
许多企业正逐渐意识到拥有机器学习模型只是将其 ML 驱动的应用程序朝着投入生产迈出的一小步,更为重要的是要构建端到端流水线。
Google Cloud 提供一个大规模训练和部署模型的工具 —— Cloud AI Platform,这一平台整合了多种编排工具 (orchestration tool),例如,TensorFlow Extended 和 KubeFlow Pipelines(KFP)。不过,经常会有这样的情况:企业已经在其自己的生态系统中使用 scikit-learn 和 xgboost 之类的框架构建了模型,将这些模型移植到云可能既复杂又耗时。
由于所涉及的所有样板的量,即使对于有着丰富 Google Cloud Platform (GCP) 经验的 ML 从业者,要将 scikit-learn 模型(或者同等模型)迁移至 AI Platform 可能也要耗费较长时间。ML Pipeline Generator 是一个允许用户在 GCP 中轻松部署现有 ML 模型的工具,无服务器模型训练和部署以及更快地将其解决方案推向市场能够让用户受益匪浅。
本文概要介绍了这一解决方案的工作原理以及预期的用户迁移之旅,同时,提供了在 AI Platform 中编排 TensorFlow 训练作业的相关指南。
概述
ML Pipeline Generator 允许拥有预构建 scikit-learn、xgboost 和 TensorFlow 模型的用户在 GCP 中利用其自有代码和数据快速生成并运行端到端 ML 流水线。
要做到这一点,用户必须填写描述其代码元数据的配置文件。库会接受这个配置文件并生成所有必要的样板,以供用户使用模板引擎以协调的方式在云中训练和部署其模型。此外,训练 TensorFlow 模型的用户还可以使用 Explainable AI 功能来更好地了解其模型。
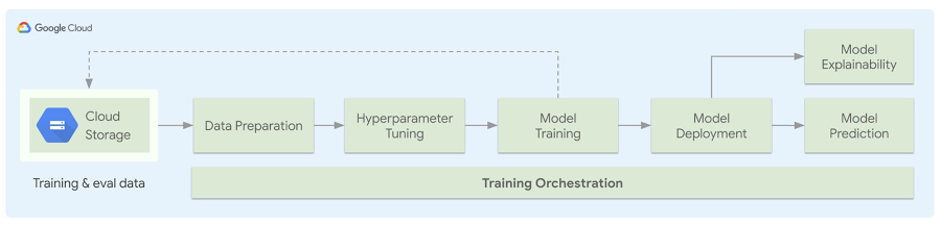
在下图中,我们将重点介绍生成的流水线的架构。用户将使用自己的数据、定义执行数据预处理的方式,并且添加其 ML 模型文件。一旦用户填写了配置文件,他们可以使用简单的 python API 生成自包含样板代码,代码负责执行指定的任何预处理、将其数据上传至 Google Cloud Storage (GCS) 以及利用超参数调试启动训练作业。一旦完成上述操作,模型即可被部署以供使用,并且根据模型类型,执行模型可解释性分析。整个流程是通过 KubeFlow Pipelines 进行编排。
分步指南
我们将向您详解如何利用给定的模型配置参数和模型代码构建端到端 Kubeflow Pipeline 以训练和使用模型。我们将基于 Census Income Data Set(人口调查收入数据集)构建一个流水线来训练一个浅层的 TensorFlow 模型。利用 Cloud AI Platform 训练该模型并可在 Kubeflow UI 中对其进行监控。
开始之前
为了确保您能完全使用解决方案,需要对 GCP 中的一些项进行设置:
1. 您需要一个 Google Cloud 项目以运行此演示。我们建议创建一个新项目并确保为该项目启用下列 API。
1. Compute Engine(计算引擎)
2. AI Platform Training and Prediction(AI 平台训练与预测)
3. Cloud Storage(云存储)
2. 安装 Google Cloud SDK,以便您可以通过命令行访问所需要的 GCP 服务。SDK 安装后,利用您以上所创建的项目的项目 ID 来设置应用程序默认凭据。
gcloud auth login
gcloud auth application-default login
gcloud config setproject [PROJECT_ID]
3. 如果您寻求使用此解决方案在 KubeFlow Pipelines 部署 ML 模型,在您的项目中创建基于 AI Platform Pipelines 的新的 KFP 实例。记下实例的主机名(表单中的 Dashboard URL: [vm-hash]-dot-[zone].Pipelines.googleusercontent.com)。
4. 最后,创建存储桶,这样,就能在 GCS 中存储数据和模型。记下存储桶 ID。
第一步:设置环境
从 github repo 克隆演示代码 ,并创建一个 Python 虚拟环境。
git clonehttps://github.com/GoogleCloudPlatform/ml-pipeline-generator-python.git
cd ml-pipeline-generator-python
python3 -m venv venv
