
2 月 11 日,蚂蚁集团开源发布全模态大模型 Ming-Flash-Omni 2.0。在多项公开基准测试中,该模型在视觉语言理解、语音可控生成、图像生成与编辑等关键能力表现突出,部分指标超越 Gemini 2.5 Pro。
模型地址:https://github.com/inclusionAI/Ming
据介绍,Ming-Flash-Omni 2.0 是业界首个全场景音频统一生成模型,可在同一条音轨中同时生成语音、环境音效与音乐。用户只需用自然语言下指令,即可对音色、语速、语调、音量、情绪与方言等进行精细控制。模型在推理阶段实现了 3.1Hz 的极低推理帧率,实现了分钟级长音频的实时高保真生成,在推理效率与成本控制上走在前列。
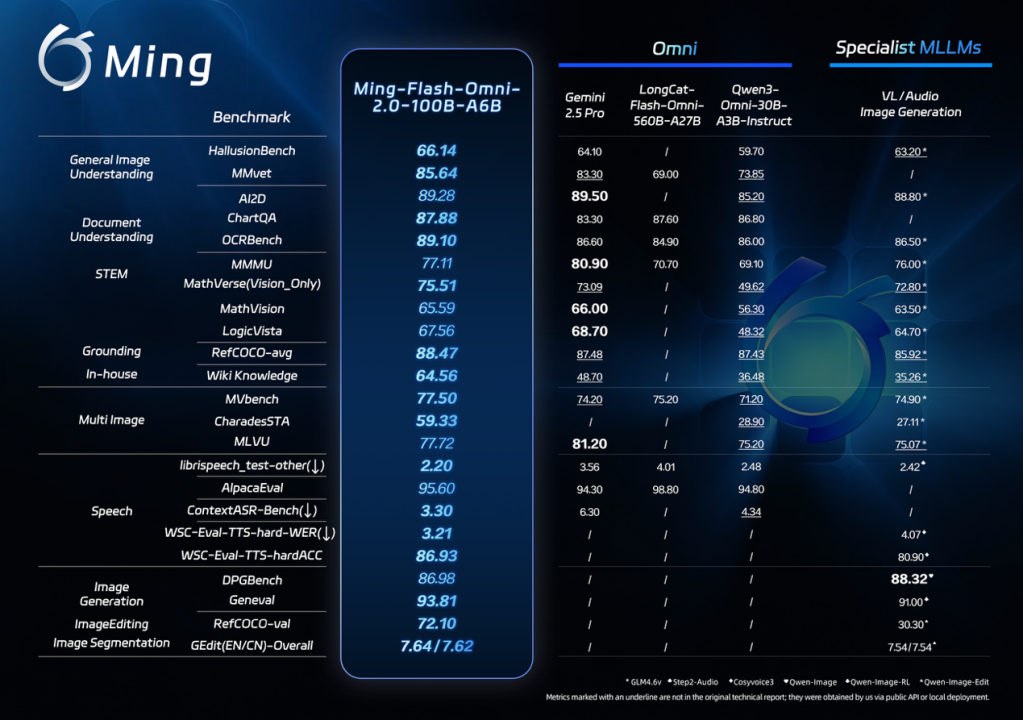
(图说:Ming-Flash-Omni-2.0 在视觉语言理解、语音可控生成、图像生成与编辑等核心领域实测表现均已达到开源领先水准)
全模态和多模态有啥不一样?
在大模型快速演进的背景下,“多模态”和“全模态”这两个概念正在频繁出现在技术发布和行业讨论中。表面看,它们都指向“模型能处理多种类型的数据”,但在底层实现路径和能力边界上,两者存在本质差异。
从能力表象来看,多模态与全模态高度相似。无论是多模态大模型还是全模态大模型,用户侧的直观体验都是:模型可以同时接收文本、图片、视频,甚至音频等不同模态的输入,并给出统一的输出结果。这也是许多非技术用户容易将两者混为一谈的原因。
真正的分水岭,出现在模型内部的实现方式。目前主流的“多模态大模型”,本质上是一种“模型拼装”思路:针对不同模态的数据,系统会分别调用对应的专用模型进行处理——例如,文本由语言模型理解,图像由视觉模型解析,音频交给语音模型识别。随后,再通过一个融合模块,将来自不同模型的结果进行整合,生成最终输出。
这种架构的优势在于工程实现相对成熟、可控,也便于在已有单模态模型基础上快速扩展能力。但其局限同样明显:不同模态之间更多是“后验融合”,信息在中间环节已经被压缩或结构化,跨模态的深层语义关联难以充分建模。
相比之下,“全模态大模型”走的是一条更底层的路线。所谓全模态,并不是简单地“支持更多输入类型”,而是指模型在设计之初,就将多种模态视为统一的信息空间,在同一个模型参数体系中进行联合建模。文本、图像、音频、视频不再对应独立的子模型,而是通过统一的表示方式进入同一套网络中学习、推理和生成。
这意味着,全模态大模型具备原生的跨模态理解与生成能力:不同模态之间的关联不是在输出阶段“拼接”出来的,而是在模型内部的表示层和推理过程中自然形成的。从理论上看,这种架构更接近人类对世界的感知方式,也更有潜力支持复杂的跨模态推理任务。
在当下,大多数落地应用仍然基于多模态架构。
业内普遍认为,多模态大模型最终会走向更统一的架构,让不同模态与任务实现更深层协同。但现实是,“全模态”模型往往很难同时做到通用与专精:在特定单项能力上,开源模型往往不及专用模型。
蚂蚁集团在全模态方向已持续投入多年,Ming-Omni 系列正是在这一背景下持续演进:早期版本构建统一多模态能力底座,中期版本验证规模增长带来的能力提升,而最新 2.0 版本通过更大规模数据与系统性训练优化,将全模态理解与生成能力推至开源领先水平,并在部分领域超越顶级专用模型。
此次将 Ming-Flash-Omni 2.0 开源,意味着其核心能力以“可复用底座”的形式对外释放,为端到端多模态应用开发提供统一能力入口。
Ming-Flash-Omni 2.0 基于 Ling-2.0 架构(MoE,100B-A6B)训练,围绕“看得更准、听得更细、生成更稳”三大目标全面优化。视觉方面,融合亿级细粒度数据与难例训练策略,显著提升对近缘动植物、工艺细节和稀有文物等复杂对象的识别能力;音频方面,实现语音、音效、音乐同轨生成,支持自然语言精细控制音色、语速、情绪等参数,并具备零样本音色克隆与定制能力;图像方面,增强复杂编辑的稳定性,支持光影调整、场景替换、人物姿态优化及一键修图等功能,在动态场景中仍保持画面连贯与细节真实。
百灵模型负责人周俊表示,全模态技术的关键在于通过统一架构实现多模态能力的深度融合与高效调用。开源后,开发者可基于同一套框架复用视觉、语音与生成能力,显著降低多模型串联的复杂度与成本。未来,团队将持续优化视频时序理解、复杂图像编辑与长音频生成实时性,完善工具链与评测体系,推动全模态技术在实际业务中规模化落地。




