
在 Apache 首次亚洲线上技术峰会 --ApacheCon Asia 大会上,网易数帆大数据专家,Apache Kyuubi PPMC,Apache Spark / Submarine Committer 燕青(Kent Yao)分享了 Apache Kyuubi 孵化器项目(注:下文中出现的 Apache Kyuubi/Kyuubi 等缩写均指代 Apache Kyuubi 孵化器项目)以及 Serverless Spark 在网易的实践和探索。Kyuubi 是网易数帆大数据团队开源的项目,在各位导师和社区小伙伴的共同努力之下于今年 6 月 21 号正式进入 Apache 孵化器。以下为本次分享内容整理,在不改变原意的基础上有所删减。
Kyuubi 研发目的与架构设计
首先简单认识一下 Kyuubi 项目。Kyuubi 是基于 Apache Spark 实现的一个 Thrift JDBC/ODBC 服务,支持多租户和分布式的特性,可以满足企业内诸如 ETL、BI 报表等多种的大数据场景的应用。它的设计动机是让 Spark 能够开箱即用,用户可以像使用一个 OpenAPI 一样直接调用 Spark 能力,而不需要像使用 SDK 一样将 Spark 嵌入自己的业务逻辑,这样一方面可以降低用户使用 Spark 的门槛,另一方面也使得业务代码与 Spark 数据访问层解耦,简化业务代码逻辑。
GitHub 地址:
https://github.com/apache/incubator-kyuubi
从业务场景来讲,Kyuubi 在网易构建之初的目的是为了丝滑地迁移 Hive 任务到 SparkSQL 之上。在早期的踩坑过程中,我们也尝试过 Spark ThriftServer(STS)和 Hive on Spark 这两个社区项目。前者不支持多租户,导致细粒度权限控制等重要功能难以实现,我们也曾经尝试去魔改它,但是魔改的版本较难维护和拓展,对 Spark Core 的侵入式修改使得后续升级 Spark 版本也不容易,另外它本身的架构也不适合大规模应用来支持每天几万、几十万的 Hive 任务的迁移,最终放弃了。后者的性能跟 Spark 差距还是很巨大的,稳定性也不尽如人意。
HiveServer2 是一个广为使用的组件,对于 SQL on Hadoop 的场景来讲,它功能齐全,开箱即用,但是性能相对堪忧,所以大家都在找替代方案。下图分别展示了不同用户提交不同的 SQL 任务到 Kyuubi、Spark ThriftServer 和 Hive 的不同处理方式,最右边 Hive on Spark 是将原本的 MR 擎换成了 Spark,但是为了和原本的 MR 及 TEZ 引擎共存,Hive 选择保留了自己的优化器,将 HiveQL 转换成 Spark Core 代码。然而,Hive 的优化器翻译的执行计划不如 Spark 优化器翻译的合理和高效,另外部署这样一套系统需要维护两个大型项目,从运维的角度来讲也不是特别好。
