
10 月 29 日,作为 Cursor 2.0 版本更新的一部分,Composer 大模型正式发布。官方给出的关键信息是:在相似智能水平下,Composer 生成 token 的效率大约是其他模型的四倍,试图在“又快又聪明”的代码 Agent 赛道上拉开差距。
发布没多久,海外网友就开始“考据”起这只新 Agent 的身世。有开发者在 X 上贴出截图,称自己捕捉到了 Composer 的 thinking 过程日志,结果一展开,居然是中文输出,由此吐槽说:Cursor 的新模型 Composer,很可能是建立在某个中国大模型之上。这类段子一边在社交媒体上传播,一边也把大家的注意力拉回到一个更现实的问题上——不管底座是谁,它到底是怎么做到又快又能干的?
最近,Cursor 的开发者体验 VP Lee Robinson 在演讲里详细分享了如何通过强化学习、克服基础设施挑战,让 Composer 成为一个既强大又极速的代码 Agent。基于该演讲视频,InfoQ 进行了部分删改。
核心观点如下:
强化学习可以很好地扩展并应用在高度专门化的任务上,除了编程以外,也完全可能扩展到其他领域。
语义搜索显著提升了 Cursor Agent 中几乎所有模型的表现,尤其是 Composer,因为它在训练时就使用了与推理完全一致的环境。
模型训练与基础设施之间的关联远比想象中紧密,框架层的“魔法时刻”往往离不开底层基础环境的支撑。
“速度 vs 智能”
Cursor Composer 是为真实世界的软件工程而设计的模型,目标是在高速与高智能之间取得平衡。根据我们的内部基准测试,它的表现优于当前最好的开源模型,接近最新的前沿模型,如 Sonnet 4.5 和 GPT-5.1 Codex。它的突出优势在于:在相似智能水平下,生成 token 的效率大约是其他模型的四倍,实现速度与智能的双重提升。
Cursor 本身已经是 IDE,那我们为何还要进入模型领域?原因在于,我们团队一直在研发名为 Tab 的自动补全模型,希望将这种低延迟模型的理念进一步应用到 Agent 编程中。
一开始,我们也不确定这套方法是否会奏效,于是便尝试构建早期版本并向用户测试。让我们惊讶的是,尽管早期版本并不算特别智能,但用户依然非常喜欢其速度。但他们也反馈说,模型的智能水平仍不足以成为日常开发的主力工具。因此,我们必须让它足够快速,也足够聪明。
为此,我们开发了一个内部基准,用来反映我们真实的开发流程和仓库使用情况。我们设想:如果某个检查点版本能够达到让公司工程师每天都愿意用它来开发产品和软件的程度,那我们就找对方向了。一个关键突破来自模型能够并行调用工具,并高效利用语义搜索系统。
在使用 Composer 1 模型时,Cursor 会以非常高的速度并行调用多种工具:读取文件、执行 shell 命令、修改文件、维护任务列表等。这样你可以在前台快速推进任务,例如排查某个开源仓库的问题。与以往启动一个 Agent 后等待二十分钟结果再切回处理相比,这种实时互动让你保持在“心流”之中,彻底改变了编程体验。
怎么做到的?
