
近日,密瓜智能团队与沐曦 MetaX 团队紧密合作,基于曦云 C 系列产品,在 HAMi v2.7.0 版本中联合推出了统一调度方案。
该方案通过深度整合,实现了 sGPU 共享、三档 QoS、拓扑智能调度与 WebUI 全面适配,旨在大幅提升大规模 AI 训练与推理场景下的资源利用率与任务执行效率,为构建国产自主可控的 AI 算力底座提供了坚实支持。
HAMi v2.7.0 版本为沐曦 MetaX GPU 提供了统一的调度方案。本文将在功能介绍的基础上,深入代码实现,详细剖析 HAMi 在支持 MetaX sGPU 共享、拓扑感知调度、QoS 策略等核心功能时的具体设计与实现原理。
核心特性总览
HAMi 为沐曦 MetaX GPU 提供了一套完整的虚拟化和调度优化方案,其核心特性包括:
GPU 共享(sGPU)与资源隔离:允许多个容器任务共享同一张物理 GPU 卡,并通过精确限制每个任务的显存(如 4G)与计算核心比例(vcore, 如 60%)来实现资源隔离,从而显著提高资源利用率。
sGPU 拓扑感知调度::(v2.7.0 新增)针对单机多卡的场景,调度器能动态感知 GPU 间的连接拓扑(如 MetaXLink、PCIe Switch),并为多卡 sGPU 任务优先选择通信带宽最高的 GPU 组合,提升训练性能。
服务质量 (QoS) 策略:(v2.7.0 新增)支持为 sGPU 任务设置不同的资源服务等级,如 BestEffort (尽力而为)、FixedShare(固定份额)和 BurstShare(突发份额),以满足不同业务场景的需求。
健康检查与监控: (v2.7.0 新增) 提供设备健康状态检查,在 HAMi-WebUI 中打通沐曦监控全链路,使得异构指标在界面中更直观呈现,可视化地展示整个集群的资源分配和使用情况。
GPU 拓扑感知调度: 基于 DevicePlugin 的预先打分,为多卡 GPU 任务优先选择通信带宽最高的 GPU 组合,支持 binpack 和 spread 等调度策略,实现更精细化的资源布局。
sGPU 拓扑感知调度:智能寻优
在单台服务器上配置多张 GPU 时,GPU 卡间根据双方是否连接在相同的 PCIe Switch 或 MetaXLink 下,存在近远(带宽高低)关系。服务器上所有卡间据此形成一张拓扑,如下图所示:
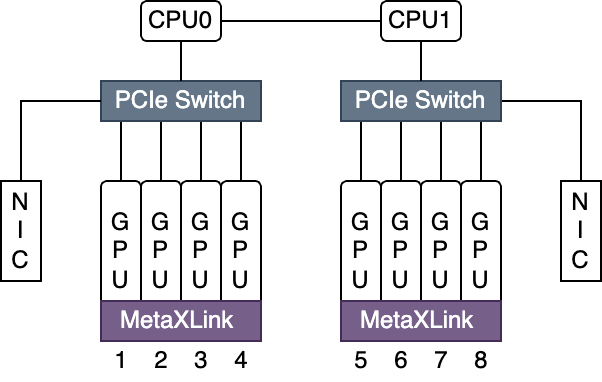
HAMi 调度器对沐曦 MetaX GPU 的拓扑寻优,是为申请整卡的多卡任务专门设计的。该功能需要通过请求 metax-tech.com/sgpu 资源,同时不指定 vcore(使其默认为 100)来触发。其核心目标是确保任务在高速互联的 GPU "群组"内部执行,从而最大化通信效率。
其核心思想是:一个结合了节点内“优先级”和节点间“量化评分”的两阶段决策机制。
它首先在每个节点内部,通过一套确定性的优先级规则直接选出最优的 GPU 组合,优先从单个高速互联域(linkZone)中分配。
随后,在多个候选节点之间,它通过一个综合了“分配质量”和“拓扑损失”的评分公式进行量化评估,选出不仅对当前任务最好,也对集群未来资源布局最有利的节点。
阶段一:节点内设备选择 - “规则至上”的确定性决策
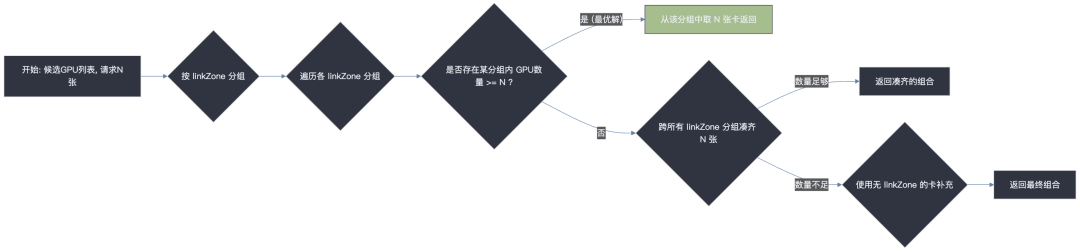
此阶段核心是在节点内部找到一个符合拓扑最优的 GPU 组合。这个过程不是一个评分竞赛,而是一个确定性的、遵循严格优先级的决策树。
工作流程详解
输入:节点上所有满足 Pod 资源请求(如显存、算力)的候选 GPU 列表。
分组:算法首先将这些候选 GPU 按照它们的 linkZone ID (高速互联域标识) 进行分组。
决策树: 算法开始按以下优先级顺序进行决策:
第一优先级 (最优解:域内满足): 算法会检查是否存在任何一个 linkZone 分组,其内部的 GPU 数量足以满足任务的全部需求。
第二优先级 (次优解:跨域组合): 算法会创建一个新的空列表,然后逐个遍历所有 linkZone 分组,将里面的 GPU 全部添加到这个新列表中,直到列表中的 GPU 总数满足任务需求。
第三优先级 (保底解:补充无互联信息设备): 如果遍历完所有 linkZone 分组后,列表中的 GPU 数量仍然不够,算法最后会用那些没有 linkZone 信息的 GPU 来补足剩余的数量。
阶段一的本质:通过强制的优先级规则,用最高效的方式锁定节点内部理论上通信性能最高的 GPU 组合。
此阶段的逻辑由 pkg/device/metax/sdevice.go 中的 prioritizeExclusiveDevices 函数实现。
其核心是,优先选择能被单个 linkZone 满足的设备组合。
// File: pkg/device/metax/sdevice.gofunc prioritizeExclusiveDevices(candidateDevices device.ContainerDevices, require int) device.ContainerDevices { // ... (代码将所有候选 GPU 按 linkZone 进行分组) ... // linkDevices: 存储了所有带 linkZone 的设备组 // otherDevices: 存储了所有不带 linkZone 的设备 // 1. pickup devices within MetaLink (第一优先级) for _, devices := range linkDevices { if len(devices) >= require { klog.V(5).Infof("prioritize exclusive devices: best result, within metalink") return devices[0:require] // 找到一个linkZone能满足所有需求,直接返回,这是最优解 } } prioritizeDevices := device.ContainerDevices{} // 2. pickup devices cross MetaLink (第二优先级) // ... (如果单个 linkZone 不够,则开始跨 linkZone 凑齐设备) ... // 3. if not satisfied, pick up devices no MetaLink (第三优先级) // ... (用 otherDevices 里的设备进行补充) ... return ... } 设计思想: 这种“规则至上”的设计避免了对 C(n, k) 种组合进行暴力评分的巨大开销。它基于一个核心共识:域内通信的性能远高于跨域通信。因此,一旦找到满足条件的“最优解”(第一优先级),任何其他组合方案都无需再被考虑,从而极大地提升了调度效率。
阶段二:节点间评分决策 - “深谋远虑”的量化评估
当多个节点都能通过第一阶段(即都能提供一个有效的 GPU 组合)时,调度器需要在这几个候选节点中做出最终选择。这个阶段采用的是量化评分机制。
评分机制详解
此阶段的逻辑由 pkg/device/metax/sdevice.go 中的 scoreExclusiveDevices 函数实现:
// File: pkg/device/metax/sdevice.gofunc scoreExclusiveDevices(podDevices device.PodSingleDevice, previous []*device.DeviceUsage) int { // ... (代码构建 allocatedDevices, availableDevices, restDevices 列表) ... // 计算三个核心分数 availableScore := availableDevices.Score() // 分配前总分 allocatedScore := allocatedDevices.Score() // 分配组合得分 restScore := restDevices.Score() // 剩余设备得分 // 计算拓扑损失分 lossScore := availableScore - allocatedScore - restScore // 计算最终得分,放大 allocatedScore 的权重 result := 10*allocatedScore - lossScore klog.V(5).Infof("calcScore result[%d] >>> availableScore[%d], allocatedScore[%d], restScore[%d], lossScore[%d]", result, availableScore, allocatedScore, restScore, lossScore) return result}每个候选节点都会被计算一个最终得分,得分最高的节点胜出。最终得分公式:
Final Score = (10 * allocatedScore) - lossScore
我们来拆解这个公式:
allocatedScore (分配质量分): 这个分数衡量的是第一阶段选出的那个 GPU 组合本身的内部连接紧密程度。组合内处于相同 linkZone 的设备对越多,这个分数就越高。10 * allocatedScore 表明调度器极度重视为当前任务分配一个高质量的组合。权重乘以 10,使其在最终得分中占据主导地位。
lossScore (拓扑损失分 / 碎片化惩罚): 这是一个非常关键的“远见”指标。它衡量的是:“为了完成本次分配,我们对节点上剩余的、未被分配的 GPU 的拓扑完整性造成了多大的破坏?”
计算方式:lossScore = (分配前总分) - (分配组合得分) - (剩余设备得分)
这意味着调度器会惩罚那些会导致节点拓扑资源“碎片化”的分配行为,在分配质量分相同的时候会起作用,保护了集群为未来的大型任务保留优质、完整拓扑资源的能力。
最终总结: 这个两阶段原理,首先通过刚性的优先级规则在每个节点内部“优中选优”,然后通过一个兼顾“当前利益”与“长远规划”的评分公式,在所有候选节点中做出全局最优决策。

服务质量(QoS)策略:“同类聚合”的隔离实现
HAMi v2.7.0 为 MetaX sGPU 提供了三种 QoS 策略:
BestEffort (尽力而为): 默认策略。资源尽力分配,不限制算力,追求最大化的资源利用率。
FixedShare (固定份额): 严格保证任务分配到的算力 (vcore) 和显存 (vmemory)固定配额,性能稳定,不受其他任务干扰。
BurstShare (突发份额): 有固定资源配额,但在 GPU 空闲时允许被 sGPU 使用,适合有突发负载的业务。
设计考量
在共享环境中,最大的挑战是如何隔离不同服务等级的业务。与其在底层驱动做复杂的动态资源抢占,设计者选择了一种更简洁、高效的方式:在调度入口进行“物理分组”。通过一个简单的规则,确保不同 QoS 类型的任务从一开始就不会被混合部署在同一张物理卡上,从而实现根源上的隔离。
核心原理与代码实现
该逻辑的核心是 checkDeviceQos 函数,我们可以将其总结为一句话:
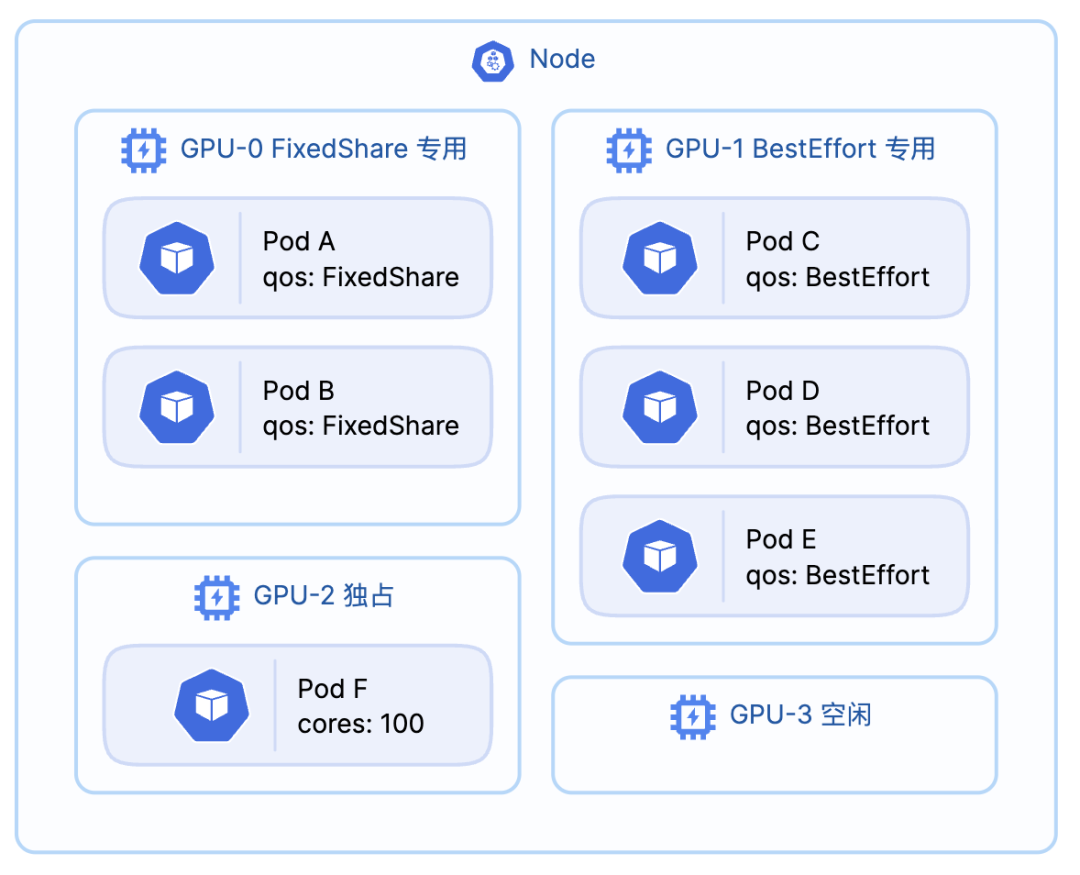
一张物理 GPU 卡,从第一个任务入驻开始,就只能接受和它“同类”的后续任务。
这意味着,一个 GPU 的“身份”在被第一个 Pod 占用时就被决定了。
如果第一个 Pod 是 FixedShare,这张卡就变成了“FixedShare 专用卡”。
如果第一个 Pod 是 BestEffort,这张卡就变成了“BestEffort 专用卡”。
任何试图进入一张“身份”不符的卡的 Pod,都会在调度阶段被拒绝,其核心逻辑如下:
检查 GPU 是否空闲: 如果 GPU 完全空闲,允许任何 QoS 任务入驻,并由该任务设定卡的 QoS 模式。
检查 QoS 是否匹配: 如果 GPU 已被占用,则新任务的 QoS 注解必须严格等于卡上现有任务的 QoS 模式,否则调度将被拒绝。
独占任务例外: 请求 100% 算力的任务,因不涉及共享,不受此规则限制。
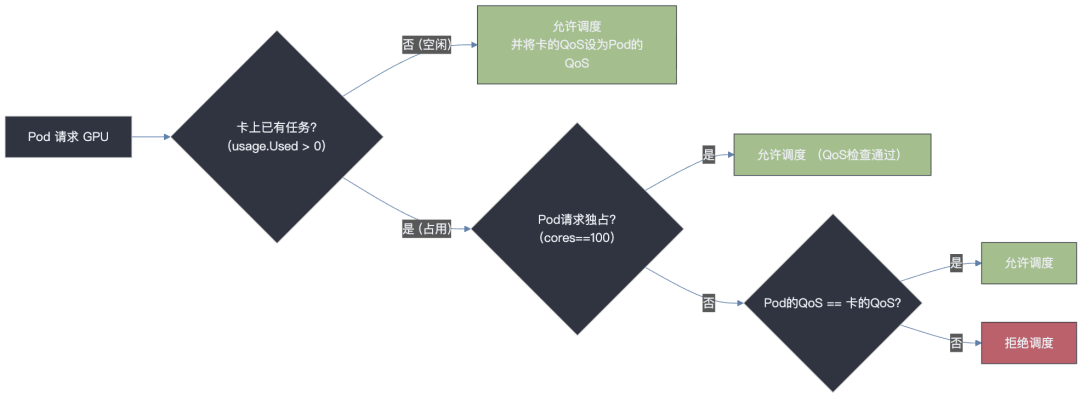
