 Impala 架构的 3 倍。
数据模型设计与异构查询实现
01 核心挑战
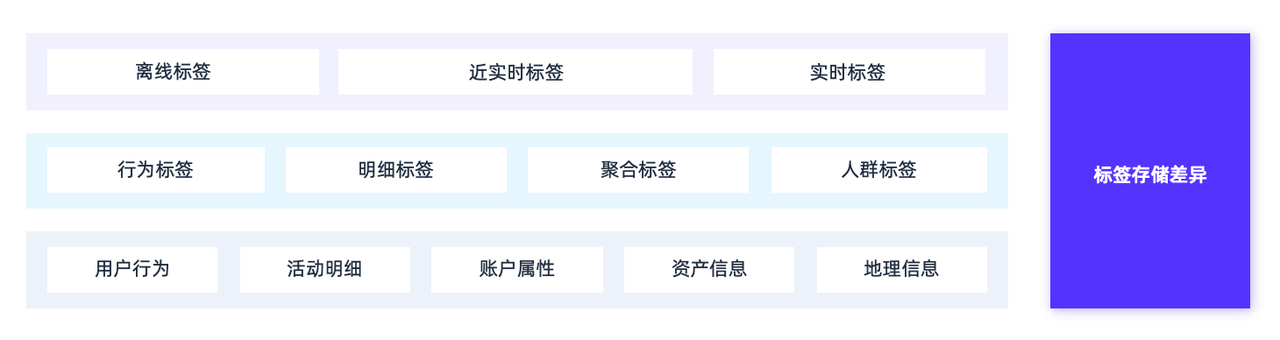
首先是用户画像标签存储的挑战。面对 3000+ 标签的体系,我们发现标签数据天然存在三个维度的分裂特征:业务属性(行为/属性/地理等)、聚合粒度(明细/聚合/人群)、更新时效(离线/近实时/实时)。不同业务属性的数据在更新频率、查询模式、存储密度上差异巨大。
此外,用户使用画像标签的时候,对人群标签/明细标签/聚合标签等概念不清晰,只会进行简单的拖拉拽拼接规则。因此在标签使用场景,如何选择存储模型成为了核心问题。若使用宽表,将面临动态更新以及列拓展的挑战;而高表则面临复杂查询与嵌套逻辑的挑战。
02 存储模型设计
面对复杂的标签管理,我们采用了基于 Apache Doris 分而治之的存储方案,具体分为三类模型来进行协同工作。
标签宽表
存储低频更新的标签。
存储无法用高表存储的密集标签。
利用 Doris 的列式存储技术,利用索引、物化视图等优化手段,支持高效的多维分析。
标签宽表建表 SQL 参考:
CREATE TABLE wide_table ( user_id varchar(1000) NULL COMMENT "", age bigint(20) REPLACE_IF_NOT_NULL NULL COMMENT "", height bigint(20) REPLACE_IF_NOT_NULL NULL COMMENT "", ......) ENGINE=OLAP AGGREGATE KEY( user_id ) COMMENT "OLAP"DISTRIBUTED BY HASH( user_id ) BUCKETS 40PROPERTIES ( ... )标签高表
存储高频更新的稀疏标签。
支持秒级/分钟级数据更新,标签新增的场景下,可以规避宽表频繁 ALTER TABLE 导致的锁表问题。
多个标签的位图交并计算,并且支持毫秒级响应。
标签高表建表 SQL 参考:
CREATE TABLE high_table ( tag varchar(45) NULL COMMENT "标签名", tag_value varchar(45) NULL COMMENT "标签值", time datetime NOT NULL COMMENT "数据灌入时间", user_ids bitmap BITMAP_UNION NULL COMMENT "用户集") ENGINE=OLAP AGGREGATE KEY( tag , tag_value , time ) COMMENT "OLAP"DISTRIBUTED BY HASH( tag ) BUCKETS 128PROPERTIES ( ... )人群位图表
用于存储标签规则圈选出来的人群结果。
用户 ID 集合使用 RoaringBitmap 压缩,降低存储成本。
支持人群依赖计算,避免表数量膨胀问题,⽀持⼈群营销实验业务。
人群位图表建表 SQL 参考:
CREATE TABLE routine_segmentation_bitmap ( time datetime NOT NULL COMMENT "数据灌入时间", seg_name varchar(45) NULL COMMENT "标签值", user_ids bitmap BITMAP_UNION NULL COMMENT "人群ID集合") ENGINE=OLAP AGGREGATE KEY( time , seg_name )COMMENT "OLAP" PARTITION BY RANGE(`time`) (...)DISTRIBUTED BY HASH( seg_name )BUCKETS 128PROPERTIES (..., "dynamic_partition.enable" = "true", ...);03 人群圈选与异构组合查询
基于上述提到了三种存储模型,我们构建了以位图计算为核心的异构组合计算体系,并将其作用于整个人群圈选的场景,实现宽表、高表及人群表这三类存储模型之间的无缝联动。
第一步:将所有单一标签或子查询的结果都处理成 Bitmap 位图,处理宽表的标签使用
TO_BITMAP聚合多列 ID 结果,处理标签高表和人群表则直接使用预聚合的 Bitmap,加速逻辑复用。第二步,通过
UNION ALL整合宽表/高表/人群表三种数据源的 Bitmap,并使用外层的BITMAP_INTERSECT/BITMAP_UNION实现跨模型交并集运算(AND/OR 逻辑)。第三步,由于