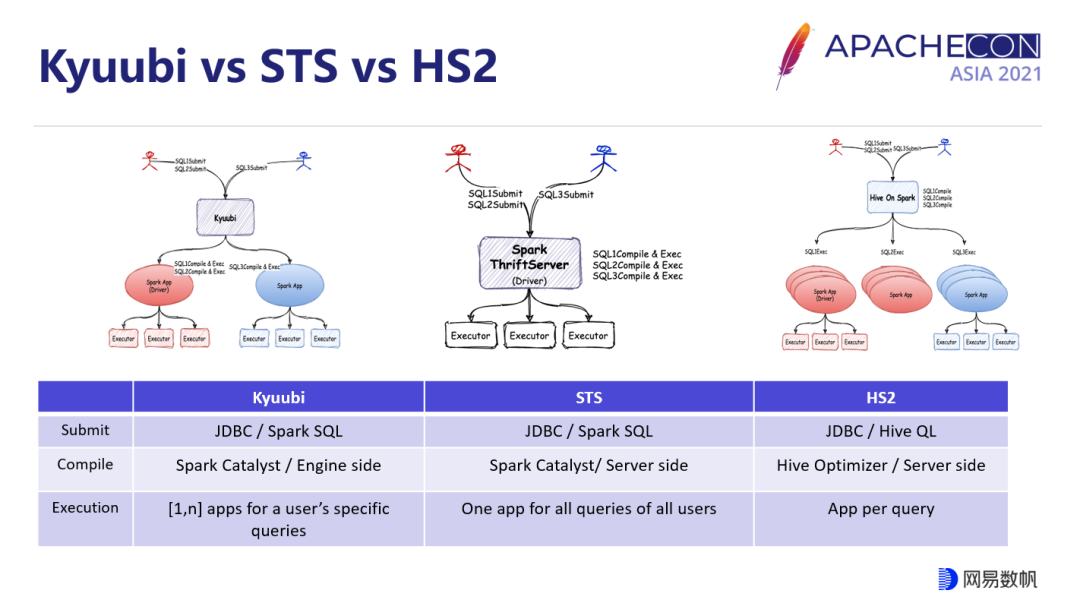
Spark ThriftServer 是 Spark 社区维护的对标 HiveServer2 的一个组件,也是开箱即用,而且性能非常好。但它是基于 Spark 单 APP 构建的,全局只有一个用户,不支持多租户,所以计算和数据的访问都没办法做到隔离,而各 APP 的整体吞吐也受到主从架构的下主节点的单点瓶颈的限制,并发能力有限。当不同的用户有不同的 UDF 去注册到它上面来的时候,就会产生很多冲突。
为了更加契合企业内部多租户场景下的应用,我们需要将资源隔离的需求在 Kyuubi 上面去实现。Kyuubi 需要在 Spark 之上引入一个多租户的能力,有了租户概念的引入,我们才能很好的在在 Spark 上面做权限认证,来保障各类服务以及数据的安全。与 Hive on Spark 相比,Kyuubi 在 SQL 优化和执行都选择依赖于 Spark 本身去实现,以获得极致的性能,包括 Spark APP 的管理也是通过 Spark 的 public API 实现,所以它的技术栈相对来说收敛于一个整体的运维和管理。
Spark 作为一个生态级的应用,对于用户而言是十分复杂的。一方面 Spark 只是个计算框架,它需要运行在基础设施之上,用户如果直接写 Spark 的逻辑,有时候还不得不和底层的存储、调度等基础设施打交道。另一方面 Spark 计算框架也不是那么容易上手,用户需要懂得使用 Spark 的一种或多种的 API 接口来编写代码,需要对 Spark 的数据抽象、资源累计使用、大几百的参数等等都有较好的了解,问题的定位也如大海捞针无从下手。
此外 Spark 社区也是一个发展非常快的社区,新技术不断迭代,这也会让用户感觉到学无止境。如图所示,我们通过 Kyuubi,想把右侧包括 YARN、Kubernetes 等调度框架,以及 Hive 元数据存储、HDFS 元数据存储,或者把环湖生态的整个构建对用户隐藏,在 Kyuubi 里面用户只需要使用已有的 BI 工具,或者通过 JDBC 程序使用 Spark 操作数据就好了,不需要引入任何的 Spark 代码来实现业务,最终的服务也会把自身给隐藏掉,Spark 底层及其依赖的一些复杂性,可以由我们这些服务端的同学来帮助完成。诸如一些问题的定位诊断,性能的优化以及对接数据库产品,实现 Spark on Kubernetes,或者是对 Spark 能力的一些拓展,都可以在服务端来帮助用户完成。这一方面便于用户使用,另一方面也使得底层服务以及底层的数据更加安全可控。
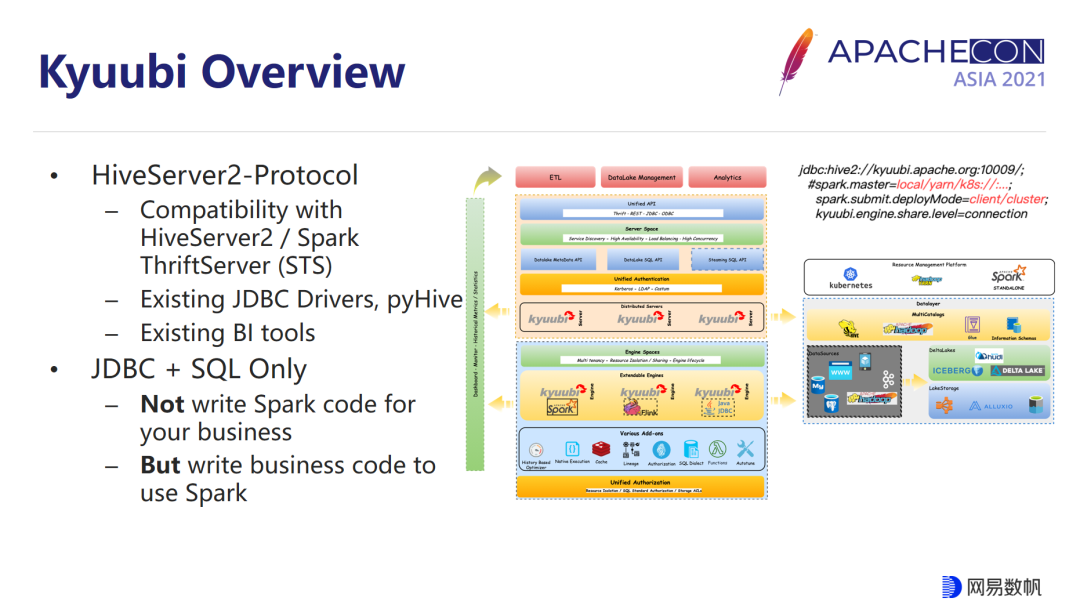
Kyuubi 从软件架构上分为 5 个层次,从上至下依次为客户端层、Server Space 层、Kyuubi Server 层、Engine Space 层和 Engine 层。其中,Server 是提供服务的常驻进程;Engine 是 Spark SQL 程序,全盘保留了 Spark SQL 的既有能力和拓展空间;Server Space 层提供了 Kyuubi Server 的“对外”注册发现机制,它通过一个“统一”的 space 空间提供所有租户,以及所有客户端的服务发现;Engine Space 提供了 Kyuubi Engine 的“对内”注册发现机制,通过一个“租户专有”的 space 提供特定租户内部的发现机制,用以实现租户的隔离。
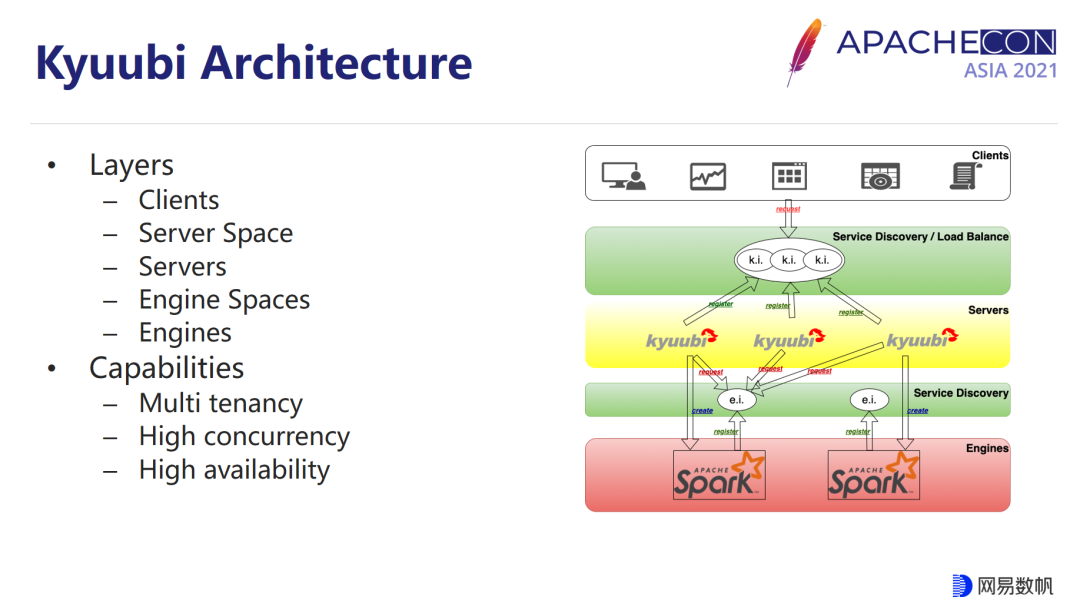
引入 Engine Space 层的另一个目的是为了在高可用模式下让 Kyuubi Server 所有负载均衡节点也能顺利发现对应已经存在的 Engine,同时在这个框架下,Server 自身不再需要去维护 Engine 的状态,更有利于线性水平扩展,提高并发能力。
举个例子,当某个用户通过客户端发起连接请求时,先在 Server Space 中会选择一个可用的 Kyuubi Server 服务,Kyuubi Server 服务会探测用户的专有空间下面是否存在一个可用的引擎,如果没有的话就会负责创建一个,当引擎初始化完毕之后,它会将自己暴露到专有空间中,被 Server 轮询到之后建立连接,其他负载均衡 Server 如果在这个时候也同时在处理同租户的不同连接请求,并索引到这个引擎,也可以直接建立连接、将连接建立完毕,客户端就可以顺利的把 SQL 发送到这个引擎之上来执行了。
对于不同共享级别的引擎,我们设计了不同的回收策略,分别针对于单个 JDBC 连接或者是单个用户这两个维度,另外用户维度还可以设置“子域”进行细粒度的共享。比如说当引擎是 JDBC 连接专有的,所有的 SQL 处理完成之后,整个 JDBC 连接关闭,这个引擎我们会立马回收掉;如果是用户级别的共享,我们可以自定义它的缓存时间,缓存周期内下一次连接或者是从别的负载均衡节点上的连接都可以快速的建立,可以大大减少 Spark 程序的启动时间,资源的常驻也可以让 SQL 作业快速的得到响应,因此这种模式对 ad-hoc 场景非常友好。
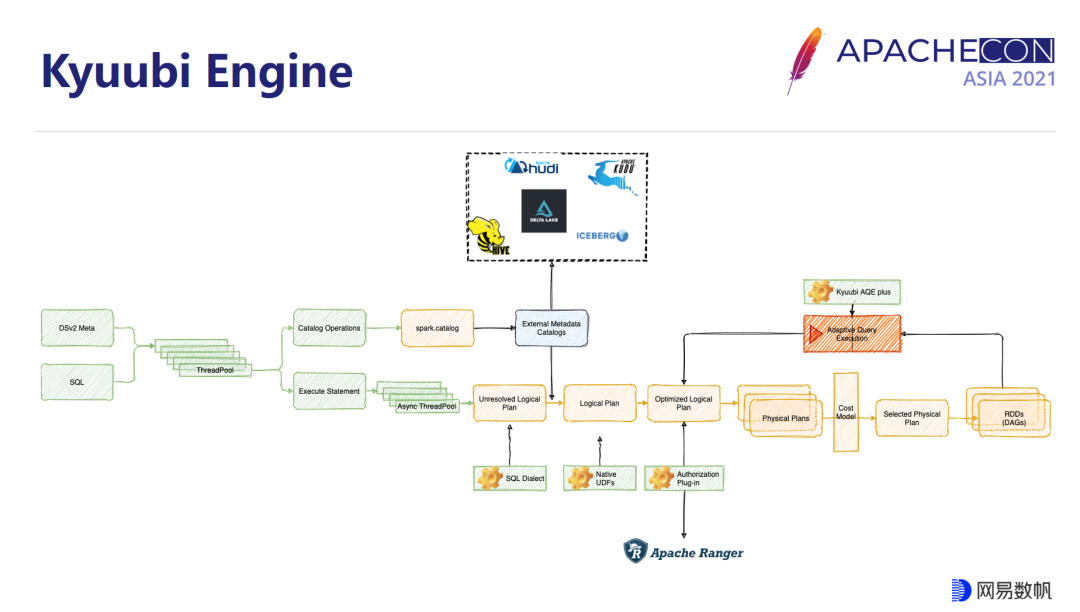
Kyuubi 引擎是我们对 SparkSQL 内核的多个维度的拓展而构建的一个独立的 Spark APP,它最终负责处理指定用户的所有 SQL 请求,SparkSQL 从整个编译执行链路上提供了很多扩展点,让我们可以帮助用户或自己在原生的 Spark 之上实现很多有趣的功能。比如在 Kyuubi 里面,我们在 Optimizer 的阶段对于权限控制插件的引入,以及在 AQE 阶段对于 AQE 本身的扩展,让 Kyuubi 面向实际场景的时候做到更加自动化。
网易如何基于 Kyuubi 实现 Serverless Spark
在网易我们通过 Kyuubi 来实现 Serverless Spark,我们尝试将它抽象成两块内容:一个是提供服务的平台以及 Kyuubi Server,另一个是平台提供的服务,是 Kyuubi Engine,也是一个 Spark 程序服务,其实就是 Spark 计算框架的能力。Spark 是一个通用的数据处理框架,所以平台要做的事情是将 Spark 对于数据处理的能力直接赋能给用户,而不是将计算框架本身或者是使用这个计算框架去写业务代码的能力给用户。

换一种角度来讲,为用户提供 Serverless Spark 服务平台本质上需要降低 Spark 自身在这个框架之下的存在感。平台需要提供简单的 API 以外,还需要易于管理和维护,升级也不会成为障碍,因为我们在整个服务生命周期需要频繁地对 Spark 进行升级或者是拓展,这需要对 Spark 内核或者是线上发布版本进行变更,而且这个过程需要不停服来实现,这样可以做到用户无感知。同时我们需要提供高可用和高并发能力,来满足 SLA 的目标。对于数据的接入以及资源的使用,对于计算过程的自动化以及以快速获得技术支持等,各个方面我们都希望能够做到弹性。
多源数据接入能力
Serverless Spark 的内容很多,这里挑选一些重点分享。第一点是构建 Serverless Spark 提供数据的接入能力,它是一个基础的工作,现在发布生态非常火,Spark 提供的多数据源的访问能力就可以做到这一点,包括最新的几个炙手可热的数据湖框架,比如 Iceberg、Hudi,最初都是围绕着 Spark 社区构建的,Kyuubi 在 JDBC 的 Meta API 上面进行拓展,支持了数据湖场景下多 Catalog**** 特性。
下图右边是我们基于 Kyuubi 1.2、Spark 3.0 和 Iceberg 0.11 构建的一个小 DEMO,我们可以看到无论是 Spark 内置的传统数仓,Hive 提供的 Hive catlog,还是新的数据湖框架,Iceberg 提供的 Hadoop catlog,以及这些 catlog 所有包含的汇表的信息以及它们所支持的数据结构,都可以在一个开源的 SQL 客户端中展示,配合 Spark 对于多 catlog 的读写支持,这使得我们对整个数据湖的管理访问探索变得所见即所得,用户是不需要感知他操作的是一个传统的数仓还是一个新型的数据湖架构的。

多级资源弹性能力
第二点是通过弹性地资源利用来提升计算的性价比。资源弹性涵盖集群可利用资源和作业已使用资源,并可以分为多个层级。
第一个是集群级别的资源弹性,我们可以根据需求来构建集群的规模,来控制队列的大小,并通过一定的策略,比如时间的因素来动态扩缩容。
第二个是节点资源的弹性,我们可以针对不同的业务类型,比如在网易我们将业务分为在线和离线业务,通过标签的方式控制不同的业务在单个节点上能够使用的资源比例,包括 CPU、内存、网络等,可以设定不同的调度优先级,以及不同的驱逐策略,还可以动态调整这些参数的设置来改变策略。
第三个是作业级别的资源弹性,通过前面讲的 Kyuubi 对于引擎的生命周期进行管理,来实现高效的回收和复用。