// file: pkg/device/metax/sdevice.go// func: checkDeviceQos (simplified logic)func (sdev *MetaxSDevices) checkDeviceQos(reqQos string, usage device.DeviceUsage, request device.ContainerDeviceRequest) bool { if usage.Used == 0 { // 空闲卡 return true } if request.Coresreq == 100 { // 独占卡 return true } // ... 获取 devQos ... if devQos == "" || reqQos == devQos { // 核心匹配规则 return true } else { return false }}这个简单的“同类聚合”规则,会在集群中自然地形成逻辑上的“QoS 资源池”,例如某些卡会自动成为 FixedShare 专用卡,另一些则成为 BestEffort 专用卡,从而实现了优雅而高效的资源隔离。
WebUI 支持
WebUI 现已全面支持沐曦 MetaX GPU 的监控指标展示,提供直观的资源使用情况概览。
GPU 拓扑感知调度:Binpack 与 Spread
当用户申请传统的 metax-tech.com/gpu资源时,HAMi 的 binpack 和 spread 策略会通过一种被动的、读取静态分数的方式来影响调度决策。
该机制依赖于沐曦 DevicePlugin 预先计算并标注在节点 Annotations 上的分数。调度器在决策时会读取这些分数,而不会进行任何实时的拓扑计算。
spread模式: 调度器会读取metax-tech.com/gpu.topology.scores(MetaxAnnotationScore) 的注解值。为了配合 HAMi 框架“分数越低,越靠前”的spread逻辑,这里需要做反转处理 (分数 = 2000 - score)。这意味着,一个节点的预计算score越高,其在 HAMi 的最终得分反而越低,从而排名靠前,越倾向于被调度,进而选择最优拓扑。binpack模式: 调度器会读取节点上metax-tech.com/gpu.topology.losses(MetaxAnnotationLoss) 的注解值。这个loss值越低,代表资源“损失”越小,节点得分就越高 (分数 = 2000 - loss),从而被优先选择,进而保障剩余资源的拓扑尽可能完整。
其核心代码位于 pkg/device/metax/device.go:
// File: pkg/device/metax/device.gofunc (dev *MetaxDevices) ScoreNode(...) float32 { res := float32(0) if policy == string(util.NodeSchedulerPolicyBinpack) { lossAnno, ok := node.Annotations[MetaxAnnotationLoss] if ok { loss := parseMetaxAnnos(lossAnno, sum) res = 2000 - loss } } else if policy == string(util.NodeSchedulerPolicySpread) { scoreAnno, ok := node.Annotations[MetaxAnnotationScore] if ok { score := parseMetaxAnnos(scoreAnno, sum) res = 2000 - score } } return res}MetaXLink 优先级高于 PCIe Switch,包含两层含义:
两卡之间同时存在 MetaXLink 连接以及 PCIe Switch 连接时,认定为 MetaXLink 连接;
服务器剩余 GPU 资源中 MetaXLink 互联资源与 PCIe Switch 互联资源均能满足作业请求时,分 配 MetaXLink 互联资源。
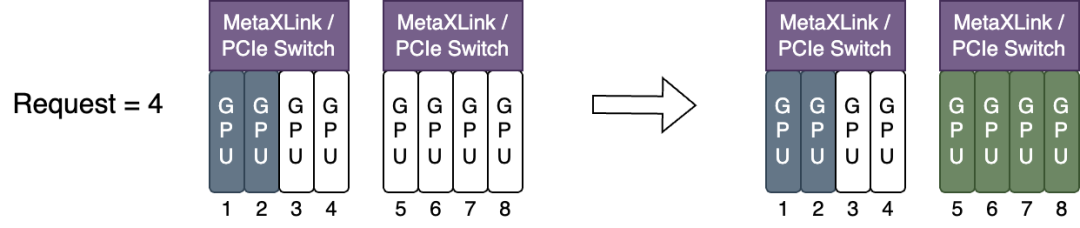
当任务使用
node-scheduler-policy=spread,分配 GPU 资源尽可能位于相同 MetaXLink 或 PCIe Switch 下,如下图所示:
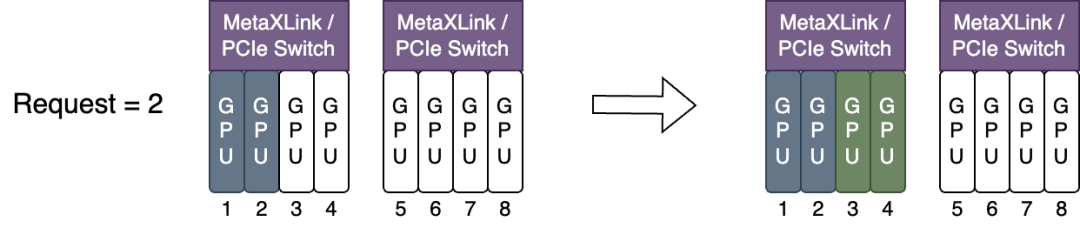
当使用
node-scheduler-policy=binpack,分配 GPU 资源后,剩余资源尽可能完整,如下图所示:
使用方式
GPU 拓扑感知调度
通过 hami.io/node-scheduler-policy 注解控制 binpack 或 spread 行为。
apiVersion: v1kind: Podmetadata: name: gpu-pod2 annotations: # binpack 策略: 针对 'gpu' 资源,调度器将读取节点注解 'metax-tech.com/gpu.topology.losses' 的值。 # 评分按 `2000 - loss` 计算,因此 loss 值越低的节点得分越高,会被优先选择,进而保障剩余资源的拓扑尽可能完整。 hami.io/node-scheduler-policy: "binpack" spec: containers: - name: ubuntu-container resources: limits: metax-tech.com/gpu: 2apiVersion: v1kind: Podmetadata: name: gpu-pod3 annotations: # spread 策略: 针对 'gpu' 资源,调度器将读取节点注解 'metax-tech.com/gpu.topology.scores' 的值。 # 评分按 `2000 - score` 计算。这会配合 HAMi 框架的 spread 逻辑,优先选择得分较低(即 score 注解值较高)的最优拓扑节点。 hami.io/node-scheduler-policy: "spread"spec:# ...sGPU 拓扑感知调度