BITMAP_INTERSECT/BITMAP_UNION的结果也是 Bitmap,所以可以用同样的处理方式,递归整合子查询的查询结果,并支持直接导出或对接业务系统。
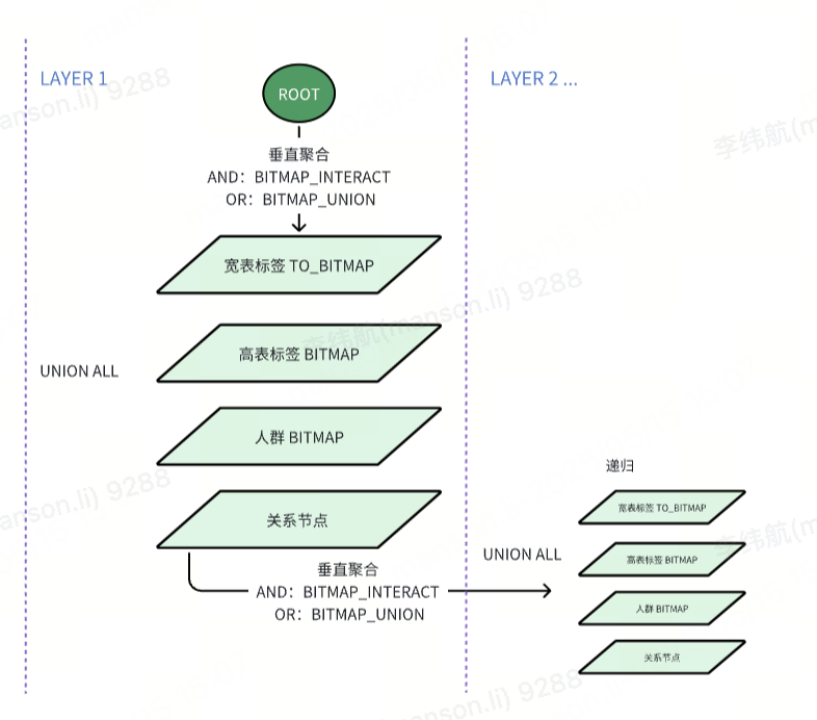
该实现方法具备三大核心优势:
灵活拓展:动态嵌套子查询支持无限层级规则(如 “A 且(B 或 C)且(D 且(E 或 F))” ) ,静态属性、动态行为以及预计算人群等复杂的标签规则皆可无缝嵌入。
资源节省:复用人群表(预计算人群)的数据从而大幅减轻计算压力,并允许不同人群间相互依赖进行计算;人群计算结果使用 RoaringBitmap 存储,不需要额外新增表。
业务友好:支持人群+标签的复杂混合嵌套查询,用户无需技术基础,仅通过简单的拖拽标签条件即可高效圈定目标用户群体,适用于营销等多种场景。
查询 SQL 示例:
SELECT BITMAP_INTERSECT(b) FROM ( -- Layer1: 宽表条件A SELECT TO_BITMAP(...) AS b FROM 标签宽表 WHERE 条件A UNION ALL -- Layer1: 高表条件B SELECT user_ids AS b FROM 标签高表 WHERE 条件B UNION ALL -- Layer1: 人群条件C SELECT user_ids AS b FROM 人群表 WHERE 条件C UNION ALL -- Layer2: 嵌套子查询(新条件D/E/F) SELECT BITMAP_INTERSECT(b) FROM ( SELECT TO_BITMAP(...) AS b FROM 标签宽表 WHERE 条件D -- 新宽表条件 UNION ALL SELECT user_ids AS b FROM 标签高表 WHERE 条件E -- 新高表条件 UNION ALL SELECT BITMAP_INTERSECT(...) AS b FROM 人群表 WHERE 条件F -- 新人群条件 )) t;04 数据导入
货拉拉画像服务的实时标签/人群点查主要采用 HBase 与 Redis 相结合的方式,Doris 主要承担人群圈选、人群洞察、行为分析等任务。实时和近实时标签写入 Doris 则通过 Flink 完成,离线导入依赖 Doris 的 Broker Load 功能。对应的数据导⼊⽅式和应⽤场景如下:
实时/近实时标签
定义:秒级/小时级更新的动态数据(如点击、登录事件)。
数据源:Kafka 日志、API 埋点、云文件存储。
处理方式:
秒级/分钟级标签:Flink -> Doris / Hbase。
小时级标签:云文件存储 -> BrokerLoad。
场景:用户行为分析,用户实时人群。
离线标签
定义:T+1 更新的历史数据(如年龄、历史订单)。
数据源:Hive。
处理方式:
数据量:3000+ 标签,4 亿+用户总量。
定时调度:BrokerLoad。
调优手段:宽表导入拆分多表和多个 BrokerLoad 任务。数据量少的稀疏标签使用高表导入。
导入效率:200+ 标签宽表 4 亿行+导入 30min 以内,高表标签导入 5min 以内。
场景:用户人群圈选、用户画像分析。
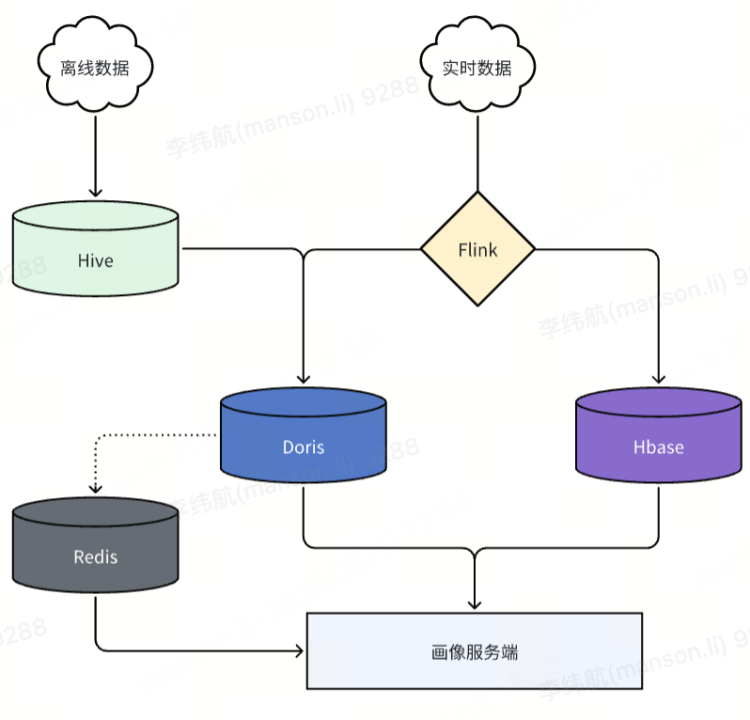
特别值得注意的是,大规模数据导入时,建议拆分多个表并行导入以提升效率,例如在早期 1.2.4 版本集群测试中,单个包含 200 余标签、四亿行记录的宽表导入耗时超过 1.5 小时,而拆分为 6 个任务并行导入后,总耗时缩短至约 20 分钟,效率提升近 5 倍。
货拉拉画像工程查询优化实践
01 DSL 与 SQL 优化
首先是离线人群包圈选的流程,主要分为三步:【运营通过平台进行多规则拼接,前端完成 DSL 构建】-【DSL 经过服务后端优化】-【最终将业务规则自动转化为高效 SQL】。DSL 优化的目的是提前排除冗余计算,从而将优化后的 DSL 直接翻译为高效易用的 SQL。
为什么需要优化?当前异构查询 SQL 痛点:
部分标签在业务逻辑上可以合并 ,引擎侧没有覆盖识别;
多层聚合导致冗余扫描:复杂嵌套的场景下,嵌套的
UNION ALL和BITMAP_INTERSECT导致执行计划层级膨胀,导致冗余的扫描。稳定性:高峰期人群计算时,内存占用高、网络传输量大,高内存开销影响集群稳定性。
如何实现优化?DSL 优化:
条件合并(染色):将同类标记的标签条件合并为同个子查询。
结构扁平化(剪枝):去除冗余的 AND/OR 逻辑节点
