
单纯承担存取和备份功能的传统存储,已经无法满足 AI 时代的需求。
在数据规模激增、工作负载复杂的情况下,要提升 AI 基础设施的效率,支撑 AI 行业化落地,存储必须从被动的空间提供者,演进为与 AI、数据紧密结合的“智能存储”甚至“AI 数据平台”。也正因如此,最近几年来,很多存储厂商都把手伸向了人工智能的领域。
改善存储框架以适应 AI 的需求、实现数据自动化放置与策略化管理,是目前存储厂商与 AI 领域结合的主流思路。
相比之下,华为数据存储团队追赶 AI 发展的脚步显得更为紧密。其 2023 年以来推出的一系列产品——包括多款 AI 存储产品,DCS AI 解决方案,以及方案中开源的 AI 训推全流程工具链 ModelEngine、UCM 推理记忆数据管理器,和近期最新发布并开源的算力虚拟化调度平台 Flex:ai——都表明,华为数据存储团队正在探索一条独特的发展道路。
最近,华为公司副总裁、华为数据存储产品线总裁周跃峰对 InfoQ 解释了这些变化背后的逻辑。
他表示,“面向行业打造轻量级 AI 数据中心,并具备支撑行业化应用的能力”是华为数据存储团队目前最为关注的重点之一。
周跃峰还借用“AI 大脑 = 数据存储 + 处理器”的公式来概括华为数据存储产品线的战略考量。
