
3 月 2 日,阿里巴巴将大模型 B 端品牌和 C 端应用品牌统一为千问。千问大模型(Qwen)涵盖基础大模型和专业领域模型,千问 APP 是阿里巴巴在 C 端的旗舰 AI 应用。为了避免之前千问、通义千问、Qwen 等多个名称导致的混淆问题,统一名称之后,阿里巴巴大模型品牌中文为“千问大模型”,英文为“Qwen”。“通义千问”的名称将不再使用。“通义实验室”为阿里巴巴集团旗下 AI 机构的组织名称。
3 月 3 日消息,阿里巴巴昨晚再度开源千问 3.5 系列模型,这次是 4 款小尺寸模型。其中最小的 0.8B 和 2B 两款,体积极小、推理速度快,适合移动设备、IoT 边缘设备部署,以及低延时的实时交互场景。4B 模型则适合作为轻量级 Agent 的核心大脑,平衡了性能与资源消耗。9B 模型性能媲美 GPT-OSS-120B,适合需要较高智力水平但受限显存资源的服务器端部署,是性价比极高的通用模型选择。
官方表示,四款 Qwen3.5 新模型虽是小尺寸,但均拥有原生多模态能力,以极小的参数量实现了极大的性能提升。模型发布后,迅速引爆 AI 社区,马斯克也火速在社交媒体上点赞评论,称阿里千问模型“智能密度令人印象深刻”。
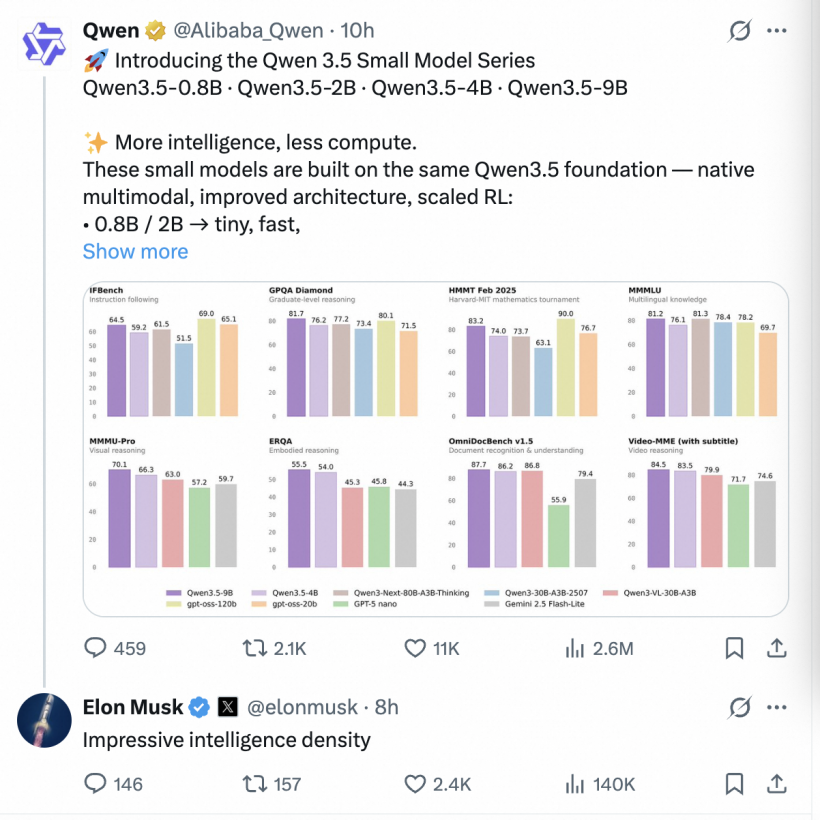
截至目前,千问 3.5 家族已开源 8 款模型,均以更少参数实现“跨级”性能超越,小尺寸性能媲美中型模型,而中型尺寸拥有顶级模型的智能水平。这正是马斯克说的智能密度。
刚刚过去的除夕,千问开源 3.5 系列的第一款模型 Qwen3.5-397-A17B,参数不到 4000 亿,性能即超过万亿参数的 Qwen3-Max 模型且部署成本大幅下降。2 月 25 日,阿里继续开源千问 3.5 系列模型。这次开源三款中等规模的新模型,包括 Qwen3.5-35B-A3B、Qwen3.5-122B-A10B、Qwen3.5-27B。千问 3.5 新模型甚至可直接部署于消费级显卡,对开发者极为友好。基于 Qwen3.5-35B-A3B 的托管模型 Qwen3.5-Flash 已上线阿里云百炼,每百万 Token 输入低至 0.2 元。
千问 3.5 模型采用混合注意力机制,结合高稀疏的 MoE 架构创新,并基于更大规模的文本和视觉混合 Token 上训练,新模型以更小的总参数和激活参数量,实现了更大的性能提升。
整体看,千问家族迄今已经开源 400 多款大模型。每个系列不仅包括不同尺寸的语言模型,也包括编程、数学、语音、视觉理解、图像生成等类型模型。这种“全尺寸”“全模态”的开源,受到开发者追捧。不同开发者和企业都能根据自己的需求、场景找到一款适配的千问大模型。