将同类合并操作后的 DSL 转为 SQL,原本查询 3 次宽表读取了 3 个 BITMAP 进行合并计算,优化后统一成 1 次宽表查询和 1 次 BITMAP 读取,减少了 60% 的冗余读取。参考下图,DSL 的每一个圆圈对应一个 BITMAP 查询:
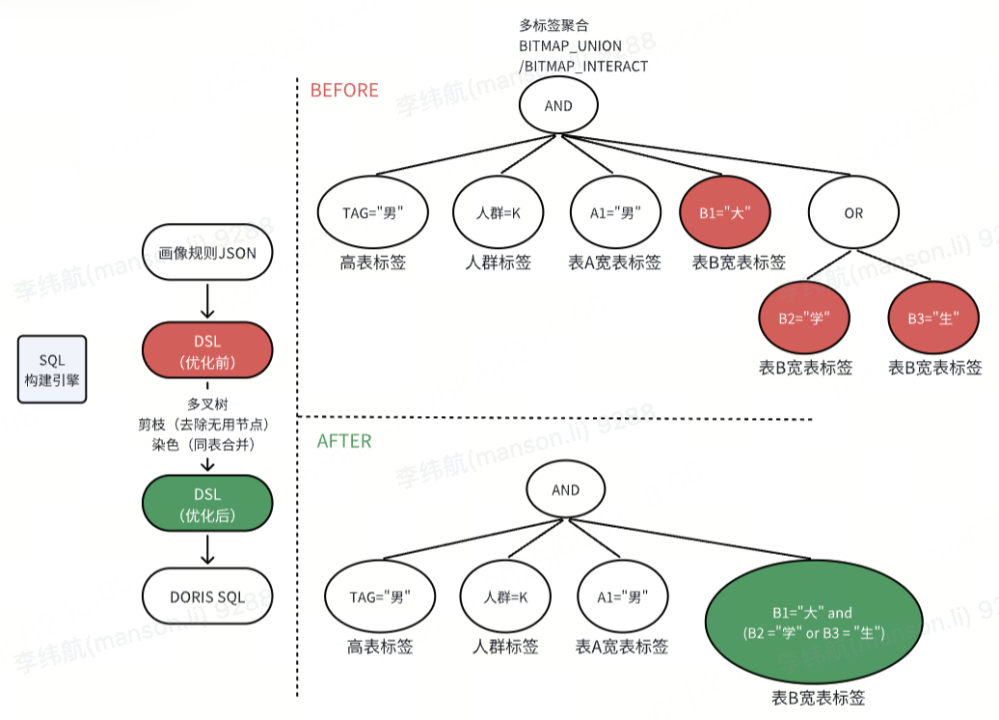
关于 EXPLAIN 指标优化前后的具体表现,我们在此也分享一则参考示例,详情如下:
-- 优化前SELECT BITMAP_INTERSECT(b) AS result FROM ( SELECT BITMAP_INTERSECT(b) AS b FROM ( SELECT user_bitmap as b FROM user_bitmap WHERE group = ‘A’ UNION ALL SELECT TO_BITMAP(id) AS b FROM wide_table WHERE city = '东莞' UNION ALL SELECT TO_BITMAP(id) AS b FROM wide_table WHERE sex = '男' ) t1 ) t2; -- 优化后SELECT BITMAP_INTERSECT(b) AS result FROM ( SELECT user_bitmap as b FROM user_bitmap WHERE group = ‘A’ UNION ALL SELECT TO_BITMAP(id) AS b FROM wide_table WHERE city = '东莞' and sex = ‘男’) t1 ) t2;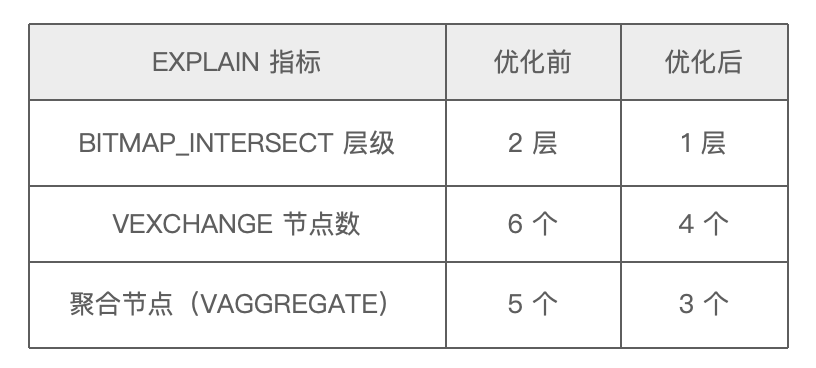
在业务圈选逻辑不变的情况下,通过将优化前 BITMAP 子查询合并到 WHERE 条件中以避免重复扫描表,同时减少 BITMAP 子查询及数据分片合并次数,进而减少聚合层级实现结构扁平化,降低人群计算时的内存峰值。
在业务高峰期针对大规模人群展开计算的场景下,此优化措施能够有效减少 30~50% 的内存开销。与此同时,JVM 的堆内存使用峰值从原本的 60% 降至 20% 。
02 人群位图表读取优化
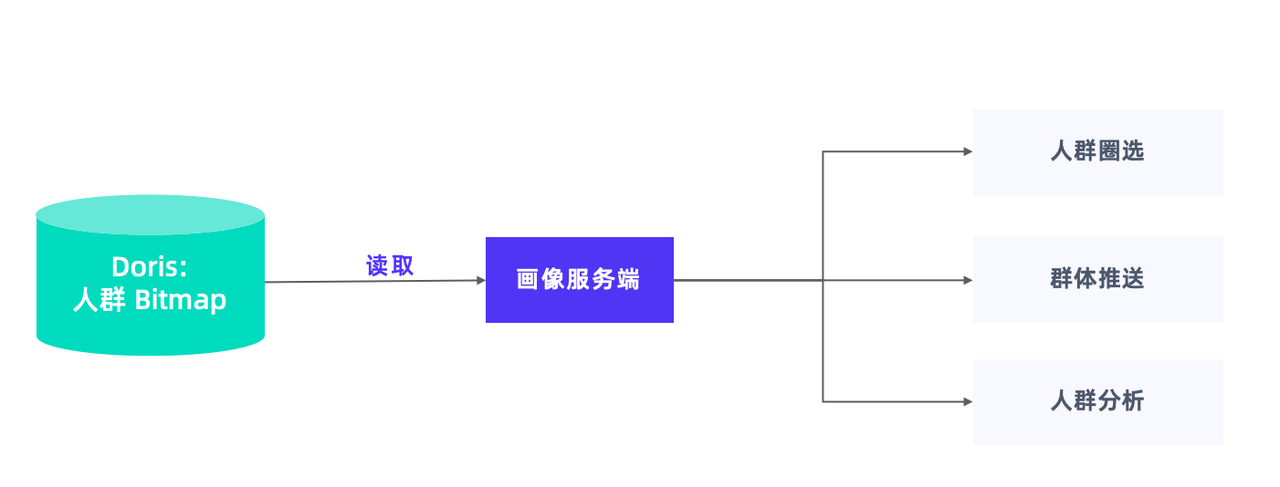