随着 Flex:ai 容器技术的发布和开源,华为在 AI 行业化落地的解决方案生态上缺失的链条被进一步补齐。
值得注意的是,周跃峰强调,华为最终的目标不是用 Flex:ai 做高度定制化的行业方案,“而是通过开源的方式吸引生态伙伴,和我们一起结合行业场景不断优化,让 Flex:ai 成为一个好用的工具,从而推动 AI 在行业里进一步落地。”
对标 Run:ai,但更开源、更底层
在 AI 算力编排这一关键赛道上,华为在 11 月 21 日发布的 Flex:ai AI 容器技术,明确对标了去年年底被 NVIDIA 以 7 亿美元高价收入麾下的初创公司 Run:ai。
NVIDIA Run:ai 是基于 Kubernetes 构建的 AI 工作负载和 GPU 编排平台,目前提供自托管和 SaaS 两种产品类型。
然而,被 NVIDIA 收购后,Run:ai 的生态开放性开始面临市场的审视。
尽管 Run:ai 在宣布被收购时曾公布开源计划,并承诺逐步开放对 NVIDIA GPU 之外芯片的支持,但截至目前,其集群在硬件兼容性上仍高度受限,仅支持 NVIDIA GPU,兼容 x86 和 ARM CPU 架构。
在面临欧盟和美国反垄断审查的背景下,NVIDIA 仅开放了 Run:ai 的 KAI Scheduler 解决方案。部分业内观点认为,这种有限的开源举措更多是为了安抚反垄断监管机构。
