
Meta发布了有关其生成式广告模型(GEM)的详细信息,这是一个旨在改善其平台广告推荐能力的基础模型。该模型处理每天数十亿的用户-广告交互数据,解决了推荐系统(RecSys)中的核心挑战——有意义的信号(如点击和转化)非常稀疏。GEM 致力于解决从多样化广告数据中学习的复杂性,包括广告商目标、创意格式、测量信号以及跨多个投放渠道的用户行为。
该公司使用三种方法构建了这个系统:基于先进架构的模型缩放技术、用于知识迁移的后训练技术,以及增强型训练基础设施——该基础设施利用数千块 GPU 实现高级并行计算,以满足大规模基础模型训练的计算需求。
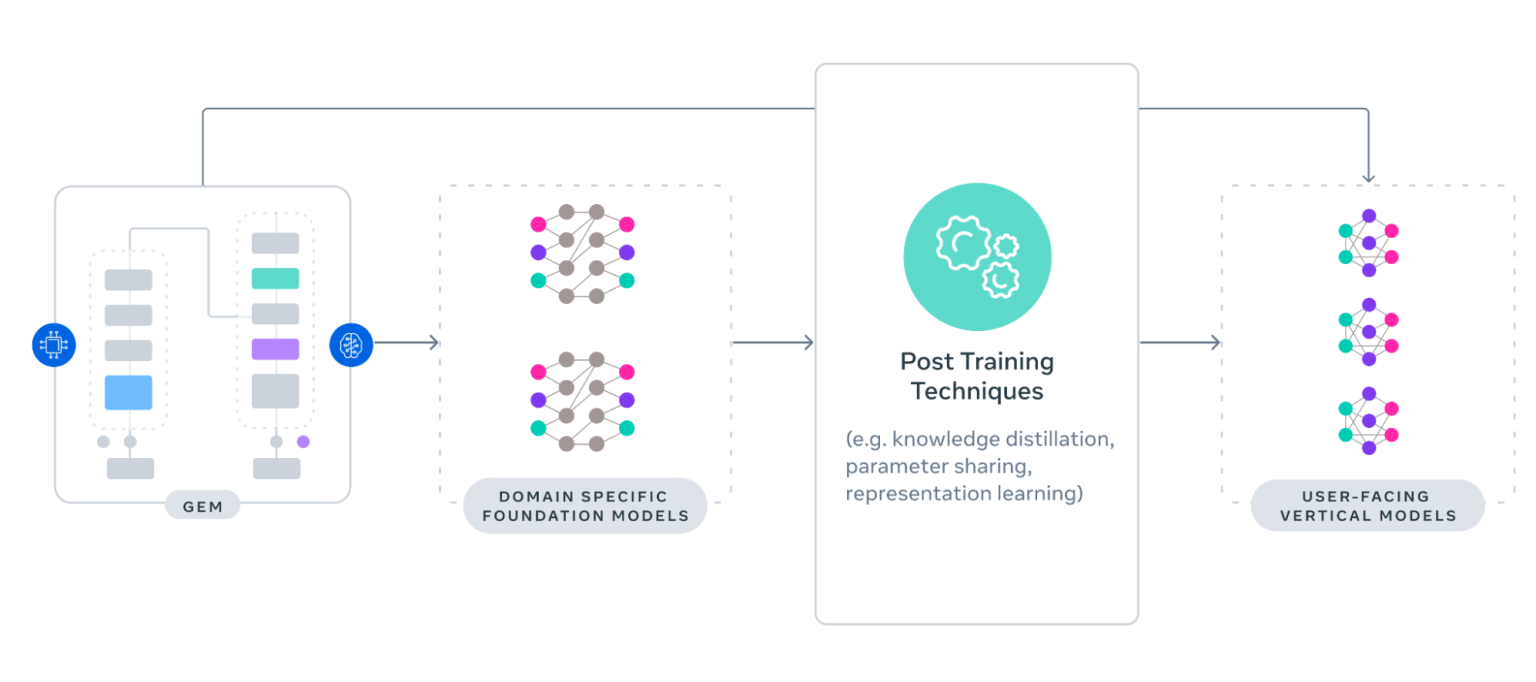
图片来源:GEM架构
Meta 对训练架构进行了重新设计,使其能够以媲美现代大型语言模型的规模支持 GEM。该公司针对不同模型组件采用了定制化的多维并行策略:密集型模型组件采用混合分片分布式并行(HSDP)技术,在数千块 GPU 间优化内存使用并降低通信开销;稀疏型组件(主要为用户和物品特征的大型嵌入表)则采用结合数据并行与模型并行的二维并行方案。
为了减少训练瓶颈,Meta 实施了几项 GPU 级别的优化,包括:针对可变长度用户序列设计的定制 GPU 内核;PyTorch 2.0 中的图级编译技术,可自动执行激活检查点和操作符融合;采用 FP8 量化等内存压缩技术处理激活值。
Meta 团队通过 NCCLX(Meta 的 NVIDIA NCCL 分支)开发了 GPU 通信集合,可以在不使用流式多处理器资源的情况下运行。这消除了通信工作负载和计算工作负载之间的竞争。Meta 通过优化训练器初始化、数据读取器设置和检查点,将作业启动时间减少了 5 倍。通过优化缓存策略,PyTorch 2.0 的编译时间减少了 7 倍,提高了处理新数据所花费的训练时间占比。
该系统在模型生命周期中持续优化 GPU 效率。在探索阶段,与完整模型相比,轻量化模型变体以更低的成本支持了超过半数的实验。Meta 通过持续在线训练刷新基础模型,并在训练过程与训练后的知识生成阶段之间共享流量,从而降低计算需求。
按照 Meta 的设计,GEM 将知识迁移到数百个面向用户的垂直模型,在其平台上提供广告服务。该公司采用两种迁移策略,将基础设施模型的能力转化为可衡量的收益。
直接迁移使 GEM 能够向其接受训练的数据空间内的主要垂直模型传递知识。分层迁移则将 GEM 的知识提炼为特定领域的基础模型,进而用于训练垂直模型。
这些方法通过知识蒸馏、表示学习和参数共享最大限度地提升了 Meta 广告模型生态系统中的迁移效率。
特斯拉前总监Swapnil Amin评论说:
GEM 感觉就像我们都知道要到来的转变——一种真正能同时学习创造力、语境和用户意图的模型,而非事后拼凑碎片。
他强调:
23 倍的有效浮点运算性能提升是改变经济效益的关键所在。
微软高级产品经理Sri.P认为该技术对广告商具有潜在的应用价值,并表示:
这对营销人员/广告商来说是一个游戏规则的改变者!可以看到,它有可能为小型企业节省大量的资金,因为他们不需要试验营销策略,而是可以依靠智能模型来充分利用他们的广告支出。
按照 Meta 的设想,广告推荐系统的基础模型将发展出一种可以更好地理解用户偏好和意图的能力,使用户与广告的互动更加个性化。对于广告商来说,Meta 将这种模型定位为实现大规模一对一连接的方法。
原文链接:




