
现代湖仓架构的愿景是构建一个统一的数据层,使 Snowflake、Spark、Trino 和 Flink 等各类计算引擎都能够借助 Apache Iceberg 等开放标准实现无缝互操作。
尽管数据存储和元数据格式标准化方面已经取得了显著的进展,但仍然存在严重的互操作障碍:不同数据库引擎之间没有一种通用的语言。由于各厂商支持的功能存在差异,所以支持一种通用的 SQL 方言是一件很有挑战性的事,但我们要指出的是,即便在标识符(数据库、模式、表、表列等)这种最基础的方面,也存在不一致之处。
每种引擎在处理和规范化标识符时都有自己的历史规则,从而形成了一种“巴别塔”效应:各个工具之间无法在数据库对象命名上达成共识,妨碍了组织构建受控、统一且现代化的 AI/Data 系统的目标。随着组织从孤立的数据湖向湖仓架构转型,这一问题变得越来越明显,这些微妙的标识符问题已经在数据管道的可靠性和一致性方面引发问题。
湖仓中 SQL 方言的互操作鸿沟
为了理解这个问题,让我们通过一个场景来分析下:一名数据工程师使用以下命令在 Spark 中创建了一个表:
SQL CREATE TABLE my_lakehouse.MyTable (id INT, value STRING); SELECT * from my_lakehouse.mytable; — 成功返回结果默认情况下,Spark 会在 Apache Iceberg 目录中以与提供时完全一致的大小写形式将表名持久化:MyTable。随后,有一位业务分析师试图从 Flink 或 Trino 中查询该表:
SQL -- 尽管该查询在 Spark 上能执行成功,但在 Flink 和 Trino 上却会因不同原因而失败SELECT * FROM my_lakehouse.mytable;
Flink 会完全保留标识符的原始输入形式,因此,当分析师输入 mytable 时,Flink 会将 mytable 发送至目录,而目录中存储的表名为 MyTable。如果目录执行查找时区分大小写,那么就无法找到这个表。即使表解析出来了(例如通过不区分大小写的目录),列级访问仍然会严格区分大小写:对于查询 “SELECT Id FROM MyTable”,如果该列在 Iceberg 元数据中是按 id 存储的,那么查询依然会失败。Flink 将返回错误:“在任何表中均未找到列 ‘Id’;您是否想查询 ‘id’?”
由于 SQL 方言的差异,Trino 会带来另一种挑战。 Trino 会将标识符转换为小写,因此对 MyTable 或 mytable 的查询都是查找 mytable(小写)。如果 Spark 将该表持久化为 MyTable 或 MYTABLE,那么 Trino 区分大小写的目录查找将无法找到匹配项。
Trino 没有对带分隔符的标识符提供一等支持,因此,即使用户尝试指定大小写规则,针对非小写元数据条目的解析依然会失败。实际上,这会导致 Trino 引擎无法发现创建时表名使用了大写或大小写字母组合的表。
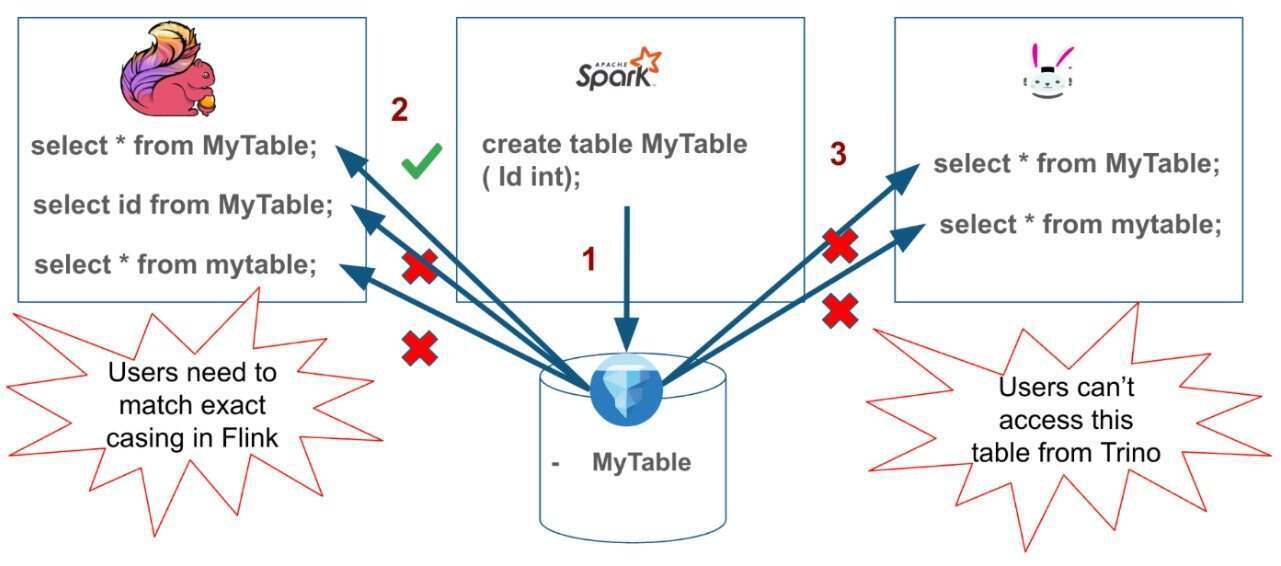
图 1. 展示主流数据库引擎中标识符问题的多引擎湖仓架构
在实践中,数据架构师通常借助 DBT 或 SQLMesh 等中间工具,将 SQL 代码编译为适用于不同查询引擎的格式,从而避免工作负载与单个查询引擎的紧耦合。虽然转译有助于减少为每个引擎重写工作负载带来的麻烦,但它无法防止架构师锁定那些在不同引擎间不兼容的标识符设计方案。
为什么现在是问题了?
在数据库领域,这一挑战并不是什么新鲜事,因为在历史上,数据库迁移就曾遇到过类似的 SQL 方言不一致问题。然而,在传统的孤岛式环境中,工作流受限于单一的引擎规则,人们往往觉得一次性的迁移困难很平常。而在现代湖仓架构中,多个引擎会同时处理同一组数据,这种痛点会始终存在。当 Spark 将 Table1 和 table1 视为不同的对象,而 Trino 却将其视为相同的对象时,自动化管道和跨引擎工作流就可能会失败,并导致严重的数据损坏或契约违背。
解决这种 SQL 方言互操作性问题,主要责任在于制定湖仓战略的组织,而非由单一目录或数据库平台来解决。本文将深入探讨不同目录和数据库之间的技术细节及行为差异,希望能帮助架构师设计出更具韧性的湖仓战略。
技术概览
标识符名称解析涉及到一套规则,其中规定了标识符中可以包含哪些字符,以及如何将标识符规范化为规范化的大小写形式(CNF),从而方便进行比较,并存储在元数据和存储系统中。在湖仓架构中,由不同供应商独立开发的多个组件需要相互协作,才能产生一种“有效”的标识符行为,这可能会打破现有工作负载的假设。
下图展示了湖仓架构中标识符解析与持久化的整体流程,并列出了涉及的各个组件:
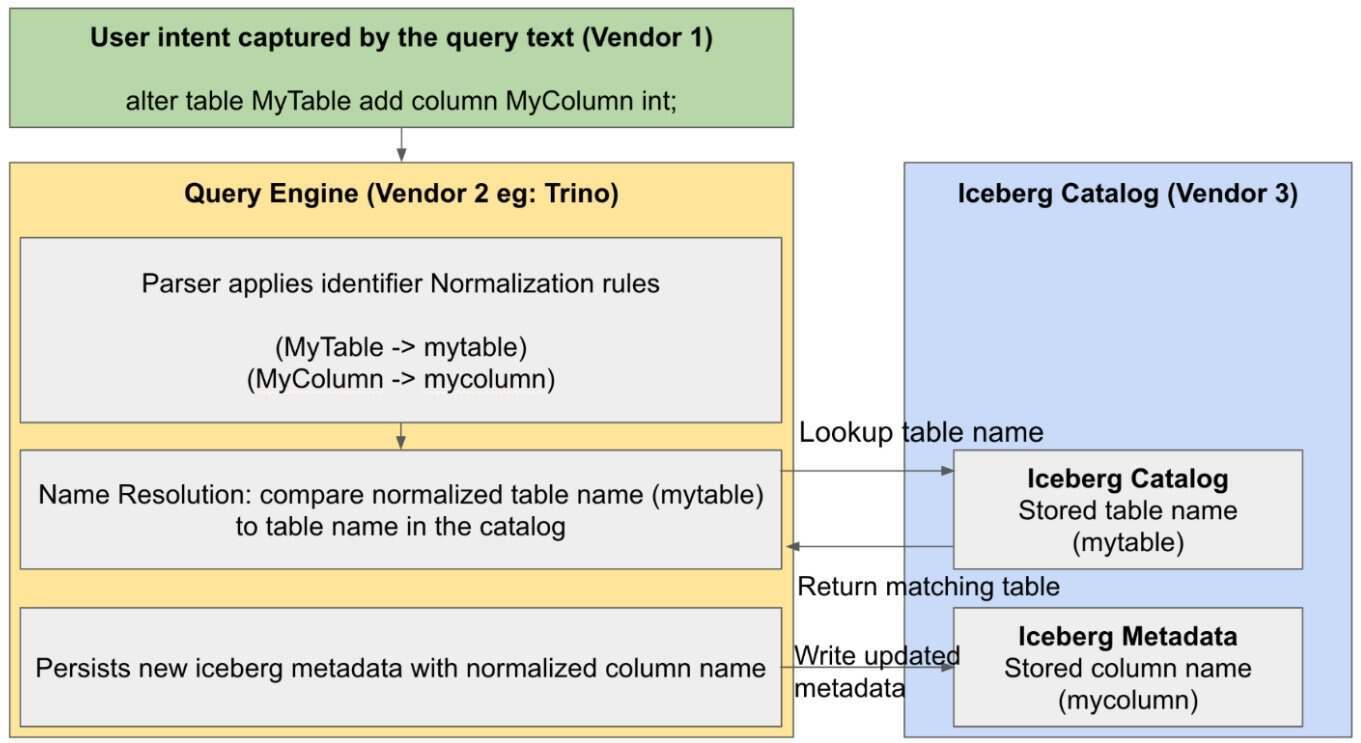
图 2. 标识符解析的高级流程图
因此,有必要对不同供应商的数据库引擎和目录进行调研,以了解其“实际”的行为及常见的陷阱。
行为调查:目录和引擎
本节将介绍不同数据库引擎和目录所采用的各种约定。我们将首先分析最常用的数据库引擎的行为,随后分析最常用的目录。
数据库引擎层差异
数据库引擎在与目录层交互时采用不同的逻辑。
数据库引擎层差异对比
目录层差异
目录是实体名称的权威来源,但其具体实现方式各不相同。
Apache Polaris 遵循 Apache Iceberg 规范。它接受通过 REST 接口提供的字符串,并在查找时进行区分大小写的匹配。
Databricks Unity Catalog 会将标识符标准化为小写。当 Spark 用户(他们可能期望区分大小写)与 Unity Catalog 中已经标准化为小写的对象进行交互时,这种标准化可能会导致不同的结果。
AWS Glue Data Catalog 会自动将大写实体名称转换为小写。
这三层(用户意图、数据库引擎和目录)之间的语义差异会导致隐蔽的故障和下游风险,进而可能导致日后需要耗费大量的成本进行重写。
场景演示
虽然从技术规范上看,每种引擎的解析逻辑在标识符处理方式上存在着明显的差异,但要真正理解这些选择所带来的实际影响,最好通过其运营后果来分析。以下两个场景非常具有代表性,因为它们并非基于单个客户案例,而是综合了多个真实案例。公司名称和具体细节均为虚构,但故障模式、错误信息和解决方案都是生产环境中实际遇到的。
对于为何一个组织选择了保留大小写的目录,而另一个则选择了规范化为小写的目录,我们做了分析,这两种选择均未提供放之四海而皆准的解决方案,而是各自以一种故障模式换取了另一种故障模式。
场景 A:NovaPay 使用保留大小写的目录(Polaris)
NovaPay 是一家金融科技公司,每天在 15 个国家处理超过 200 万笔交易。其数据架构包含 Apache Polaris(REST 目录)、用于 ETL 的 Spark、用于即席分析的 Trino、用于商业智能报告和机器学习的 Snowflake,以及用于实时欺诈检测的 Flink。他们选择了 Polaris 默认保留大小写的行为,以便在 400 多个表中保持驼峰式命名规范。
开始的时候, Spark 管道运行得非常顺畅,因为 Polaris 会完全按照输入的方式存储标识符。
CREATE TABLE payments.dailyTransactions ( transactionId STRING, merchantName STRING, paymentAmount DECIMAL(10,2), processingDate DATE); -- 通过 spark 创建的表当分析团队开始使用 Trino 时,问题随之而来:
SELECT * FROM payments.dailytransactions;-- Trino 会将其转换为小写 “dailytransactions”,Polaris 显示 “dailyTransactions” → 404该模式与已经记录的行为相符:其中,包含大写字母的表在浏览时会被转换为小写,而且,根据用户反馈,“来自 Iceberg REST 目录的区分大小写的标识符无法在 Trino 查询中引用,因为它们在传递给 REST 目录时已经全部被转换为小写”。实际上,这四百多个表对分析团队而言是不可见的。通过目录关联数据库(CLD)实现的 Snowflake 集成可以提供帮助,因为 CLD 会采用不区分大小写的解析方式将表名规范化为小写,从而使表可以被发现。然而,Flink 欺诈检测团队遇到了列级故障: Iceberg 元数据将 transactionId 存储为大写形式,而 Flink 采用区分大小写的解析方式,因此导致 SELECT transactionid 语句执行失败。为了解决这个问题,NovaPay 进行了一次迁移,将所有表重命名为 snake_case(即所有字母均为小写,单词间以下划线分隔的命名规范),并添加了 CI 代码检查规则,未来任何不使用小写的标识符都将被拒绝。
场景 B:小写规范化目录 (AWS Glue)
MediStream 是一家医疗健康分析初创公司,负责处理来自五十多家医院系统的患者记录,其数据架构如下:AWS Glue(目录)、基于 EMR 的 Spark 用于 ETL、基于 Trino 的 Athena 用于分析师查询,以及基于 Kinesis 的 Flink 用于实时警报。
这家初创公司之所以选择 AWS Glue,是因为他们是一家原生 AWS 环境的公司,并且期望 AWS Glue 目录的小写规范化功能能够帮助他们避免任何跨引擎的大小写问题。
团队立刻就遇到了瓶颈,因为 Glue 拒绝了他们采用 PascalCase 格式的表名:
# PySpark ETL jobspark.sql(""" CREATE TABLE glue_catalog.clinical.PatientVitals ( PatientId STRING, HeartRate INT, BloodPressure STRING, RecordedAt TIMESTAMP )""")Error: `ValidationException: 不能使用 PatientVitals 作为 Glue 表名,因为表名必须由 1 至 255 个字符组成,且仅包含小写字母、数字和下划线`这个问题与用户报告的另一个问题类似,即 Spark 无法跳过 Glue 的表名验证。团队花了两周时间,将八十多个表和 ETL 脚本重写为 snake_case。基础设施即代码(IaC)又增加了一个摩擦点: Glue 会将 Terraform 发送的大小写混合的名称默默转换为小写,因此, Terraform 会检测到持续不断的漂移。
即使是对表名进行标准化处理之后,列级问题依然存在。Glue 可以控制表名,但列名存储在 Iceberg 元数据中,因此,最初由 Spark 创建的 PatientId 列仍然保留着大小写混合的格式。基于 Trino 的 Athena 会在内部自动转为小写,从而透明地处理这个问题,但 Flink 要求严格区分大小写,这就导致同一张表在某个引擎上运行正常,而在另一个引擎上却会失败。为解决这些问题,MediStream 重建了早期的表,使用了小写的列名,将 Terraform 配置为小写,并在任何 CREATE TABLE 操作之前添加了一个验证步骤,拒绝不使用小写的列名。
如何选择你的数据库引擎组合?
作为实践者,以下决策框架可帮助你构建一个数据湖仓,并最大限度地减少与大小写敏感相关的问题。最具影响力的决策是选择一组能在数据湖仓中协同工作的引擎。你可以参考以下兼容性矩阵:
✅ = 兼容而且不需要做额外的工作
⚠️ = 兼容,但需要强制采用小写命名标准
⚠️⚠️ = 部分基础功能可用,但只靠小写命名规范不能完全解决问题(列级问题依然存在)
Spark 和 Snowflake(CLD)具有广泛的兼容性,因为二者在解析时均不区分大小写,表可以在它们之间无缝迁移。DuckDB 也采用不区分大小写的解析方式,因此同样兼容。Trino 严格的小写规范化机制会与保留大小写的引擎(例如 Spark、Flink 和 DuckDB)产生冲突,除非所有标识符原本就是小写。Flink 的要求最为严格,因为其区分大小写的解析机制会使得任何列大小写不匹配便引发错误,因此,它是对命名规范要求最严格的引擎。
强制执行命名规范
为避免数据技术栈中出现可发现性及其他与大小写相关的问题,必须制定并严格执行一套适用于湖仓架构中所有工具的命名规范。最有效的策略之一是将所有标识符默认限定为小写并使用下划线,这种做法在各类引擎和目录中均被广泛接受。如果偏离这个默认设置,就需要谨慎地匹配引擎并调整其配置,确保它们在所有场景中都能正常地运行。
采用小写命名规范可以避免大多数问题,但湖仓架构中的每一层都提供了配置选项,可进一步减少与大小写相关的问题。在多引擎环境中,默认设置并不总是最优的选项。
湖仓技术栈的配置选项
跨引擎验证
强制执行命名规范可以避免大多数问题,但要确保真正的跨引擎可移植性,唯一的方法是进行端到端测试。设置一个轻量级的持续集成任务,通过主引擎创建一张表,并验证该表能否被栈中其他所有引擎发现和查询,这有助于发现任何集成问题。这些跨引擎问题——例如目录规范化中的意外情况、Iceberg 元数据中列级大小写不匹配以及解析差异——只有在验证过程包含跨多个引擎的交互时才会显现出来。
小结
现代湖仓架构承诺,任何引擎都可以连接和访问单一数据副本,这一愿景依然是数据架构的指导方向,但前文讨论的案例证明,仅靠共享存储和统一目录并不足以提供无缝的数据访问体验。这一问题的根源在于两种标识符解析方法之间存在着根本性的理念分歧:即保留大小写的保真度与规范化大小写的统一性。虽然某些引擎遵循高保真理念,即保留并解析对象的确切大小写形式,因为它们的设计初衷是维护元数据的丰富性。但对于严格遵循规范化理念的其他引擎而言,这种灵活性会导致部分数据无法被发现。为了确保符合 SQL 标准,这些引擎会强制将标识符转换为规范化的大小写形式,从而丧失了发现不合逻辑对象的能力。
这种冲突迫使架构师不得不做出艰难的权衡:他们要么接受“影子表”的风险,要么实施僵化的、仅限小写的约束,去除传统系统的命名约定。组织必须停止将标识符命名视为引擎偏好的问题,而应将其视为一项关键的数据契约。
无论引擎或目录采用何种机制,制定一套严格的、全组织通用的命名规范,都可以最大限度地减少各团队的摩擦。归根结底,要解决“巴别塔”问题,就需要转变思维方式:真正的互操作性不仅在于共享磁盘上相同的数据,更在于确保所有接触这些数据的引擎都遵循共同的语言规范。
声明:本文为 InfoQ 翻译,未经许可禁止转载。
原文链接:https://www.infoq.com/articles/lakehouse-sql-identifier-rules/