在技术融合上,业界普遍预测,Run:ai 未来将被用于打包售卖,通过将自身的软切分技术与 NVIDIA 现有的 MIG(多实例 GPU)硬切分技术进行融合,共同增强其资源的配置灵活性。
与 Run:ai 相对封闭的生态相比,华为 Flex:ai 选择了更彻底的开源路线。
目前,Flex:ai 向下开放兼容第三方 XPU,向上则开放标准化接口,对接上层各类 AI 平台生态;除此之外,同步开源与高校联合研发的多级智能调度、算力资源切分和跨节点资源聚合三项核心技术。

值得注意的是,虽然都专注 AI 算力编排,Flex:ai 更强调其作为容器技术的突破。
Flex:ai 采用了与 Run:ai 相似的时分技术,但相比专注上层调度的 Run:ai,Flex:ai 加入了从底层开始的容器技术,使其在虚拟化、隔离等方面更具有优势。
华为技术专家向 InfoQ 表示,硬切分会提供更好的隔离性,但相比 MIG 技术,Flex:ai 能提供更灵活和便捷的分片方式;相比 Run:ai 通过调度实现的虚拟化技术,Flex:ai 则能提供更好的隔离性。
从调度工具,到 AI 容器
Flex:ai 与 Run:ai 的分野,实质上源于两者对容器技术角色的根本认知不同。
Run:ai 的核心仍是一套面向 GPU/NPU 调度的工具链。它基于 Kubernetes 完成集群级任务编排,再通过分片,在节点上实现细粒度的 GPU/NPU 内存虚拟化与计算时间片切分,从而提升利用率、减少资源浪费。
而华为希望构建的,是一个 AI 原生的容器基础设施。
它不仅需要承载 GPU、NPU 等异构算力,还要处理大规模模型训练、推理、多任务混部等复杂负载;解决抢占、迁移、扩缩容、细粒度共享等 AI 时代的系统性需求。
这些变化,使 AI 容器成为承载整个异构算力池的基础设施,也对容器作为一种虚拟化技术,提出了更高的业务需求。
华为 2012 实验室理论研究部首席研究员张弓将 AI 虚拟化的核心诉求总结为四点:支持高优先级任务的抢占与快速恢复;任务能够动态快速扩缩容;实现细粒度的 GPU/NPU 资源共享,达到一虚多;支持任务迁移,提升资源利用率。
传统的全虚拟化和半虚拟化技术,存在开销巨大、无法获得应用层信息的问题;MIG 这样的硬件虚拟化技术,无法动态分布、高效利用资源;内核虚拟化上,现有技术需要侵入式修改内核,不支持任务迁移。
这正是 Flex:ai 试图突破的技术边界。
为解决上述目标,华为构建了 AI 容器弹性计算框架。
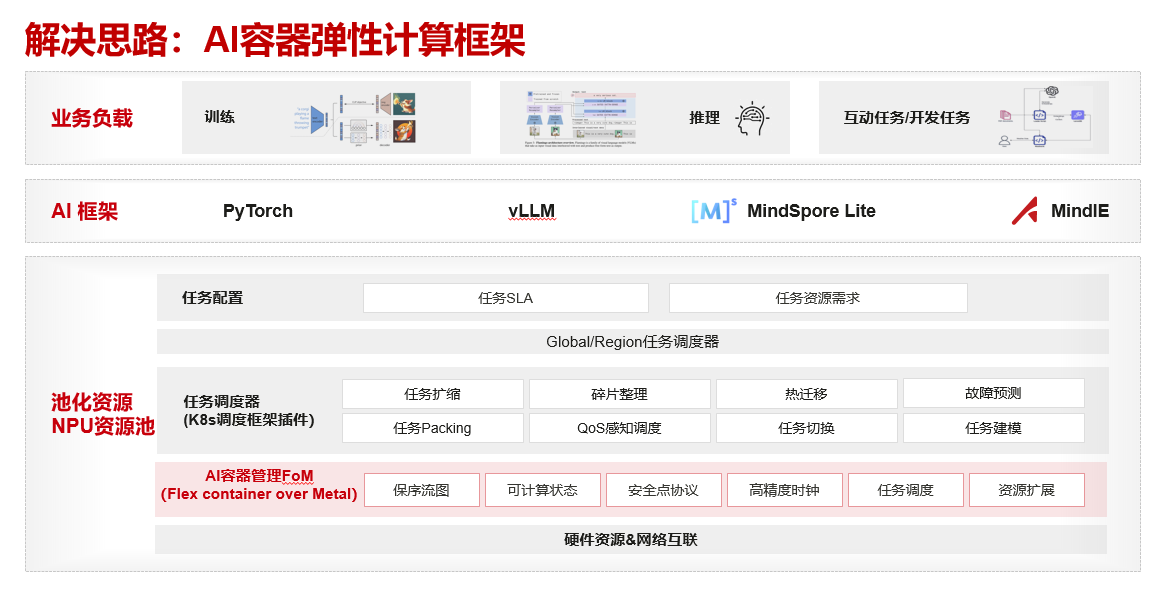