apiVersion: v1kind: Podmetadata: name: gpu-pod1 annotations: metax-tech.com/sgpu-topology-aware: "true" # 开启拓扑感知调度spec: containers: - name: ubuntu-container resources: limits: # 请求 4 张完整的 GPU。因未指定 vcore,默认为100,从而触发独占模式与拓扑感知 metax-tech.com/sgpu: 4# ...sGPU 共享与 QoS 策略
通过 metax-tech.com/sgpu-qos-policy 注解指定 QoS。
apiVersion: v1kind: Podmetadata: name: gpu-pod annotations: metax-tech.com/sgpu-qos-policy: "fixed-share" # 或 "best-effort", "burst-share"spec: containers: - name: ubuntu-container resources: limits: metax-tech.com/sgpu: 1 metax-tech.com/vcore: 60 metax-tech.com/vmemory: 4总结
HAMi 对沐曦 MetaX GPU 深度的支持,在设计上体现了清晰的工程哲学:在关键路径上追求极致性能,同时通过简化非核心路径的实现来保证系统的稳定与高效。其两阶段的拓扑寻优算法兼顾了当前任务与集群的长期健康,而“同类聚合”的 QoS 策略则以极低的复杂度实现了有效的服务隔离。这些设计共同构成了一套成熟、高效的 GPU 调度与共享方案。
HAMi 与沐曦 MetaX 的此次深度合作为社区驱动的开源项目与硬件厂商的协同提供了思路。这些共同设计、联合开发的功能,不仅构成了一套成熟、高效的 GPU 调度与共享方案,也为国产 AI 生态的繁荣发展注入了新的活力。
Dynamia 密瓜智能,致力于提供异构算力调度、统一管理的全球化解决方案。发起的 CNCF 开源项目 HAMi,是唯一专注异构算力虚拟化的开源项目,通过灵活、可靠、按需、弹性的 GPU 虚拟化提升资源利用率,助力 AI 时代算力效率提升。
参考资料:
说明文档:MetaX GPU 支持说明(https://github.com/Project-HAMi/HAMi/blob/master/docs/metax-support_cn.md)
使用样例:MetaX GPU 样例(https://github.com/Project-HAMi/HAMi/tree/master/examples/metax)
相关 PRs:
https://github.com/Project-HAMi/HAMi/pull/1123
https://github.com/Project-HAMi/HAMi/pull/1193
https://github.com/Project-HAMi/HAMi/pull/1295
https://github.com/Project-HAMi/HAMi-WebUI/pull/46




