
据纽约时报报道,数据科学家在挖掘出有价值的“金块”之前,要花费 50%至 80%的时间在数据准备上。如何更高效地进行数据准备,如何更好地将原始数据转为资产体现价值,如何通过数据将业务和技术紧密结合也是业内热点和难点话题。本文主要通过介绍面向业务用户群体的数据准备过程,聚焦实际应用案例,探讨数据准备工具的企业级应用价值。
数据准备工具介绍
1. 数据准备
根据 Gartner 的报告,数据准备是一项必须具备的技术,是一个迭代且灵活的过程,可以用于查找、组合、清理、转换和共享数据集,包括用于分析/商业智能(BI)、数据科学/机器学习(ML)和自主数据集成中。具体来说,数据准备是在处理和分析之前对原始数据进行清洗和转换的过程,通常包括重新格式化数据、更正数据和组合数据集来丰富数据等。
但是对于数据专业人员或业务用户来说,数据准备通常是一项漫长的工作,但同时也是将数据置于上下文环境中的必要前提,以便将其转化为洞察力,并消除由于数据质量差而产生的偏见。
良好的数据准备可以实现高效的分析,减少数据在处理过程中可能出现的错误和不准确性,并使所有处理过的数据更易于用户访问。随着新工具的出现,任何用户都可以更加容易地自己清理数据。
数据准备工具就是这样一类体量轻、适用人群广的专业化工具,能助力业务用户(包括分析师、数据工程师和数据科学家等)为他们的项目案例集成内部和外部数据集,从而保证更快地交付、集成和管理数据。此外,工具允许用户识别异常和特殊格式,并以可重复的方式改进和审查其发现的数据质量。一些工具嵌入机器学习算法,在某些情况下,可以完全自动化某些可重复和普通的数据准备任务。缩短交付数据和洞察的时间是这个市场的核心。
2. 为什么要有专门的数据准备工具
纽约时报曾有过一篇报道,数据科学家在挖掘出有价值的“金块”之前,要花费 50%至 80%的时间在收集数据、准备不规则数据、清理数据的烦冗任务上。没有合适的工具,数据准备将是耗时的、昂贵的、且容易出错的,下面是一些公司在此方面的反馈:
Blue Hill:
分析师花费 80%的时间来查找和清理数据,每年每个分析师花费公司 22000 美元。
Forbes:
88%手动创建的电子表格包含重大错误。
IBM:
2016 年,糟糕的数据质量使得美国损失 3.1 万亿美元。
Harvard Business Review:
大多数企业单位使用小于 50%的结构化数据和小于 1%的非结构化数据进行业务决策。
因此,数据准备方案不再是一个可选项任务,它已经变成了数据分析流程中的必选项。同时,在越来越强调团队协作的环境下,企业分工越来越重要。对数据来说,创建社区型的数据市场,一人创建,全体受益的模式,在现代型企业中更受欢迎。
3. 与 ETL 的异同
我们熟知的 ETL 也是包括了数据抽取、数据的清洗转换和数据加载的过程,以此达到将企业中分散凌乱且标准不统一的数据整合在一起,为企业决策提供分析依据的目的。
看到这里可能很多人对于数据准备工具与 ETL 之间的关系充满好奇,甚至觉得我们已经有了完整的 ETL 流程,为什么还需要数据准备工具呢?
如果 ETL 是你日常工作的一部分,那么你就会知道提取、转换和加载有效完成工作所需的关键数据可能需要 1 到 24 个月的时间。作为一名分析师,等待正式的 ETL 流程来访问必要的数据可能会导致项目滞后等问题。
如果不需要等待呢?如果你能在数小时内得到你自己需要的数据呢?你所需要的只是自助数据准备。
如今,分析师 80%的时间都花在从不同来源提取、清理和准备数据上,但是有了数据准备工具,你就可以花更多时间分析信息以获得重要的业务洞察。
用户角色
ETL 工具是为技术用户创建的,而数据准备工具更多的是面向业务用户,例如分析师、销售运营经理、市场经理等各行各业的许多人都可以使用这些工具。
目前数据准备工具大都设计为可视化的数据表示形式,类似于 Excel 电子表格,用户可以在工作空间的中心看到数据。这允许非技术用户调查数据质量问题、准备数据、验证数据,并查看数据值如何随着应用不同的规则或条件而变化。
实际使用
ETL 依赖于一套预先确定的规则和工作流程,需要事先预料到一些潜在的问题,这样就可以将如何处理这些问题的规则构建到工作流中。相反,使用数据准备工具能够在工作流程中直接发现和调查数据。
数据复杂性
除了关系型数据源等常见数据来源,数据准备工具在更复杂的数据类型中仍然很强大,例如从 PDF 文件中提取数据等。
总的来说,ETL 和数据准备在概念上相似,解决的是同一个问题,但不同之处在于实际使用方式、数据类型和用户角色等,这些也决定了他们在市场上服务的案例类型。
尽管 ETL 仍然在长期项目中占有一席之地,但自助数据准备可以补充 ETL,为你提供访问关键数据的控制权、所有权、敏捷性和速度,并加快决策制定的时间。
4. 数据准备工具市场
根据 Gartner 预测,到 2022 年,数据准备将成为超过 80%的数据集成、分析/BI、数据科学、数据工程和数据湖实现平台的关键能力。其中,到 2021 年,那些为用户提供内部和外部准备好的数据分类的企业将比那些不提供的企业实现两倍的分析投资的商业价值。
不远的将来,预计到 2024 年,增强数据准备、数据目录、数据统一、数据虚拟化和数据质量工具将汇聚成一个统一的数据结构,用于大多数新的分析/数据科学项目。
实际应用场景和案例
主要结合全球知名的数据准备工具 Altair Monarch™介绍在金融领域的应用场景案例。
1. 挑战:减少银行交易中的时间和错误(例如:ATM 机)
银行将每天的 ATM 交易合并成自动生成的文件(通常是电子表格)。每天有成千上万台机器和成千上万条记录,手动对账到余额水平需要数千小时且非常容易出错。
通过数据准备工具可以自动化任务流程,且将每天自动生成的文件附加在一起。无需业务分析师每天花费数小时手动将大量文件加载到数据库中、运行逻辑并与核心银行系统解决方案中的信息进行比较,Monarch 可以在短短几分钟内完成这项任务。数据模型使报告标准化以满足用户和法规的要求,提高运营效率且降低成本。在整个过程中没有加载 ETL,用户可以自己完成数据转换工作,并将最终报告与其他系统/应用程序集成在一起。通过减少花费在手动调节任务上的时间,从银行客户反馈得知,时间成本从每月 3500 小时缩短到 1500 小时。
类似的需要对数据采集、准备和交付等设置大量自动化及周期性任务,比如会计部门的总账、分类账,以及零售银行的申请表、对账单等都可以使用这一解决方案提高终端用户参与的灵活度和高效性。
2. 挑战:减少从数千个数据创建报告时的时间和错误
在企业中,通常有一个集中的文件存储库,半结构化数据(例如:文本、PDF、电子表格)被转储到存储库中。但是不同应用程序之间的报表格式常常不一致,甚至使用相同应用程序创建的报表格式也不一致。
通过数据准备工具和 RPA 的结合,RPA 会自动将数据从总的文件存储库下载到目标文件夹,然后完成从这些文件中批量提取数据。数据准备工具自动将提取的数据转换为符合最终用户和监管要求的标准化报告格式。实际应用于公司得到的反馈为:通过实施该完整的解决方案,其共享服务团队每月在数据提取和数据转换任务上节省了 3000 多个小时,同时最终报告的准确性显著提高。这一方案将帮助用户优化工作流程,并减少了分析师的 300%所需的 IT 时间。
只要是用户需要手动将数据从文本/PDF 文件中复制到基于电子表格的报表的应用场景,都可以使用这一解决方案节省大量时间并提高准确性,比如用于对账、认证、财务报告、分录、监管备案等。
数据准备工具 Altair Monarch™
Altair Monarch™是 Altair 数据产品中的数据准备工具,已有三十年的历史。利用 Monarch 可从多种数据来源中快速、简单地提取需要的数据,包括将非结构化数据,如 PDF、文本、网页等,转化为行与列的结构化数据。提取数据后,用户可以在无需编码和基于鼠标点击的方法下进行数据的清理、转换、合并、去重等工作,并且可以导出到任何的数据分析平台或者 BI 工具进行进一步的操作。
2020 年 12 月,Altair Monarch 在 Gartner Peer Insights 数据准备工具评选中荣获“客户之选”称号,在总分为 5 的综合评分中获得 4.5 分的认可。该称号的评选会对工具的多项指标进行综合评分,包括整体评级、供应商比较、针对公司规模、行业和区域的客户选择等,Monarch 在数据准备领域已经获得了众多客户的青睐和来自业界的认可。
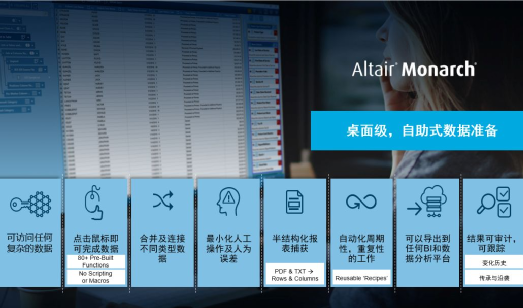
使用 Monarch,任何人都可以做到:
从多源异构中提取数据,如 PDF、文本、网页等;
将非结构化、半结构化和多结构化的数据转换为行与列;
使用预先构建的功能进行数据清理,不需要任何编码;
记录数据处理的每一步操作,形成命令流文件,对后续同类的文件做到自动化处理,无需手工重复操作;
对转换好的行与列数据,进行合并、去重、转置等操作;
导出结构化文件到各种数据分析,可视化工具进行下一步的操作。

Altair Monarch 的专业、高效、灵活、极易上手等特征使其被国内外众多知名企业青睐,包括:
万事达卡、花旗、汇丰、摩根大通等金融客户(信用风险、市场分析、财务报表等);
辉瑞、联合健康集团等医疗健康客户(收支周期管理、文件处理等);
政府部门(内审、外审、PDF 文件转换等);
麦格纳、福特等制造业客户(HR、交易对账、财务等)。
本文转载自:DataFunTalk(ID:dataFunTalk)
原文链接:专业数据准备工具的介绍和应用