AI 容器弹性计算框架的核心是 AI 容器管理组件 FoM (Flex container Over Metal) ,它让华为在虚拟化的深度和管理对象上和 Run:ai 走上了完全不同的道路。
Run:ai 在 Kubernetes 容器编排层之上,它通过 GPU Fractions 在各个 worker 节点本地运行,管理 GPU 的显存分块和计算时间切片;它通过 GPU Fractions 构造 “逻辑 GPU”,本质上依靠强制显存配额与时间片共享机制来提高 GPU 的利用率。
FoM 则位置更靠近硬件,它位于 Kubernetes 调度框架插件之下,直接深入到 NPU 的算子层级进行管理。FoM 的核心功能有 API 算子的劫持和生成 NPU 算子执行图、可计算状态、安全协议等能力;通过一个 Client/Server 式的虚拟化体系对 CANN API 进行拦截和重构,使多个 NPU 应用能够被调度到同一张物理卡上,真正实现任务级别的抢占、迁移与细粒度共享。
面向行业落地的 AI 容器
面向行业落地的能力,是目前 Flex:ai 关注的核心。
当 AI 真正走向行业场景时,问题往往不是模型不够强,而是算力和工程体系“跟不上”。
医疗行业是最典型的例子。一个医院通常只会采购 4~16 张 GPU 或 NPU,用来承担本地化的模型训练或推理。但这样的“小规模集群”很容易带来浪费:任务较小时,一张卡只跑了不到一半的资源;任务太大时,又无法跨多机拼成更大的虚拟算力;多人并发使用资源时,只能依靠简单排队,扩卡既昂贵,也不现实。