第四个是作业内的资源弹性,Spark 支持动态资源分配来实现 Excutor 的弹性分配,其中最重要一点是向下缩容的能力,可以避免“拖尾任务”导致大量的 Excutor 长期闲置。
这个功能依赖于 Spark External Shuffle Service 来帮助管理 Shuffle 阶段的数据才能实现。但目前在这个功能在 Spark ob Kubernetes 模块里是缺失的,社区目前只有一个临时的解决方案,叫做 Shuffle Tracking。在我们实践过程中发现这个临时方案用处不大,就是说 Spark 社区版本在 Kubernetes 上基本丧失了向下缩容的能力,这会造成大量的资源浪费。
针对这个问题,我们在 Kyuubi 里面引入了如图所示的一个 External Shuffle Service(ESS)来解决,这个方案实现非常简单,我们可以直接利用 Spark 提供的镜像来制作一个基础镜像,只要修改它的一个启动入口,设置启动 Spark 自带的 Standalone 模块中提供的的 External Shuffle Service 来直接复用它,再将它制作成一个 DaemonSet 发布到 Kubernetes 集群的每一个节点,这样一个基础的 External Shuffle Service 就做好了。

同时我们和网易数帆存储团队合作,使用他们开源的分布式存储系统 Curve 来远程存储我们的 Shuffle 数据,这一方面帮助我们克服了传统物理集群上面经常出现的 disk failed 等硬件故障导致作业的不稳定,另一方面在 Shuffle read 的阶段配合 Spark Shuffle 参数的调优,采用这个方式也大大缩短了数据传输的链路,使得性能有一定程度上的提升。当然最主要的目的还是为了在 Spark on Kubernetes 场景下面,能够优雅地向下缩容来节省资源。
计算自动优化能力
第三点是对于计算过程做到自适应,因为在 Serverless Spark 场景下面,用户的一条 SQL 过来,Spark 作为一个计算引擎,虽然知道访问哪些数据,但它很难去保证这些数据的统计特征是准确的,优化能力有限。静态的分区设置也可能会导致一些不良的后果:如果静态分区设置过小,它会导致 Spark 在计算过程中并发度不够,严重影响性能;如果静态分区值设置过大,也可能会引入小文件的问题;此外可能还会产生数据倾斜的问题。在这种场景下面,对于大部分用户来讲,他在 SQL 上自己处理的能力还是欠缺的。
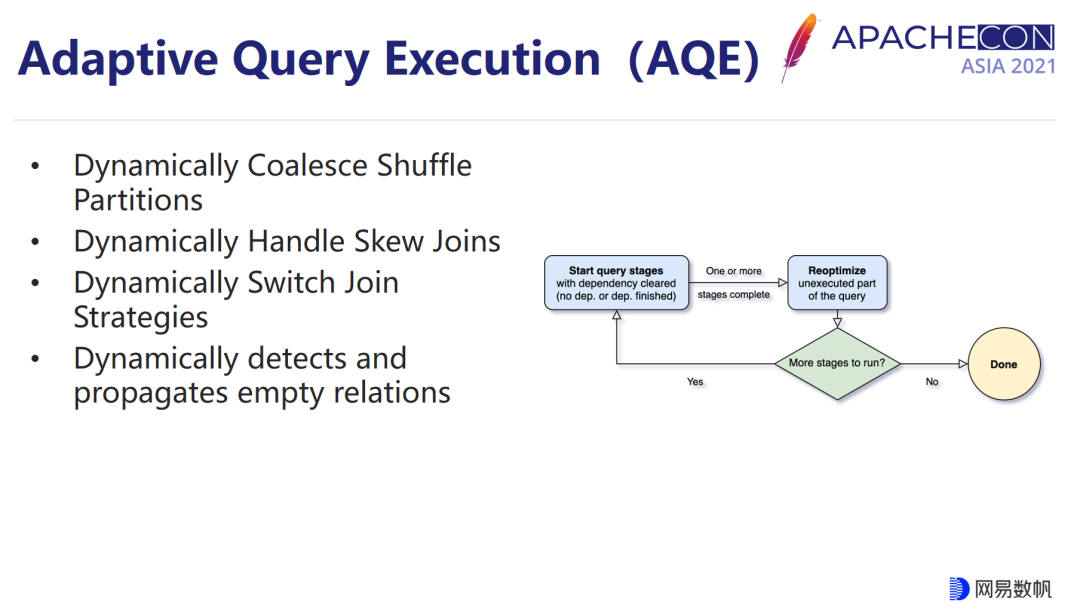
Spark 在 3.0 版本之后引入了一个自适应查询优化(AQE)的功能,它可以利用 Shuffle 和广播等过程中记录的一个中间物化结果的准确统计值,在对剩余的执行计划进行进一步的优化。这个特性对于表达能力受限的纯 SQL 场景是非常必要的,除了能提升性能之外,更重要的是能帮我们自动地去解决前面讲的一些问题,比如在发现分区数比较小的时候,它可以帮助我们进行合并,防止调度侧的开销浪费,或者是一些小文件的 I/O 的问题;反之如果是部分分区体积过大过大,它可以对我们的大分区进行切割,防止数据倾斜的问题发生。