人群位图结果集通过 BITMAP 存储于人群表中,读取人群位图数据主要用于人群圈选、人群分析,并将整个结果集推送至下游。

读取位图数据的方案有三种:
第一种方案,直接使用 Doris 自带的
bitmap_to_string函数,该函数可将位图转化为逗号分隔的字符串,客户端按此字符串解析出用户列表。但是当面对大型位图时,解析难度较大,且数据体积会大幅膨胀。优点是简单易用,适合测试和导出场景。第二种方案,采用
explore与lateral view先将整个位图展开,再构建服务端流处理逻辑。不过,Doris 需将位图展开成用户列表并缓存于服务器,这会给服务端带来压力,尤其在高峰期,人群计算任务繁重时更为明显。此外,画像工程侧需维护流处理逻辑,开发维护成本较高。该方案适合人群多表的关联分析。第三种方案,也是较为推荐的方案,直接将位图的二进制数据读取至服务端内存,再进行反序列化。服务端设置
return_object_data_as_binary=true,即可直接读取位图的二进制数据,画像服务端可基于 Doris 源码中的位图协议进行反序列化。此方式仅需传输位图的原始二进制数据,内存占用和开销较低。开发成本初期较高,但后期维护方便且稳定。此读取方式适用于人群圈选场景,将位图全量读取至服务内存后,高峰期每分钟可轻松处理几十甚至上百个人群。
总结与规划
货拉拉自引入 Apache Doris 构建用户画像系统以来,收益十分显著:业务查询效率提升近 30 倍,数据导入速度是 Impala+KUDU 的 3 倍,内存开销降低 30%-50%,系统稳定性大幅提升,满足了画像场景数千个标签的精细化运营需求,同时通过可视化标签筛选,降低业务分析的操作门槛。
后续,货拉拉将重点投入以下两个方面:
接入画像实时业务:当前货拉拉画像服务的实时标签/人群点查主要使用 Hbase 和 Redis,基于稳定性和迁移升级成本的考虑,Doris 主要承担人群圈选、人群洞察、行为分析等作业。未来规划使用 Doris 高版本的架构,承担大部分高并发的实时点查流量,提升人货匹配效率和体验。
引入湖仓一体架构:使用 Doris + 数据湖,在存储架构方面,尝试落地数据湖解决方案,画像平台将打通其他数据应用平台、实现超大规模数据的分析。