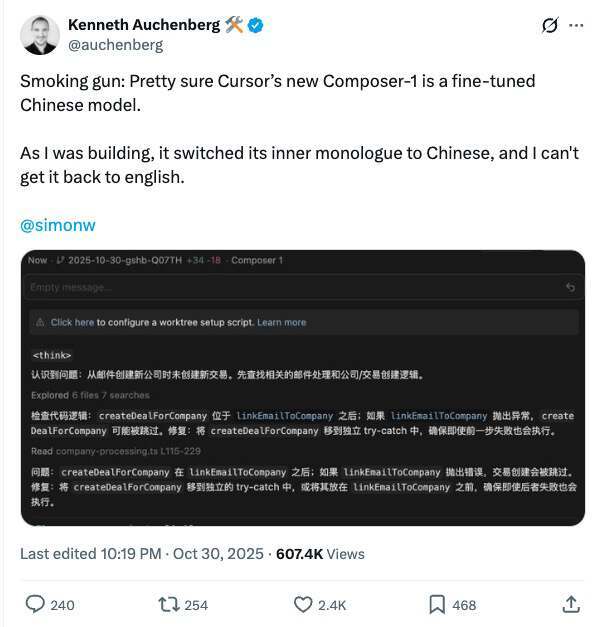
在 Cursor 中,用户向后端提交请求,Agent 接收后会决定调用哪些工具。目前 Agent 大约有十种工具,这里重点介绍其中五种:读取文件、编辑文件、代码库搜索、Lint 检查与执行终端命令。模型会自主决定工具调用是串行还是并行,并通过强化学习尽量逼近真实生产环境的表现。
在训练中,我们会运行大量 rollouts,例如模型可能选择读取文件或编辑文件;在另一轮推演中,以同样初始状态,它可能选择进行代码库搜索。我们随后对这些结果评分,选出更优的结果,再调整模型参数。
尽管这一理念在概念上很简单,但难点在于把它扩展到大规模训练。主要挑战包括:
第一,训练环境与推理环境的一致性。Composer 是大型 MoE 模型,需在数千张 GPU 上并行训练。如果训练速度跟不上,模型根本无法完成。因此,我们必须让训练采样环境尽可能接近真实使用场景。
第二,Agent rollouts 的复杂性。推演可能涉及几十万至上百万 token、上百次工具调用,而且不同推演的执行时间可能完全不同,导致管理异步结果成为一项难题。
第三,一致性问题。为了贴近生产环境,我们必须使用与真实 Cursor 完全一致的工具格式与工具返回结果。但训练阶段的计算负载极其集中、呈爆发式,与生产环境分布式、平稳的请求模式差异巨大,这带来了巨大的基础设施挑战。
以上三个看似是机器学习问题的挑战,其实最终都需要依靠底层基础设施来解决。接下来,我想讨论我们是如何解决这些问题的。
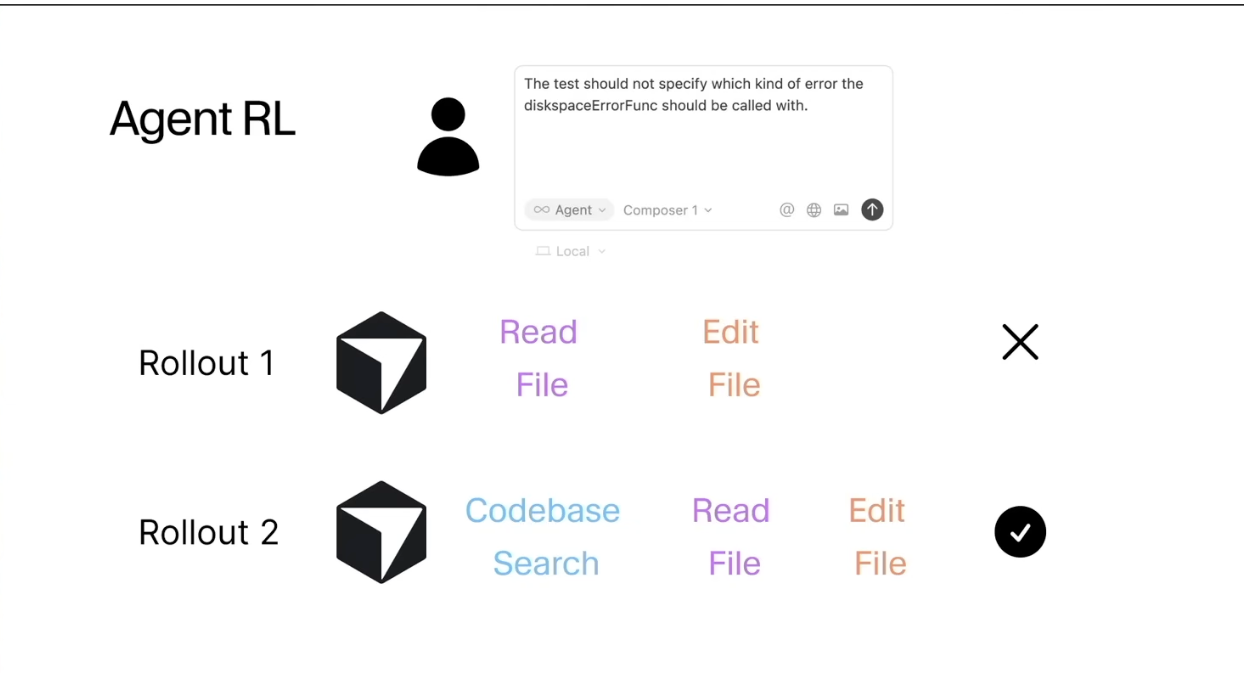
我们主要使用三类服务器:推理服务器、运行标准 PyTorch 机器学习栈的训练服务器,以及用于模拟我之前提到的 Cursor 环境的环境服务器。这三类服务器彼此通信,例如推理服务器会将优势函数传回训练端,根据 rollout 的反馈 nudging 模型参数,并更新权重。
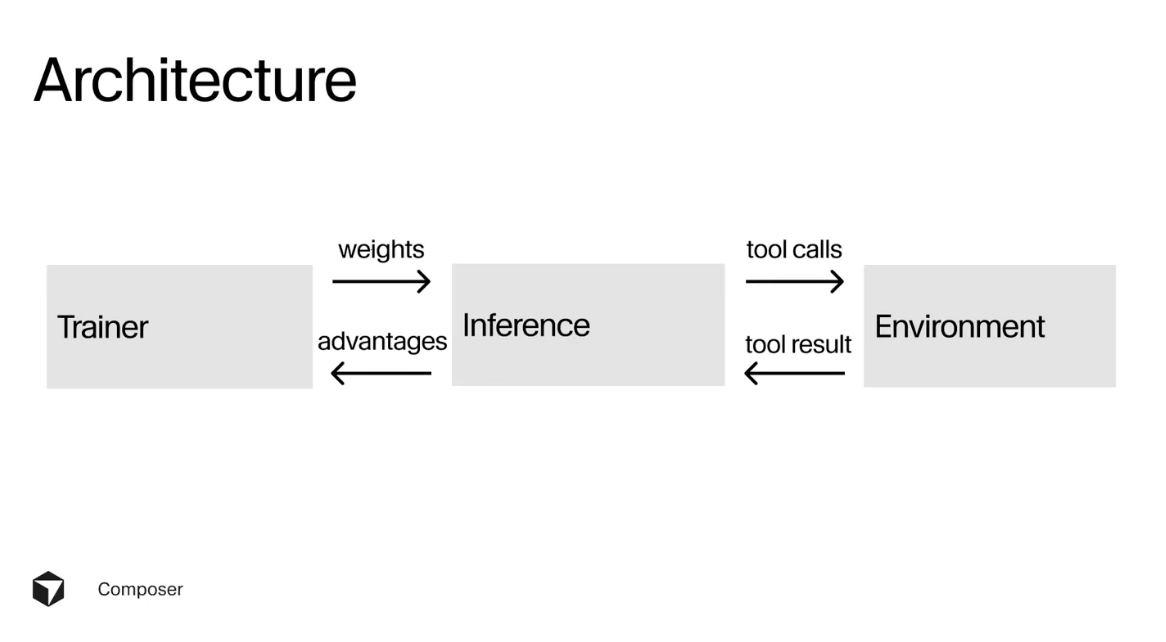