source ./venv/bin/activate
安装 ml-pipeline-gen 包。
pip install ml-pipeline-gen
下列文件使我们能够确保生成模型并正常运行:
1. examples/ 目录包含 sklearn、Tensorflow 和 XGBoost 模型的示例代码。我们将使用 examples/kfp/model/tf_model.py 在 KubeFlow Pipelines 中部署 TensorFlow 模型。不过,如果您使用自己的模型,可利用您的模型代码修改 tf_model.py 文件。
2. examples/kfp/model/census_preprocess.py 会下载 Census Income 数据集并为模型预处理该数据集。对于您的自定义模型,可根据需要修改预处理脚本。
3. 工具从 config.yaml 文件读取所需的元数据来为流水线构建工件。打开 examples/kfp/config.yaml.example 模板文件查看示例元数据参数,您可以在在此找到详细的模式。
4. 如果您要使用 Cloud AI Platform 的超参数调试功能,可在 hptune_config.yaml 文件中包含参数,并将其路径添加到 config.yaml。您可以在此处查看 hptune_config.yaml 的模式。
第二步:设置所需要的参数
1. 复制 kfp/ 示例目录
cp -r examples/kfp kfp-demo
cd kfp-demo
2. 使用 config.yaml.example 模板创建 config.yaml 文件并使用项目 ID、存储桶 ID、您之前记下的 KFP 主机名以及模型名更新下列参数。
project_id: PROJECT_ID
bucket_id: BUCKET_ID
data:
train: “gs://BUCKET_ID/MODEL_NAME/data/adult.data.csv”
evaluation:"gs://BUCKET_ID/MODEL_NAME/data/adult.test.csv"
prediction:
input_data_paths:
- "gs://BUCKET_ID/MODEL_NAME/inputs/*"
orchestration :
host: “KUBEFLOW_PIPELINE_HOST_URL”
第三步:构建流水线并训练模型
有了配置参数后,我们就准备好了生成所有模块,它们将构建流水线以训练 TensorFlow 模型。运行 demo.py 文件。
pythondemo.py
首次运行 KubeFlow Pipelines 演示时,工具会提供适用于 GKE 集群的 Workload Identity,以修改 Dashboard URL。要部署您的模型,只需在 config.yaml 中更新 URL 并再次运行演示。
demo.py 脚本从公共 Cloud Storage 存储桶下载人口调查数据集、按照 examples/kfp/model/census_preprocess.py 准备数据集以进行训练和评估、将数据集上传到 config.yaml 中指定的 Cloud Storage URL、构建训练的流水线图并将该图上传到 KubeFlow Pipelines 应用程序实例作为试验。
一旦提交该图以供运行,可在 KubeFlowPipelines UI 中对运行进度进行监控。打开 Cloud AI Platform Pipelines 页并且打开您的 KubeFlow Pipelines 集群的 Dashboard。
注意:
如果您要使用 Scikit-learn 或者 XGBoost 示例,可遵循如上所述的相同步骤,但要利用上述类似的变更来修改 examples/sklearn/config.yaml,无需额外步骤来创建 KubeFlowPipelines 实例。要了解详细信息,请参考 public repo 中的指南或者遵循我们使用 Jupyter notebook 撰写的详尽教程。
结论
在本文中,我们为您介绍了如何通过三个轻松步骤将您的自定义 ML 模型迁移至 Google Cloud 以进行训练和部署。大部分繁琐工作都由解决方案完成,用户只需提供自己的数据和模型定义,并且说明希望如何处理训练和服务。
我们详解了一个示例,公共代码库包含针对其他支持框架的示例。我们邀请您使用该工具并且开始能够为您的机器学习工作负载带来云的诸多优势之一。
鸣谢
没有以下人员的辛勤工作(按姓氏字母顺序排列),本文不可能完成:ChanchalChatterjee、Stefan Hosein、Michael Hu、Ashok Patel 和 Vaibhav Singh。