Flex:ai 正是为解决这些行业侧痛点。它通过虚拟化、资源池化和多级调度,把原本粗颗粒的算力切成可弹性调度的小单元,让小集群也能获得“高利用率 + 高并发 + 高隔离”的能力。
XPU Pool:细粒度虚拟化,大幅提高算力利用率
行业小模型(如 RAG 推理)往往只吃掉 3%~5% 的卡资源,轻量化的大模型任务(如 Llama 3B 量化)也很难撑满一整张卡,小集群因此普遍存在严重浪费。
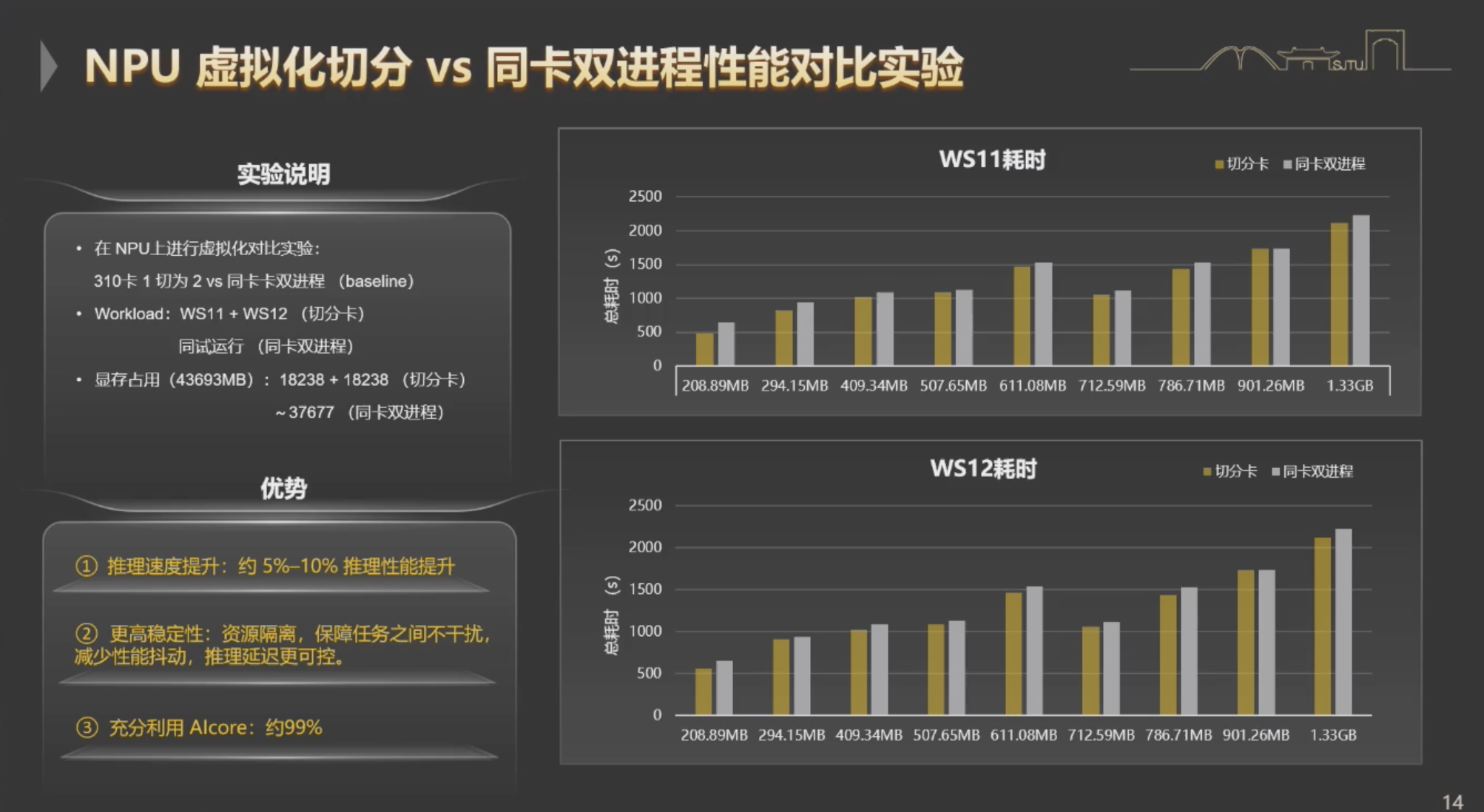
由华为与上海交通大学联合研发的 XPU Pool 通过细粒度的软切分,将一张 GPU/NPU 划分成任意数量的虚拟算力单元,并支持动态重配置。资源通过时分共享,任务之间保持严格隔离。
在多任务场景下,交大在 NPU 300 I Duo 上的对比实验显示:XPU Pool 不仅确保了任务间的稳定性,还提升了 5%~10% 的推理性能。
Hi Scheduler:多级、分时调度,精准匹配负载和算力资源
为了实现 AI 训练和推理任务与底层计算资源的最优匹配,Flex:ai 引入了与西安交通大学联合研发的多级智能调度器 Hi Scheduler。
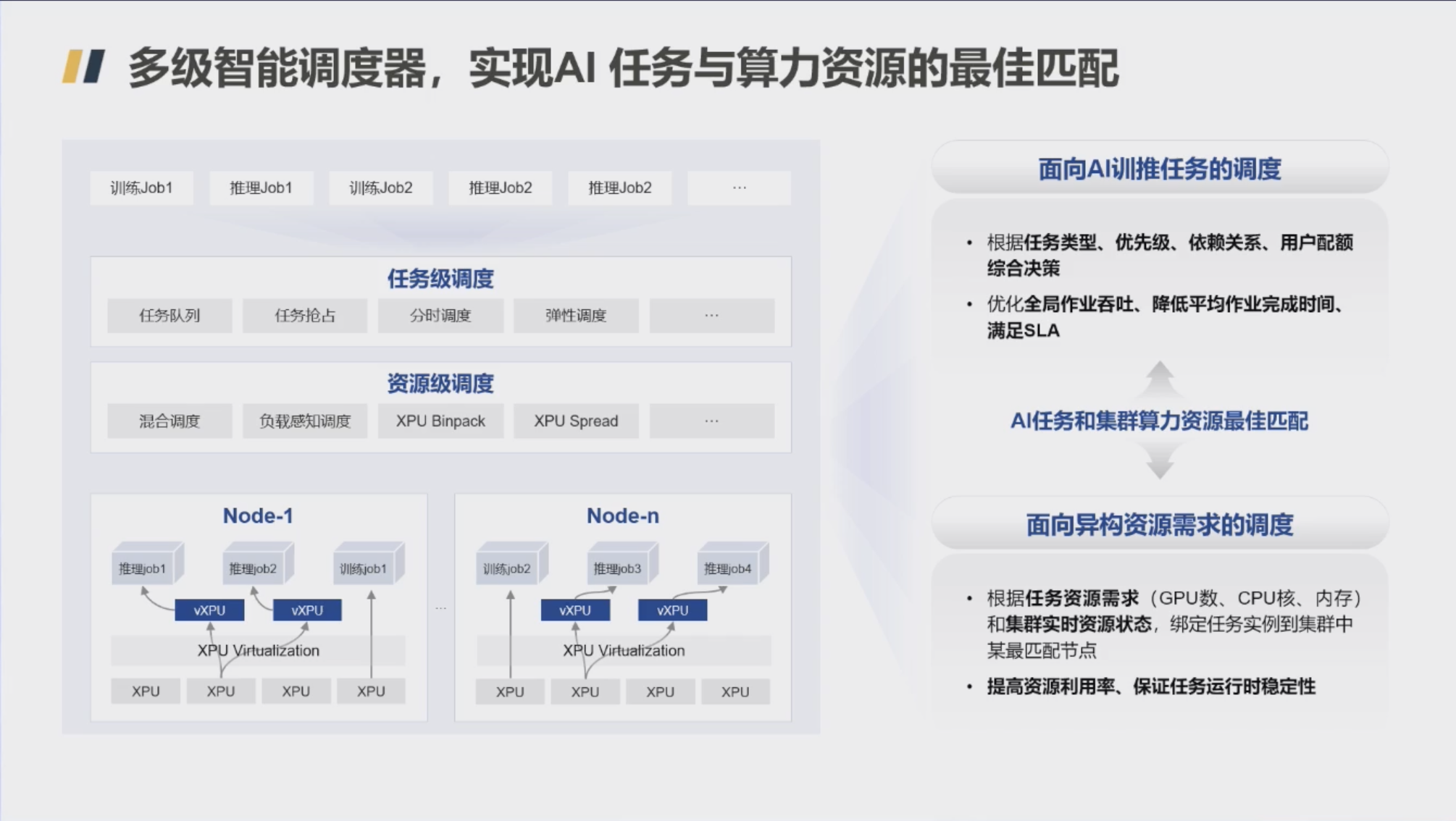
宏观上,Hi Scheduler 根据任务类型、优先级、用户配额等决策调度策略,优化全局作业的吞吐量,并确保 SLA。
微观上,它结合集群实时的资源状态和任务的异构需求,将任务准确地分配到最合适的计算节点。
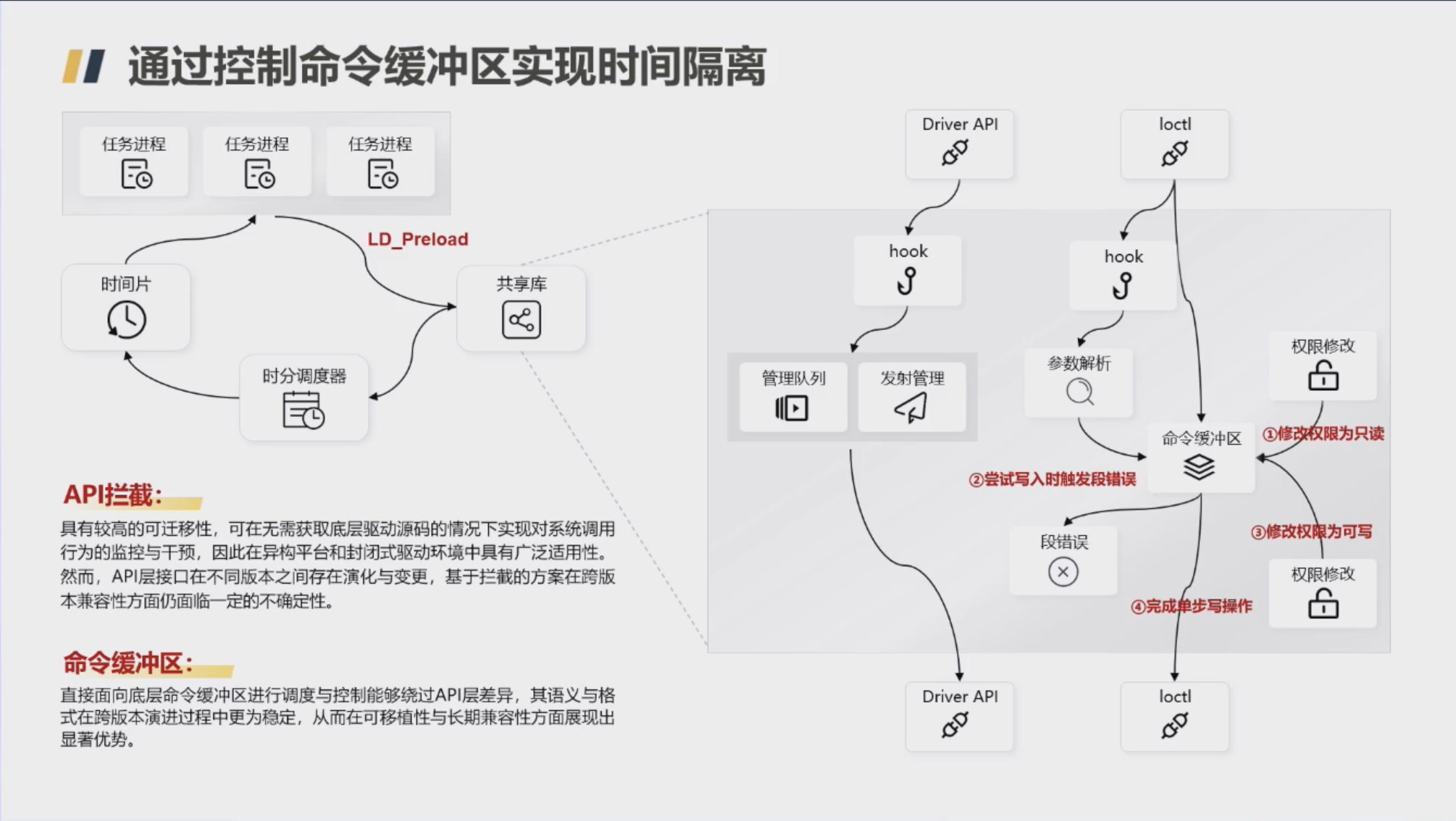
为了跨平台稳定运行,Hi Scheduler 通过控制命令缓冲区实现时间隔离。直接面向底层命令缓冲区进行调度与控制,有效屏蔽了 API 层的差异性,其语义与格式在跨版本演进过程中更为稳定,从而在可移植性与长期兼容性方面展现出显著优势。
拉远虚拟化:同时面向多租户、多作业
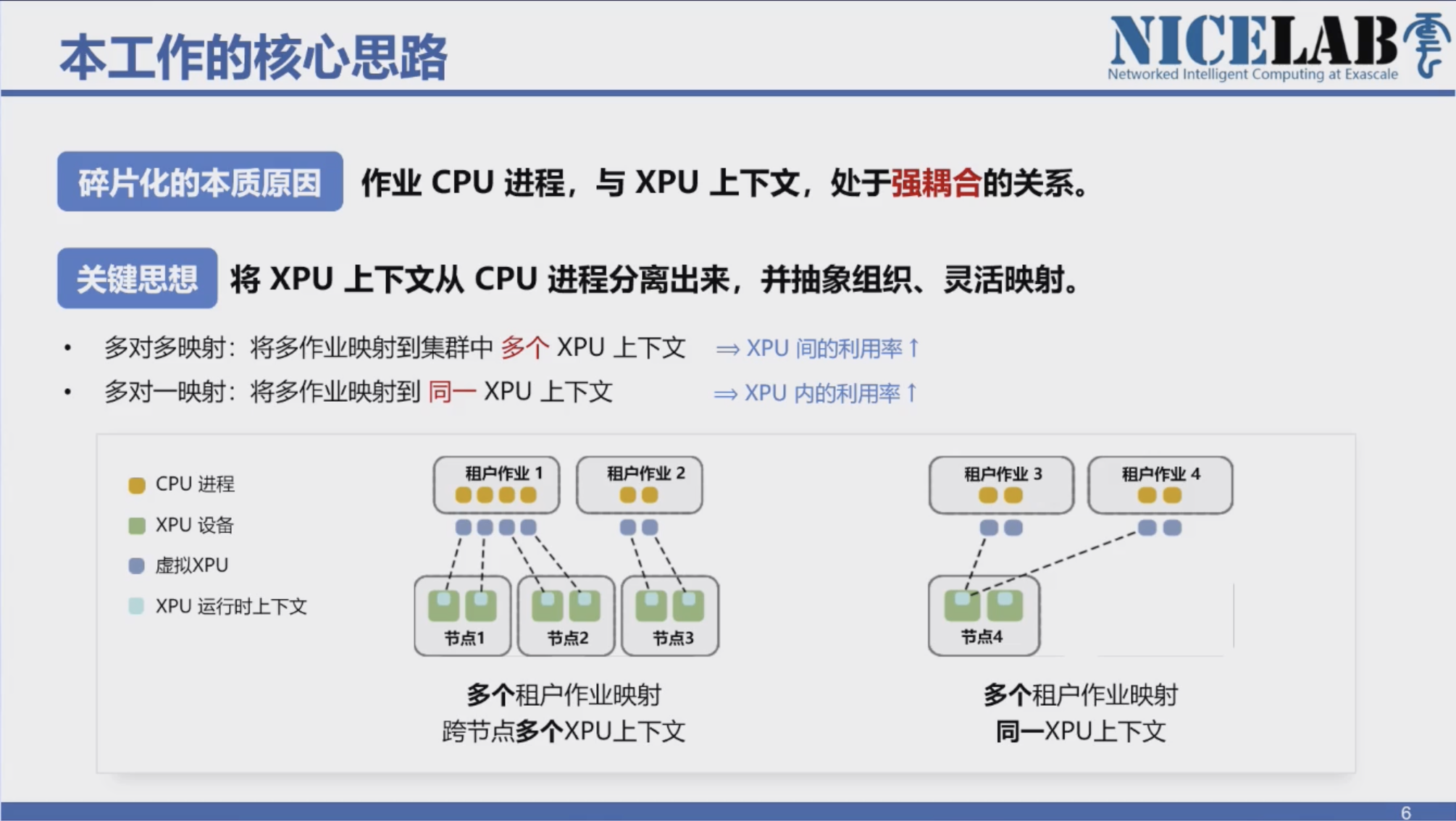
传统 XPU 虚拟化,由于 CPU 进程与 XPU 上下文的强耦合,面临两个核心瓶颈:外部,跨节点 XPU 空闲形成孤岛;内部,单卡内部算力难以被多任务同时利用。
华为与厦门大学联合研发拉远虚拟化技术,提供了面向多租户、多作业的算力复用能力,可以在不做复杂的分布式任务设置情况下,将集群内各节点的空闲 XPU 算力聚合形成“共享算力池”,此时不具备智能计算能力的通用服务器通过高速网络,可将 AI 工作负载转发到远端“资源池”中的 GPU/NPU 算力卡中执行,实现通用算力与智能算力资源融合。
XPU 共享技术包括两项技术突破:
跨节点的 XPU 映射技术,将 XPU 上下文从进程中剥离,实现“多对多”与“多对一”的灵活映射,打破 CPU–XPU 的绑定关系;
性能感知的时空复用技术,通过多流映射与共享上下文,在保证公平性的前提下实现多作业的并行处理;结合启发式空分复用,让低频与高频任务协同执行,提高整体吞吐。
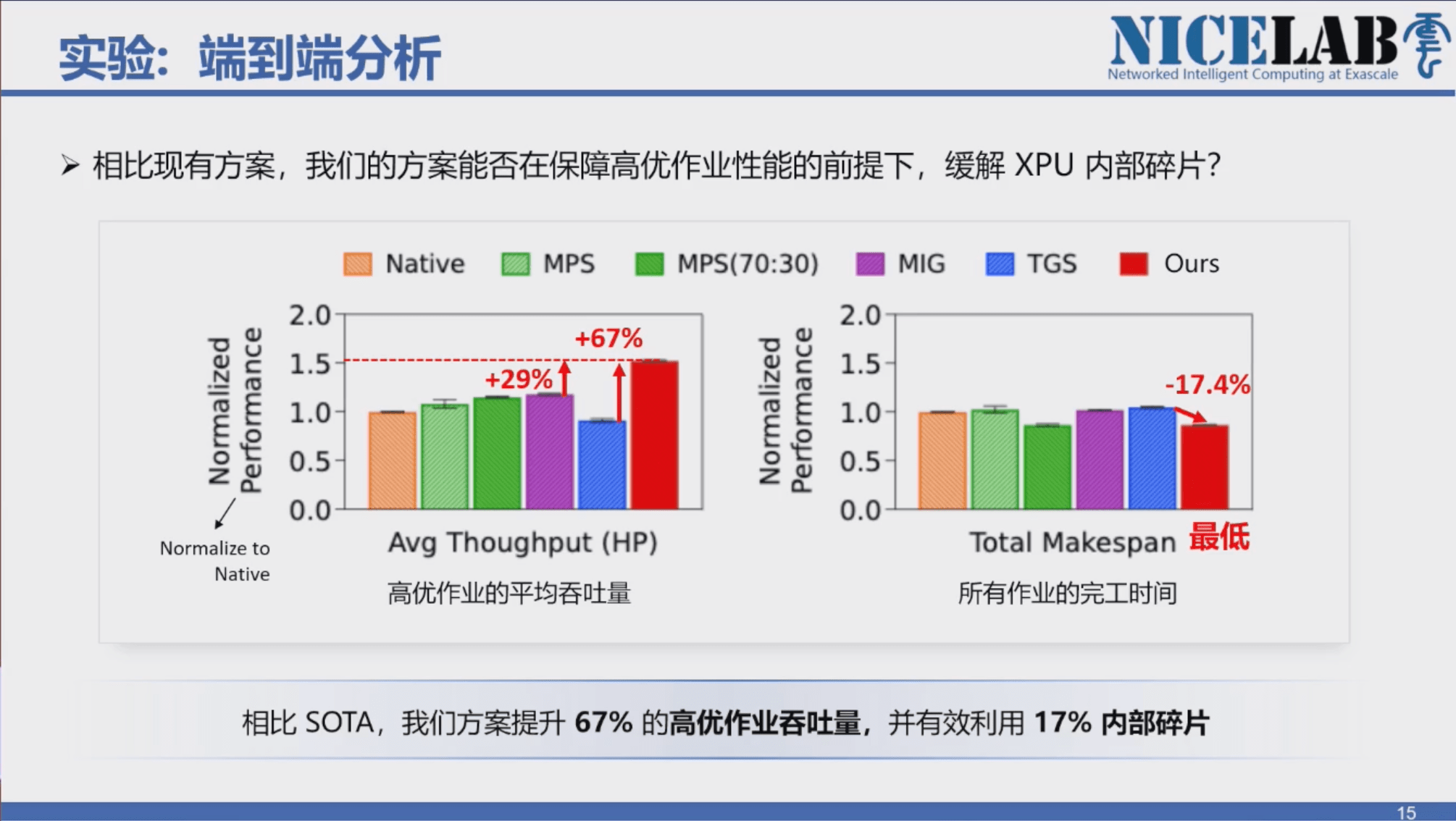
通过端到端的实验,厦门大学的方案相比 SOTA,提升 67% 的高优作业吞吐量,并有效利用 17%内部碎片。
目前,Flex:ai 已经在实际场景中落地。在与国内某头部三甲医院的合作中,华为利用 DCS AI 解决方案,集成 ModelEngine、Flex:ai 等组件,在 2 个月内、基于 16 张卡完成百万级病理切片训练,推动行业专家大模型本地化部署。
该实践也证明,在容器技术加持后,小规模算力集群同样能够承担行业级 AI 任务。
在此基础上,Flex:ai 等技术的开源,为国内的解决方案厂商与系统集成商提供了更加灵活的技术选项,使其在不依赖大规模中心化算力的情况下,也能构建可扩展、可演进的行业 AI 基础设施。