我们希望在尽可能短的时间内训练一个非常大的模型,研究团队开发了一套低精度训练的自定义算子库,大幅提升了训练效率,同时也让模型更易部署到推理服务器。使用英伟达 Blackwell 芯片后,我们在 MoE 层上取得了约 3.5 倍的性能提升,对训练速度产生了显著影响。
在训练过程中,当权重更新后,需要将它们回传给推理服务器,而推理服务器负责执行 rollout、调用工具并进行任务管理。挑战在于这些任务的完成时间不一致,若按朴素方式执行会造成大量空闲等待。为此,我们在不同线程与进程间做负载均衡,动态调度任务,避免因为某些 rollout 调用了大量工具(如安装包、加载库等)而阻塞其他任务。推理服务器会频繁与环境通信、调用工具并接收返回结果。为确保训练环境最大程度接近真实产品,我们构建了与 Cursor 生产环境高度一致的模拟环境。
同时开发编码 Agent 与 IDE,也构建模型的训练与研究体系的好处在于,能够实现“共同设计”(Co-design)。例如,在搭建强化学习训练体系的同时,我们也开发了 Cloud Agents 产品,使用户可以在手机、网页或 Slack 中离线运行 Cursor Agent。每台云端虚拟机(Virtual Machine)都会加载用户代码,让 Agent 在安全沙箱中修改文件、运行工具并编辑代码。而巧合的是,这套 VM 基础设施也非常适合作为强化学习的训练环境,让我们能够大规模运行模拟环境。
尽管如此,训练负载与推理负载的形态并不相同。训练任务更具峰值性和不稳定性,因此我们需要构建能支撑大规模集群、调度数十万台虚拟机的基础设施。这是我们利用 Composer 构建的内部可视化仪表盘,用于监控整个 VM 集群。

为什么我们如此在意训练环境与生产环境的一致性?原因之一是,这使我们能让模型使用我们认为在真实 Agent 中极其有价值的工具。例如,我们训练了自研的嵌入模型,用于语义搜索。当用户使用 Cursor 时,我们会索引其代码库,使 Agent 能通过自然语言检索需要编辑的文件。研究表明,语义搜索显著提升了 Cursor Agent 中几乎所有模型的表现,尤其是 Composer,因为它在训练时就使用了与推理完全一致的环境,从而成为语义搜索工具的“熟练用户”。