这里我们给了一个 DEMO 来演示 AQE 的功能,DEMO 大致的意思是通过 id 去关联两张表,接着对于 id 取个模分个组,然后来求 sum、count 等聚合值,最终输出到一张 text 表里面。
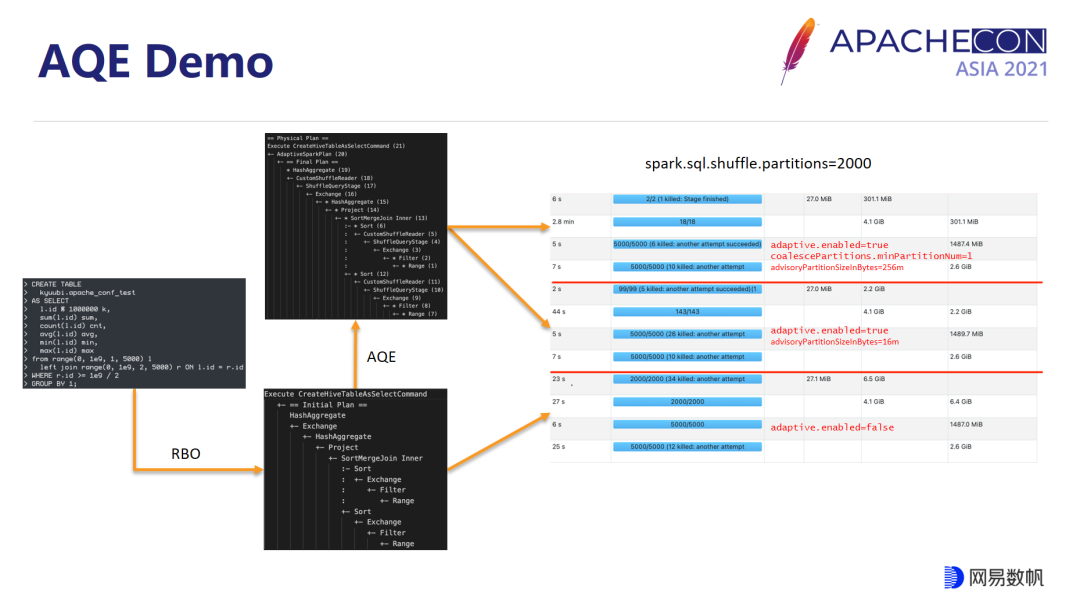
首先我们可以看到经过 Spark 的 RBO 它帮助我们完成了位置下推,条件传递、 left join、转 in 的 join 等操作,最终让我们拿到一个 initial 的 physical 的 plan。
在 AQE 关闭的条件下面,我们直接执行这个 plan,我们发现在最后的两个 stage,它的分区数是 2000 这样一个静态的配置,过大的分区数,会导致非常严重的小文件问题,这需要我们额外对这些小文件进行处理,或者是起另一个 Spark job,或者是起另一个 Hive job 去合并这些小文件,这也导致了一些算力的浪费。在 APP 内部它也导致了调度侧的一些压力,很多 task 其实是一些无效计算,造成计算资源的浪费。
在 AQE 的开启了之后,AQE 就会拿 initial plan 自上而下地遍历到找到这些 exchange 的节点,并将之物化,根据这些物化的统计信息自动去优化剩余的 plan,一直循环到 final plan 为止。
我们可以看到分区合并规则的作用,过小的分区被合并了,我们在第 3 个 stage 以及第 4 个 stage 里面看到它的分区数大大的降低了,小文件的问题得到了一定的缓解,但是因为 SQL 最终还是需要输出到一张表,99 个文件去存储 27M 的数据,显然也不是很合理,这个时候我们可以进一步调大推荐分区的大小,以及调小 minPartitionNums 的值,最终可以让我们只输出两个文件,但是我们在这个过程中也同时发现分区数过分降低会对 Spark 性能造成一定的影响。
对于这个看似于和熊掌不可见得的场景,我们在 Kyuubi 里面拓展了 AQE 规则,让 AQE 对我们纯 SQL 场景更加友好,比如 stage 级别的配置隔离,让不同的 stage 可以使用不同的 AQE 参数来控制推荐分区大小或者是分区设置。

第二个是增加 jion 倾斜的命中,第三个是对于简单 SQL 的小文件处理。比如刚刚讲的 Case,我们开启 stage 级别的配置隔离之后,发现整个执行计算过程中可以让中间的 stage 的并发度得以保留,但是在最后的一个 stage,我们尽量将它合并,让输出的文件个数更加合理。
当然资源可以弹性,计算可以动态,但是第三点,人力往往是做不到这一点,针对于这个问题,一方面我们通过 Kyuubi API 的收敛,充足的文档以及 Monitoring 工具的构建,很大程度上降低了和用户之间的沟通成本,因为用户只用 SQL 来执行作业,所以我们通过一些资源监控工具,可以便捷、全面地了解知道用户在做什么,做的事情到底合不合理。
另一方面我们没有选择自己维护一个很重的内部分支,而是将大部分的特性和 bugfix 第一时间贡献给了 Spark 社区,这个大包袱丢掉之后,我们 Spark 基础分支的升级换代能力以及升级过程的兼容性保证,都得到了大大的提升,新版本的 Spark 一般来说它真的很香。
作为回报,当我们遇到一些超出能力范围的问题时,我们也会得到 Spark 社区很多直接的帮助,所以我们也希望通过 Kyuubi 也能去构建这样一个良性的社区,帮助他人也帮助自己。
应用案例
最后介绍网易实际工作中在 Kyuubi 项目之上完成的两个 case。
从 HiveQL 到 SparkSQL 的迁移
第一个是将 HiveQL 迁移到 SparkSQL 上,由于我们这个架构上面 Kyuubi 对于 Hive 的高度兼容性,整个过程代价和痛苦非常小,但是收效很明显,在 AQE 和我们对 AQE 拓展的加持下,我们帮助业务整体将资源砍掉将近一半的同时,任务的平均执行时间反而缩减了 75% 左右。
同时 Kyuubi C/S 架构保证了 Spark 版本快节奏的升级,我们现在内部使用的 Spark 版本是 3.1.2,基本跟社区最新版本 match 的节奏,而且我们提交到 master 分支上面的很多 patch,以及和社区一起做的 patch,都会 fork 到我们内部分支上面来,进一步增强内部分支的能力。
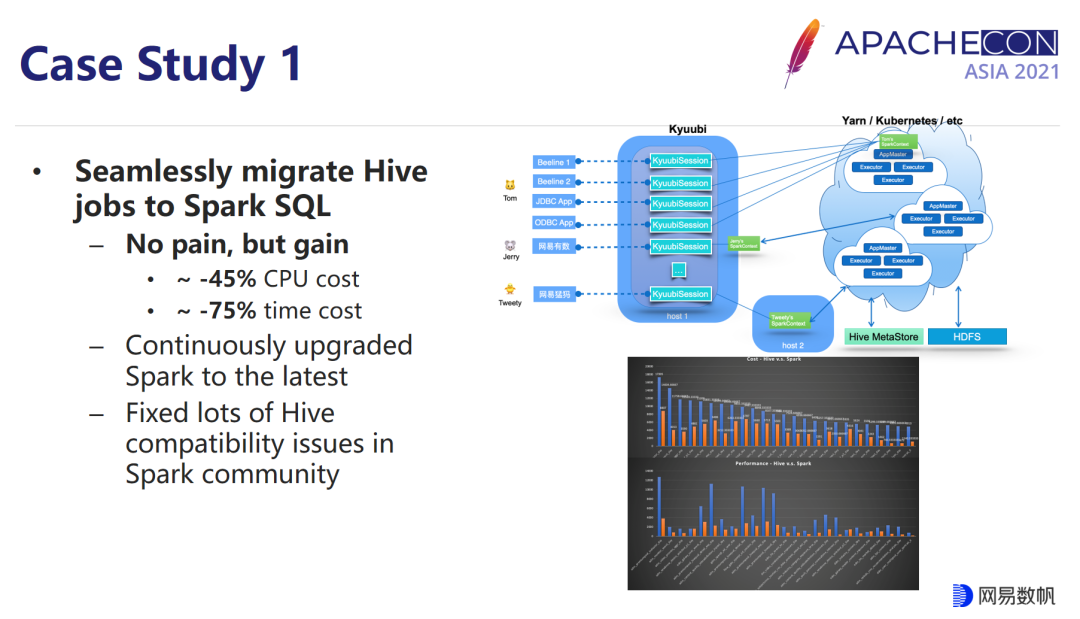
当然在这个过程中,我们也不可避免地会遇到还有 HiveQL 跟 SparkSQL 的一些兼容性问题,以及底层的一些 FileFormat 的兼容性问题,大部分问题都已经顺利地和 Spark 社区解决,社区一些 won’t fix 的问题,我们也及时敦促用户修改,或者是通过 Spark 的拓展点去提供一些额外的插件,帮助用户去解决这些问题。
从 Spark on YARN 到 Spark on Kubernetes
第二个是我们正在帮助业务线做 Spark 作业从 YARN 集群迁移到 Kubernetes 集群上的工作,目的是实现存算分离,离线业务和在线业务混部等诉求,最终可以通过一个集群来管控所有的任务,帮助他们实现一个更好的资源弹性,从而来节省大量的集群构建的成本。
Spark on Kubernetes 的方案,我们是直接是将 Spark 裸跑在 Kubernetes 集群上面,而不是中间套一层 YARN 集群或者 Spark Standalone 这种伪模式,我们基于 Kyuubi 构建一个跟 YARN 几乎镜像的 Kubernetes 环境来承接整个迁移过来的任务,包括前面所说的对于 ESS 的支持。
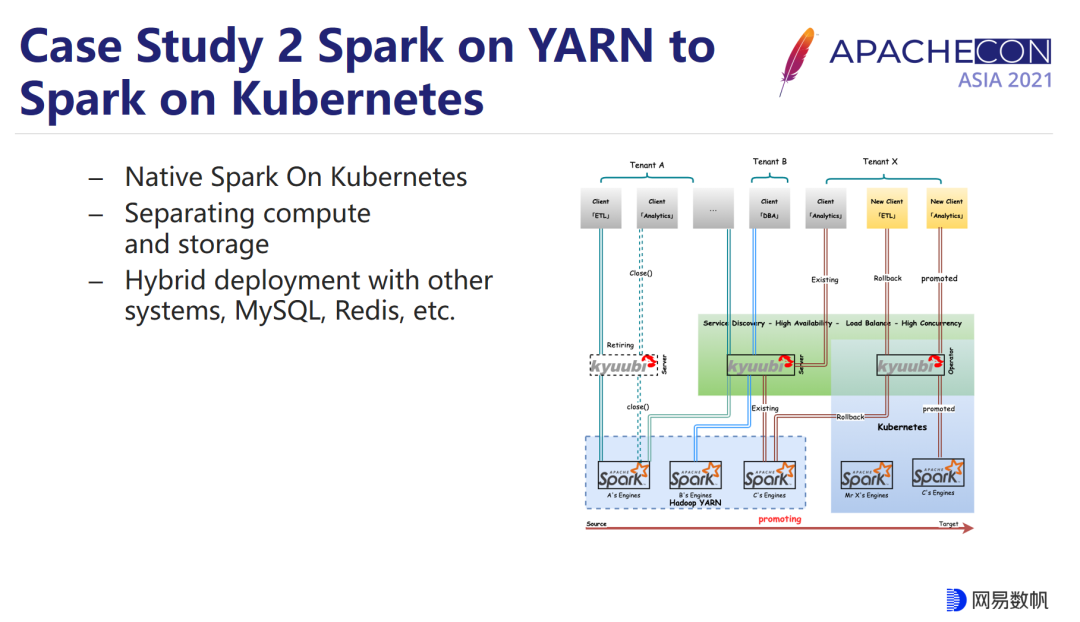
理论上整个过程是可以做到对于用户几乎感知的,但我们是第一次做这个事情,出于安全迁移的考虑,我们重新部署了一个 Service 暴露给用户来使用我们的服务,相当于我们在 YARN 跟 Kubernetes 上面有两个独立的服务来提供这样的迁移。当然对用户来讲,他们的感知其实也只有参数变更,在整个迁移周期内,YARN 的服务并不是直接下线的,而是逐步根据迁移的比例慢慢缩容,这可以帮助我们防止迁移过程中的各种问题导致业务停摆,任务可以适时回滚到 YARN 去保障执行。
正如所料,我们迁移 Kubernetes 的整个过程并不是一帆风顺的。比如这样一个 case,我们将它迁移到 Kubernetes 上之后,任务的耗时相比它在 YARN 上面执行增加了 10 倍多。为了防止后续任务因此出现问题,用户可以直接修改参数连接到 YARN 上面,Space 可以保障用户重新调度到 YARN 上面去,这也同时给了我们诊断问题的时间和机会。
在这个过程中我们会着手修复这个问题,我们大部分修复的方式是将这个问题定位出来,直接抛给社区,然后拉着社区的大咖帮助我们做 code review 来保证 PR 的质量。社区的 Master 分支合进去之后,我们会第一时间回合到内部分支。在问题解决之后,我们任务就可以最终迁移到 Kubernetes 集群之上。
未来展望
未来围绕 Kyuubi 社区和 Spark 社区,我们其实还有很多事情可以做。短期内的主要工作,第一个是根据我们现在使用 Kubernetes 以及在 Kyuubi 里面实际的使用案例,和 Spark 社区继续去完善 AQE 框架和 Spark on Kubernetes 模块。
第二个是我们会为 Kyuubi 引入一个基于历史的优化器,对于在 Kyuubi 之上周期性的任务,根据它的历史对它的 SQL 或者是资源使用做进一步的优化。
第三是在 Apache 基金基金会下面,我们想围绕 Kyuubi 构建一个多元化的社区,有很多志趣相投的小伙伴已经加入,也提供了非常棒的 idea。欢迎更多有兴趣的伙伴加入我们。
我今天的分享就到这里。谢谢大家!
相关链接:
全票通过!网易数帆开源项目 Kyuubi 进入 Apache 孵化器
https://mp.weixin.qq.com/s/A83TYAl9KvvXYQpQrUqhlw
Kyuubi 与 Spark Thrift Server 的全面对比分析
https://mp.weixin.qq.com/s/4LQRlf2XAZL-MqWIXSHUvA
提效 7 倍,Apache Spark 自适应查询优化在网易的深度实践及改进
https://mp.weixin.qq.com/s/9XyLAkJ5seF-aPMZvo0hVQ
Kyuubi: 网易数帆开源的企业级数据湖探索平台(架构篇)
https://mp.weixin.qq.com/s/uQdAfMqv8Zkxjxkt6S2iPw
网易 Spark Kyuubi 核心架构设计与源码实现剖析
https://mp.weixin.qq.com/s/zFqTB_DU4uhgswXPBXH0aw
Apache Kyuubi PPMC 燕青:为什么说这是开源最好的时代?