未来方向
在训练阶段,我们通过持续 rollout 来观察模型性能是否不断提升。最初,我们的性能与最好的开源模型大致相当。随着投入更多计算资源,性能持续提升,如今已经接近业界最强的代码 Agent。我们认为这说明强化学习可以很好地扩展并应用在高度专门化的任务上,除了编程以外,也完全可能扩展到其他领域。
强化学习还帮助我们调整模型的一些关键行为,使其更符合 Cursor 产品的需求。例如,我们不仅希望模型生成 token 的速度快,更希望端到端结果的体验良好。通过工具调用并行处理,我们使模型能够同时读取十个文件,而非逐个读取,从而在 Composer 中显著加快响应速度。模型的 Agent 行为也随训练逐渐改善:早期模型会进行大量不必要的编辑,而经过训练后,它更倾向于先搜索、先阅读、确认目标后再修改,从而提升整体效率。
Composer 随 Cursor 2.0 一同发布,目前用户反馈良好。我常用的比喻是“飞机上的 Wi-Fi”,它能用,但也令人沮丧,你希望它更快,否则宁愿没有。早期的编码 Agent 就处在这种“半同步的痛苦地带”:既不够快,也不足够强,任务往往要等 10–20 分钟,非常影响体验。而 Composer 带回了“写代码时的那种愉悦感”,高度同步、快速响应。现在,我日常会用 GPT 5.1 Codex 来写计划,再让 Composer 根据这些计划执行实际的构建。
关于 Composer 的研发,我们有几点反思。
首先,强化学习在训练高度专用模型时效果出乎意料地好,只要给予高质量数据与足够算力。Cursor 并不追求通用人工智能,而是要做最好的代码模型,而强化学习在这一方向上非常契合。
其次,像 Cursor 这样的 AI 工具能极大加速研发效率。我们的工程团队都在使用 Cursor 编写与调试代码,这种效率提升在团队规模增长后会呈指数级放大,让我们能更快尝试新想法、迭代产品与研究。
第三点是我们发现模型训练与基础设施之间的关联远比想象中紧密,框架层的“魔法时刻”往往离不开底层基础环境的支撑。
参考链接:




